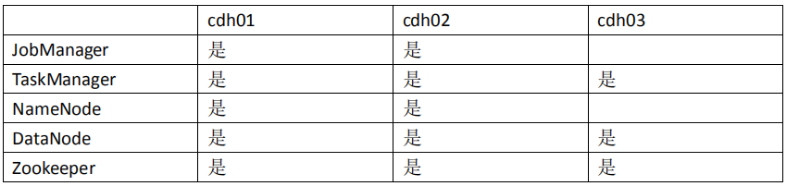
1.主机规划
这里我们选择 3 台节点安装 flink,分别为 cdh01、cdh02、cdh03。每台节点对 flink 的角色规划如下所示。
2.软件规划
官网要求 Flink 环境安装要求 Java1.8 或者更高版本,另外要求必须 SSH 免密。SSH 免密及 Java 环境大家自行安装,这里不再赘叙。

3.用户规划
为了方便操作,flink 集群我们仍然安装在 hadoop 用户下。

4.Flink Standalone 集群安装配置
4.1 下载
Flink 安装包可以直接到官网下载,官网地址:官网:https://archive.apache.org/dist/flink/。这里我们选择下载较新的稳定的 Flink1.6.2 版本。
因为 Flink 后期要实现与 hadoop 集成,结合我们前面规划的 hadoop 版本,我们选择下载 flink-1.6.2-bin-hadoop26-scala_2.11.tgz。
4.2 解压
我们将下载好的 flink-1.6.2-bin-hadoop26-scala_2.11.tgz 上传至 cdh01 节点的 /home/hadoop/app 目录下,通过 tar 命令进行解压,具体操作如下(为了方便后期 Flink 版本的升级更新,配置 flink 环境变量之前,可以创建 Flink 的软连接。):
[hadoop@cdh01 app]$ tar -zxvf flink-1.6.2-bin-hadoop26-scala_2.11.tgz
[hadoop@cdh01 app]$ ls
flink-1.6.2
[hadoop@cdh01 app]$ ln -s flink-1.6.2 flink
4.3 配置环境变量
Flink 环境变量可以配置在 root 用户下的/etc/profile 文件中,此时对所有用户生效。也可以配置在 hadoop 用户下的~/.bashrc 文件中,此时只对 hadoop 用户有效。为了避免不同用户环境干扰,这里我们选择将 flink 环境变量配置在 hadoop 用户下的~/.bashrc 文件中,在文件的末尾增加如下内容:
[hadoop@cdh01 app]$ vi ~/.bashrc
export FLINK_HOME=/home/hadoop/app/flink
export PATH=$FLINK_HOME/bin:$PATH
然后保存退出,并通过 source 命令使环境变量生效。
[hadoop@cdh01 app]$ source ~/.bashrc
4.4 修改 flink-conf.yaml 文件
flink-conf.yaml 文件是 flink 的核心配置,具体配置如下所示:
[hadoop@cdh01 conf]$ vi flink-conf.yaml
#JobManager 地址
jobmanager.rpc.address: cdh01
#槽位配置为 3(可以默认不配置)
taskmanager.numberOfTaskSlots: 3
#设置并行度为 3(可以默认不配置)
parallelism.default: 3
4.5 修改 masters 文件
[hadoop@cdh01 conf]$ vi masters
#启动 JobManagers 的所有主机以及 Web 用户界面绑定的端口
cdh01:8081
4.6 修改 slaves 文件
[hadoop@cdh01 conf]$ vi slaves
#配置 worker 节点
cdh01
cdh02
cdh03
4.7 安装目录同步其他节点
通过 deploy.sh 脚本将 flink 安装目录同步到 cdh01 和 cdh02 节点
[hadoop@cdh01 app]$ deploy.sh flink /home/hadoop/app/ slave
在从节点分别创建 flink 软连接
[hadoop@cdh02 app]$ln -s flink-1.6.2 flink
[hadoop@cdh03 app]$ln -s flink-1.6.2 flink
4.8 启动 flink Standalone 集群
在 cdh01 节点上,进入/home/hadoop/app/flink 目录,使用如下命令启动 flink 集群:
[hadoop@cdh01 flink]$ bin/start-cluster.sh
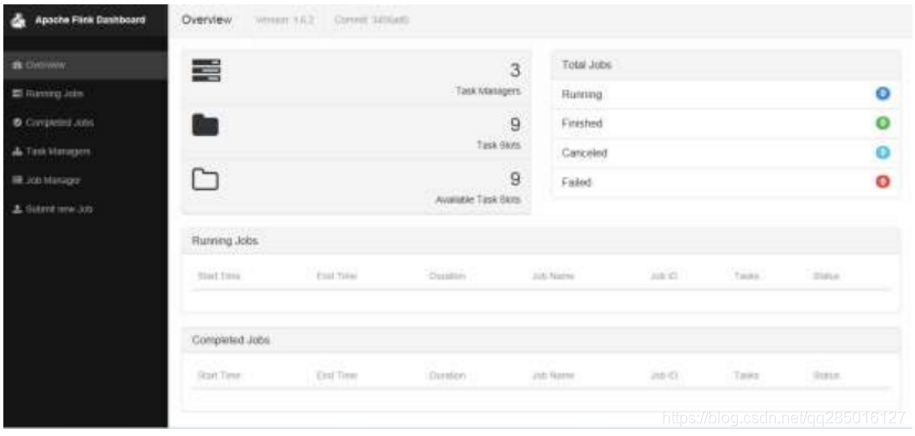
4.9 web ui 查看 fink
在浏览器中输入地址:http://cdh01:8081/
5.Flink Standalone HA 配置
5.1 修改 conf/flink-conf.yaml 文件
Flink Standalone HA 官网参考地址:https://ci.apache.org/projects/flink/flink-docs-release1.7/ops/jobmanager_high_availability.html
[hadoop@cdh01 conf]$ vi flink-conf.yaml
#高可用模式,必须为 zookeeper
high-availability: zookeeper
#配置独立 Zookeeper 集群地址
high-availability.zookeeper.quorum: cdh01:2181,cdh02:2181,cdh03:2181
#添加 ZooKeeper 根节点,在该节点下放置所有集群节点
