ALS算法是2008年以来,用的比较多的协同过滤算法。它已经集成到Spark的Mllib库中,使用起来比较方便。
从协同过滤的分类来说,ALS算法属于User-Item CF,也叫做混合CF。它同时考虑了User和Item两个方面。
用户和商品的关系,可以抽象为如下的三元组:<User,Item,Rating>。其中,Rating是用户对商品的评分,表征用户对该商品的喜好程度。
ALS算法是基于模型的推荐算法。起基本思想是对稀疏矩阵进行模型分解,评估出缺失项的值,以此来得到一个基本的训练模型。然后依照此模型可以针对新的用户和物品数据进行评估。ALS是采用交替的最小二乘法来算出缺失项的。交替的最小二乘法是在最小二乘法的基础上发展而来的。
假设我们有一批用户数据,其中包含m个User和n个Item,则我们定义Rating矩阵,其中的元素表示第u个User对第i个Item的评分。
一般情况下,k的值远小于n和m的值,从而达到了数据降维的目的。在实际使用中,由于n和m的数量都十分巨大,因此R矩阵的规模很容易就会突破1亿项。这时候,传统的矩阵分解方法对于这么大的数据量已经是很难处理了。
另一方面,一个用户也不可能给所有商品评分,因此,R矩阵注定是个稀疏矩阵。矩阵中所缺失的评分,又叫做missing item。
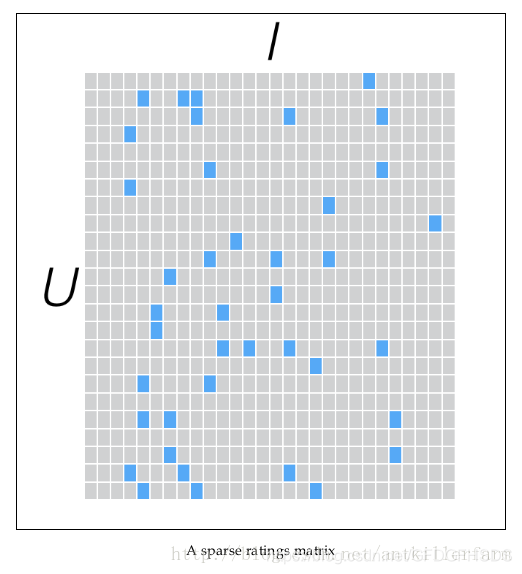
针对这样的特点,我们可以假设用户和商品之间存在若干关联维度(比如用户年龄、性别、受教育程度和商品的外观、价格等),我们只需要将R矩阵投射到这些维度上即可。这个投射的数学表示是:
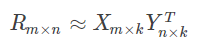
这里的表明这个投射只是一个近似的空间变换。一般情况下,k的值远小于n和m的值,从而达到了数据降维的目的。
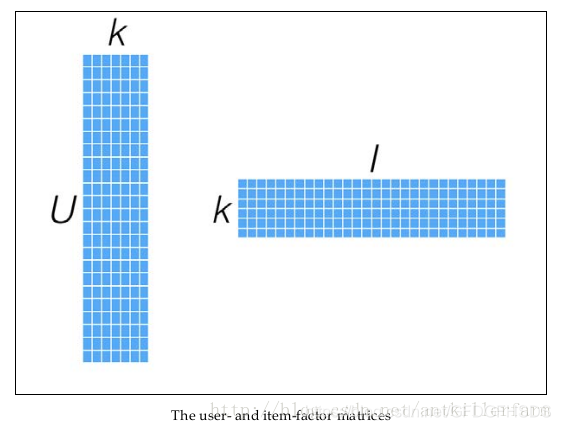
幸运的是,我们并不需要显式的定义这些关联维度,而只需要假定它们存在即可,因此这里的关联维度又被称为Latent factor。k的典型取值一般是20~200。
这种方法被称为概率矩阵分解算法(probabilistic matrix factorization,PMF)。ALS算法是PMF在数值计算方面的应用。
为了使低秩矩阵X和Y尽可能地逼近R,需要最小化下面的平方误差损失函数:
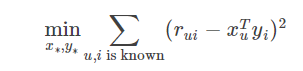
考虑到矩阵的稳定性问题,使用Tikhonov regularization,则上式变为:
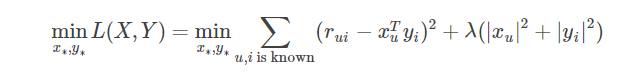
优化上式,得到训练结果矩阵。预测时,将User和Item代入,即可得到相应的评分预测值。
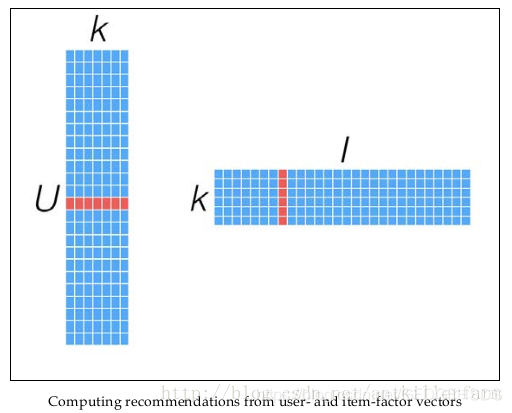
同时,矩阵X和Y,还可以用于比较不同的User(或Item)之间的相似度,如下图所示
ALS算法的缺点在于:
1.它是一个离线算法。
2.无法准确评估新加入的用户或商品。这个问题也被称为Cold Start问题。
ALS算法优化过程的推导


