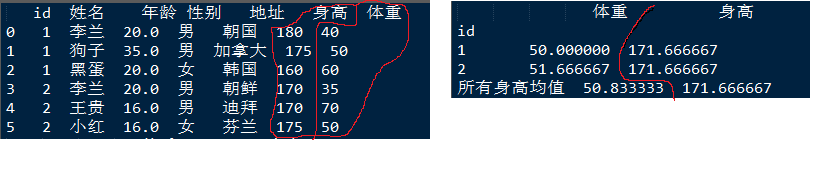
透视图函数df.pivot_table()
格式: pivot_table(data, values=None, index=None, columns=None, aggfunc=‘mean’, fill_value=None, margins=False, dropna=True, margins_name=‘All’, observed=False)
主要参数:
index:行分组键
columns:列分组键
values:分组的字段,(需要统计的列的属性名)列中的内容只能为数值型变量
aggfunc:聚合函数
margins:是否需要总计
fill_value:数值缺失时的填充值
若某一行没有数值会显示nan,
import pandas as pd
import numpy as np
df=pd.read_csv('my_csv.csv',header=0,\
encoding='gbk',dtype={'年龄':float})
print(df)
pd_pivo=pd.pivot_table(data=df,index="id",values=["身高",'体重'],aggfunc=np.mean,margins=True,margins_name="所有身高均值")
print(pd_pivo)
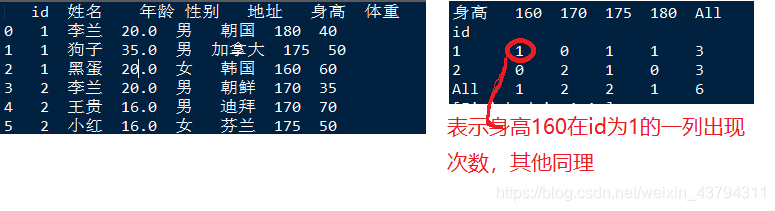
交叉表函数df.crosstab()
crosstab(index, columns, values=None, rownames=None, colnames=None, aggfunc=None, margins=False, margins_name=‘All’, dropna=True, normalize=False)
常用参数:
index:表示行索引,
columns:列索引,可以确定,数据在两个索引的交叉位置出现的次数
margins:是否需要总计
normalize:计算每个数据出现的占比值,值为All时表示占全部数据的比例,也是每一行列的 占比
import pandas as pd
import numpy as np
df=pd.read_csv('my_csv.csv',header=0,\
encoding='gbk',dtype={'年龄':float})
print(df)
print(pd.crosstab(index=df['id'],\
columns=df['身高'],margins=True))