Spark–ALS推荐算法
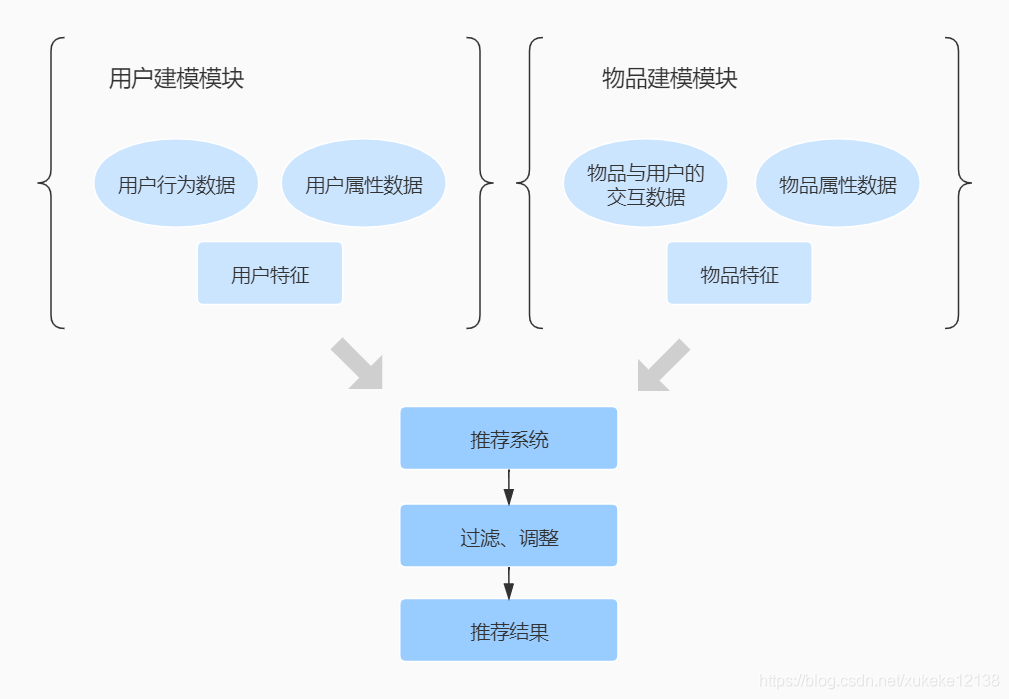
常用的推荐方法:
-
基于内容的推荐
将物品和用户分类。将已分类的物品推荐给对该物品感兴趣的用户。需要较多的人力成本。 -
基于统计的推荐
基于统计信息,如热门推荐。易于实现,但对用户的个性化偏好的描述能力较弱。 -
协同过滤推荐
可以达到个性化推荐,不需要内容分析,可以发现用户新的兴趣点,自动化程度高。
协同过滤 (Collaborative Filtering, 简称 CF)
一个简单的问题:如果你现在想看个电影,但你不知道具体看哪部,你会怎么做?
协同过滤的核心思想:
基于相关人群的观点进行推荐。
协同过滤的步骤:
收集数据——找到相似用户和物品——进行推荐
收集数据
历史行为数据,分为显性评分(Explicit Rating)和隐形评分(Implicit Rating)。
评分信息是显性信息,其他信息如浏览、关注、收藏等为隐性信息。
找到相似的用户和物品,即计算距离
-
欧几里得距离
-
皮尔逊相关系数
-
Cosine 相似度
-
Tanimoto 系数
进行推荐
- 基于用户(User CF)
- 基于物品(Item CF)
- 用户和物品混合(User-Item CF)
基于用户的协同过滤User CF
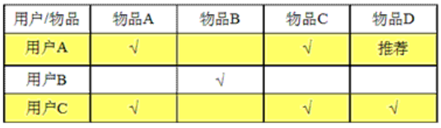
基于用户对物品的偏好,找相邻用户,将相邻用户喜欢的推荐给当前用户。适用于社交网站。
基于物品的协同过滤Item CF
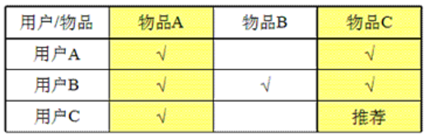
和User CF 类似,基于用户对物品的偏好找到相似的物品,然后根据用户的历史偏好,推荐相似的物品给他。适用于非社交网络网站中。
User-Item CF推荐算法
ALS推荐算法
ALS算法是User-Item CF,同时考虑了User和Item信息。是2008年以来用的比较多的协同过滤算法。已经集成到Spark的Mllib库中。
ALS推荐算法
将用户和物品的关系抽象为三元组(User, Item, Rating)。从而建立Rating矩阵。
但用户和物品数很大,评分的信息很少。
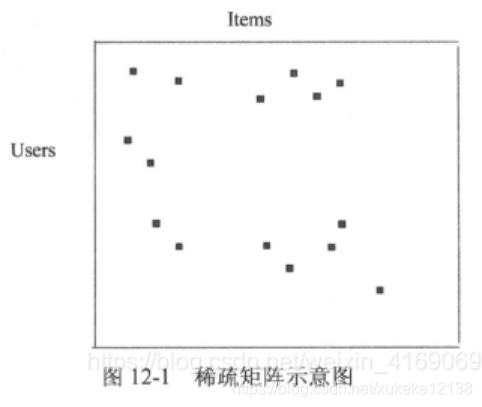
矩阵分解
将原本A(m * n)的稀疏矩阵分解,
得到X(m * k)和Y(n * k)的两个低秩矩阵。
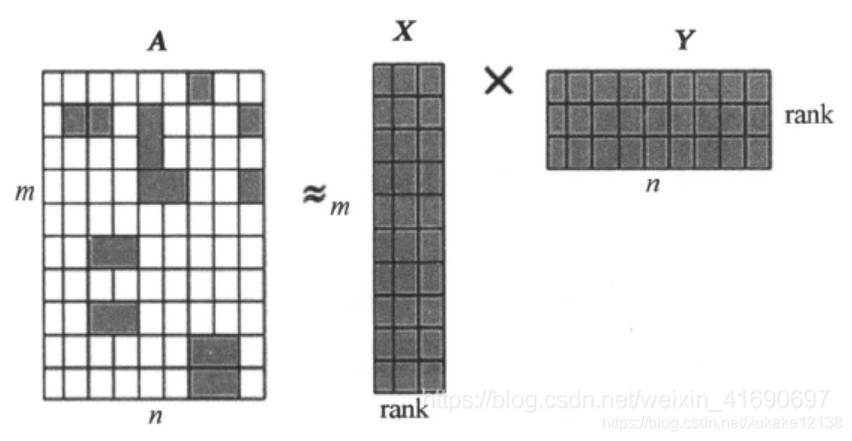
k<<min(n, m),从而达到数据降维的目的。
k的典型取值一般是20~200。
算法推导
对求导而言,X和Y矩阵是对称的。
(公式略)
因此可以将优化迭代过程简化。

在迭代过程交替优化X和Y,因此又被称作交替最小二乘算法(Alternating Least Squares,ALS)。
| 缺点: |
|---|
| 1.是一个离线算法。 |
| 2.冷启动(Cold Start) |
在Oracle官方文档中的函数解释:
使用ALS.train进行训练,训练完成后就会创建推荐引擎模型MatrixFactorizationModel.

针对用户推荐电影,使用MatrixFactorizationModel
.recommendProducts(user, num)进行推荐。