1、Flink-HA高可用
JobManager 高可用(HA)
- jobManager协调每个flink任务部署。它负责任务调度和资源管理。
- 默认情况下,每个flink集群只有一个JobManager,这将导致一个单点故障(SPOF):如果JobManager挂了,则不能提交新的任务,并且运行中的程序也会失败。
- 使用JobManager HA,集群可以从JobManager故障中恢复,从而避免SPOF(单点故障) 。 用户可以在standalone或 YARN集群 模式下,配置集群高可用
2、JobManager HA配置步骤
- Standalone集群的高可用
Standalone模式(独立模式)下JobManager的高可用性的基本思想是,任何时候都有一个 Master JobManager ,并且多个Standby JobManagers 。 Standby JobManagers可以在Master JobManager 挂掉的情况下接管集群成为Master JobManager。 这样保证了没有单点故障,一旦某一个Standby JobManager接管集群,程序就可以继续运行。 Standby JobManager和Master JobManager实例之间没有明确区别。 每个JobManager都可以成为Master或Standby节点 - Yarn 集群高可用
flink on yarn的HA 其实主要是利用yarn自己的job恢复机制 - 详细配置步骤信息请参考<<Flink HA配置指南.doc>>
3、配置,操作步骤
(1)在flink文件的flink-1.7.0/conf/配置文件
[root@Flink105 conf]# vim flink-conf.yaml
[root@Flink105 conf]#
//配置参数本机名
jobmanager.rpc.address: flink105
(2)配置slaves
[root@Flink105 conf]# vim slaves
flink106
flink107
(3)配置masters
//然后修改配置 HA 需要的参数
[root@Flink105 conf]# vim masters
flink105:8081
flink106:8081
(4) 配置flink-conf.yaml
[root@Flink105 conf]# vim flink-conf.yaml
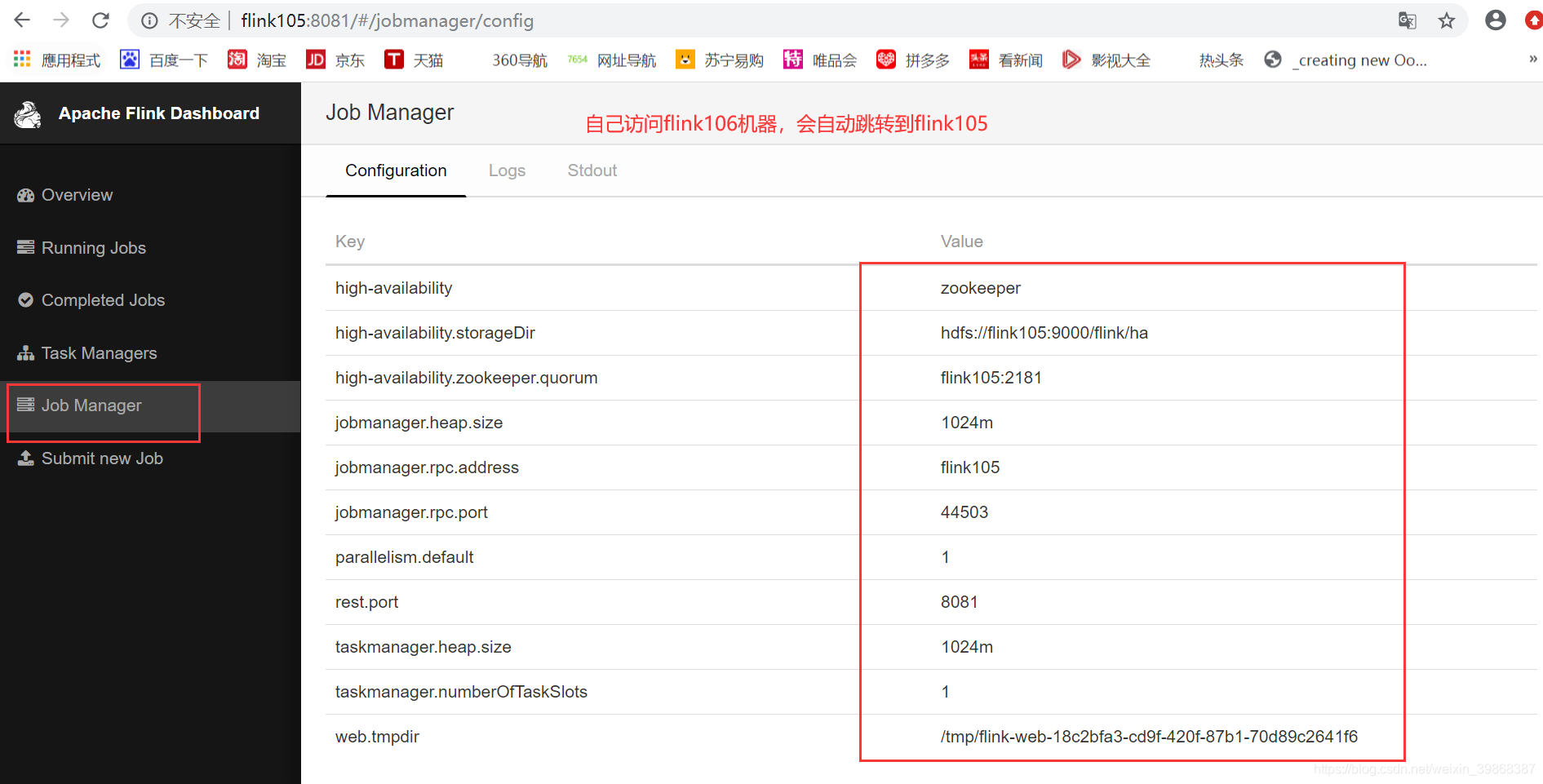
high-availability: zookeeper
high-availability.zookeeper.quorum: flink105:2181
//ZooKeeper节点根目录,其下放置所有集群节点的namespace
high-availability.zookeeper.path.root:/flink
//建议指定hdfs的全路径。如果某个flink节点没有配置hdfs的话,不指定全路径无法识别
