文章目录
Abstract
卷积算子(convolution operator)是卷积神经网络(cnn)的核心组成部分,它使网络能够通过融合每层局部接受域内的空间和通道信息来构建信息特征。广泛的先前研究已经调查了这种关系的空间组成部分,寻求通过增强整个特征层次的空间编码质量(enhancing the quality of spatial encodings throughout its feature hierarchy)来加强CNN的表示能力。在这项工作中,我们将重点放在通道关系(channel relationship)上,并提出了一种新的架构单元,我们称之为 “Squeeze-and-Excitation”(SE)块,该单元通过明确建模通道之间的相互依赖性,自适应地重新校准通道特征响应。这些块可以堆叠在一起,形成SENet架构,可在不同的数据集上极其有效地泛化。我们进一步证明,SE块在略微增加计算成本的情况下,为现有最先进的cnn带来了显著的性能改进。Squeeze-and-Excitation Networks 构成了我们2017年ILSVRC分类提交的基础,该分类提交获得了第一名,并将前5名的误差降低到2.251%,比2016年的获奖作品相对提高了25%。模型和代码可在 https://github.com/hujie-frank/SENet 上获得。
1 INTRODUCTION
在本文中,我们研究了网络设计的另一个方面——通道之间的关系。我们引入了一个新的架构单元,我们称之为挤压和激励(SE)块,其目标是通过显式地模拟其卷积特征通道之间的相互依赖性(by explicitly modelling the interdependencies between the channels of its convolutional features)来提高网络产生的表示的质量。为此,本文提出了一种机制,允许网络进行特征重校准(feature recalibration),通过这种机制,网络可以学习使用全局信息来有选择性地强调有信息量的特征,并抑制不太有用的特征。
SE 构建块的结构如图1所示。对于任意给定的将输入 X \mathbf{X} X 映射到 U \mathbf{U} U ,其中 U ∈ R H × W × C \mathbf{U} \in \mathbb{R}^{H \times W \times C} U∈RH×W×C 的特征映射的变换 F t r \mathbf{F}_{tr} Ftr,例如卷积,我们可以构造一个相应的 SE 块来执行特征重新校准(feature recalibration)。