懒惰学习算法的典型例子。
KNN仅仅对训练集有记忆功能,不会从其他训练集中通过学习得到一个判别函数
参数化模型和非参数化模型:
1、 参数化模型,通过训练数据估计参数:感知机、逻辑回归、线性SVM
2、 非参数化模型,无法通过固定参数来进行表征,参数数量随训练数据的增加而递增:核SVM、决策树、KNN
KNN基于实例的学习,只对训练数据产生记忆,学习阶段的计算成本基本为0
KNN的实现过程:
1、 选择近邻数量k和距离高度量方法
2、 找到待分类样本的k个最近邻居
3、 根据最近邻居的类标进行多数投票
KNN图:
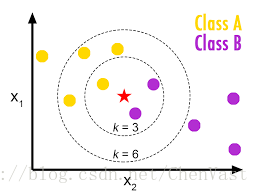

KNN基于选定的距离度量标准,从训练数据集中找到与待预测目标点的k个距离最近(相似)的样本。
目标点的类标基于这k个最近的近邻的类标使用多数投票确定。
优点:分类器可以快速的适应新的训练数据
缺点:最坏情况下,复杂度随样本的数量的增多而呈线性增长
对于KNN来说,找到正确的k值是在欠拟合和过拟合中找到平衡点的关键所在。
必须保证所选的距离度量标准适用于数据集中的特征。
使用闵可夫斯基距离是对欧几里得距离及曼哈顿距离的一种泛化。

维度灾难:使得KNN算法易于过拟合,对于一个样本数量大小稳定的训练数据集,随着其特征数量的增加,样本中有具体的特征数量变得极其稀疏,也就是近邻距离过远。
本文使用的数据集和库文件定义在该章节有定义了,链接:http://mp.blog.csdn.net/postedit/79196206
实现代码:
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=5, p=2, metric='minkowski')
knn.fit(X_train_std, y_train)
plot_decision_regions(X_combined_std, y_combined,
classifier=knn, test_idx=range(105,150))
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.legend(loc='upper left')
plt.tight_layout()
# plt.savefig('./figures/k_nearest_neighbors.png', dpi=300)
plt.show()