//storageDir存储了恢复一个JobManager所需的所有元数据
high-availability.storageDir:hdfs://flink105:9000/flink/ha
(5)拷贝分发到其他机器
[root@Flink105 module]# scp -r flink-1.7.0/ flink106:/opt/hadoop/module/
[root@Flink105 module]# scp -r flink-1.7.0/ flink107:/opt/hadoop/module/
(6)启动hadoop集群
[root@Flink105 module]# start-all.sh
(7)启动zookeeper集群
[root@flink105 zookeeper-3.4.5]# bin/zkServer.sh start
[root@flink106 zookeeper-3.4.5]# bin/zkServer.sh start
[root@flink107 zookeeper-3.4.5]# bin/zkServer.sh start
//查看进程
[root@Flink105 zkData]# jps -l
16596 org.apache.hadoop.hdfs.server.namenode.NameNode
9959 org.apache.hadoop.yarn.server.resourcemanager.ResourceManager
16888 org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode
17016 org.apache.zookeeper.server.quorum.QuorumPeerMain
17176 sun.tools.jps.Jps
10073 org.apache.hadoop.yarn.server.nodemanager.NodeManager
16698 org.apache.hadoop.hdfs.server.datanode.DataNode
8349 org.apache.flink.runtime.entrypoint.StandaloneSessionClusterEntrypoint
//启动zookeeper客户端,之后关闭
[root@Flink105 bin]# ./zkCli.sh
//启动cluster集群
[root@Flink105 flink-1.7.0]# bin/start-cluster.sh
Starting HA cluster with 2 masters.
Starting standalonesession daemon on host Flink105.
Starting standalonesession daemon on host Flink106.
Starting taskexecutor daemon on host Flink106.
Starting taskexecutor daemon on host Flink107.
