前言:本文大水文一篇,大神请绕道。在正文之前,首先假设读者都已经了解SVM(即支持向量机)模型。
1. introduction
libsvm是台湾大学林智仁(Chih-Jen Lin)教授于2001年开发的一套支持向量机的工具包,可以很方便地对数据进行分类或者回归分析。使用时,只需要把训练数据按照它的格式打包,然后直接喂进去训练即可。我这里的数据是保存在mat文件的,数据怎么导入这里略去不说(以下内容提及的特征向量和一个样本是一回事)。
2. prepare
几个重要的数据结构
2.1
struct svm_problem
{
int l; // 记录样本的总数
double *y; // 样本所属的标签(+1, -1)
struct svm_node **x; // 指向样本数据的二维数组(即一个矩阵,行数是样本数,列数是特征向量维度)
};2.2
struct svm_node
{
int index;
double value;
};svm_node是用来存储单个样本数据的,打个比方说,svm_problem是一群羊,那么svm_node就是这一群羊中的一只。需要注意的是,svm_node的存储空间应该比特征数大一位,最后一位index值必须以-1结束。比如:
svm_node* node = new svm_node[1 + feature_size];
for (int j = 0; j < feature_size; j++)
{
node[j].index = j + 1;
node[j].value = xdata[j];
}
node[feature_size].index = -1;
return node;2.3
struct svm_parameter
{
int svm_type;// SVM的类型
int kernel_type;// 核函数
double degree;// 多项式参数
double gamma;// 核函数为poly/rbf/sigmoid的参数
double coef0;// 核函数为poly/sigmoid的参数
//下面是训练所需的参数
double cache_size;// 训练所需的内存MB为单位
double eps;// 训练停止的标准(误差小于eps停止)
double C;// 惩罚因子,越大训练时间越长
int nr_weight;// 权重的数目,目前只有两个值,默认为0
int *weight_label;// 权重,元素个数由nr_weight决定
double* weight;// C_SVC权重
double nu;
double p;
int shrinking;// 训练过程是否使用压缩
int probability;// 是否做概率估计
};
3. 训练你的模型
在vs建立一个工程,把libsvm里的svm.h和svm.cpp导入你的项目中。
3.1 准备训练数据
svm_problem prob;
svm_parameter param;
/*train_x,train_y是我已经导入的数据,分别是样本及其对应的类别标签*/
void init_svm_problem()
{
prob.l = train_size; // 训练样本数
prob.y = new double[train_size];
prob.x = new svm_node*[train_size];
svm_node* node = new svm_node[train_size*(1 + feature_size)];
prob.y = vec2arr(train_y);
// 按照格式打包
for (int i = 0; i < train_size; i++)
{
for (int j = 0; j < feature_size; j++)
{ // 看不懂指针就得复习C语言了,类比成二维数组的操作
node[(feature_size + 1) * i + j].index = j + 1;
node[(feature_size + 1) * i + j].value = train_x[i][j];
}
node[(feature_size + 1) * i + feature_size].index = -1;
prob.x[i] = &node[(feature_size + 1) * i];
}
}3.2 设置训练参数
void init_svm_parameter()
{
param.svm_type = C_SVC; // 即普通的二类分类
param.kernel_type = RBF; // 径向基核函数
param.degree = 3;
param.gamma = 0.01;
param.coef0 = 0;
param.nu = 0.5;
param.cache_size = 1000;
param.C = 0.09;
param.eps = 1e-5;
param.p = 0.1;
param.shrinking = 1;
param.probability = 0;
param.weight_label = NULL;
param.weight = NULL;
}上面的C和gamma是我进行调优过的,用于你的数据时应该重新调整。
3.3 进行训练
int main()
{
load_data(); // 导入训练及测试数据
init_svm_problem(); // 打包训练样本
init_svm_parameter(); // 初始化训练参数
svm_model* model = svm_train(&prob, ¶m);
svm_save_model("model", model); // 保存训练好的模型,下次使用时就可直接导入
int acc_num = 0; // 分类正确数
//svm_model* model = svm_load_model("model");
for (int i = 0; i < test_size; i++)
{
svm_node* node = init_test_data(vec2arr(xdata[i]));
double pred = svm_predict(model, node);
if (pred == label[i])
acc_num++;
}
cout << "accuracy: " << acc_num*100.0 / test_size << "%" << endl;
cout << "classification: " << acc_num << " / " << test_size << endl;
return 0;
}3.4 训练及测试结果
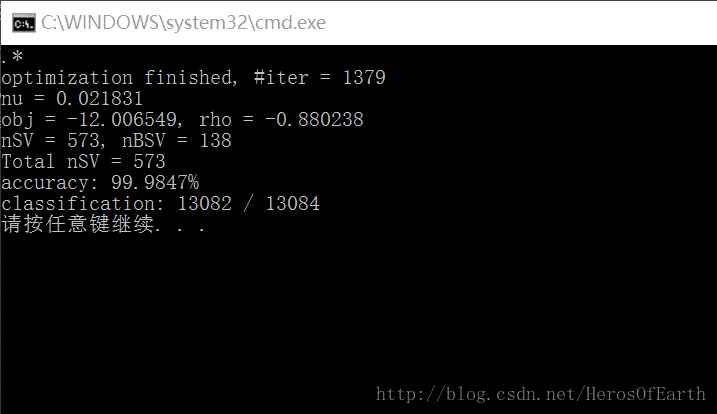
正确率几乎达到100%,可见分类效果是非常好的(这也是我一直钟情于SVM的原因)!
训练你的模型吧!