high-availability.zookeeper.path.root: /flink
#添加 ZooKeeper 的 cluster-id 节点,在该节点下放置集群的所有相关数据
high-availability.cluster-id: /cluster_one
#JobManager 的元数据持久化保存的位置,hdfs://mycluster 为 hdfs NN 高可用地址
high-availability.storageDir: hdfs://mycluster/flink/recovery
5.2 修改 conf/masters 文件
[hadoop@cdh01 conf]$ vi masters
cdh01:8081
#增加 JobManager 备用节点
cdh02:8081
5.3 修改配置同步其他节点
[hadoop@cdh01 conf]$ deploy.sh flink-conf.yaml /home/hadoop/app/flink/conf/ slave
[hadoop@cdh01 conf]$ deploy.sh masters /home/hadoop/app/flink/conf/ slave
5.4 修改 JobManager 备用节点的 conf/flink-conf.yaml 文件
[hadoop@cdh02 conf]$ vi flink-conf.yaml
jobmanager.rpc.address: cdh02
5.5 启动 flink Standalone HA 集群
1.启动 Zookeeper 集群(提前安装)
通过 runRemoteCmd.sh 远程脚本,同时启动 cdh01、cdh02、cdh03 节点的 Zookeeper 服务。
[hadoop@cdh01 app]$ runRemoteCmd.sh "/home/hadoop/app/zookeeper/bin/zkServer.sh start" all
2.启动 HDFS 集群(提前安装)
在 cdh01 节点上,使用一键启动 HDFS 分布式集群服务。
[hadoop@cdh01 hadoop]$ sbin/start-dfs.sh
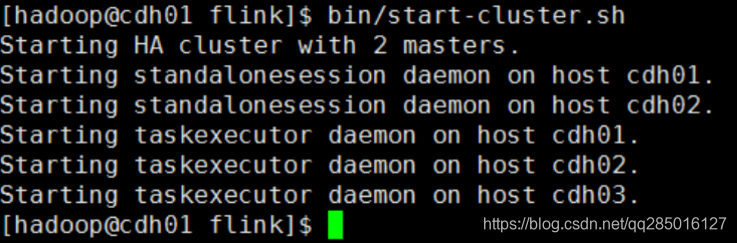
3.启动 flink 集群
在 cdh01 节点上,进入/home/hadoop/app/flink 目录,使用如下命令启动 flink 集群:
[hadoop@cdh01 flink]$ bin/start-cluster.sh
常见错误:Cannot instantiate file system for URI: hdfs://mycluster/flink/recovery
原因:flink 默认从${HADOOP_HOME}/etc/hadoop 目录下读取 hdfs 相关配置文件,识别 mycluster。但是如果没有配置 HADOOP_HOME,flink 会找不到 hdfs 相关配置。
解决:
需要在每个 flink 节点添加 hadoop 环境变量,这里以 cdh01 节点为例
[hadoop@cdh01 app]$ vi ~/.bashrc
export HADOOP_HOME=/home/hadoop/app/hadoop
export PATH=$HADOOP_HOME/bin:$PATH
4.web ui 查看 flink
在浏览器中输入地址:http://cdh01:8081/,此时 cdh01 的节点 JobManager 为 active
在浏览器中输入地址:http://cdh02:8081/,此时 cdh02 的节点 JobManager 为 standby,它也会跳转到 cdh01 节点。
5.JobManager HA 测试
在 cdh01 节点关闭 JobManager 服务。
[hadoop@cdh01 flink]$ bin/jobmanager.sh stop
Stopping standalonesession daemon (pid: 5605) on host cdh01.
等待一会之后,cdh02 节点的 JobManager 称为 active 接管服务,在浏览器中输入地址: http://cdh02:8081/。
然后从新在 cdh01 节点启动 JobManager
[hadoop@cdh01 flink]$ bin/jobmanager.sh start cdh01 8081
Starting standalonesession daemon on host cdh01.
接着在浏览器中输入地址:http://cdh01:8081/,此时也会跳转到 cdh02 的 JobManager 地址。
6.Flink job 测试运行
6.1 使用 netcat 启动本地服务
[hadoop@cdh01 app]$ nc -l 9999
6.2 提交 flink 作业
[hadoop@cdh01 flink]$ bin/flink run examples/streaming/SoctWindowWordCount.jar --hostname cdh01 --port 9999

6.3 输入测试数据
[hadoop@cdh01 app]$ nc -l 9999
flink
flink
flink
flink
flink
flink
flink
flink
flink
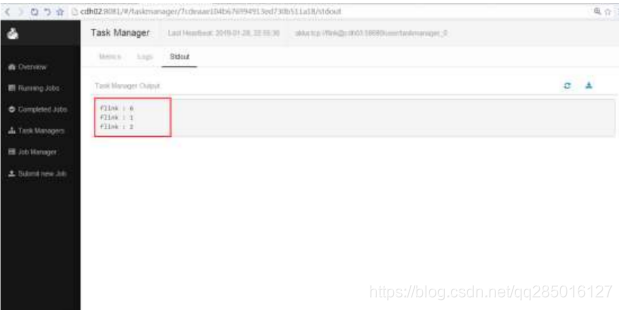
6.4 查看作业运行结果
在 TaskManager 界面的 stdout 选项下,查看 Flink 运行结果。