1.xml解析:Dom解析,SAX解析
2.Dom4j
3.XPath解析
一。XML
eXtendside markup language 可扩展的标记语言
XML
指可扩展标记语言(
EXtensible Markup Language
)
XML
是一种
标记语言
,很类似
HTML
,
HTML
文件也是
XML
文档
XML
的设计宗旨是
传输数据
,而非显示数据
XML
标签没有被预定义。您需要
自行定义标签
。
XML
被设计为具有
自我描述性
(
就是易于阅读
)
。
XML
是
W3C
的推荐标准
W3C
在
1988
年
2
月发布
1.0
版本,
2004
年
2
月又发布
1.1
版本,但因为
1.1
版本不能向下兼容
1.0
版本,所以
1.1
没
有人用。同时,在
2004
年
2
月
W3C
又发布了
1.0
版本的第三版。我们要学习的还是
1.0
版本。
xml与Html的差异“
XML
不是
HTML
的替代。
XML
和
HTML
为不同的目的而设计。
XML
被设计为传输和存储数据,其焦点是数据的内容。
HTML
被设计用来显示数据,其焦点是数据的外观。
HTML
旨在显示信息,而
XML
旨在传输信息。
xml的格式:
<?xml version="1.0" encoding="utf-8" ?>
<person id="abc">
<name>王三</name>
<age>12</age>
<sex>男</sex>
</person>xml的作用:
可以用来保存数据
可以用来做配置文件
数据传输载体
XML
在企业开发中主要有两种应用场景:
1
)
XML
可以存储数据
,
作为数据交换的载体
(
使用
XML
格式进行数据的传输
)
。
2
)
XML
也可以作为配置文件,例如后面框架阶段我们学习的
Spring
框架的配置
(applicationContext.xml)
都是通过
XML
进行配置的(企业开发中经常使用的)
3.xml的组成元素
XML
文件中常见的组成元素有
:
文档声明、元素、属性、注释、转义字符、字符区。
3.1文档声明:
<?xml version="1.0" encoding="utf-8" ?>1. 使用 IDE 创建 xml 文件时就带有文档声明 .2. 文档声明必须为 <?xml 开头,以? > 结束3. 文档声明必须从文档的 0 行 0 列位置开始4. 文档声明中常见的两个属性:version :指定 XML 文档版本。必须属性,这里一般选择 1.0 ;encoding :指定当前文档的编码,可选属性,默认值是 utf-8 ;
3.2 元素element:
格式 1: <person></person>格式 2: <person/>1. 元素是 XML 文档中最重要的组成部分;2. 普通元素的结构由开始标签、元素体、结束标签组成。3. 元素体:元素体可以是元素,也可以是文本,例如: <person><name> 张三 </name></person>4. 空元素:空元素只有标签,而没有结束标签,但元素必须自己闭合,例如: <sex/>5. 元素命名区分大小写不能使用空格,不能使用冒号不建议以 XML 、 xml 、 Xml 开头6. 格式化良好的 XML 文档,有且仅有一个根元素。
3.3 属性
<person id = "110" >1. 属性是元素的一部分,它必须出现在元素的开始标签中2. 属性的定义格式:属性名 =“ 属性值 ” ,其中属性值必须使用单引或双引号括起来3. 一个元素可以有 0~N 个属性,但一个元素中不能出现同名属性4. 属性名不能使用空格 , 不要使用冒号等特殊字符,且必须以字母开头
3.4 注释
<!-- 注释内容 -->XML 的注释与 HTML 相同,既以 <! -- 开始, -- > 结束。
3.5 转义字符:
XML
中的转义字符与
HTML
一样。因为很多符号已经被文档结构所使用,所以在元素体或属性值中想使用这些符号
就必须使用转义字符(也叫实体字符),例如:
">"
、
"<"
、
"'"
、
"""
、
"&"
。

