其实在很早之前,博主就想做这件事情了。但是奈何自己才疏学浅,想做却又没有做成,在经过一段时间的学习后,博主再次进行尝试,最终侥幸爬取成功,下面博主就将代码和讲解贴出来。
爬取时间:2020-03-27
爬取难度:★★★★☆☆
请求链接:https://wp.m.163.com/163/page/news/virus_report/index.html?_nw_=1&_anw_=1
爬取目标:爬取该网站上我国以及世界各国当日的疫情人数(确诊、治愈、死亡等信息)并保存为 CSV 文件
涉及知识:requests、json、time、CSV储存、pandas等。
一、选择数据源
新型冠状病毒感染的肺炎疫情爆发后,对人们的生活产生很大的影响。当前感染人数依然在不断变化。每天国家卫健委和各大新闻媒体都会公布疫情的数据,包括累计确诊人数、现有确诊人数等。
针对于此,博主专门选择了几个网站准备进行爬取,但是发现有的网站是文本,有的网站是图片,这些数据并不方便采集。最终我选择了网易的疫情实时动态播报平台作为数据源。
网址为:https://wp.m.163.com/163/page/news/virus_report/index.html?nw=1&anw=1
打开后我们会看到下图:
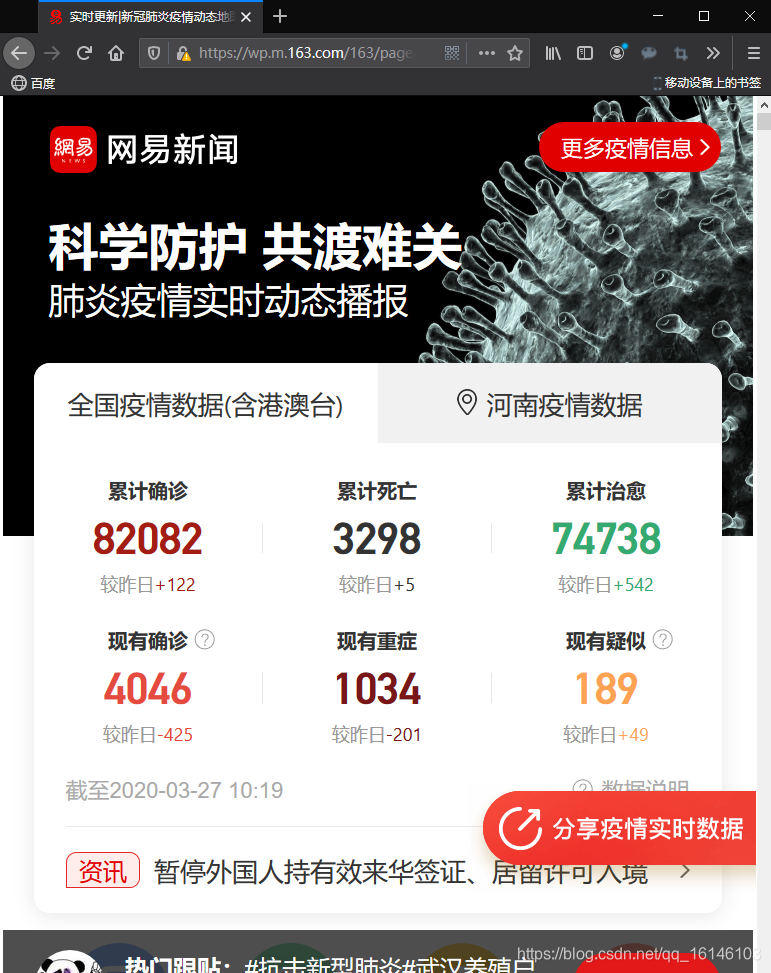
打开网页我们可以发现这时一个动态网页,因此数据可以在F12->Network标签下找到我们想要的数据。
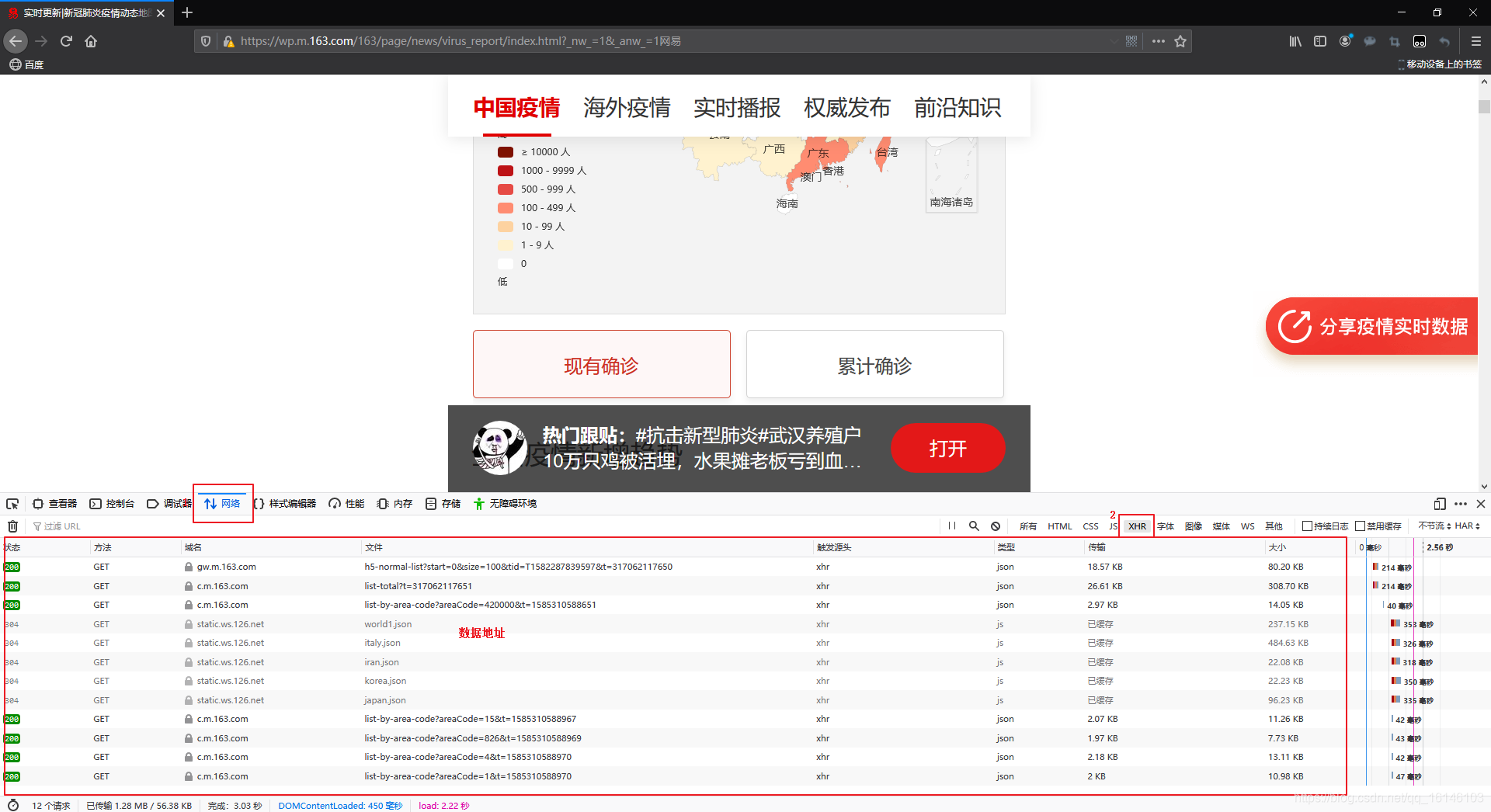
二、初步了解数据
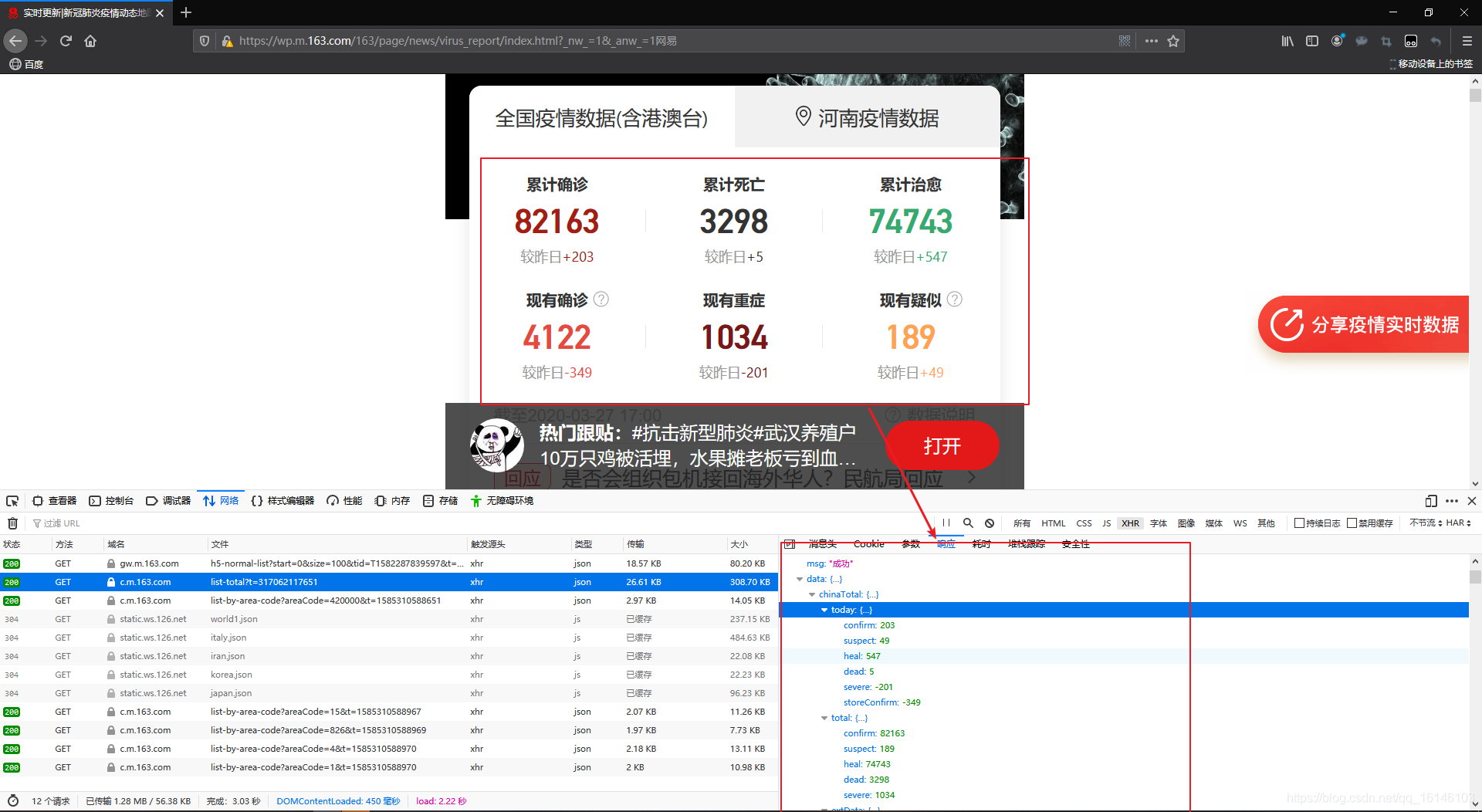
在以上网页中,我们可以看到数据所在位置。,同时也能看到这是JSON类型。
