性能测试的作用:提供有效的容量规划能力、系统风险识别、系统瓶颈识别、性能调优指导
压测模型(简单):压力工具–>Nginx–>应用1、2…–>Redis、DB
压流流程:性能需求指标–>性能方案–>性能监控–>性能场景执行–>性能结果/报告
详细概念介绍
性能需求指标
- 时间指标:响应耗时,258原则已经不能满足现在的互联网需求,现在的需求比如:500ms
- 容量指标:并发量、在线用户数 最终落库的数据量
- 资源利用率指标:安全可靠范围的Cpu、内存等,可与运维确认
如何进行性能需求分析与测试设计?
例子:产品提供PV/UV 1000w/天、运维提供监控–>小时/分钟、峰值数据【注:PV:页面浏览量或者点击量/天、UV:访客数量/天】
- 设计并发量:UV * 80% /(4*3600)
- 流量概念:
- 用户行为拆分【电商为例】:用户首页浏览、进入商品详情页、加购物车、下单,根据线上监控数据,确认核心行为场景,场景的接口确认,制定请求比例
- 抽取主要核心接口:抽取行为比例,作为接口设计比例
- 如果是新产品:竞品数据参考、找到核心场景、抓包确定核心接口
28原则,是没有一切有效数据的基础上的原则,根据实际的系统分析流量值才可取,比如:凌晨1点到早上5点半可能基本上用户量是没有的
需求分析注意:需求确认后需要公示项目组
性能模型
- 业务模型:用户行为流程、测试操作匹配业务模型、流程拆分、相同的流程对于不同的系统实现来说压测的指标会有不同
- 监控模型:
性能方案

- 测试环境:线上、线下【系统拓扑图】
- 测试数据、测试模型:基于业务模型,设计用户数据、订单数据等
- 性能指标:性能需求指标
- 压力策略:递增策略,一定的并发数、预计TPS值、持续一段时间15分钟,递增加压
- 准入准出:根据性能标准,系统做适配,满足准入准出条件
- 进度风险
性能监控:客户端监控+服务端监控【系统架构、系统监控、中间件、缓存、队列、负载均衡、熔断限流、链路监控等】
性能场景执行
- 基准场景:新系统上线、重构、性能调优专项。
- 容量场景
- 稳定性场景
性能结果/报告:场景结果整理、监控结果整理、性能整体分析、性能结论、优化建议、运维建议
场景结果整理、监控结果整理、性能整体分析、性能结论、优化建议、运维建议
多次性能测试调优,得出最终结果
性能拐点:并发数、资源利用率、吞吐量(TPS、QPS)、响应时间
随着并发数增加,到达第一个拐点,资源利用率与吞吐量增加到平稳状态–>容量规划的最优值
继续增加并发数,响应时间由平稳陡增,可能是服务端某些资源,如:mysql的响应耗时增加,导致–>当前系统极值
测试数据准备和构造
- 接口请求参数:自己构造/日志获取/上下关联
- 数据表数据填充:jmeter构造、mysql构造
- 多接口,结合业务场景设计请求比例(PV)
对于多系统、多场景的造数据来说,可以进行单系统压测、再多系统压测。
性能指标预期
- QPS每秒请求数
- 请求响应时间(最小、最大、平均)
- 最大并发数
- 错误率
- 机器性能:cpu idle 30% 、memory无剧烈抖动或者飙升
- 压测过程接口功能是否正常
不同性能测试方式下指标预期会有差异
发压工具准备
- jmeter
- 脚本编写
- 启压:./jmetr -n -t hb.jmx -l hb.jtl【windows 在jmeter的bin目录下执行】
命令启动加压
压测过程说明/共识
- 测试前环境监察:记录机器参数
- 起压:根据被压情况,调节并发量到适合的情况
- 查看记录各项性能指标
nginx日志查看每秒请求数
查看nginx错误请求
查看机器参数:cpu idle、mem等
查看db、cache等数据是否写入正常
访问接口,查看功能是否正常
分工合作
结果分析和测试报告
基准测试:验证单业务单用户的场景执行,找到单业务最大的TPS和最优的响应时间
容量测试:验证最大的TPS和最优的响应时间之后,继续加压,找到服务的极值
以首页为例说明TPS与QPS,首页共有4个请求接口,将其放进一个事务里,请求一次
TPS:记一次TPS
QPS:记发送4个请求
也就是一个TPS包含4个QPS
实例–测试全过程:
- 被测系统有哪些?
- 子系统划分:前后、后台、、C端、B端
- 项目介绍:包括什么系统,基于什么实现,前台、后台业务模块包括哪些?
- 模块对应的接口请求是哪些?
