文章目录
- 1、前言
- 2、ZooKeeper与Hadoop、HBase的关系
- 3、Hadoop与HBase的关系
- 4、架构资源规划
- 5、ZooKeeper集群设置
- 6、Hadoop HA配置详细说明
- 6.1 core-site.xml 加入zk服务
- 6.2 hdfs-site.xml
- 6.3 mapred-site.xml
- 6.4 yarn-site.xml配置
- 6.5 指定worker
- 6.6 修改start-dfs.sh和 stop-dfs.sh文件
- 7、集群启动
- 7.1 启动JournalNode进程
- 7.2 格式化 NameNode和zkfc
- 7.3 启动ZookeeperFailoverController、HDFS、YARN
- 7.4 启动Application(job)History进程服务
- 7.5 使用命令或者web页面查看集群组件服务情况
- 7.6 hadoop主备切换测试
- 8、HBase的HA配置
- 8.1 配置conf
- 8.2 配置hbase-site.xml
- 8.3 编辑regionservers
- 8.4 创建hdfs-site.xml的软链到hbase的conf目录下
- 8.5 启动HBase集群遇到的问题
- 8.6 查看HBase集群信息
- 8.7 HBase 主备切换测试
- 9、HBase在hdfs创建的目录
- 10、在HBase创建table测试
1、前言
前面的博客中链接已经给出Hadoop3.1.2和yarn的完整部署(但还不是高可用),此篇博客将给出Hadoop的高可用部署,以及HBase高可用,为之后应用数据层开发提供底层的BigTable支持。前面的文章,我们已经深入讨论的ZooKeeper这个中间件的原理以及分布式锁的实现,事实上zookeeper使用最广泛的场景是“选举”主从角色,Hadoop以及Hbase的高可用(主从架构)正是通过ZooKeeper的临时节点机制实现。
以下的配置会跳过Hadoop3.1.2的部署,仅给出ZooKeeper分布式物理方式部署、以及HBase的部署过程、测试结果。
2、ZooKeeper与Hadoop、HBase的关系
ZooKeeper作为协调器,在大数据组件中提供:管理Hadoop集群中的NameNode、HBase中HBaseMaster的选举,节点之间状态同步等。例如在HBase中,存储HBase的Schema,实时监控HRegionServer,存储所有Region的寻址入口,当然还有最常见的功能就是保证HBase集群中只有一个Master。
3、Hadoop与HBase的关系
完整的hadoop组件环境架构图
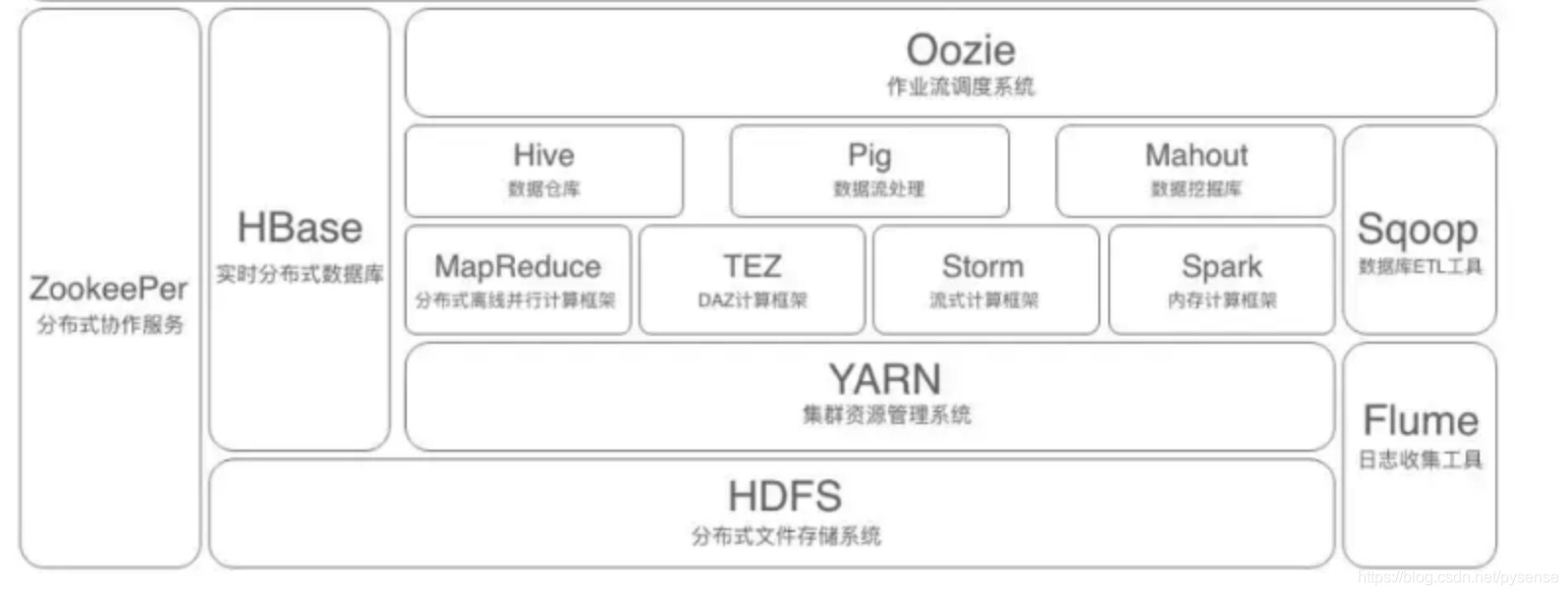
首先HBase是一个分布式的、面向列的开源数据库,正是业务数据需要列数据库的支持以及该数据库能够支持业务超大数据集扩展存储的需求,HBase当然作为中间件选型的首选。上图描述Hadoop组件生态中的各层系统。其中,HBase位于结构化存储层,Hadoop的HDFS为HBase提供了高可靠性、分布式的底层存储支持,Hadoop MapReduce、Spark为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定选举服务和failover机制。
此外,Pig和Hive还为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变的非常简单。 Sqoop则为HBase提供了方便的RDBMS数据导入功能,使得传统数据库数据向HBase中迁移变的非常方便。
(当然本blog也会针对Hbase的架构原理做出一篇文章讨论)
其实,本博客有关大数据的多篇文章的内容,都是为了能够梳理出大数据多个组件全流程部署、架构原理、业务数据应用开发到BI的呈现的完整技术内容,以实现大数据库开发工程师必备的项目经历。
4、架构资源规划
| nn | dn1 | dn2 |
|---|---|---|
| 1vcpu,2G内存 | 1vcpu,1G内存 | 1vcpu,1G内存 |
| NameNode | NameNode | |
| DataNode | DataNode | DataNode |
| JournalNode | JournalNode | JournalNode |
| DFSZKFailoverController | DFSZKFailoverController | DFSZKFailoverController |
| ResourceManager | ResourceManager | |
| NodeManager | NodeManager | NodeManager |
| JobHistoryServer | JobHistoryServer | |
| ZooKeeper | ZooKeeper | ZooKeeper |
| HBase master | HBase master | |
| RegionServer | RegionServer | RegionServer |
Hadoop版本、JDK版本、HBase版本、ZooKeeper版本参考如下:
[root@nn opt]# ls
hadoop-3.1.2 jdk1.8.0_161
hbase-2.1.7 zookeeper-3.4.14
关于Hadoop与HBase的兼容性,官方已经给出Hadoop version support matrix,目前HBase2.1.x、HBase2.2.x支持Hadoop 3.1.1+(Tested to be fully-functional)。关于版本兼容分析,很多类似文章也有提到,但他们所提到的兼容比对情况已过时,故最佳途径应及时查阅官网最新发布的内容。
5、ZooKeeper集群设置
5.1 设置nn节点的zoo.conf
[root@nn conf]# pwd
/opt/zookeeper-3.4.14/conf
# 拷贝zoo_sample.cfg并重命名为zoo.cfg :
[root@nn conf]# cp zoo_sample.cfg zoo.conf
# 修改 zoo.cfg
[root@nn conf] vi zoo.cfg
# data目录需自行创建,添加:
dataDir=/opt/zookeeper-3.4.14/data
# 在该文件最后添加,指定zookeeper集群主机及端口,节点数必须为奇数
server.1=nn:2888:3888
server.2=dn1:2888:3888
server.3=dn2:2888:3888
# 在/opt/zookeeper-3.4.14/data目录下创建myid文件
[root@nn data]# pwd
/opt/zookeeper-3.4.14/data
[root@nn data]# touch myid
[root@nn data]# ls
myid
# 文件内容为1,即表示当前节点为在zoo.cfg中指定的server.1
5.2 将zookeeper目录拷贝到dn1、dn2节点上,并更改对于的myid
[root@nn opt]# scp -r zookeeper-3.4.14/ dn1:/opt
[root@nn opt]# scp -r zookeeper-3.4.14/ dn2:/opt
# 更改dn1 myid内容为2,dn2 myid内容为3
5.3 设置zk的全局环境变量
在三个节点上都要配置
[root@nn opt] vi /etc/profile
# 新增
ZOOKEEPER_HOME=/opt/zookeeper-3.4.14
export PATH=$ZOOKEEPER_HOME/bin:$PATH
source ~/.bash_profile
5.4 启动zk集群
在每个节点上运行zkServer.sh start
查看三个节点的zk角色
# nn节点
[root@nn ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.4.14/bin/../conf/zoo.cfg
Mode: follower
# dn1节点
[root@dn1 opt]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.4.14/bin/../conf/zoo.cfg
Mode: leader
# dn2节点
[root@dn2 opt]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.4.14/bin/../conf/zoo.cfg
Mode: follower
使用jps查看zk的进程QuorumPeerMain
QuorumPeerMain是zookeeper集群的启动入口类,用来加载配置启动QuorumPeer线程
[root@nn opt]# jps
1907 Jps
1775 QuorumPeerMain
[root@dn1 opt]# jps
16226 Jps
16201 QuorumPeerMain
[root@dn2 opt]# jps
5824 QuorumPeerMain
5861 Jps
注意:如果某个节点使用jps命令后,没有QuorumPeerMain进程,一般是因为zk的端口号2181被占用,在/opt/zookeeper-3.4.14目录中,zookeeper.out执行日志会给相应的提示。
[root@nn zookeeper-3.4.14]# ls
bin ivy.xml README.md zookeeper-3.4.14.jar.sha1 zookeeper.out
…
以下为之前docker方式部署zk时占用了2181端口
[root@dn2 zookeeper-3.4.14]# ss -tnlp |grep 2181
LISTEN 0 128 :::2181 :::* users:(("docker-proxy",pid=1499,fd=4))
# kill docker占用的2181进程,再重新启动zk即可。
6、Hadoop HA配置详细说明
首先配置hadoop的jdk路径:
vi hadoop-env.sh
JAVA_HOME=/opt/jdk1.8.0_161
6.1 core-site.xml 加入zk服务
<configuration>
<!-- hdfs地址,单点模式值为namenode主节点名,本测试为HA模式,需设置为nameservice 的名字-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hdapp</value>
</property>
<!-- 这里的路径默认是NameNode、DataNode、JournalNode等存放数据的公共目录,也可以单独指定 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-3.1.2/tmp</value>
</property>
<!--加入zk服务,不少于三个节点-->
<property>
<name>ha.zookeeper.quorum</name>
<value>nn:2181,dn1:2181,dn2:2181</value>
</property>
</configuration>
<!--设置web访问用户,否则web端浏览hdfs文件目录会提权限不足-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
6.2 hdfs-site.xml
因为要配置hadoop HA,因此这部分的属性项比较多,这部分内容参考
Apache官网HA配置,官网已经给出非常详细且易懂的描述。
<configuration>
<!-- hadoop HA 配置开始 -->
<!-- 为namenode集群起一个services name,名字和core-site.xml的fs.defaultFS指定的一致 -->
<property>
<name>dfs.nameservices</name>
<value>hdapp</value>
</property>
<!-- nameservice 包含哪些namenode,为各个namenode起名 -->
<property>
<name>dfs.ha.namenodes.hdapp</name>
<value>nn,dn2</value>
</property>
<!-- 指定nn的namenode的rpc地址和端口号,rpc用来和datanode通讯 -->
<property>
<name>dfs.namenode.rpc-address.hdapp.nn</name>
<value>nn:9000</value>