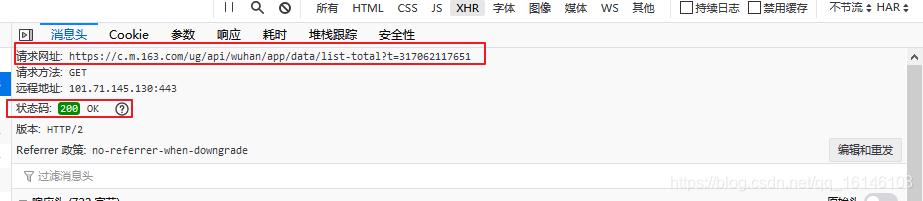
上图我们看到了请求网址和状态码。
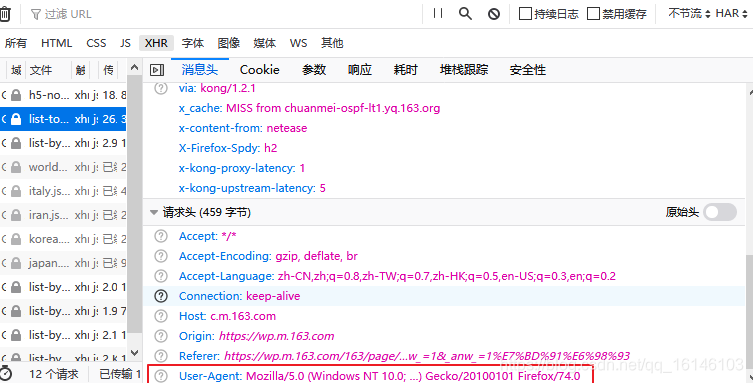
上图的为User-Agent。
好了知道上面的我们就可以准备开始了。
首先我们先导入包和设置代理头
import requests
import pandas as pd
import time
pd.set_option('max_rows',500)
headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'}
url = 'https://c.m.163.com/ug/api/wuhan/app/data/list-total' # 定义要访问的地址
r = requests.get(url, headers=headers) # 使用requests发起请求
这个时候我们请求以下:
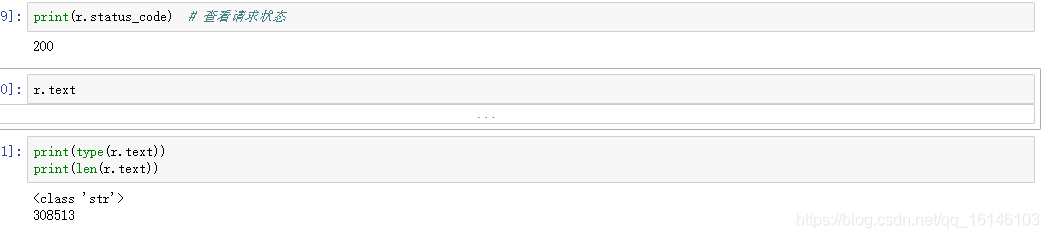
由上图我们可以看到返回后的内容是一个几十万长度的字符串,由于字符串格式不方便进行分析,并且在网页预览中发现数据为类似字典的json格式,所以我们将其转为json格式。
import json
data_json = json.loads(r.text)
data_json.keys()

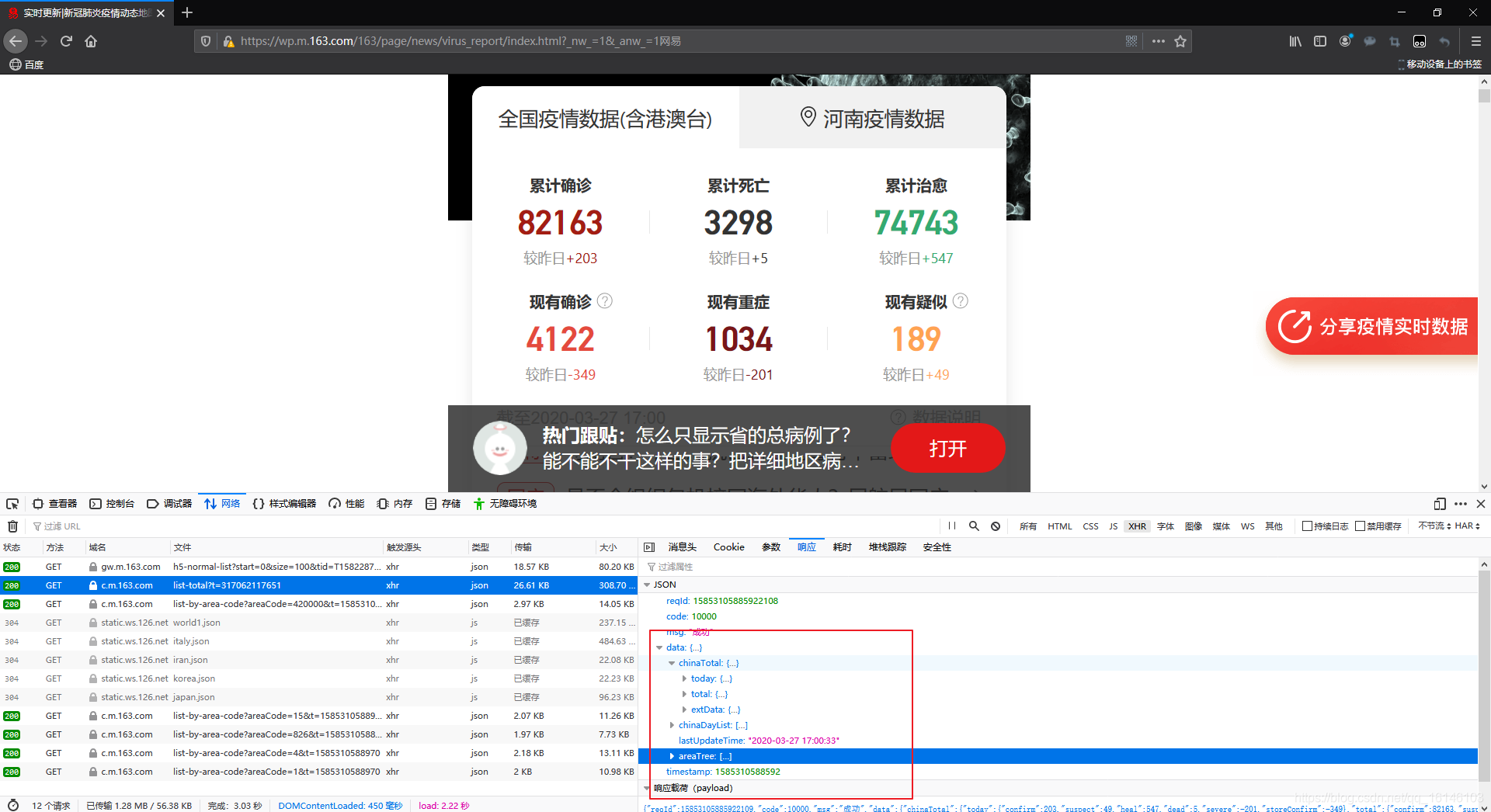
我们可以看出在data中存放着我们需要的数据,因此我们取出数据。
data = data_json['data']
data.keys()

数据中总共有四个键,每个键存储着不同的内容:
键名称 数据内容
- chinaTotal 全国当日数据