注意:严格地讲,在
XML
中仅有字符
"<"
和
"&"
是非法的。省略号、引号和大于号是合法的,但是把它们替换为实
体引用是个好的习惯。
示例:
假如您在 XML 文档中放置了一个类似 "<" 字符,那么这个文档会产生一个错误,这是因为解析器会把它解释为新元素的开始。因此你不能这样写<message> if salary < 1000 then </message>为了避免此类错误,需要把字符 "<" 替换为实体引用,就像这样:<message> if salary <; 1000 then </message>
3.6.字符区
<![CDATA[文本数据]]>
1. CDATA
指的是不应由
XML
解析器进行解析的文本数据(
Unparsed Character Data
)
2. CDATA
部分由
""
结束;
3.
当大量的转义字符出现在
xml
文档中时,会使
XML
文档的可读性大幅度降低。这时如果使用
CDATA
段就会好一
些。
<! [ CDATA [if salary < 1000 then]]注意:CDATA 部分不能包含字符串 "]]>" 。也不允许嵌套的 CDATA 部分。标记 CDATA 部分结尾的 "]]>" 不能包含空格或折行
4.XML的文件的约束
在xml技术里,可以编写一个文档来约束一个xml文档的书写规范,这就是xml规范
常见的xml约束:dtd,Schema
(1)DTD约束
DTD是文档类型定义;Document Type Definition ,DTD 可以定义在xml 文档中出现的元素,这些元素出现的次序,他们如何相互嵌套,以及XML文档结构的其他详细信息、
语法:
文档声明:
1.
内部
DTD
,在
XML
文档内部嵌入
DTD
,只对当前
XML
有效。
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE 根元素 [...// 具体语法 ]> <!-- 内部 DTD-->< 根元素 ></ 根元素 >
2.
外部
DTD—
本地
DTD
,
DTD
文档在本地系统上,企业内部自己项目使用。
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE 根元素 SYSTEM "bookshelf.dtd"> <!-- 外部本地 DTD-->< 根元素 ></ 根元素
3.
外部
DTD—
公共
DTD
,
DTD
文档在网络上,一般都有框架提供
,
也是我们使用最多的
.
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE web-app PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN""http://java.sun.com/dtd/web-app_2_3.dtd"><web-app></web-app>
元素的声明:
约束元素的嵌套层级
语法:
<!ELEMENT 父标签 (子标签 1 ,子标签 2 , … ) >代码<!ELEMENT 书架 ( 书 +)> <!-- 约束根元素是 " 书架 " , " 书架 " 子元素为 " 书 " , “+” 为数量词,请看下面介绍 --><!ELEMENT 书 ( 书名 , 作者 , 售价 )> <!-- 约束 " 书 " 子元素依次为 “ 书名 ” 、 “ 作者 ” 、 “ 售价 ” , “+” 书元素至少 1次 -->
约束元素体里面的数据
<!ELEMENT 标签名字 标签类型
标签类型

代码
<!ELEMENT 书名 ( #PCDATA )> <!--" 书名 " 元素体为字符串数据 --><!ELEMENT 作者 ( #PCDATA )> <!--" 作者 " 元素体为字符串数据 --><!ELEMENT 售价 ( #PCDATA )> <!--" 售价 " 元素体为字符串数据 --><!ELEMENT 出版日期 ANY > <!--" 出版日期 " 元素体为任意类型 --><!ELEMENT 版本号 EMPTY > <!--" 版本号 " 元素体为空元素 -->
数量词

属性声明:
语法:
<!ATTLIST 标签名称属性名 称 1 属性类 型 1 属性说 明 1属性名 称 2 属性类 型 2 属性说 明 2…>

代码“
<!ATTLIST 书 <!-- 设置 " 书 " 元素的的属性列表 -->id ID #REQUIRED <!--"id" 属性值为必须有 -->编号 CDATA #IMPLIED <!--" 编号 " 属性可有可无 -->出版社 ( 清华 | 北大 ) " 清华 " <!--" 出版社 " 属性值是枚举值,默认为 “ 清华 ”-->type CDATA #FIXED "IT" <!--"type" 属性为文本字符串并且固定值为 "IT"-->>
5.Schema约束:
概念:
Schema语言也可作为XSD(XML Schema Definition)
Schema比DTD强大,是DTD的替代者
Schema本身也是XML文档,单Schema文档扩展名为xsd,而不是xml
Schema功能更强大,数据类型约束更完善、
约束体验