</property>
<!-- 指定dn2的namenode的rpc地址和端口号,rpc用来和datanode通讯 -->
<property>
<name>dfs.namenode.rpc-address.hdapp.dn2</name>
<value>dn2:9000</value>
</property>
<!--名为nn的namenode的http地址和端口号,用来和web客户端通讯 -->
<property>
<name>dfs.namenode.http-address.hdapp.nn</name>
<value>nn:50070</value>
</property>
<!-- 名为dn2的namenode的http地址和端口号,用来和web客户端通讯 -->
<property>
<name>dfs.namenode.http-address.hdapp.dn2</name>
<value>dn2:50070</value>
</property>
<!-- namenode间用于共享编辑日志的journal节点列表/hdapp是表示日志存储的在hdfs上根路径,为多个HA可公用服务器进行数据存储,节约服务器成本 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://nn:8485;dn1:8485;dn2:8485/hdapp</value>
</property>
<!-- journalnode 上用于存放edits日志的目录 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/hadoop-3.1.2/tmp/dfs/journalnode</value>
</property>
<!-- 指定该集群出现故障时,是否自动切换到另一台namenode -->
<property>
<name>dfs.ha.automatic-failover.enabled.hdapp</name>
<value>true</value>
</property>
<!-- 客户端连接可用状态的NameNode所用的代理类 -->
<property>
<name>dfs.client.failover.proxy.provider.hdapp</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 一旦需要NameNode切换,使用两方式进行操作,优先使用sshfence -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence
shell(/bin/true)
</value>
</property>
<!-- 如果使用ssh进行故障切换,使用ssh通信时指定私钥所在位置 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- ssh连接超时超时时间,30s -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<!-- HA配置结束 -->
<!-- 设置 hdfs 副本数量,这里跟节点数量一致 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
注意在sshfence设置中,若ssh用户名不是root,且ssh端口不是默认22,则需改为
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence([[my_hadoop][:31900]])</value>
</property>
<property>
以上设置非常重要,涉及sshfence能否正常切换主备hadoop服务
官网给出自定义shell脚本去切换namenode进程
#shell - run an arbitrary shell command to fence the Active NameNode
#The shell fencing method runs an arbitrary shell command. It may be configured like so:
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/path/to/my/script.sh arg1 arg2 ...)</value>
</property>
6.3 mapred-site.xml
<!-- 采用yarn作为mapreduce的资源调度框架 -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 打开Jobhistory -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>nn:10020</value>
</property>
<!-- 指定nn作为jobhistory服务器 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>nn:19888</value>
</property>
<!--存放已完成job的历史日志 -->
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/history/done</value>
</property>
<!--存放正在运行job的历史日志 -->
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/history/done_intermediate</value>
</property>
<!--存放yarn stage的日志 -->
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/history/staging</value>
</property>
# web上默认最多显示20000个历史的作业记录信息,这里设为1000个。
<property>
<name>mapreduce.jobhistory.joblist.cache.size</name>
<value>1000</value>
</property>
<property>
<name>mapreduce.jobhistory.cleaner.enable</name>
<value>true</value>
</property>
<!-- 一天清理一次 -->
<property>
<name>mapreduce.jobhistory.cleaner.interval-ms</name>
<value>86400000</value>
</property>
<!-- 仅保留最近1周的job日志 -->
<property>
<name>mapreduce.jobhistory.max-age-ms</name>
<value>432000000</value>
</property>
</configuration>
注意,这里加入yarn执行application(job)的日志记录进程,因为nn和dn2做了HA,所以nn、dn2节点都配上该jobhistory服务,dn1节点不需要。
6.4 yarn-site.xml配置
<configuration>
<!-- 启用yarn HA高可用性 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定resourcemanager的名字,自行命名,跟服务器hostname无关 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>hayarn</value>
</property>
<!-- 使用了2个resourcemanager,分别指定Resourcemanager的地址 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 指定nn节点为rm1 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>nn</value>
</property>
<!-- 指定dn2节点为rm2 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>dn2</value>
</property>
<!-- 指定当前机器nn作为主rm1 -->
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
</property>
<!-- 指定zookeeper集群机器 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>nn:2181,dn1:2181,dn2:2181</value>
</property>
<!-- NodeManager上运行的附属服务,默认是mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
<!-- 禁止启动一个线程检查每个任务正使用的物理内存量、虚拟内存量是否可用 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
6.5 指定worker
三个节点都设为datanode,在生产环境中,DD不要跟DN放在同一台服务器
[root@nn hadoop-3.1.2]# vi etc/hadoop/workers
nn
dn1
dn2
6.5 将/opt/hadoop-3.1.2/目录拷贝到dn1、dn2节点
(因为dn1不作为resourcemanager standby角色,因此在其yarn-site.xml删除)
nn节点作为resourcemanager 角色,因此在其yarn-site.xml,RM设为自己
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
</property>
而dn2节点作为resourcemanager standby角色,因此在其yarn-site.xml,RM设为自己
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm2</value>
</property>
6.6 修改start-dfs.sh和 stop-dfs.sh文件
在/opt/hadoop-3.1.2/sbin/中,分别在 start-dfs.sh 和 stop-dfs.sh文件开始处添加如下内容
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
HDFS_ZKFC_USER=root
HDFS_JOURNALNODE_USER=root
# 以上内容在三个节点上配置
在start-yarn.sh和stop-yarn.sh文件头部添加如下命令
```shell
YARN_RESOURCEMANAGER_USER=root
HDFS_DATANODE_SECURE_USER=yarn
YARN_NODEMANAGER_USER=root
# 以上内容在三个节点上配置
至此,以及完成hadoop层面的HA的配置文件,因为属性项很多,配置过程务必仔细核对,否则启动各种出错。下面将逐步验证各项组件启动情况
7、集群启动
在第5节内容中,三个节点zk的QuorumPeerMain进程已正常启动
7.1 启动JournalNode进程
JournalNode服务三个节点启动都启动,因此,需在每个节点上单独运行启动命令,建议使用全局命令hdfs,否则得去每个节点的sbin目录下使用hadoop-daemon.sh
[root@nn ]# hdfs --daemon start journalnode
[root@nn opt]# jps
4889 JournalNode
4987 Jps
1775 QuorumPeerMain
若启动正常,jps可以看三个节点都启动了相应进程
7.2 格式化 NameNode和zkfc
这里的zkfc指:ZK Failover Controller daemon
在NameNode的nn主节点上进行
[root@nn opt]# hdfs namenode -format
# 成功提示
Storage directory /opt/hadoop-3.1.2/tmp/dfs/name has been successfully formatted.
[root@nn opt]# hdfs zkfc -formatZK
# 成功提示
: Successfully created /hadoop-ha/hdapp in ZK.
