Squeeze-and excitation network
introdutcion
motivation:当前一些研究表明,将attention机制引入网络中来捕获特征之间的空间相关性可增强CNN的表征,但本文希望建立channels之间的关系。
整体的SE block的图:

如上图所示:变换函数Ftr将输入x转化为特征U,U的shape为h*w*c。随后U经两个分支,在上面的分支中,U先经squeeze operation,产生通道级描述(a channel descriptor),再经an excitation operation,对每个通道产生权重。最后将产生的权重与下面分支出来的特征U相乘,得到SE block的输出。
实验数据集:imagenet
squeeze-and-excitation blocks
1.得到指定维度的输出U
Ftr:将输入X转换为shape=H*W*C的特征图U, Ftr定义为卷积操作。(对应到resnet中这一部分可以理解为一系列的卷积+激活+bn操作,目的是得到变化后的特征U)
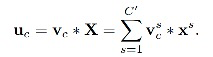
2.squeeze操作
目的:获取channel dependencies。squeeze这里执行了global average pooling,从而将h和w维度置为1,来得到C维向量z,z中每一个值:
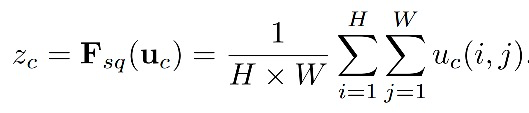
3.excitation操作
目的:fully capture channel-wise dependencies。
![]()
这里 δ是relu,增加非线性。W1的shape=C/r *c,W2的shape= C * C/r,可以理解为先对通道降维再升维,来减少参数计算。这里选用了两个FC层,具体就是a dimensionality-reduction(第一个fc) --relu (激活)-- a dimensionality-increasing layer(第二个fc)+sigmoid层(得到0-1间的分数),最终输出原channel维度大小的向量。
看代码发现,squeeze和exctitation都很简单啊~上代码:

这里的avg_pool对应squeeze操作,fc对应excitation操作,两步操作后得到的输出与原始输入的shape相同。
4.计算final output
![]()
5.将SE block引入到主流模型中
我们构建了SE-inception network和SE-resnet module

experiment
1.是否加SE block的对比


2.在imagenet上与state-of-the-art对比

个人想法:
1)resnet中,具体的se-layer是接在每个block中,最后一个bn层后面
2)在ucf101上测试过se,效果并不明显。一开始使用se时反而会掉点,后来过了段时间把se的每个通道权重打出来看了下,发现完全分布在0.5附近,且差异非常小。