- 整体服务存储?mysql、Redis、Oracle,,压测过程中不同的存储方式会有不同的监控方案
API文档–>集成 swagger ui,初步的接口调试与使用
流量的预估模型:
生产环境取数据:流量情况、确认场景比例(但不会覆盖所有的场景,核心场景即可,根据平均值算出的比例,大于1%或其他,注意重要的写接口要保留)
查看nginx日志情况,统计相关的流量:
拿到nginx机器的日志路径 var/log/nginx/access.log
还有一个error.log日志文件
分析日志内容,拿到页面请求地址统计信息
nginx的工作原理须知?测试须知
确认核心接口的服务是哪些?
比如注册拉新登陆,核心接口:注册、获取验证码、登陆,接口场景比例1:1:1,需保存鉴权信息
分析实际业务场景与开发代码,确认mysql服务、redis服务的有几个读写调用,便于监控。
生成验证码:写入Redis
public CommonResult generateAuthCode(String telephone) {
StringBuilder sb = new StringBuilder();
Random random = new Random();
for(int i=0;i<6;i++){
sb.append(random.nextInt(10));
}
//验证码绑定手机号并存储到redis
redisService.set(REDIS_KEY_PREFIX_AUTH_CODE+telephone,sb.toString());
redisService.expire(REDIS_KEY_PREFIX_AUTH_CODE+telephone,AUTH_CODE_EXPIRE_SECONDS);
return CommonResult.success(sb.toString(),"获取验证码成功");
}
使用注册码发起注册:读取redis,验证验证码,写入mysql注册数据
public CommonResult register(String username, String password, String telephone, String authCode) {
//验证验证码
if(!verifyAuthCode(authCode,telephone)){
return CommonResult.failed("验证码错误");
}
//查询是否已有该用户
UmsMemberExample example = new UmsMemberExample();
example.createCriteria().andUsernameEqualTo(username);
example.or(example.createCriteria().andPhoneEqualTo(telephone));
List<UmsMember> umsMembers = memberMapper.selectByExample(example);
if (!CollectionUtils.isEmpty(umsMembers)) {
return CommonResult.failed("该用户已经存在");
}
//没有该用户进行添加操作
UmsMember umsMember = new UmsMember();
umsMember.setUsername(username);
umsMember.setPhone(telephone);
umsMember.setPassword(passwordEncoder.encode(password));
umsMember.setCreateTime(new Date());
umsMember.setStatus(1);
//获取默认会员等级并设置
UmsMemberLevelExample levelExample = new UmsMemberLevelExample();
levelExample.createCriteria().andDefaultStatusEqualTo(1);
List<UmsMemberLevel> memberLevelList = memberLevelMapper.selectByExample(levelExample);
if (!CollectionUtils.isEmpty(memberLevelList)) {
umsMember.setMemberLevelId(memberLevelList.get(0).getId());
}
memberMapper.insert(umsMember);
umsMember.setPassword(null);
return CommonResult.success(null,"注册成功");
}
用户登录:一次计算、一次读取mysql
public String login(String username, String password) {
String token = null;
//密码需要客户端加密后传递
try {
UserDetails userDetails = loadUserByUsername(username);
if(!passwordEncoder.matches(password,userDetails.getPassword())){
throw new BadCredentialsException("密码不正确");
}
UsernamePasswordAuthenticationToken authentication = new UsernamePasswordAuthenticationToken(userDetails, null, userDetails.getAuthorities());
SecurityContextHolder.getContext().setAuthentication(authentication);
token = jwtTokenUtil.generateToken(userDetails);
} catch (AuthenticationException e) {
LOGGER.warn("登录异常:{}", e.getMessage());
}
return token;
}
实例:
1.用户鉴权信息
2.首页流量比例分配
3.获取分类parentid信息,不建议写死数据,尽量模拟真实场景,打散数据。【不确定当同一个数据大量请求后会有什么影响。】
大批量清理数据需要注意:编写sql加limit,避免对数据库造成隐患、慢查询等!