查看进程
//已经有了
[root@Flink105 flink-1.7.0]# jps
16596 NameNode
9959 ResourceManager
16888 SecondaryNameNode
17016 QuorumPeerMain
17976 Jps
10073 NodeManager
16698 DataNode
8349 StandaloneSessionClusterEntrypoint
Web页面访问
http://flink105:8081
扫描二维码关注公众号,回复:
9627792 查看本文章

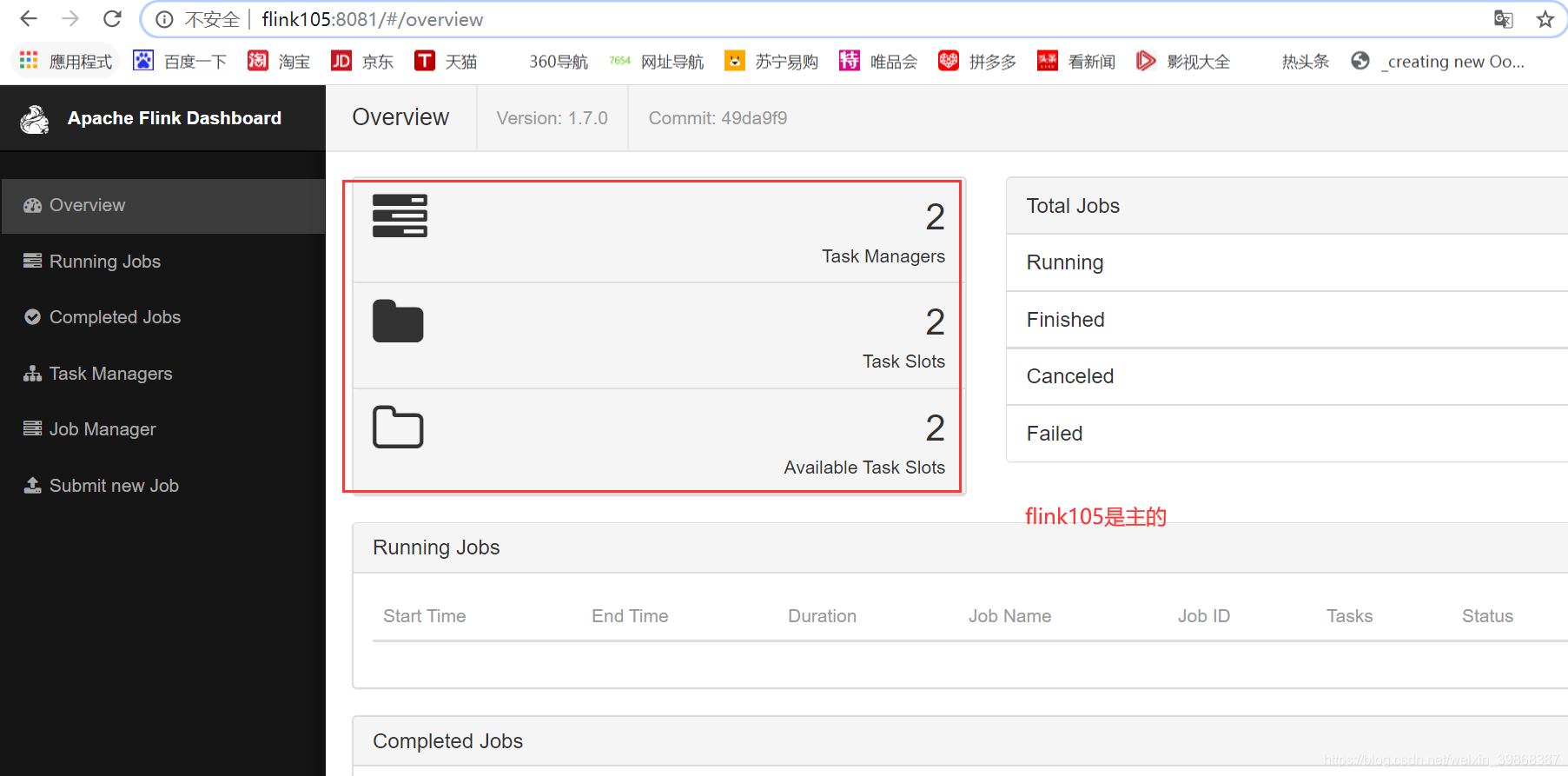
当我们访问flink106(别的机器也会跳到flink105)