- chinaDayList 全国历史数据
- lastUpdateTime 更新时间
- areaTree 世界各地实时数据
接下来我们开始获取实时数据。
三、爬取实时数据
3.1 爬取各省实时数据
首先我们抓取全国各省的实时数据,在areaTree键值对中,存放着世界各地的实时数据,areaTree是一个列表,每一个元素都是一个国家的数据,每一个元素的children是各国家省份的数据。 我们首先找到中国各省的实时数据,如下图所示:
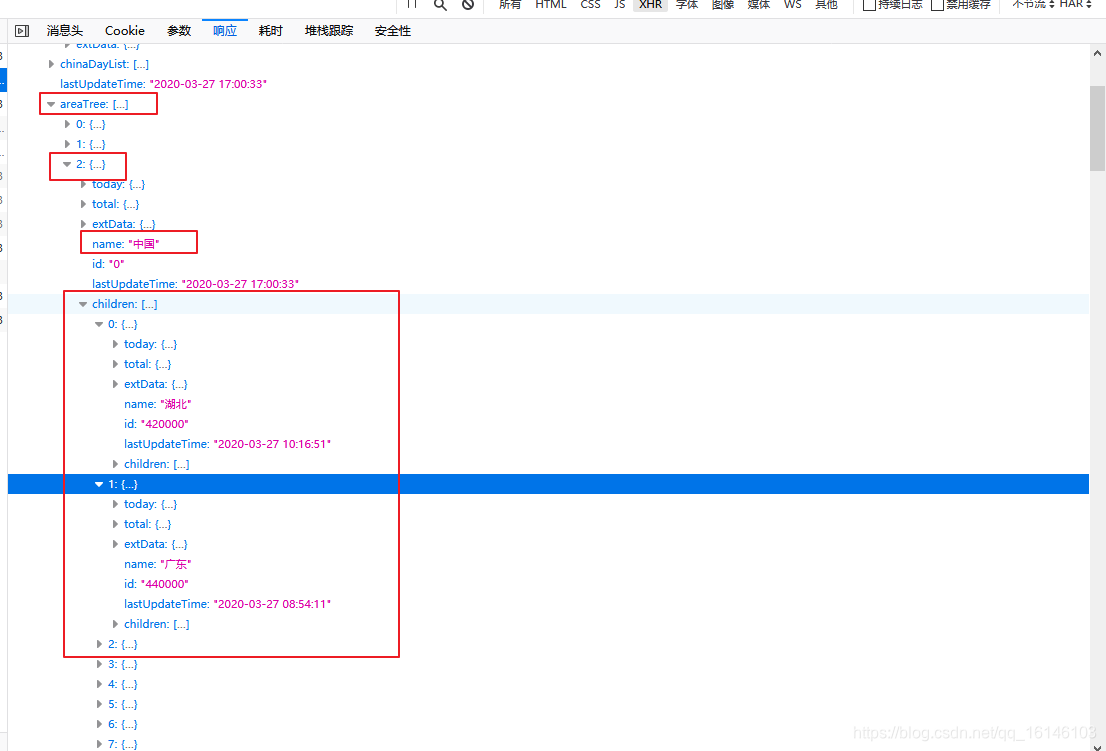
下面开始取出我国各省的数据:

data_province = data['areaTree'][2]['children']
下面我们先看下每个省的键名称
data_province[0].keys() # 查看每个省键名称
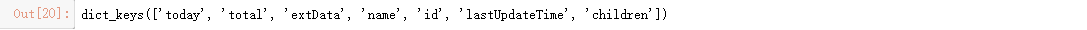
键名称 数据内容
- today 各省当日数据
- total 各省当日累计数据
- extData 无任何数据
- name 各省名称
- id 各省行政编号
- lastUpdateTime 更新时间
- children 各省下一级数据
下面我们先遍历查看各省名称、更新时间
for i in range(len(data_province)):
print(data_province[i]['name'],data_province[i]['lastUpdateTime'])
if i == 5:
break

下面我们先生成个表格看一下效果
pd.DataFrame(data_province).head()
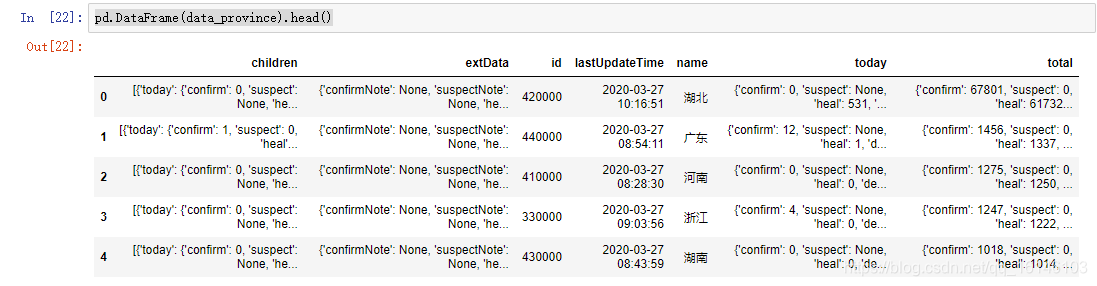