重要
在备机dn2节点上执行fsimge元数据同步命令
[root@dn2 sbin]# hdfs namenode -bootstrapStandby
# 可以看到namenode主从服务信息
=====================================================
About to bootstrap Standby ID dn2 from:
Nameservice ID: hdapp
Other Namenode ID: nn
Other NN's HTTP address: http://nn:50070
Other NN's IPC address: nn/192.188.0.4:9000
Namespace ID: 778809532
Block pool ID: **
Cluster ID:**
Layout version: -64
isUpgradeFinalized: true
=====================================================
# dn2节点通过http get去nn节点下载FsImage以便实现元数据同步
namenode.TransferFsImage: Opening connection to http://nn:50070/imagetransfer?getimage=1&txid=0&storageInfo=-64:778809532:***:CID-594d1106-a909-4e60-8a2d-d54e264beee2&bootstrapstandby=true
***
namenode.TransferFsImage: Downloaded file fsimage.ckpt_0000000000000000000 size 391 bytes.
7.3 启动ZookeeperFailoverController、HDFS、YARN
启动HA服务是有顺序的,需先启动ZKFC再启动HDFS,该服务管理hadoop的namenode主备切换;若先启动HDFS,则在未启动ZKFC进程之前,两个namenode都是standby模式,直到ZKFC启动后,HDFS才会正常进入HA主备模式。
# 1、启动主备切换服务,在nn、dn2分别执行
[root@nn sbin]# hdfs --daemon start zkfc
[root@dn2 sbin]# hdfs --daemon start zkfc
# DFSZKFailoverController进程
# 2、只需在主节点nn上操作执行
[root@nn sbin]# ./start-dfs.sh
# 验证:nn,dn2显示NN、DN、JN,dn1显示DN、JN
# 注意namenode节点的tmp/dfs目录必须具有以下三个目录,否则namenode启动失败,提示相关目录不存在
[root@dn2 dfs]# pwd
/opt/hadoop-3.1.2/tmp/dfs
[root@dn2 dfs]# ls
data journalnode name
# 3、只需在主节点nn上执行
[root@nn sbin]# /start-yarn.sh
# 验证:nn,dn2显示RN、NM,dn1显示NM
7.4 启动Application(job)History进程服务
# 启动JobHistoryServer
mapred --daemon start historyserver
JobHistoryServer的作用:
可以通过历史服务器查看已经运行完的Mapreduce作业记录,比如用了多少个Map、用了多少个Reduce、作业提交时间、作业启动时间、作业完成时间等信息。
7.5 使用命令或者web页面查看集群组件服务情况
# 在NameNode主节点nn上,用命令查看Namenode
[root@nn opt]# hdfs haadmin -getServiceState nn
active
[root@nn opt]# hdfs haadmin -getServiceState dn2
standby
在http://nn:50070查看nn状态(最好使用Chrome查看,用Firefox查看Utilities栏目-Browse the file system没响应)
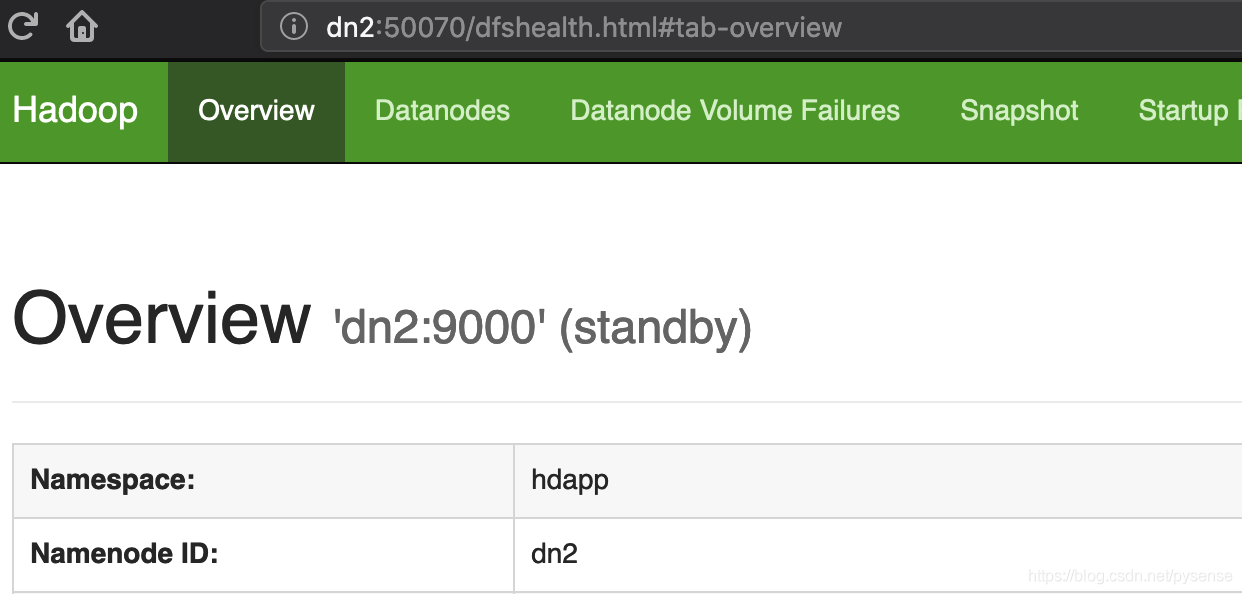
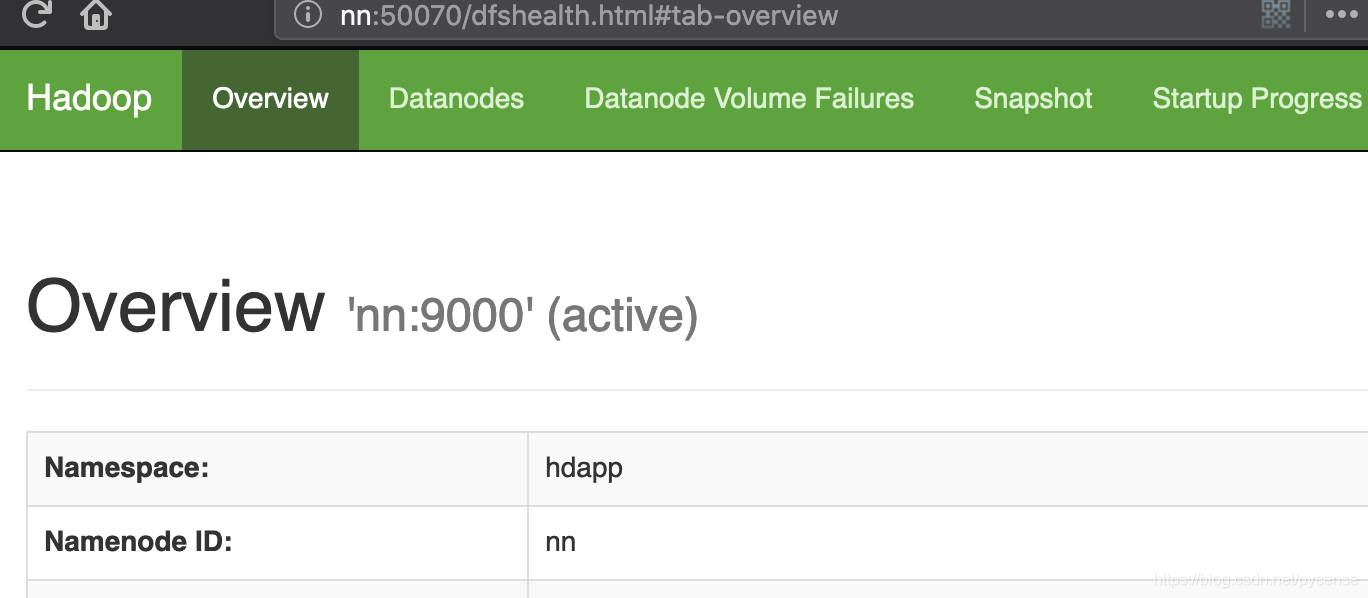 在http://dn2:50070查看dn2状态
在http://dn2:50070查看dn2状态
# 在NameNode主节点nn上,用命令查看RM节点主备状态
[root@nn opt]# yarn rmadmin -getServiceState rm1
standby
[root@nn opt]# yarn rmadmin -getServiceState rm2
active
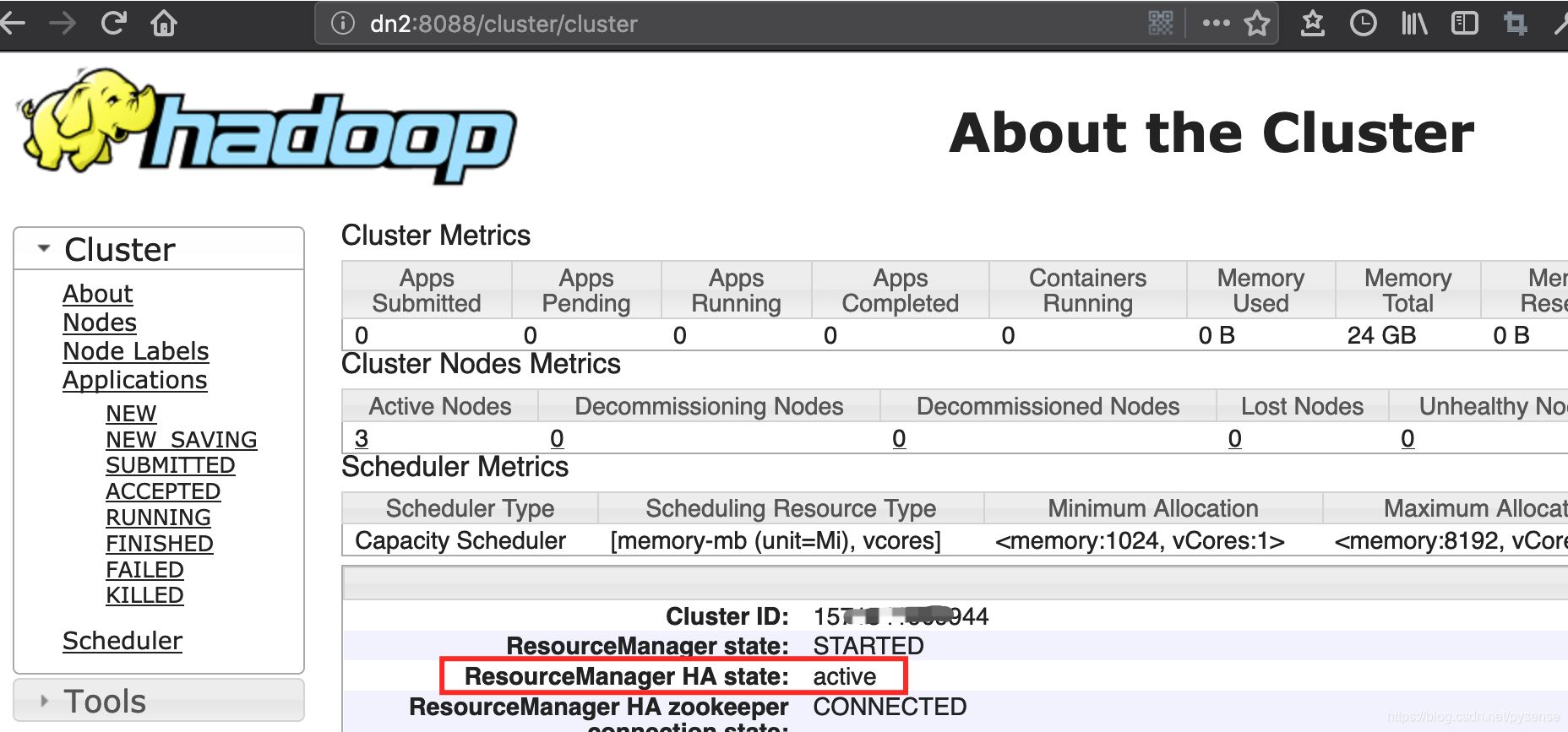
注意:这里显示是dn2(rm2)节点为active状态,当在浏览器输入http://nn:8088时,会自动被重定向到dn2的web服务:http://dn2:8088/cluster
7.6 hadoop主备切换测试
1)主备切换失败情况:
在切换测试之前,请先检查Linux系统上有无安装一个fuser的工具
fuser:fuser可用于查询文件、目录、socket端口和文件系统的使用进程,并且可以使用fuser关闭进程,当文件系统umount报device busy时,常用到fuser查询并关闭使用相应文件系统的进程。
在6.2章节hdfs-site.xml配置:
<!-- 一旦需要NameNode切换,使用ssh方式或者shell进行操作 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)</value>
</property>
以上表示fencing的方法目前有两种,sshfence和shell
sshfence方法是指通过ssh登陆到active namenode节点并kill了该namenode进程,因此需设置ssh免密登陆,还要保证有杀掉namenode进程的权限,以保证hadoop集群在任何时候只有一个namenode节点处于active状态。
如果Linux系统没有fuser工具,那么sshfence执行会提示提示
fuser: command not found
Fencing method org.apache.hadoop.ha.SshFenceByTcpPort(null) was unsuccessful.
该日志路径是在dn2作为standby节点的日志目录下:
/opt/hadoop-3.1.2/logs/hadoop-root-zkfc-dn2.log
导致主备无法正常切换,可能出现脑裂(例如两个namenode都是active模式或者standby模式)
2)解决方案:
只需安装fuser工具即可
yum install psmisc -y,安装之后,查看
[root@dn2 logs]# ls /usr/sbin/fuser
/usr/sbin/fuser
3)主备切换nn,dn2状态变更:
[root@nn sbin]# hdfs haadmin -getServiceState nn
active
[root@nn sbin]# hdfs haadmin -getServiceState dn2
standby
在主节点nn上,手动kill掉namenode进程,可以看到dn2立即变为active状态
[root@nn sbin]# jps
7424 NameNode
5585 JournalNode
5347 DataNode
6024 ResourceManager
5001 QuorumPeerMain
25322 JobHistoryServer
8922 Jps