特征 U \mathbf{U} U 首先通过 squeeze 操作进行传递,该操作通过跨其空间维度( H × W H × W H×W)聚合特征图来产生通道描述符(channel descriptor)。这个描述子的功能是产生一个通道级特征响应的全局分布的嵌入(embedding),允许来自网络的全局感受野的信息被其所有层使用。聚合之后是一个 excitation 操作,该操作采取简单的自门控(self-gating mechanism)机制的形式,将嵌入作为输入,并产生每个通道调制权重(per-channel modulation weights)的集合。这些权重被应用于特征映射 U \mathbf{U} U 以生成SE块的输出,随后可以直接馈送到网络的后续层。
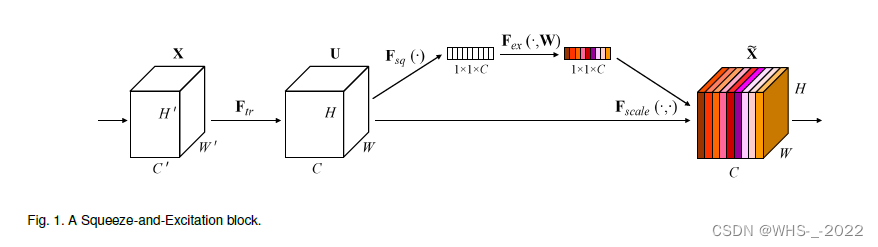
通过简单地堆叠SE块的集合,可以构建一个SE网络(SENet)。此外,这些SE块还可以在网络架构的一定深度范围内作为原始块的 drop-in replacement 。虽然构建模块的模板是通用的,但它在不同深度上所扮演的角色在整个网络中是不同的。在较早的层中,它以一种与类别无关的方式激发信息特征,加强共享的低级表示(strengthening the shared low-level representations)。在后面的层中,SE块变得越来越专门化,并以高度类特定的方式响应不同的输入(第7.2节)。因此,SE块执行的特征重新校准的好处可以通过网络积累。
在网络的较早层,模型通常专注于学习并提取更为通用和基础的特征,如边缘、颜色和纹理等。这些特征是多个类别共享的,不具有很强的类别特异性。在这一阶段,SE模块以一种类别无关的方式工作,激发有信息的特征,增强这些共享的低级表示。
然而,在网络的较深层,模型开始专注于学习更具类别特异性的特征,如特定物体的部分或者更复杂的形状。这是因为对于更深层的模型来说,它需要从更为抽象和高级的角度理解输入数据,以便进行准确的分类或预测。在这一阶段,SE模块开始变得更为专门化,响应不同类别的输入,使网络有能力捕捉并处理类别特定的信息。
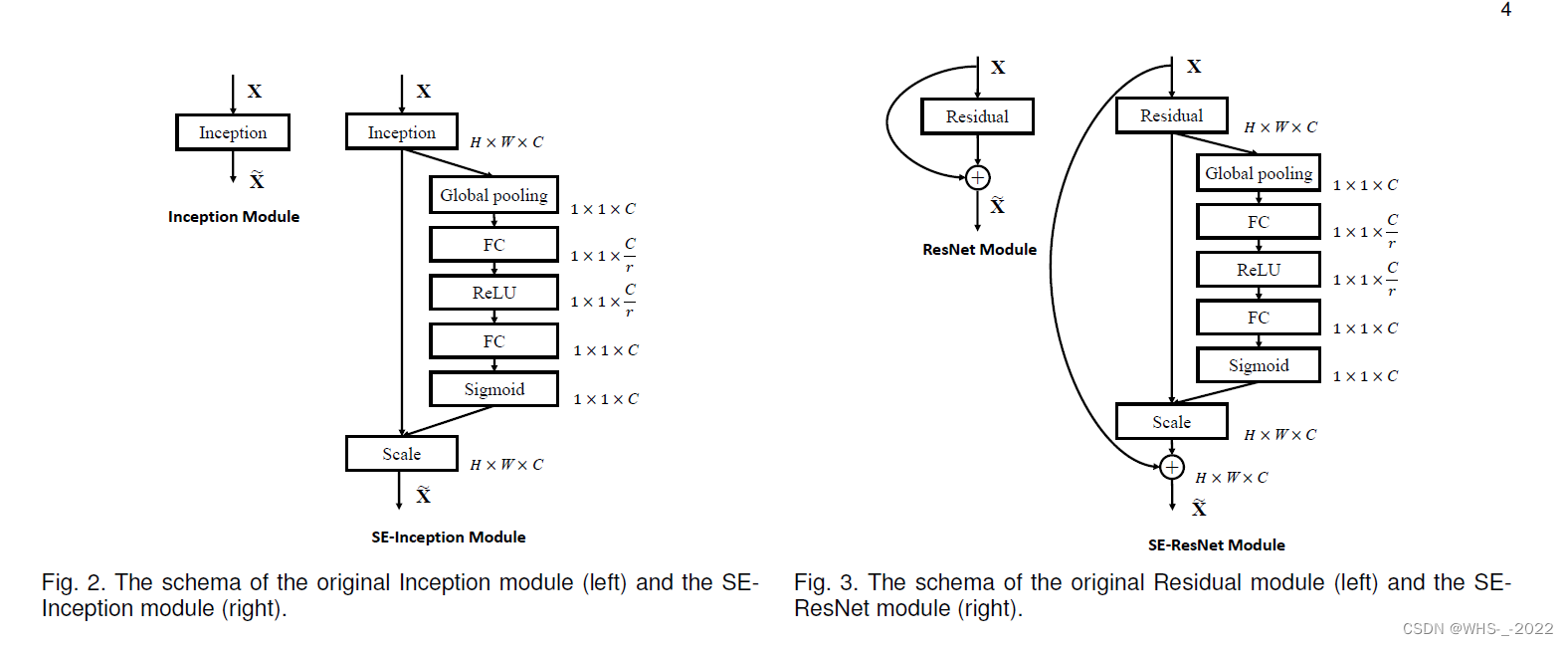
个人的简要理解以及概括就是,虽然就是卷积层中的参数是可以学习的,但是不同卷积核得到的结果重要性肯定是不一样的,所以可以通过加入通道注意力机制来提高性能。