通过生成的这个数据,我们可以清楚的看到,得到的数据和我们想要的数据有差距。只有id ,lastUpdateTime,name这三个数据正常显示。这时为什么呢?
不能直接生成DataFrame是因为数据中嵌套着字典,例如湖北省数据如下:标红线表示带有嵌套字典,红筐内没有嵌套字典。
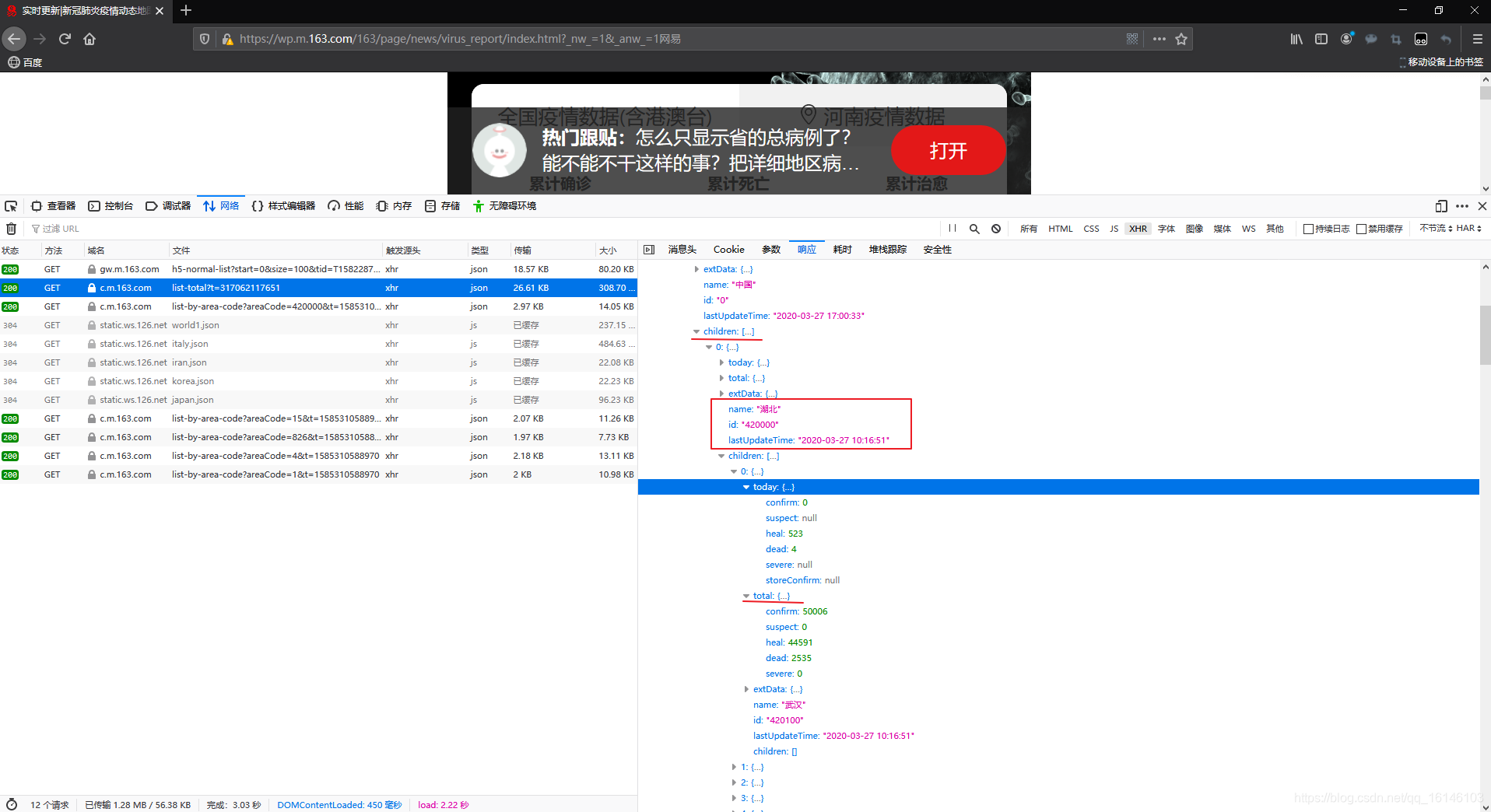
对上图进行分析:
由于此次我们只需要爬取各省的总数据,因此children不进行采集,然后extData为null,也不采集,这时我们需要采集的为today和total,但是又因为这两个存在嵌套字典,不能直接获取。我们可以把id、lastUpdateTime、name直接作为一个数据,today为一个数据,total为一个数据,最后三个数据合并为一个数据。
下面我们开始进行操作:
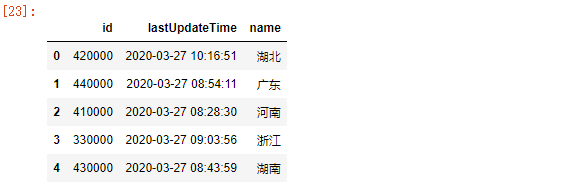
info = pd.DataFrame(data_province)[['id','lastUpdateTime','name']]
info.head()
today_data = pd.DataFrame([province['today'] for province in data_province ])
today_data.head()
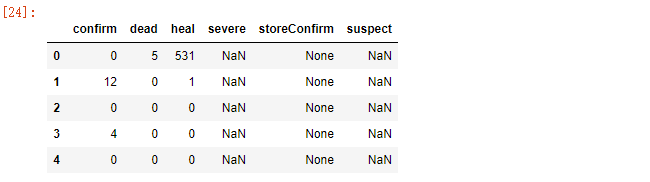
因为today中键名和total键名相同,因此需要分别修改列名称
# 获取today中的数据
today_data.columns = ['today_'+i for i in today_data.columns]
today_data.head()

# 获取total中的数据
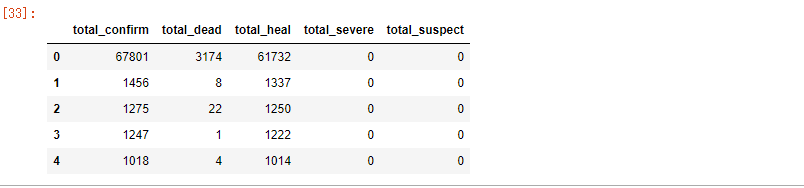