名称空间
一个
XML
文档最多可以使用一个
DTD
文件
,
但一个
XML
文档中使用多个
Schema
文件,若这些
Schema
文件中定义了
相同名称的元素时
,
使用的时候就会出现名字冲突。这就像一个
Java
文件中使用了
import java.util.*
和
import java.sql.*
时,在使用
Date
类时,那么就不明确
Date
是哪个包下的
Date
了。同理
,
在
XML
文档中就需
要通过名称空间
(namespace)
来区分元素和属性是来源于哪个约束中的。名称空间就在在根元素后面的内容
,
使用
xmlns
到引入约束 。
当一个
XML
文档中需要使用多个
Schema
文件的时候
,
有且仅有一个使用缺省的
,
其他的名称空间都需要起别名 。
参考资料中的
applicationContext.xml
文件
(spring
框架的配置文件
)
xmlns="http://www.abc.cn"<!-- 缺省的名称空间 . 使用此约束中的元素的时候只需要写元素名即可 例如 :< 书 ></ 书 > -->xmlns:aa="http://java.sun.com"<!-- aa 就是此约束的别名 , 使用此约束中的元素的时候就需要加上别名 例如 :<aa: 书 ></aa: 书 > -->
总之名称空间就是用来处理元素和属性的名称冲突问题,与
Java
中的包是同一用途。如果每个元素和属性都有自己
的名称空间,那么就不会出现名字冲突问题,就像是每个类都有自己所在的包一样,那么类名就不会出现冲突。
虽然
schema
功能比
dtd
强大,但是编写要比
DTD
复杂,同样以后我们在企业开发中也很少会自己编写
schema
文
件。
xml
编写与约束内容已经完成了,根据
xml
的作用我们了解到,无论是
xml
作为配置文件还是数据传输,我们的程序
都要获取
xml
文档中的数据以便我们进行具体的业务操作,
二。Dom4j
1.XML解析
解析描述:
当将数据存储在 XML 后,我们就希望通过程序获取 XML 的内容。如果我们使用 Java 基础所学的 IO 知识是可以完成的,不过你学要非常繁琐的操作才可以完成,且开发中会遇到不同问题(只读、读写)。人们为不同问题提供不同的解析方式,使用不同的解析器进行解析,方便开发人员操作 XML 。
2.解析方式和解析器
开发中比较常见的解析方式有三种,如下:1. DOM:要求解析器把整个XML文档装载到内存,并解析成一个Document对象a )优点:元素与元素之间保留结构关系,故可以进行增删改查操作。b )缺点: XML 文档过大,可能出现内存溢出2. SAX:是一种速度更快,更有效的方法。它逐行扫描文档,一边扫描一边解析。并以事件驱动的方式进行具体解析,每执行一行,都触发对应的事件。a )优点:处理速度快,可以处理大文件b )缺点:只能读,逐行后将释放资源,解析操作繁琐。3. PULL:Android内置的XML解析方式,类似SAX。
解析器:
就是根据不同的解析方式提供具体实现。有的解析器操作过于繁琐,为了方便开发人员,有提供易
于操作的解析开发包

常见的解析开发包JAXP:sun公司提供支持DOM和SAX开发包Dom4j:比较简单的的解析开发包(常用)JDom:与Dom4j类似Jsoup:功能强大DOM方式的XML解析开发包,尤其对HTML解析更加方便
4.Dom4j 的基本使用
(1)DOM
解析原理及结构模型
解析原理
XML DOM 和 HTML DOM 一样, XML DOM 将整个 XML 文档加载到内存,生成一个 DOM 树,并获得一个Document 对象,通过 Document 对象就可以对 DOM 进行操作。

结构模型

DOM
中的核心概念就是节点,在
XML
文档中的元素、属性、文本,在
DOM
中都是节点!所有的节点都封装到
了
Document
对象中。
引入
dom4j
的
jar
包
需要引入
“jar/dom4j-1.6.1.jar” ,
在
IDEA
中,选择项目鼠标右键
--->
弹出菜单
-->open Module settings”--
>Dependencies-->+-->JARs or directories...
找到
dom4j-1.6.1.jar,
成功添加之后点击
"OK"
即可
dom4j
必须使用核心类
SaxReader
加载
xml
文档获得
Document
,通过
Document
对象获得文档的根元素,然
后就可以操作了。
(2)常用方法

解析上上述文件:
解析此文件
,
获取每本书的
id
值
,
以及书本名称
,
作者名称和价格
.

5.XPath
介绍:
XPath
使用路径表达式来选取
HTML
文档中的元素节点或属性节点。节点是通过沿着路径
(path)
来选取的。
XPath
在解析
HTML
文档方面提供了一独树一帜的路径思想。
XPath的使用步骤:
步骤 1 :导入 jar 包 (dom4j 和 jaxen-1.1-beta-6.jar)步骤 2 :通过 dom4j 的 SaxReader 获取 Document 对象步骤 3 : 利用 Xpath 提供的 api, 结合 xpaht 的语法完成选取 XML 文档元素节点进行解析操作。
document常用的api