6652 DFSZKFailoverController
6157 NodeManager
[root@nn sbin]# kill -9 7424
[root@nn sbin]# hdfs haadmin -getServiceState dn2
active
以上kill了nn的namenode进程,再启动该进程,看看nn能否变为standby模式
[root@nn ~]# hdfs --daemon start namenode
[root@nn ~]# hdfs haadmin -getServiceState nn
standby
# 或者使用强制转换主备命测试,注意因为是是测试环境,所以可以强制测试,如果已经在生产环境,请做好fsimage备份,否则可能主备的元数据不同步导致数据丢失。
[root@nn ~]# hdfs haadmin -getAllServiceState
nn:9000 active
dn2:9000 standby
[root@nn ~]# hdfs haadmin -transitionToStandby --forcemanual nn
[root@nn ~]# hdfs haadmin -getAllServiceState
nn:9000 standby
dn2:9000 active
可以看到启动NN服务后,nn自身成功转为standby模式。
同理,RM的主备切换和恢复的过程跟上述一致,这里不再赘述。
4)在zookeeper目录下查看hadoop HA建立的znode及其内容
注意:以下说的zk节点是指znode,是一种类似目录的路径,不是指hadoop节点(服务器),注意区分。
[root@nn opt]# zkCli.sh
# 查看zk的根节点/有哪些节点
[zk: localhost:2181(CONNECTED) 8] ls /
[zookeeper, yarn-leader-election, hadoop-ha]
# 查看hadoop-ha节点,可以看到子节点hdapp就是我们在hdfs-site.xml里配置的集群nameservices名称,若有多个集群,那么/hadoop-ha节点将有多个子节点
[zk: localhost:2181(CONNECTED) 9] ls /hadoop-ha
[hdapp]
# 继续查看子节点hdapp是否还有子节点:可以看到这是都active状态节点的信息
[zk: localhost:2181(CONNECTED) 11] ls /hadoop-ha/hdapp
[ActiveBreadCrumb, ActiveStandbyElectorLock]
# ABC是持久节点,ASE是临时节点,nn、dn2都在ASE注册监听临时节点删除事件
# 查看主备选举的锁节点存放在哪个节点地址
[zk: localhost:2181(CONNECTED) 7] get /hadoop-ha/hdapp/ActiveStandbyElectorLock
hdappdn2dn2 �F(�>
***
这里可以看到dn2节点抢到了ActiveStandbyElectorLock,因此作为active节点。
ActiveBreadCrumb持久节点用来防止脑裂设计,通过注册事件回调sshfence方法在另外一个节点上kill 掉NN进程
具体逻辑参考这篇文章的讨论:文章链接,内容还不错。
同样的yarn-leader-election选举处理逻辑也是借用zk节点特性和注册事件回调方法来实现,大体差不多。
至此负责底层分布式存储的Hadoop HA高可用已经完整实现,这部分是重点和难点,因此占了较大篇幅。此外这里还没给出HA管理员命令的使用以及理解:hdfs haadmin,不过这部分内容一般是hadoop集群运维部负责的工作,作为开发者的我们,也需要了解其中一部分内容。
接下来的关于HBase的主备配置则相对简单。
8、HBase的HA配置
8.1 配置conf
进入hbase-1.3.1/conf/目录,修改配置文件:
[root@nn conf]# pwd
/opt/hbase-2.1.7/conf
[root@nn conf]# pwd vi hbase-env.sh
# The java implementation to use. Java 1.8+ required.要求1.8以上的JDK
export JAVA_HOME=/opt/jdk1.8.0_161
# 禁用HBase自带的Zookeeper,使用独立部署Zookeeper
export HBASE_MANAGES_ZK=false
以上配置在三个节点上配置(其实只需在nn和dn2 HMaster节点配置),为了避免以后需将dn1作为主节点时因之前漏了配置导致启动服务各种报错。
8.2 配置hbase-site.xml
关于hbase-site的详细内容,可以参考:
Apache HBase Getting Started里面内容。
<configuration>
<!-- 设置HRegionServers共享的HDFS目录,必须设为在hdfs-site中dfs.nameservices的值:hdapp,而且不能有端口号,该属性会让hmaster在hdfs集群上建一个/hbase的目录 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hdapp/hbase</value>
</property>
<!-- 启用分布式模式 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 启用分布式模式时,以下的流能力加强需设为false -->
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<!-- 指定Zookeeper集群位置,值可以是hostname或者hostname:port -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>nn,dn1,dn2</value>
</property>
<!-- 指定独立Zookeeper安装路径 -->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/zookeeper-3.4.14</value>
</property>
<!-- 指定ZooKeeper集群端口 -->
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
</configuration>
以上配置在三个节点配上
注意:有部分有关HBaseHA配置技术博客文章中,有人会把hbase.rootdir配成以下形式:
# 直接指定hdfs的主节点
<property>
<name>hbase.rootdir</name>
<value>hdfs://nn:9000/hbase</value>
</property>
<!-- 直接指定主的HMaster服务 -->
<property>
<name>hbase.master</name>
<value>hdfs://nn:60000</value>
</property>
接着他们还会在/opt/hbase-2.1.7/conf创建一个文件
vi backup-master
# 内容为hbase的备机服务器,例如本文的dn2节点
dn2
这种配法不是hbase HA的方式,是官方配置给出的单机模式
5.1.1. Standalone HBase over HDFS
A sometimes useful variation on standalone hbase has all daemons running inside the one JVM but rather than persist to the local filesystem, instead they persist to an HDFS instance.