total_data = pd.DataFrame([province['total'] for province in data_province])
total_data.columns = ['total_'+i for i in total_data.columns]
total_data.head()
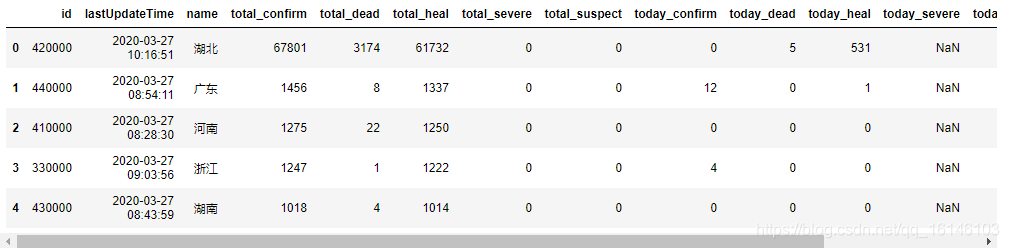
下面将三个数据进行合并:
pd.concat([info,total_data,today_data],axis=1).head()
最后进行保存:
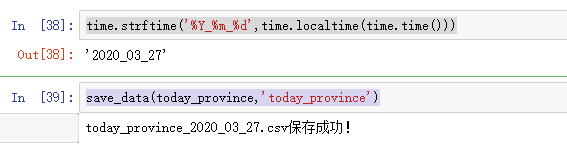
3.2、爬取世界各国实时数据
根据之前已经了解到在json数据data中的areaTree是列表格式,每个元素都是一个国家的实时数据,每个元素的children是各国家省份的数据,现在我们提取世界各国实时数据。
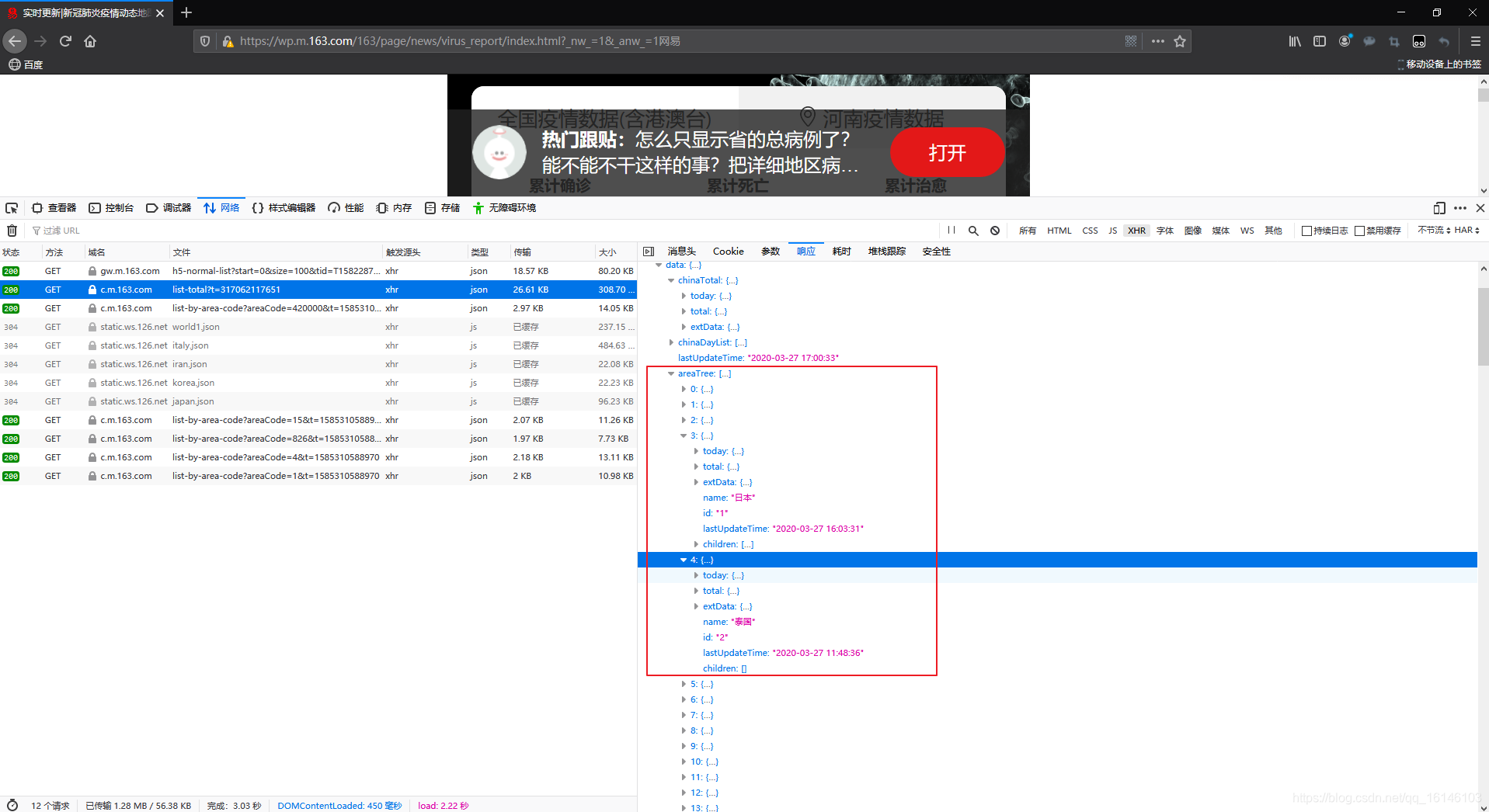
下面我们来看下结构:
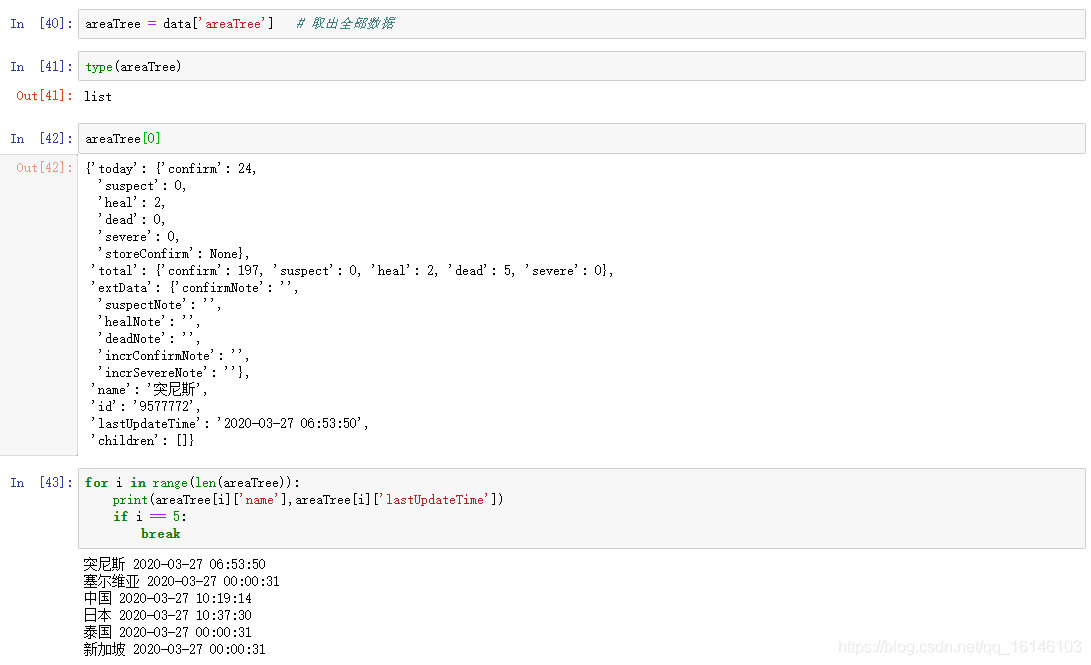
我们可以发现这和爬取我国各省实时数据一致。
那么我们可以用同样的方法进行爬取数据:还是分成三步进行。
today_world = get_data(areaTree,['id','lastUpdateTime','name'])
today_data = pd.DataFrame([i['today'] for i in data])
today_data.columns = ['today_'+i for i in today_data.columns]