隐式反馈
用户给商品评分是个非常简单粗暴的用户行为。在实际的电商网站中,还有大量的用户行为,同样能够间接反映用户的喜好,比如用户的购买记录、搜索关键字,甚至是鼠标的移动。我们将这些间接用户行为称之为隐式反馈(implicit feedback),以区别于评分这样的显式反馈(explicit feedback)。
隐式反馈有以下几个特点:
1.没有负面反馈(negative feedback)。用户一般会直接忽略不喜欢的商品,而不是给予负面评价。
2.隐式反馈包含大量噪声。比如,电视机在某一时间播放某一节目,然而用户已经睡着了,或者忘了换台。
3.显式反馈表现的是用户的喜好(preference),而隐式反馈表现的是用户的信任(confidence)。比如用户最喜欢的一般是电影,但观看时间最长的却是连续剧。大米购买的比较频繁,量也大,但未必是用户最想吃的食物。
4.隐式反馈非常难以量化。

http://www.jos.org.cn/1000-9825/4478.htm



Spark中ALS的实现原理
Spark利用交换最小二乘解决矩阵分解问题分两种情况:数据集是显式反馈和数据集是隐式反馈。隐式反馈算法的原理是在显示反馈算法原理的基础上作一定的修改,所以在此我们只会具体讲解数据集为隐式反馈的算法。
推荐系统依赖不同类型的输入数据,最方便的是高质量的显式反馈数据,它们包含用户对感兴趣商品明确的评价。例如,大众点评中对餐厅的评价数据,但是显式反馈数据不一定总是找得到。好在推荐系统还可以从更丰富的隐式反馈信息中推测用户的偏好。隐式反馈类型包括购买历史、浏览历史、搜索模式甚至鼠标动作。例如,反复浏览某一个类型理财产品的用户可能喜欢这类理财产品。
了解隐式反馈的特点非常重要,因为这些特质使我们避免了直接调用基于显式反馈的算法。最主要的特点有如下几种:
(1)没有负反馈。通过观察用户行为,我们可以推测那个商品他可能喜欢,然后购买,但是我们很难推测哪个商品用户不喜欢。这在显式反馈算法中并不存在,因为用户明确告诉了我们他喜欢什么他不喜欢什么。
(2)隐式反馈是内在的噪音。虽然我们拼命的追踪用户行为,但是我们仅仅只是猜测他们的偏好和真实动机。例如,我们可能知道一个人的购买行为,但是这并不能完全说明偏好和动机,因为这个商品可能作为礼物被购买而用户并不喜欢它。
(3)显示反馈的数值表示偏好(preference),隐式回馈的数值表示信任(confidence)。
基于显示反馈的系统用星星等级让用户表达他们的喜好程度,例如一颗星表示很不喜欢,五颗星表示非常喜欢。基于隐式反馈的数值描述的是动作的频率,例如用户购买特定商品的次数。一个较大的值并不能表明更多的偏爱。但是这个值是有用的,它描述了在一个特定观察中的信任度。一个发生一次的事件可能对用户偏爱没有用,但是一个周期性事件更可能反映一个用户的选择。
(4)评价隐式反馈推荐系统需要合适的手段。
3.1显式反馈模型
潜在因素模型由一个针对协同过滤的交替方法组成,它以一个更加全面的方式发现潜在特征来解释观察的ratings数据。我们关注的模型由奇异值分解(SVD)推演而来。一个典型的模型将每个用户u(包含一个用户-因素向量ui)和每个商品v(包含一个用户-因素向量vj)联系起来。预测通过内积rij=(uiT)vj来实现。另一个需要关注的地方是参数估计。许多当前的工作都应用到了显式反馈数据集中,这些模型仅仅基于观察到的rating数据直接建模,同时通过一个适当的正则化来避免过拟合。公式如下:
在上述公式中,lambda是正则化的参数。正规化是为了防止过拟合的情况发生。这样,我们用最小化重构误差来解决协同推荐问题。我们也成功将推荐问题转换为了最优化问题。
3.2隐式反馈模型
在显式反馈的基础上,我们需要做一些改动得到我们的隐式反馈模型。首先,我们需要形式化由rij变量衡量的信任度的概念。我们引入了一组二元变量pj,它表示用户u对商品v的偏好。pj的公式如下:
另外,用户购买一个商品也并不一定是用户喜欢它。因此我们需要一个新的信任等级来显示用户偏爱某个商品。一般情况下,rij越大,越能暗示用户喜欢某个商品。因此,我们引入了一组变量Cj,它衡量了我们观察到pj的信任度。C_j一个合理的选择如下所示:
按照这种方式,我们存在最小限度的信任度,并且随着我们观察到的正偏向的证据越来越多,信任度也会越来越大。
我们的目的是找到用户向量以及商品向量vj来表明用户偏好。这些向量分别是用户因素(特征)向量和商品因素(特征)向量。本质上,这些向量将用户和商品映射到一个公用的隐式因素空间,从而使它们可以直接比较。这和用于显式数据集的矩阵分解技术类似,但是包含两点不一样的地方:(1)我们需要考虑不同的信任度。
(2)最优化需要考虑所有可能的u,v对,而不仅仅是和观察数据相关的u,v对。