....
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://namenode.example.org:8020/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>false</value>
</property>
</configuration>
这种配法容易导致HBase服务退出:一旦nn节点从active状态切换为standby或者宕机,即使dn2对外提供hdfs服务,但hbase只认nn为active状态,并且会提示出错:
Operation category READ is not supported in state standby,也即没有可用的hdfs文件服务提供给HMaster进程去读,最后导致hbase异常退出。
8.3 编辑regionservers
修改regionservers文件,因为当前是使用独立的Zookeeper集群,所以要指定RegionServers所在机器,按规划,三个节点都是RS角色:
[root@nn conf]# pwd
/opt/hbase-2.1.7/conf
[root@nn conf]# vi regionservers
nn
dn1
dn2
以上配置在三个节点配上
8.4 创建hdfs-site.xml的软链到hbase的conf目录下
[root@nn conf]# ln -s /opt/hadoop-3.1.2/etc/hadoop/hdfs-site.xml /opt/hbase-2.1.7/conf/hdfs-site.xml
[root@nn conf]# pwd
/opt/hbase-2.1.7/conf
[root@nn conf]# ll hdfs-site.xml
lrwxrwxrwx. 1 root root 42 ** hdfs-site.xml -> /opt/hadoop-3.1.2/etc/hadoop/hdfs-site.xml
该操作在三个节点上都要执行,这一环节的配置非常关键,HBase团队也给出相关解释:
Procedure: HDFS Client Configuration
Of note, if you have made HDFS client configuration changes on your Hadoop cluster, such as configuration directives for HDFS clients, as opposed to server-side configurations, you must use one of the following methods to enable HBase to see and use these configuration changes:
Add a pointer to your HADOOP_CONF_DIR to the HBASE_CLASSPATH environment variable in hbase-env.sh.
Add a copy of hdfs-site.xml (or hadoop-site.xml) or, better, symlinks, under ${HBASE_HOME}/conf, or
if only a small set of HDFS client configurations, add them to hbase-site.xml.
An example of such an HDFS client configuration is dfs.replication. If for example, you want to run with a replication factor of 5, HBase will create files with the default of 3 unless you do the above to make the configuration available to HBase.
目的是为了HBase能够同步hdfs配置变化,例如上面提到当hdfs副本数改为5时,如果不创建这种配置映射,那么HBase还是按默认的3份去执行。
若缺少这个软链接,HBase启动集群服务有问题,部分RS无法启动!
8.5 启动HBase集群遇到的问题
1) HMaster是否有顺序
首先,hbase的HA模式是工作在hdfs HA模式下,因此首先保证hdfs HA为正常状态。其次,HMaster无需在hdfs主节点上先启动,在standby节点也可以先启动,但每个HMaster的节点需独立运行start-hbase.sh。
2) 在启动HBase期间,相关出错的解决
A、HMaster进程启动正常,但是提示slf4j jar包存在多重绑定
SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/opt/hadoop-3.1.2/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/hbase-2.1.7/lib/client-facing-thirdparty/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
解决:其实该提示不影响HMaster和HRegionServer进程,可以选择忽略
B、启动HMaster短暂几秒后异常退出,日志提示找不到相关class:java.lang.NoClassDefFoundError: org/apache/htrace/SamplerBuilder
解决办法,将htrace-core-3.1.0-incubating.jar拷到lib目录下,
$HBASE_HOME/为环境变量配置HBase路径:
cp $HBASE_HOME/lib/client-facing-thirdparty/htrace-core-3.1.0-incubating.jar $HBASE_HOME/lib/
C、两个节点的HMaster进程都正常运行,但所有HRegionServer进程会自动退出
原因:集群服务器之间的时间不同步导致,
解决办法:时间做同步
# 将硬件时间写到系统时间
[root@dn1 ~]# hwclock -s
保存时钟
[root@dn1 ~]# clock -w
或者增加与master之间的时钟误差宽容度(不建议)
<property>
<name>hbase.master.maxclockskew</name>
<value>150000</value>
</property>
8.6 查看HBase集群信息
1)首先查看各个节点已经启动的服务
nn节点(HMaster、HRegionServer):
[root@nn opt]# jps
5585 JournalNode
5347 DataNode
23844 NameNode
26839 Jps
6024 ResourceManager
25322 JobHistoryServer
5001 QuorumPeerMain
26026 HMaster
6652 DFSZKFailoverController
6157 NodeManager
26191 HRegionServer
dn1节点(HRegionServer):
[root@dn1 opt]# jps
12917 HRegionServer
8074 JournalNode
7979 DataNode
7886 QuorumPeerMain
8191 NodeManager
13183 Jps
dn2节点(HMaster、HRegionServer):
[root@dn2 conf]# jps
3200 NodeManager
18416 Jps
16339 NameNode
25322 JobHistoryServer
17827 HMaster
2869 DataNode
3973 DFSZKFailoverController
17686 HRegionServer
2698 QuorumPeerMain
2970 JournalNode
2)可通过web页面查看hbase主备情况
A、http://nn:16010显示nn为master,dn2为backup master,拥有3个RS
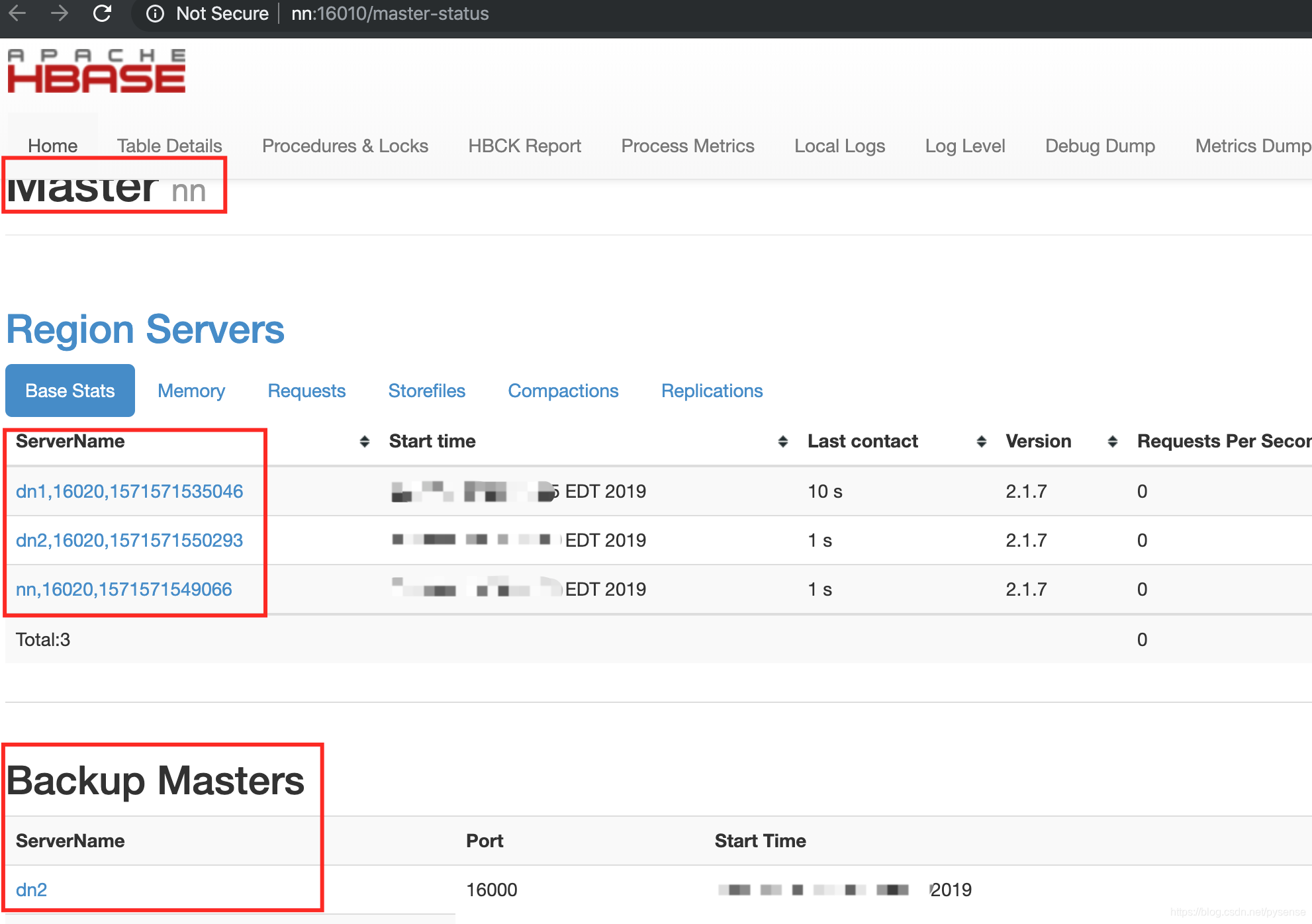 B、
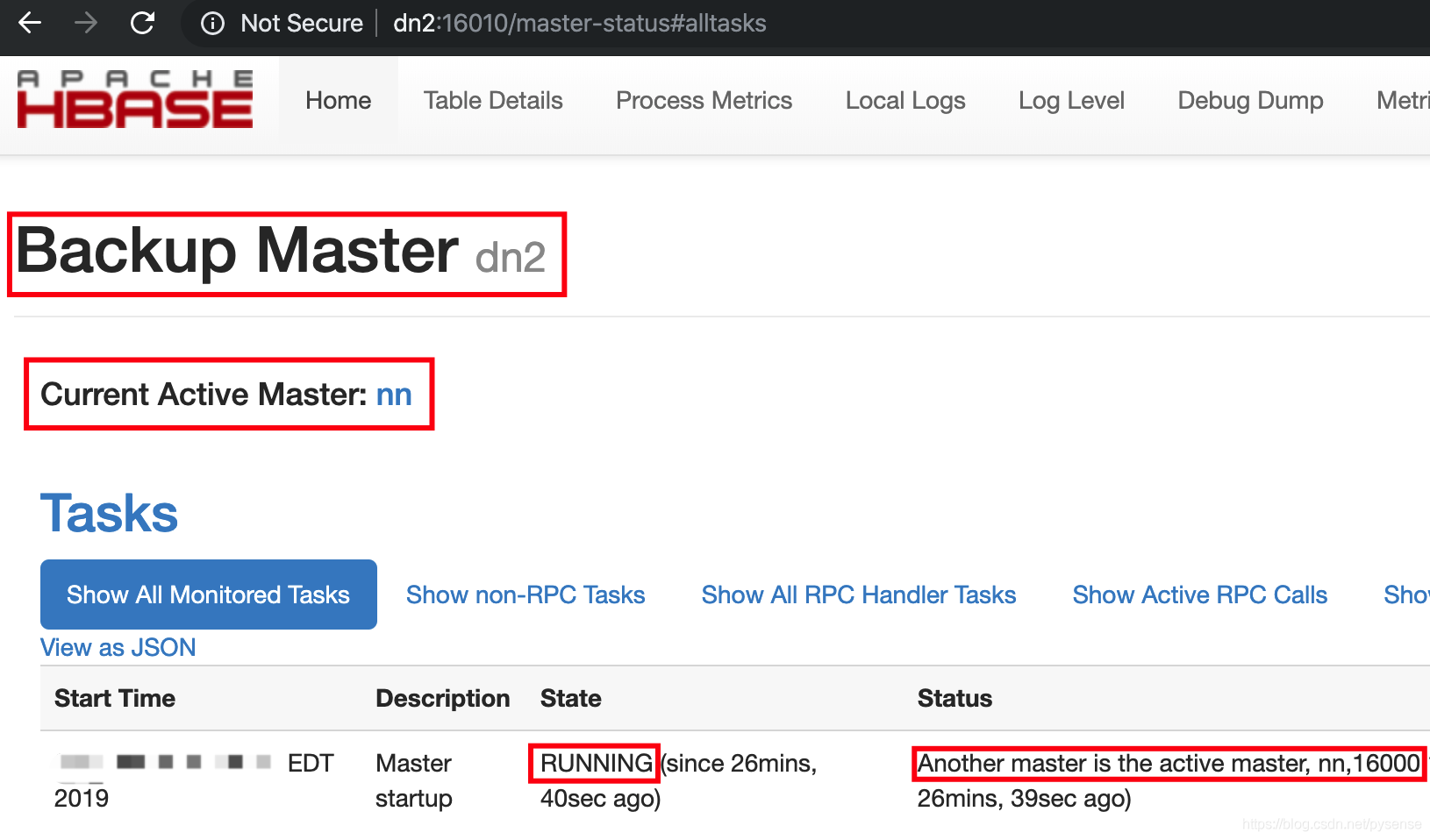
B、http://dn2:16010显示dn2为backup master,当前active master为nn节点
 C、在zookeeper上查看
C、在zookeeper上查看
[root@nn opt]# zkCli.sh
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper, yarn-leader-election, hadoop-ha, hbase]
以上可以看到hbase znode以及其他znode
继续查看/hbase子路径
[zk: localhost:2181(CONNECTED) 1] ls /hbase
[meta-region-server, rs, splitWAL,
backup-masters, table-lock, flush-table-proc,
master-maintenance, online-snapshot,
switch, master, running, draining,
namespace, hbaseid, table]
以上可以看出hbase的集群服务器非常依赖zookeeper组件!!
查看hbase节点的RS路径列表