total_data = pd.DataFrame([i['total'] for i in data])
total_data.columns = ['total_'+i for i in total_data.columns]
pd.concat([info,total_data,today_data],axis=1).head() # 将三个数据合并
最终结果如下:
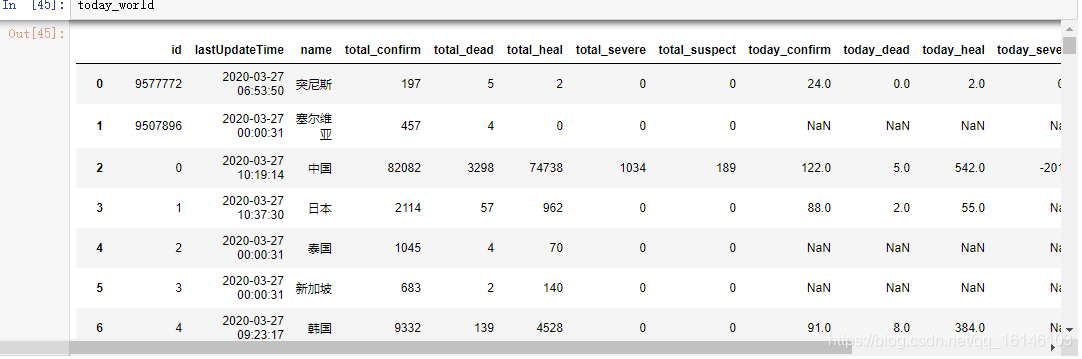
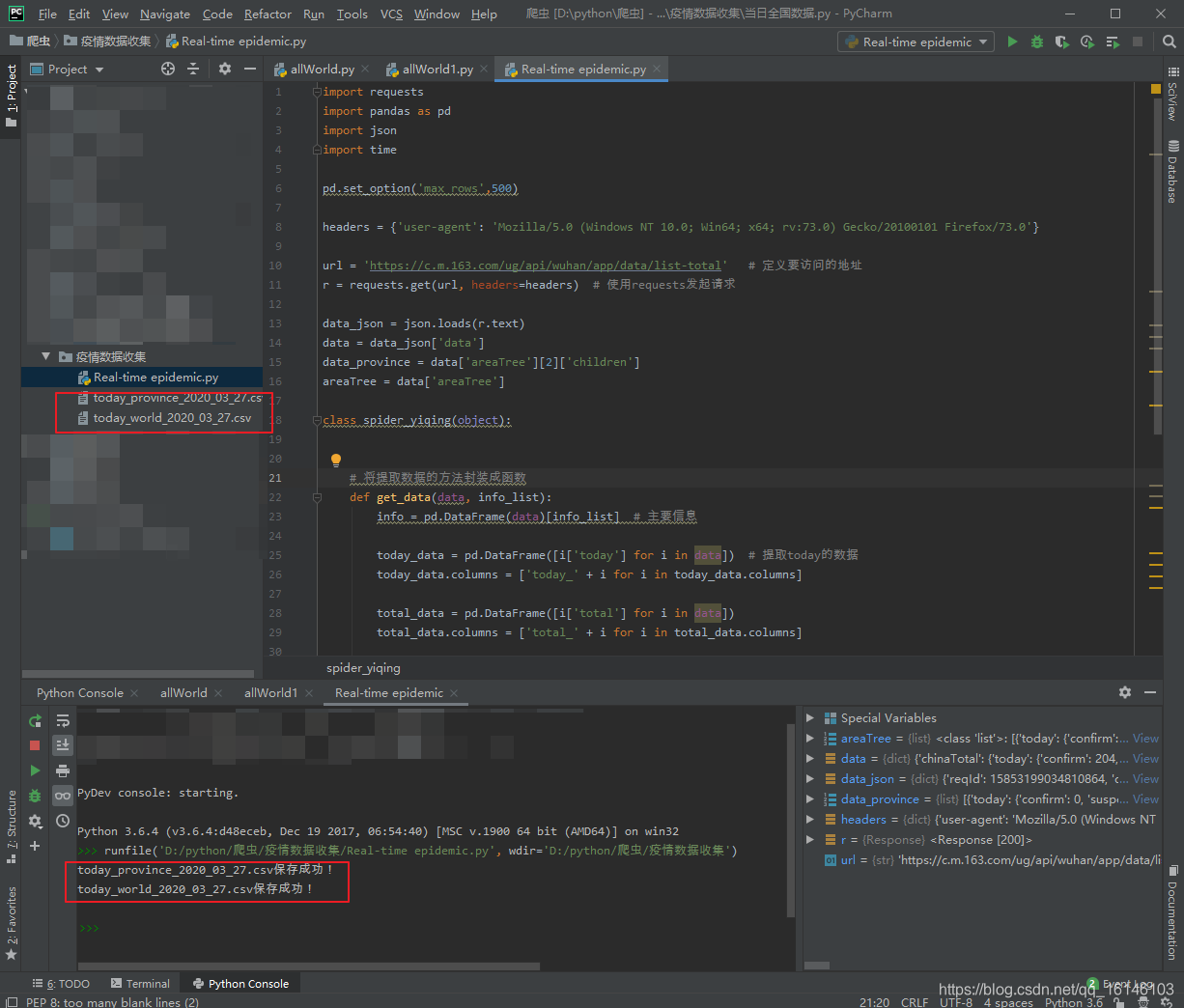
四、整体代码实现
# =============================================
# --*-- coding: utf-8 --*--
# @Time : 2020-03-27
# @Author : 不温卜火
# @CSDN : https://blog.csdn.net/qq_16146103
# @FileName: Real-time epidemic.py
# @Software: PyCharm
# =============================================
import requests
import pandas as pd
import json
import time
pd.set_option('max_rows',500)
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'}
url = 'https://c.m.163.com/ug/api/wuhan/app/data/list-total' # 定义要访问的地址
r = requests.get(url, headers=headers) # 使用requests发起请求
data_json = json.loads(r.text)
data = data_json['data']
data_province = data['areaTree'][2]['children']
areaTree = data['areaTree']
class spider_yiqing(object):
# 将提取数据的方法封装成函数
def get_data(data, info_list):
info = pd.DataFrame(data)[info_list] # 主要信息
today_data = pd.DataFrame([i['today'] for i in data]) # 提取today的数据
today_data.columns = ['today_' + i for i in today_data.columns]
total_data = pd.DataFrame([i['total'] for i in data])
total_data.columns = ['total_' + i for i in total_data.columns]
return pd.concat([info, total_data, today_data], axis=1)
def save_data(data,name):
file_name = name+'_'+time.strftime('%Y_%m_%d',time.localtime(time.time()))+'.csv'
data.to_csv(file_name,index=None,encoding='utf_8_sig')
print(file_name+'保存成功!')