XPath语法:
XPath 表达式,就是用于选取 HTML 文档中节点的表达式字符串。获取 XML 文档节点元素一共有如下 4 种 XPath 语法方式:1. 绝对路径表达式方式 例如 : / 元素 / 子元素 / 子子元素 ...2. 相对路径表达式方式 例如 : 子元素 / 子子元素 .. 或者 ./ 子元素 / 子子元素 ..3. 全文搜索路径表达式方式 例如 : // 子元素 // 子子元素4. 谓语(条件筛选)方式 例如 : // 元素 [@attr1=value]
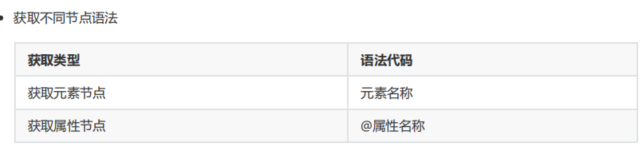
1.绝对路径表达式
绝对路径介绍格式: String xpath="/ 元素 / 子元素 / 子子元素 ...";绝对路径是以 “/” 开头,一级一级描述标签的层级路径就是绝对路径, 这里注意不可以跨层级绝对路径是从根元素开始写路径的, 这里开头的 “/” 代表 HTML 文档根元素 ,所以在绝对路径中不可以写根元素路径
2.相对路径表达式
相对路径介绍格式: String xpath1=" 子元素 / 子子元素 ...";// 获取相对当前路径元素里面的子元素的选取String xpath2="./ 子元素 / 子子元素 ";//"./" 代表当前元素路径位置String xpath3="/ 子元素 / 子子元素 ";// 功能与 xpath1 格式功能一样相对路径就是相对当前节点元素位置继续查找节点,需要使用 JXNode.sel ( xpath )进行执行相对路径表达式
3.全文搜索路径表达式
全文搜索路径介绍格式: String xpath1="// 子元素 // 子子元素 ";一个 “/” 符号,代表逐级写路径2 个 “//” 符号,不用逐级写路径,可以直接选取到对应的节点,是全文搜索匹配的不需要按照逐层级
4.谓语(条件筛选)
介绍谓语,又称为条件筛选方式,就是根据条件过滤判断进行选取节点格式:String xpath1="// 元素 [@attr1=value]";// 获取元素属性 attr1=value 的元素String xpath2="// 元素 [@attr1>value]/@attr1"// 获取元素属性 attr1>value 的 d 的所有 attr1 的值String xpath3="// 元素 [@attr1=value]/text()";// 获取符合条件元素体的自有文本数据String xpath4="// 元素 [@attr1=value]/html()";// 获取符合条件元素体的自有 html 代码数据。String xpath3="// 元素 [@attr1=value]/allText()";// 获取符合条件元素体的所有文本数据(包含子元素里面的文本)
演示:

other---
============================================================================
<?xml version="1.0" encoding="UTF-8"?>
<books>
<book id="01" 出版社="出版社">
<name>Java编程思想</name>
<author>James</author>
<price>98.00</price>
<body>库存:30</body>
</book>
<book id="02" 出版社="出版社">
<name>JavaEE从入门到精通</name>
<author>哈哈</author>
<price>40.00</price>
<body>库存:20</body>
</book>
<book id="03" 出版社="传智出版社">
<name>Java开发手册</name>
<author>阿里巴巴</author>
<price>15.00</price>
<body>库存:300</body>
</book>
</books>
解析
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.io.InputStream;
import java.util.List;
/**
*
* 请解析出图书信息,并打印。
*
*/
public class Test01 {
public static void main(String[] args) throws DocumentException {
// 获得核心解析器对象
SAXReader reader = new SAXReader();
// 加载xml文件到内存生成一个document文档对象
/*Class clazz = Test01.class;
InputStream is = clazz.getResourceAsStream("books.xml");
Document document = reader.read(is);*/
Document document = reader.read(Test01.class.getResourceAsStream("books.xml"));
// 获得根元素节点
Element rootElement = document.getRootElement();
System.out.println("rootElement:" + rootElement.getName());
/// 获得所有的子元素节点
List<Element> elements = rootElement.elements();
// 遍历
for (Element element : elements) {
//System.out.println(element.getName());
// 获得图书编号
String id = element.attributeValue("id");
System.out.println(id);
// 获得出版社
String 出版社 = element.attributeValue("出版社");
System.out.println(出版社);
// 继续获得book元素节点的子元素节点
List<Element> eles = element.elements();
// 继续遍历
for (Element ele : eles) {
String name = ele.getName();
String text = ele.getText();
System.out.println(name + ": " + text);
}
}
}
}
<?xml version="1.0" encoding="UTF-8"?>
<beans>
<!--<bean id="Animal" class="com.wsl.demo02.Dog"></bean>-->
<bean id="Animal" class="com.wsl.demo02.Cat"></bean>
</beans>
解析:
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class BeanFactory {
// 解析beans.xml文件,获得配置的全限定类名,使用反射创建对象
public static Object getBean(String id){ // id的值为Animal
Object obj = null;
try {
// 获得核心解析器对象
SAXReader saxReader = new SAXReader();
// 解析xml文件加载到内存生成一个Document对象
Document document = saxReader.read(BeanFactory.class.getResourceAsStream("beans.xml"));
// 使用dom4j结合XPath解析xml文件里面的数据
Element element = (Element) document.selectSingleNode("//bean[@id='"+id+"']");
// 获得calss属性值
String aClass = element.attributeValue("class"); //com.wsl.demo02.Dog
// 获得字节码对象
Class clazz = Class.forName(aClass);
// 创建对象
obj = clazz.newInstance();
} catch (Exception e) {
e.printStackTrace();
}
return obj;
}
}
//抽象类
public interface Animal {
abstract void eat();
}
public class Test {
public static void main(String[] args) {
// 创建对象
//Animal animal = new Dog(); // 多态【父类引用指向子类对象】
//【一旦改动就违背了Java的一个原则,开闭原则(已经写好的代码不要修改,你可以扩展其功能)】
//Animal animal = new Cat();
/////////////////////////////////////////////////
Animal animal = (Animal) BeanFactory.getBean("Animal");
System.out.println(animal);
}
}
<?xml version="1.0" encoding="UTF-8"?>
<books>
<book id="01" 出版社="呵呵版社">
<name>Java编程思想</name>
<author>James</author>
<price>98.00</price>
<body>库存:30</body>
</book>
<book id="02" 出版社="哈哈版社">
<name>JavaEE从入门到精通</name>
<author>播客</author>
<price>40.00</price>
<body>库存:20</body>
</book>
<book id="03" 出版社="你好出版社">
<name>Java开发手册</name>
<author>阿里巴巴</author>
<price>15.00</price>
<body>库存:300</body>
</book>
</books>
@Test
public void Dom4jXML() throws Exception{
SAXReader saxReader = new SAXReader();
Document document = saxReader.read(new File("D:\\book.xml"));
Element rootElement = document.getRootElement();
List<Element> elements = rootElement.elements();
for (Element element : elements) {
List<Attribute> attributes = element.attributes();
for (Attribute attribute : attributes) {
System.out.println(attribute.getName()+":"+attribute.getText());
}
List<Element> elements1 = element.elements();
for (Element element1 : elements1) {
System.out.println(element1.getName()+":"+element1.getText());
}
System.out.println("========================");
}
}
@Test
public void Dom4jXPath() throws Exception{
SAXReader saxReader = new SAXReader() ;
Document document = saxReader.read(new File("D:\\book.xml"));
List<Element> list = document.selectNodes("//book");
Node node = document.selectSingleNode("//book[@id='01']/name");
System.out.println(node.getText());
System.out.println("---------------------------------------");
for (Element element : list) {
String att1 = element.attributeValue("id");
String att2 = element.attributeValue("出版社");
System.out.println("id:"+att1);
System.out.println("出版社:"+att2);
String name = element.elementText("name");
System.out.println("name:"+name);
String author = element.elementText("author");
System.out.println("author:"+author);
String price = element.elementText("price");
System.out.println("price:"+price);
String body = element.elementText("body");
System.out.println("body:"+body);
System.out.println("========================");
}
}<?xml version="1.0" encoding="UTF-8"?>
<config>
<class id="001">
<classname>com.wsl.ze.Person</classname>
<hubby>hahhh</hubby>
</class>
</config>
public static void main(String[] args) throws Exception{
SAXReader saxReader = new SAXReader();
Document document = saxReader.read(new File("D:\\config.xml"));
Node node1 = document.selectSingleNode("//class[@id='001']/classname");
Node node2 = document.selectSingleNode("//class[@id='001']/hubby");
Class aClass = Class.forName(node1.getText());
Person person = (Person) aClass.newInstance();
Method eat = aClass.getMethod("eat");
eat.invoke(person);
Method hubby = aClass.getMethod("hubby",String.class);
hubby.invoke(person,node2.getText());
}