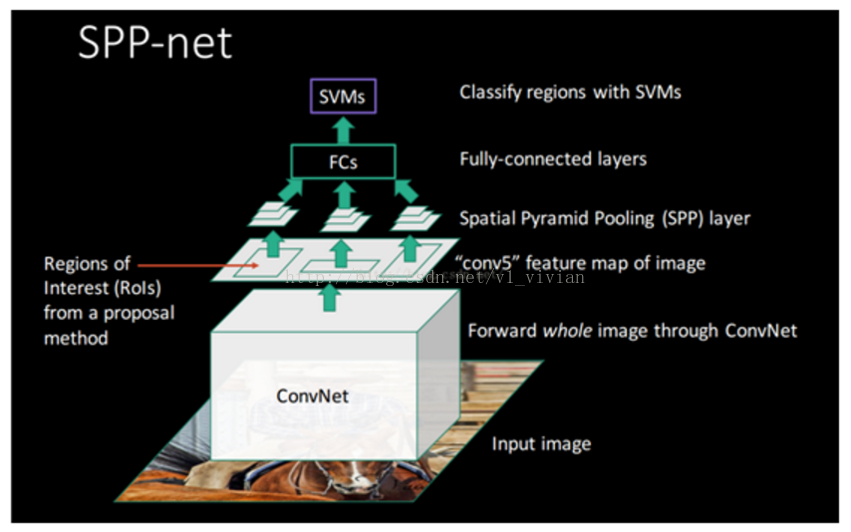
SPPNet不得不说,对后续的Fast-RCNN,Faster-RCNN都起到了举足轻重的作用。SPPNet主要解决的是固定输入层尺寸的这个限制,也从各个方面说明了不限制输入尺寸带来的好处。文章在一开始的时候就说明了目前深度网络存在的弊端:如果固定网络输入size的话,要么选择crop策略,要么选择warp策略。crop策略就是从一个大图中裁剪出固定尺寸的大小来,这样做有可能crop出object的一个部分而无法准确训练出类别,采用warp策略就是把一个BBOX直接resize成固定尺寸,这样会改变物体的宽高比,使得训练精度下降。

接着分析出需要固定大小的原因主要是网络存在全连接层,那如何去做才能使得网络不受输入尺寸的限制呢?Kaiming He 大神就想出,用不同尺度的pooling 来pooling出固定尺度大小的feature map,这样就可以不受全连接层约束任意更改输入尺度了。
核心思想

SPP-Net在最后一个卷积层后,接入了金字塔池化层,使用这种方式,可以让网络输入任意的图片,而且还会生成固定大小的输出。
金字塔池化层
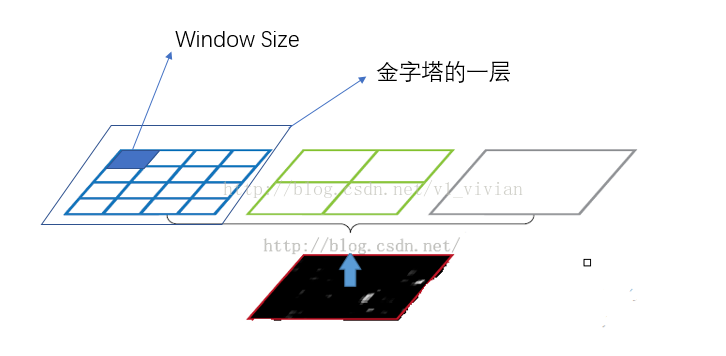
黑色图片代表conv5的特征图,接下来我们用不同大小的块来提取特征,分别是4*4,2*2,1*1,将这三张网格放到下面这张特征图上,就可以得到16+4+1=21种不同的块(Spatial bins),我们从这21个块中,每个块提取出一个特征,这样刚好就是我们要提取的21维特征向量。这种以不同的大小格子的组合方式来池化的过程就是空间金字塔池化(SPP)。比如,要进行空间金字塔最大池化,其实就是从这21个图片块中,分别计算每个块的最大值,从而得到一个输出单元,最终得到一个21维特征的输出。Conv5计算出的feature map也是任意大小的,现在经过SPP之后,就可以变成固定大小的输出了。
于是我们可以看出金字塔池化的意义,对于任意尺寸的图片,我们可以一直进行卷积、池化,直到网络即将与fc层相连的时候,就要使用金字塔池化,使得任意大小的特征图都能转化为相同大小的特征向量,这就是空间金字塔池化的意义(多尺度特征提取出固定大小的特征向量。)
网络训练阶段
论文中将网络的训练分为两部分:一种是single-size,一种是Multi-size。
single-size:
理论上来说,SPP-Net支持直接以多尺度的原始图片作为输入后直接BP即可。实际上,caffe上的实现为了计算方便,GPU,CUDA等比较适合固定尺寸的输入,所以训练的时候输入是固定了尺度的。
以224*224的输入为例:
在conv5之后的特征图为:13x13(a*a)
金字塔层bins: n*n
将pooling层作为sliding window pooling。
windows_size=[a/n] 向上取整 , stride_size=[a/n]向下取整。
例如论文中给出的参数如下:

对于pool 3*3: sizeX=5 的计算公式是:[13/3]向上取整=5 ,stride = 4的计算公式是:[13/3]向下取整。
如果输入改成180x180,这时候conv5出来的reponse map为10x10,类似的方法,能够得到新的pooling参数。
对于Multi-size training即就是:使用两个尺度进行训练:224*224 和180*180
训练的时候,224x224的图片通过crop得到,180x180的图片通过缩放224x224的图片得到。之后,迭代训练,即用224的图片训练一个epoch,之后180的图片训练一个epoch,交替地进行。
两种尺度下,在SSP后,输出的特征维度都是(9+4+1)x256,参数是共享的,之后接全连接层即可。
论文中说,这样训练的好处是可以更快的收敛。
在这里之前产生了一个阅读误区,就是这个公式计算7*7的出现了问题,后来实际代码中进行了zero-padding操作。
网络推断阶段
输入为任意大小的图片。
SPP用于目标检测
整个过程如下:
1.通过SS方法产生region proposal
2.将一整张图片送入SPPNet中,产生整张图片的特征图。然后找到这张图片的每个region proposal对应的特征图区域,对这个区域进行空间金字塔池化后进行后面的训练。
3.最后一步与RCNN一样,接一个SVM➕位置精修。
region proposal如何映射到feature map:
我们知道,在原图中的proposal,经过多层卷积之后,相对位置是不会发生变化的,现在要解决的问题就是如何能够将原图上的proposal,映射到卷积之后得到的特征图上,因为在此之后我们要对proposal进行金字塔池化。

对于映射关系,论文给了一个公式:
假设(x’,y’)表示特征图上的坐标点,坐标点(x,y)表示原输入图片上的点,那么它们之间有如下转换关系,这种映射关心与网络结构有关: (x,y)=(S*x’,S*y’)
反过来,我们希望通过(x,y)坐标求解(x’,y’),那么计算公式如下:
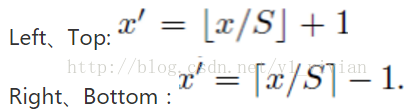
其中S就是CNN中所有的strides的乘积,包含了池化、卷积的stride。
比如,对于下图的集中网络结构,S的计算如下:
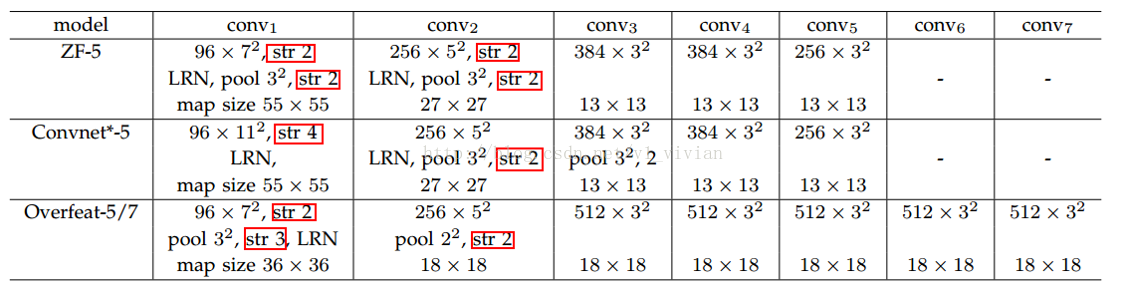
论文中使用的是 ZF-5: S=2*2*2*2=16
Overfeat-5/7 : S =2*3*2 =12
检测算法
对于检测算法,论文中是这样做的:使用ss生成2k个候选框,缩放图像min(w,h)=s之后提取特征,每个候选框使用一个4层的空间金字塔池化特征,网络使用的是ZF-5的SPPNet形式。之后将12800d的特征输入全连接层,SVM的输入为全连接层的输出。
这个算法可以应用到多尺度的特征提取:先将图片resize到5个尺度,480,576,688,864,1200,加自己6个。然后在map window to feature map一步中,选择ROI框尺度在{6个尺度}中大小最接近224x224的那个尺度下的feature maps中提取对应的roi feature。这样做可以提高系统的准确率。