负载测试:系统资源维持在某个特定的值,看对系统处理请求的影响,比如:CPU维持在70%
疲劳测试:在某个压力下长时间的稳定性测试
error率不为0 是正常现象,根据线上监控或者各个渠道找到可以接受的阈值,作为标准,一般不超过1%。
性能测试环境的搭建:线上、线下。
线下环境搭建最好与线上的机器配置类似或者同比缩放,机器的配比关系与线上尽量保持一致或类似,整体的拓扑结构与线上基本保持在这里插入代码片一致。
性能测试环境与业务测试环境:性能测试环境对于测试环境要求很高,可以分开。线上:压测流量不要影响到正式的流量,比如:可以单独几台机器进行压测。
鉴权信息:可能放在header、也可能放在cookie
JMeter小贴士:
1.使用命令行执行压测
2.尽量避免使用Listener【找到最优收集信息方案】
3.增加JVM Heap Space—后续介绍
4.尽量用最新版本的jmeter Version,性能较好,功能较新
5.慎用正则
6.每台机器尽可能模拟合理的线程数。一般来说,网络连接会是瓶颈,JVM在2000线程数以上的情况下,不会保持一个很好的压力表现。也就是1台128G机器,不如10台8G的机器去模拟压测
7.在机器性能平均的情况下去做分布式压测,如果当前情况下只有一台128G的机器,可以考虑使用docker,构建多个jmeter容器进行压测。不建议用16G以上机器,因为JVM在这种情况下不能很好的工作
8.report尽量在执行结束生成。如果有influxdb+Grafana可以不考虑这点。
9.简单场景的压测瓶颈可能会出现在网络连接上,复杂场景的压测瓶颈更可能会出现在cpu、内存上
10.BeanShell不推荐,推荐Groovy,从性能角度看
11.对于分布式压测来说,单台master控制20-30台左右slave机器,按照1台机器1000threads,最多可以并发20k-30k并发量。因为master与slave之间会相互传数据,RMI协议限制JMeter。
这种情况下的解决办法:可以创建多个相同group,但这种做法的弊端是需要人为统计聚合数据,从服务端角度出发是没有影响的。
12.要监控发压机器和被测机器
13.压测机与被压机器尽量在同一网络,网络带宽
14.根据机器内存情况,与JVM,可以动态调整MaxMetaspaceSize、MaxHeapSize的值,发压机性能一般,可以使用默认至。反之可以重新设置一下。这边的配置与jmeter中CSV文件、变量的多少决定的,如果数据量较大,可以适当加大。-gc情况
15.每台发压机的配置可以设置成一样的,推荐
压测报告
1.需求背景
2.压测方案
用户场景
接口比例
针对缓存,开启缓存、关闭缓存的情况
单接口压测性能
场景压测性能
3.部署方案
docker方式部署、Service、MySQL、Nginx混部在同一台机器
cpu情况列出
cat /proc/cpuinfo
mem情况列出
cat /proc/meminfo
MySQL 版本
Nginx 版本
…
3.1线上部署
3.2压测环境部署
3.3机器资源
备注:线上与线下的区别点
4.性能数据
1.并发用户数增长方案
2.压测过程中关联服务的压测指标
3.相关Grafana图表链接贴出
4.指出瓶颈问题
5.总结
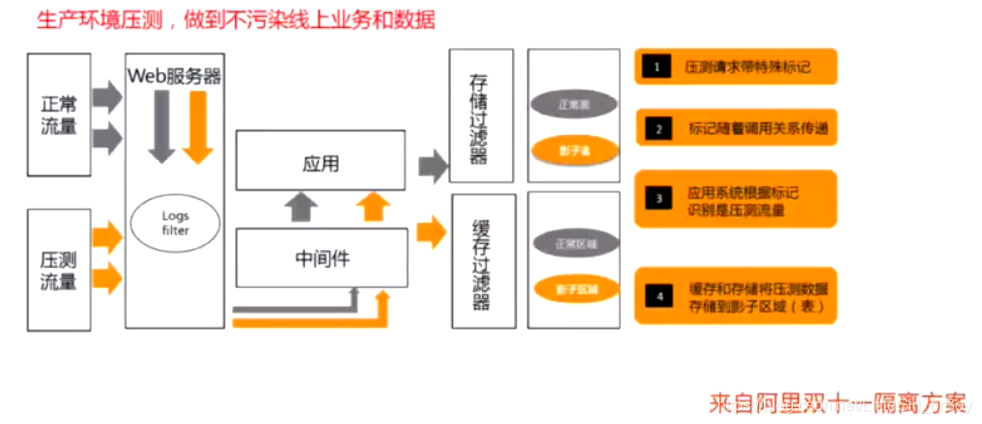
全链路性能测试介绍
线下的压测结果没有办法真实的反应线上的压测结果
链路情况:网络接入层–网关层–应用/中间件or 应用/中间件生产集群、应用/中间件测试集群–数据中间件–DB【影子表/库、正常表/库】
如何做?
1.压测流量日志过滤,识别压测流量与生产环境流量
2.对于写数据做生产数据与压测数据隔离。比如针对DB:影子表、正常表,针对kafaka会有一个test-topic区分,针对redis两者落库相同,但key会做些区分,且过期时间设置相对短
3.依赖第三方服务。mock服务,模拟延迟的情况
4.关注各种监控指标、没有办法做隔离的数据,需要给出数据清理的方案,配合DBA完成
关于高并发秒杀的测试
1.基于相对较大的步长加压,找到最大并发值
2.一次并发1中得到的最大并发值*80%,看系统情况–瞬时流量