if __name__ == '__main__':
today_province = get_data(data_province, ['id', 'lastUpdateTime', 'name'])
today_world = get_data(areaTree, ['id', 'lastUpdateTime', 'name'])
save_data(today_province, 'today_province')
save_data(today_world, 'today_world')
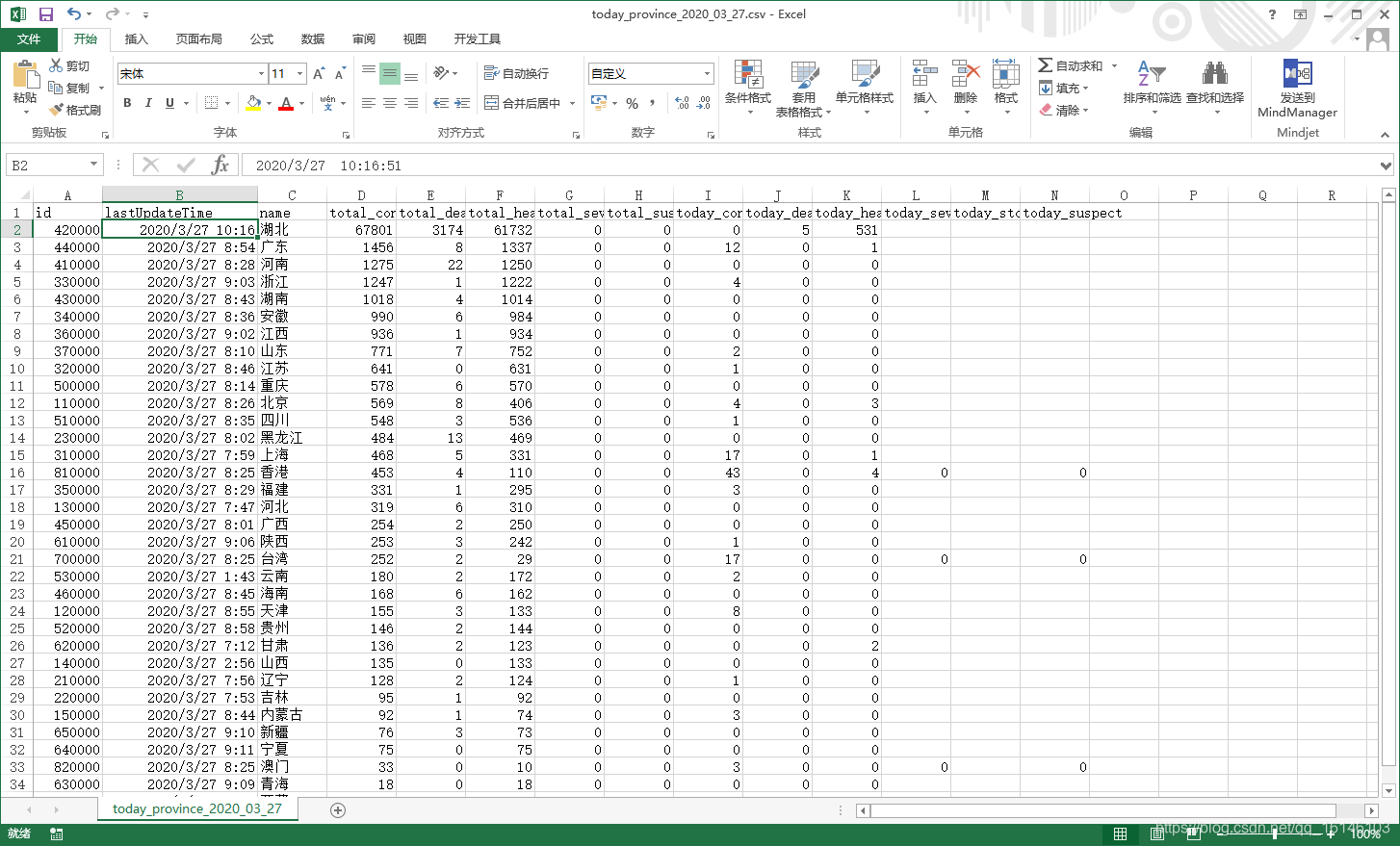
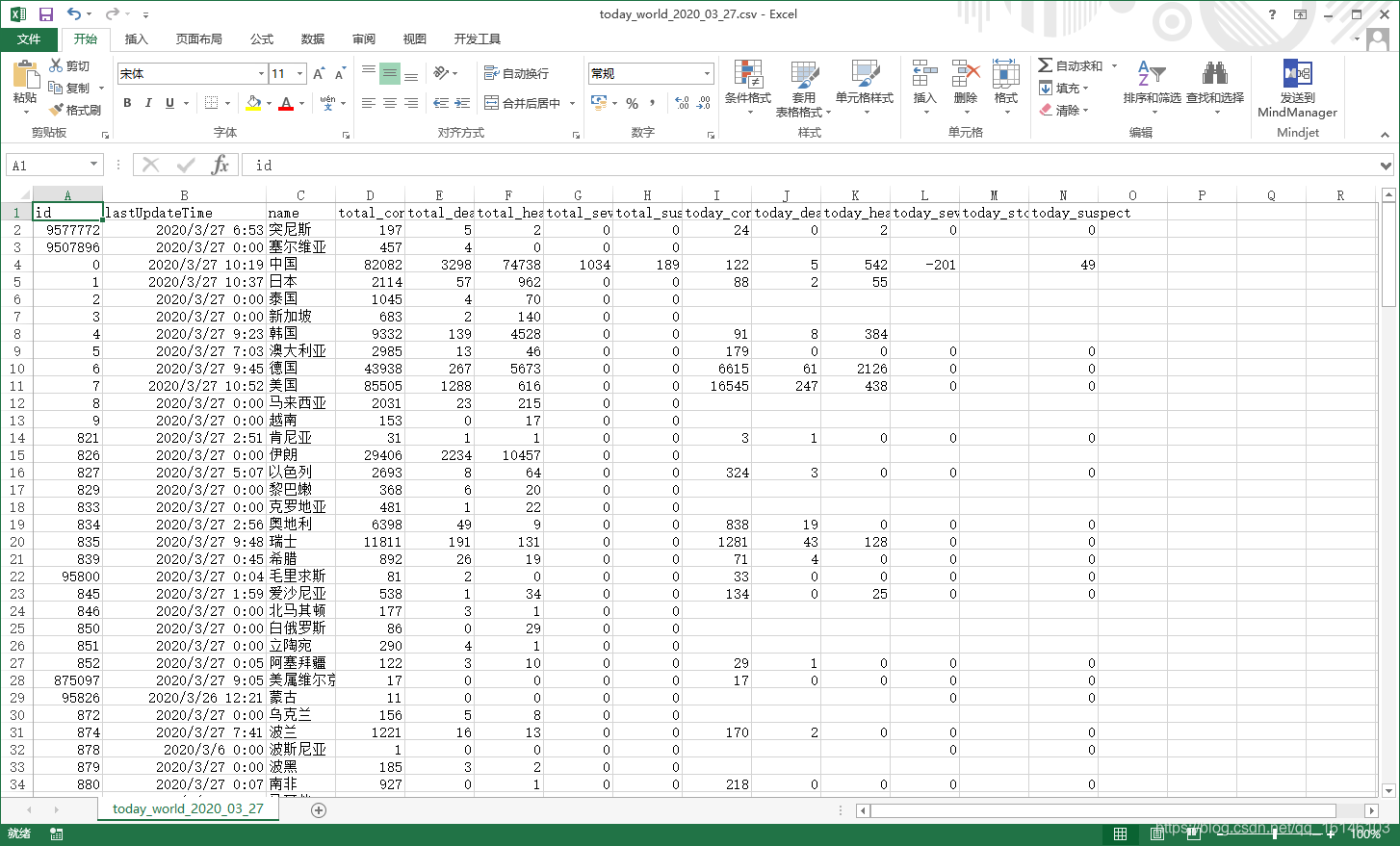
五、运行成功截图
国内各省:
世界各国:
六、总结
此程序代码有些许混乱,层次感不强。还有可能还有更高效的爬取手段。
