用dom4j对xml进行解析已经比sax方式简洁了很多,用起来很方便,但是在获取某个元素时依然有点麻烦,要一层一层的获取,如果文件过大,会很麻烦,还好dom4j提供了对XPATH的支持, XPath是使用路径表达式来获取XML文档的节点和节点集,选取节点时使用的表达式是一种路径表达式。节点是通过路径(path)或者步(steps)来选取的。
一、XPath的常用形式
| /AAA/DDD/BBB | 表示AAA下面的DDD下面的BBB元素 |
|---|---|
| //BBB | 表示得到所有的BBB元素 |
| /* | 表示得到所有元素 |
| BBB[1],BBB[last()] | 分别表示第一个BBB元素和最后一个BBB元素 |
| //BBB[@id] | 表示得到所有有id属性的BBB元素 |
| //BBB[@id=’name’] | 表示得到id属性值是name的BBB元素 |
二、dom4j支持XPath的具体操作
1、在默认情况下,dom4j是不支持Xpath的,如果想使用需引入相应的jar包。同时dom4j也不是JavaSE里的,也需要导入相应的jar包
2、dom4j提供了两个方法来支持XPath
#获取多个节点
selectNode("XPath表达式")
#获取一个节点
selectsingleNode("XPath表达式")
3、示例:
以下面这个xml文件为例
<?xml version="1.0" encoding="ISO-8859-1"?>
<student>
<p id="101">
<name>zhangsan</name>
<age>40</age>
<sex>nv</sex>
</p>
<p id="102">
<name>lisi</name>
<age>21</age>
<sex>nan</sex>
</p>
<p id="103">
<name>wanger</name>
<age>20</age>
</p>
</student>
如果我们想要获得所有的name元素的值,原来用dom4j解析xml的代码如下:
public static void chazhao() throws DocumentException {
//创建解析器
SAXReader reader=new SAXReader();
//得到document
Document document=reader.read("src/student.xml");
//得到根元素
Element root=document.getRootElement();
//得到p
List<Element> list= root.elements("p");
//循环获得每一个p下的name元素
for(Element element:list){
Element name1=element.element("name");
//获取name元素的文本内容
String s=name1.getText();
System.out.println(s);
}
}运行结果:
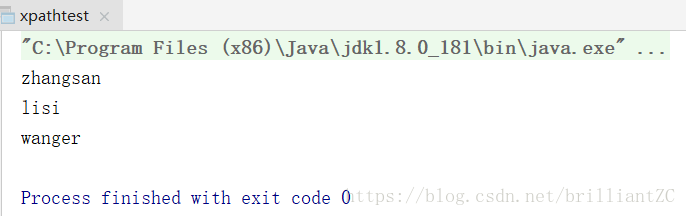
这时确实能得到所有的name元素的值,也比sax方式简单,但是仍要要一层一层的获取,如果xml标签很多,会很麻烦,这是就用XPath就可以很简单的解决,代吗如下:
public static void chazhao1() throws DocumentException {
//创建解析器
SAXReader reader=new SAXReader();
//得到document
Document document=reader.read("src/student.xml");
//得到所有的name元素
List<Element> list = document.selectNodes("//name");
//循环获取name属性值,并打印
for(Element element:list){
System.out.println(element.getText());
}
}运行结果与上面相同,用XPath就不用一层一层去解析,通过XPath更高效方便,再如我们获取lisi的age元素值:
public static void chazhao2() throws DocumentException {
//创建解析器
SAXReader reader = new SAXReader();
//得到document
Document document = reader.read("src/student.xml");
//获取lisi的age元素值
Node node = document.selectSingleNode("/student/p[@id='102']/age");
//获取age元素的值并打印
System.out.println(node.getText());
}运行结果:
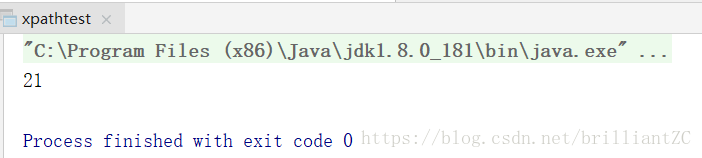
xpath用起来非常方便,这里只做了一个简单介绍,同时还有sun公司提供的针对dom和sax的解析器Jaxp,但是这个不常用,也比较麻烦,可参考以下
jaxp的dom解析xml