[zk: localhost:2181(CONNECTED) 4] ls /hbase/rs
[dn2,16020,1571571550293, nn,16020,1571571549066, dn1,16020,1571571535046]
[zk: localhost:2181(CONNECTED) 5] get /hbase/rs/dn1,16020,1571571535046
�regionserver:16020&�Q��PBU�}�
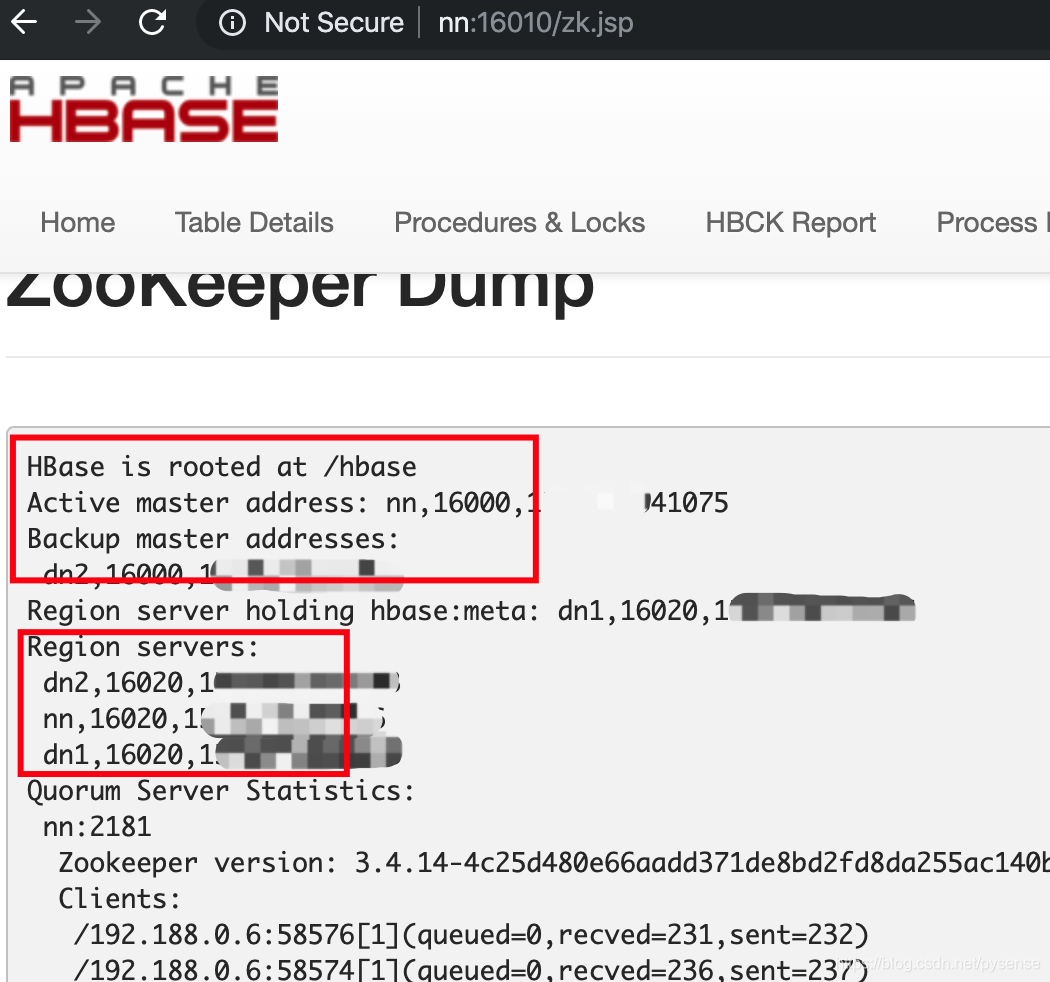
注意:在zkCli客户端get 相关path的内容因编码问题查看时会显示乱码,可通过hbase web端口查看zk内容
8.7 HBase 主备切换测试
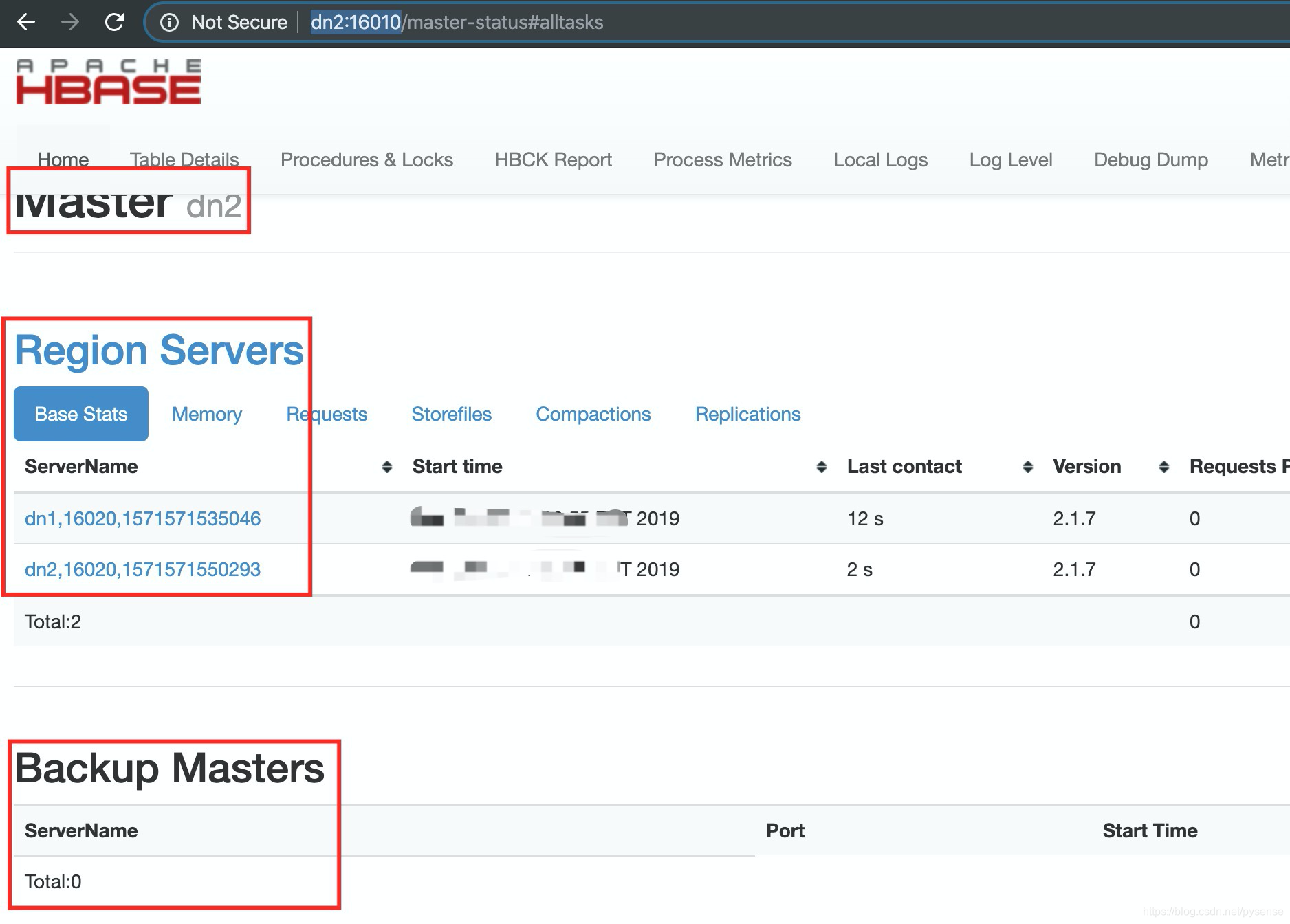
1)kill掉 nn节点的HMaster,查看dn2是否转为active master
[root@nn ~]# jps
26026 HMaster
[root@nn ~]# kill -9 26026
在http://dn2:16010查看主备情况,可以看到nn节点down后,dn2成为master hbase节点
 2)将nn恢复Hbase服务,查看nn的HMaster是否为backup状态
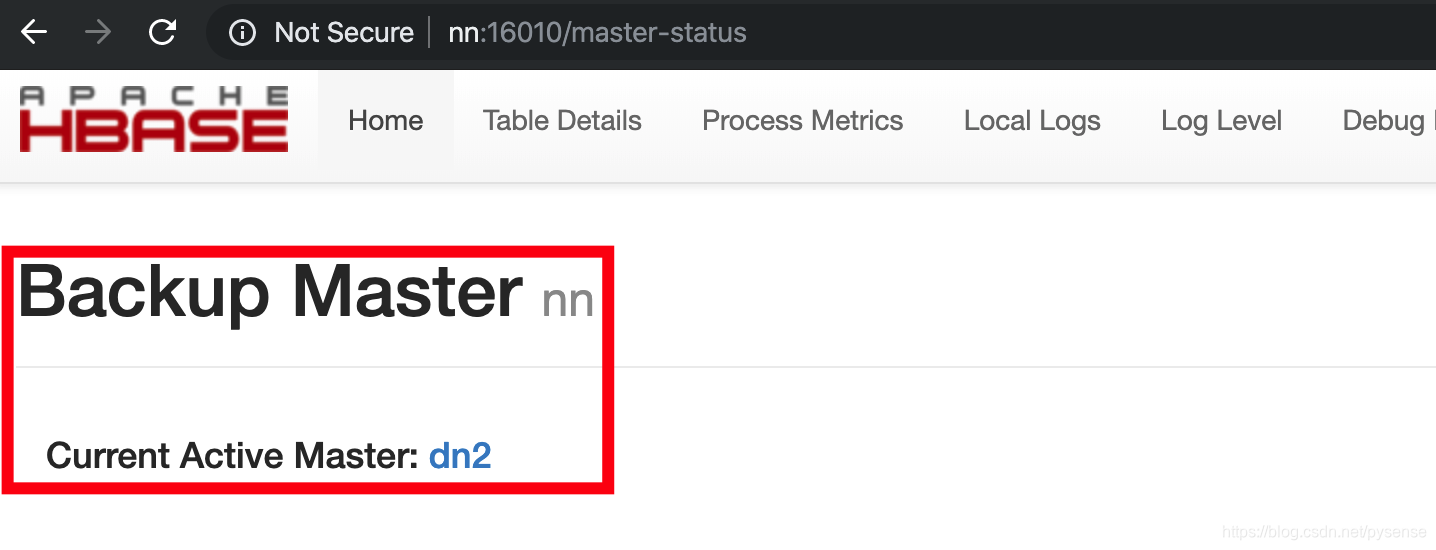
2)将nn恢复Hbase服务,查看nn的HMaster是否为backup状态
在nn节点上执行
[root@nn bin]# pwd
/opt/hbase-2.1.7/bin
[root@nn bin]# ./hbase-daemon.sh start master
查看http://nn:16010,可以看到nn节点已经作为backup master,dn2节点为active master
 在http://dn2:16010也可查看。
在http://dn2:16010也可查看。
3)强制转换底层hdfs主备状态,查看hbase HA状态
把nn强制变为standby,hbase 主:nn,hbase:dn2
[root@nn conf]# hdfs haadmin -transitionToStandby --forcemanual nn
把dn2强制变为standby,hbase 主:nn,hbase:dn2
[root@nn conf]# hdfs haadmin -transitionToStandby --forcemanual dn2
hbase的主从状态不受底层hdfs主从变化影响,因为对于hbase来说,它只知道集群hdfs服务: hdfs://hdapp/hbase并没有改变。
至此,本文已经成功搭建了hadoop HA、yarn HA以及HBase HA服务,过程详细,积累不少经验,为之后本人给出大数据应用最核心内容之一——"数据应用开发"铺了很好的基础。
小结:所有服务的启动顺序如下所示
完整启动顺序
1、分别在三台服务器上启动zookeeper
[root@nn sbin]# zkServer.sh start
# 三个服务器均可看到QuorumPeerMain进程
2、在nn和dn2主节点上,启动zkfc
[root@nn sbin]# hdfs --daemon start zkfc
# 在nn和dn2主节点上,均可看到DFSZKFailoverController进程
3、在主nn节点上,运行start-dfs.sh,无需在其他节点再运行该命令
[root@nn sbin]# ./start-dfs.sh
# 可以看到NameNode、DataNode、journalnode服务
4、在主nn节点上,运行start-yarn.sh,无需在其他节点再运行该命令
[root@nn sbin]# ./start-yarn.sh
# 可以看到ResourceManager、NodeManager服务
5、在nn、dn2主节点上,启动JobHistoryServer服务
[root@nn bin]# mapred --daemon start historyserver
# jps看到JobHistoryServer服务
6、在nn、dn2主节点上,启动hbase服务
# nn节点启动hbase
[root@nn bin]# ./start-hbase.sh
# 在dn2节点上启动hbase,
[root@dn2 bin]# ./start-hbase.sh
# HMaster\HRegionServer
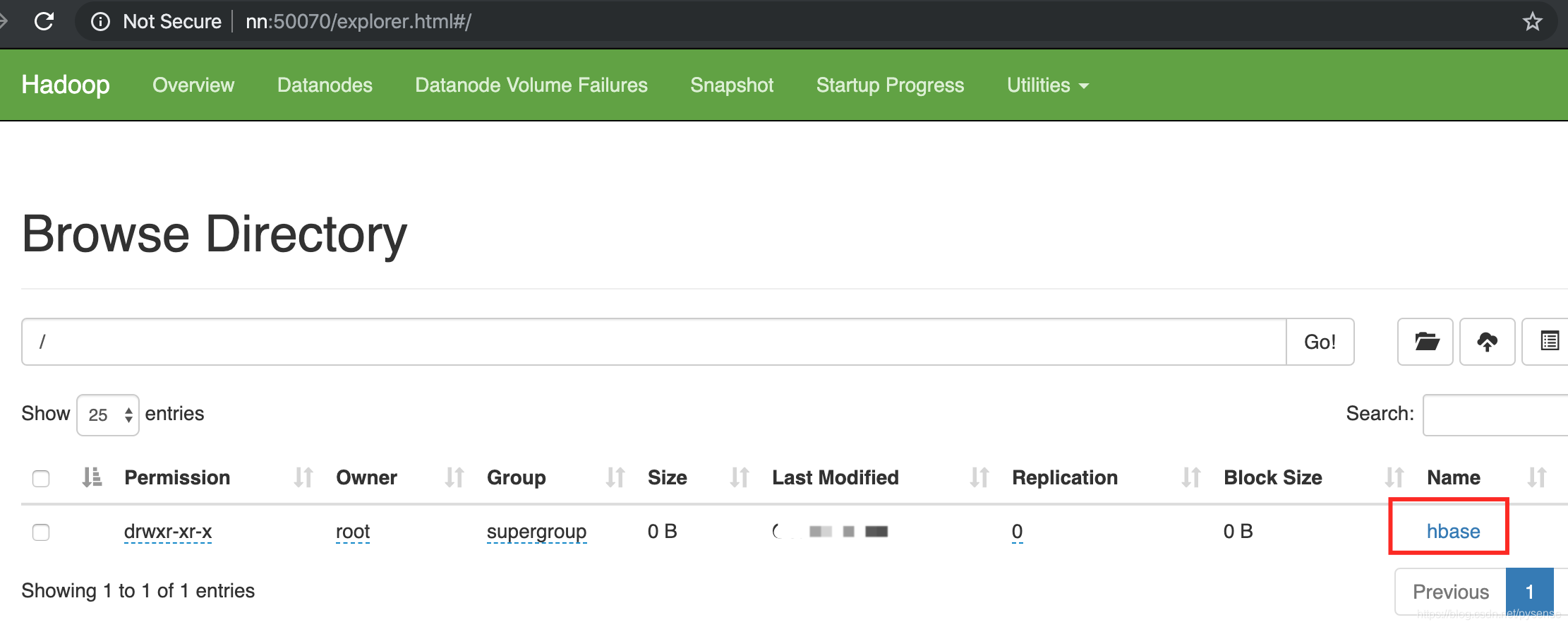
9、HBase在hdfs创建的目录
 /hbase目录下的内容
/hbase目录下的内容
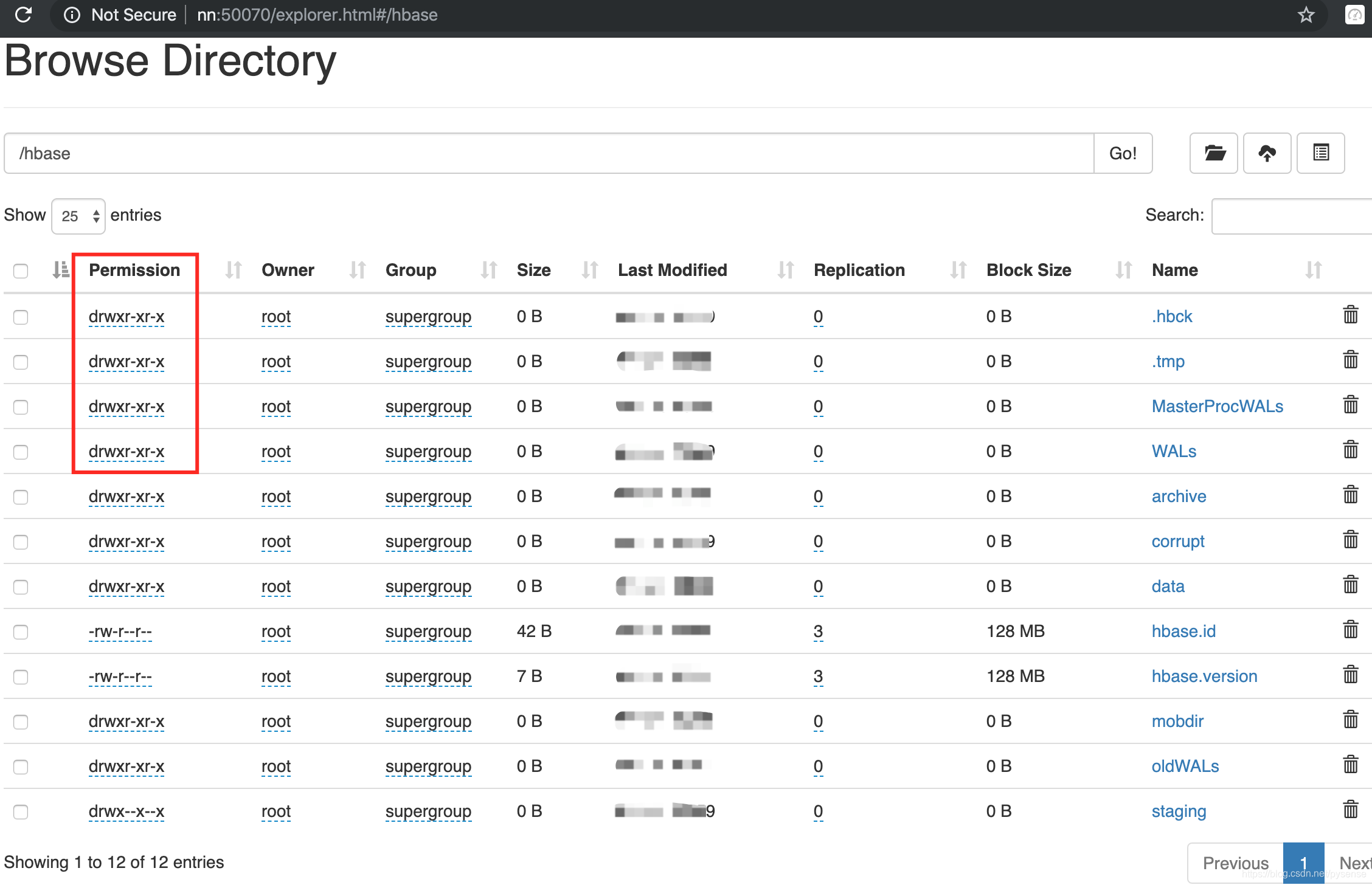 关于这些文件的解释以及作用,将在下一篇HBase架构原理给出。
