1.序言
一个人的心有多大,世界就有多大,只是太多的人只能看到眼前的苟且,于是自己的一生就和苟且做斗争,最后也只是输给了自己的眼界而已。今天要带大家抓取的是锐仕方达猎头网站,里面有很多成功的招聘案例,这是一个静态网站,适合初学者或者缺乏项目实战经验者学习,为了方便大家理解和阅读,我做了详细的思路剖析。
2.项目实战剖析
网站分析:
目标源地址url:www.risfond.com/case/fmcg/2…
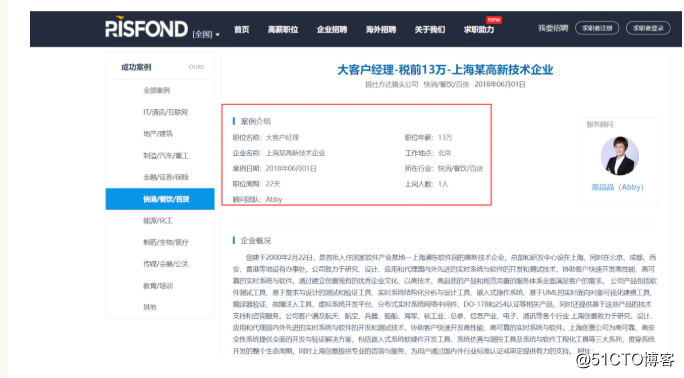
点击右键查看网页源代码,会发现上图方框内的内容在网页源代码(下图)是可以找到的!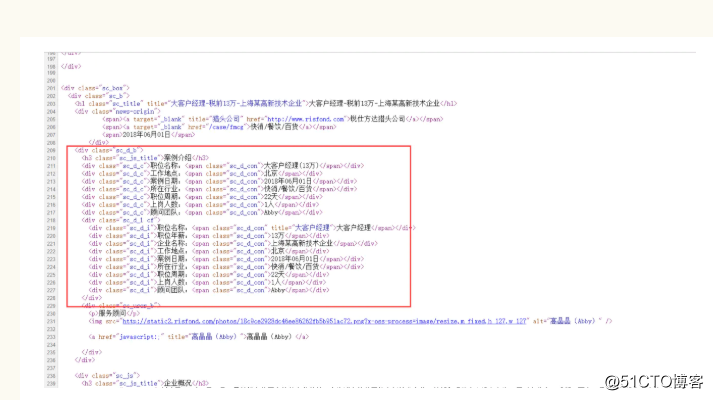
所以我们可以使用python内置的模块去访问网址,这里可以用requests或者urllib,因为之前介绍过requests模块的使用,这里我们就不做过多阐述,直接用urllib开战!虽然requests真的好用太多,但初学者其实也是需要学习内容的,技术无罪。接下来就开始我们的实战!
实战思路剖析:
1.获取网站源码
2.从源码解析所需要的数据
3.数据存储到excel
实战步骤讲解
第一步:获取网站源码
需要安装的库:pip install xlwt
第一步先导入urllib.request模块,记住python2跟3在模块上面使用是有区别的,这个模块就是如此。
如果我们想访问多个页面的话需要找寻网站的网址规律是怎么样的
http://www.risfond.com/case/fmcg/26700 ,http://www.risfond.com/case/fmcg/26701,
点击网址下一条就可以发现网址的规律,网址后面的数字是发生了改变的,
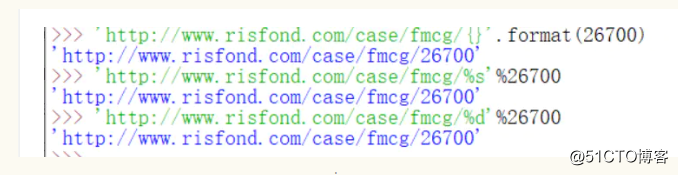
所以可以采用字符串格式化跟range函数,for in来进行使用,基础知识附带使用讲解下。
1.range函数可以生成一个整数序列,里面只有一个参数默认从0开始,2个参数是含头不含尾,示例如下:

2.字符串格式化,%s代表字符串,%d代表数字,当不知道用什么的情况下可以用%s代替,format是用{}.format()的方式做到字符串格式化的。
3.发送请求
for i in range(26700,26716):
url = 'http://www.risfond.com/case/fmcg/{}'.format(i)
html = urllib.request.urlopen(url).read().decode('utf-8')#urlopen打开网址 read 读取源代码
print(html)
复制代码第二步:从源码解析所需要的数据
这里用的是re正则表达式,可以根据一定的规则从源码中匹配出相对应的内容,打个比方说,我去水果店买西瓜,西瓜的特征是果绿色的外壳,红色的果肉,椭圆形状,都是根据这个特征去寻找的,在网站中间也是如此,获取的内容有着共同的标签比如div,而且都是在一样的html布局中,就可以写一个正则,用findall去从源码html中匹配出来。
page_list = re.findall(r'<div class="sc_d_c">.*?<span class="sc_d_con">(.*?)</span></div>',html)第三步:数据存储到excel
根据内容,我觉得存储到excel表格里面会比较好,所以对每行也写了一定的注释,大家可以参考下!
newTable = 'test2019.xls'#表格名称
wb = xlwt.Workbook(encoding='utf-8') #创建excel文件 设置编码
ws = wb.add_sheet('rsfd')#表名称
headData = ['职位名称','职位地点','时间','行业','招聘时间','人数','顾问']
for colnum in range(0,7):
ws.write(0,colnum,heData[colnum],xlwt.easyxf('font:bold on'))
index = 1
for j in range(0,len(items)):#计算数据有多少条
for i in range(0,7):
print(items[j][i])
ws.write(index,i,items[j][i])#行数 列数 数据
index+=1
wb.save(newTable)#保存
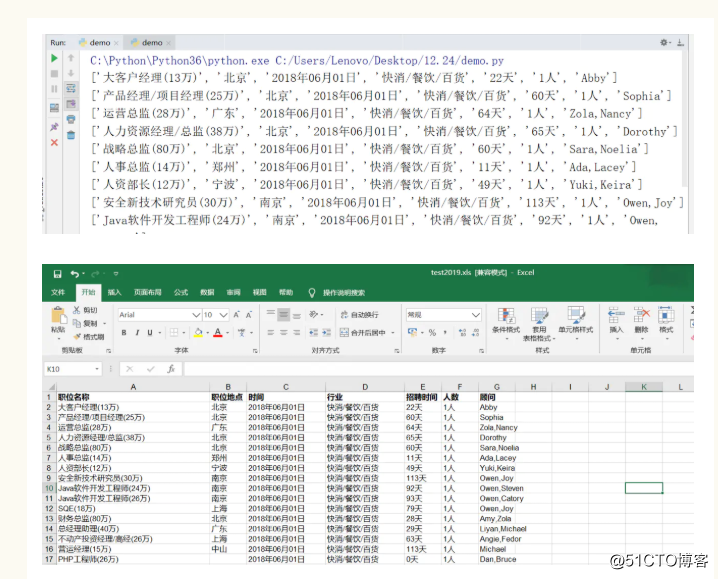
复制代码结果如下:我们可以看到所有的数据都被抓下来,并且存储到名为test2019的文件夹了。