关于这些文件的解释以及作用,将在下一篇HBase架构原理给出。
10、在HBase创建table测试
这部分内容回到大家相对熟悉的数据库知识领域,本节内容仅提供基础demo用法,关于HBase的数据结构以及架构原理,本博客将在另外一篇文章进行深入讨论。
以下company表为例进行基本操作,该表包含staff_info和depart_info两个列簇,表结构如下所示:
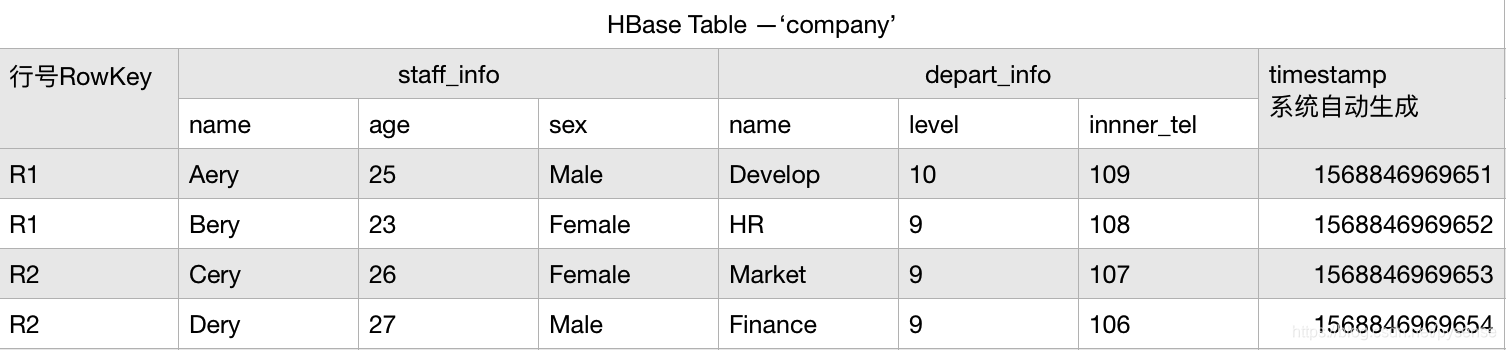 以下为基本的hbase使用:
以下为基本的hbase使用:
# 进入HBase进行交互式操作
[root@nn ~] hbase shell
# 创建company表,从这里即可看出列数据库的优势,无需预先定义列,表结构是松散灵活的,之后想加多少列都行。
hbase(main):> create 'company','staff_info','depart_info'
# 查看当前HBase有哪些表
hbase(main):> list
#获得表company的描述信息
hbase(main):> describe 'company'
# 查看全表数据,相当于selec * from company
hbase(main):> scan 't_user'
# 往表插入数据,语法 put 't' ,'r', 'c', 'v' (表名,行rowkey,列簇:具体列,值)
# 第1行记录
hbase(main):> put 'company' ,'R1','staff_info:name','Aery'
hbase(main):> put 'company' ,'R1','staff_info:age','25'
hbase(main):> put 'company' ,'R1','staff_info:sex','Male'
hbase(main):> put 'company' ,'R1','depart_info:name','Develop'
hbase(main):> put 'company' ,'R1','depart_info:level','10'
hbase(main):> put 'company' ,'R1','depart_info:inner_tel','109'
# 第2行记录
hbase(main):> put 'company' ,'R1','staff_info:name','Bery'
hbase(main):> put 'company' ,'R1','staff_info:age','23'
hbase(main):> put 'company' ,'R1','staff_info:sex','Female'
hbase(main):> put 'company' ,'R1','depart_info:name','HR'
hbase(main):> put 'company' ,'R1','depart_info:level','9'
hbase(main):> put 'company' ,'R1','depart_info:inner_tel','108'
# 第3行记录
hbase(main):> put 'company' ,'R2','staff_info:name','Cery'
hbase(main):> put 'company' ,'R2','staff_info:age','26'
hbase(main):> put 'company' ,'R2','staff_info:sex','female'
hbase(main):> put 'company' ,'R2','depart_info:name','Market'
hbase(main):> put 'company' ,'R2','depart_info:level','9'
hbase(main):> put 'company' ,'R2','depart_info:inner_tel','107'
# 第4行记录
hbase(main):> put 'company' ,'R2','staff_info:name','Dery'
hbase(main):> put 'company' ,'R2','staff_info:age','27'
hbase(main):> put 'company' ,'R2','staff_info:sex','Male'
hbase(main):> put 'company' ,'R2','depart_info:name','Finance'
hbase(main):> put 'company' ,'R2','depart_info:level','9'
hbase(main):> put 'company' ,'R2','depart_info:inner_tel','106'
# 获取数据,有以下几种方式
# 这里cell已经包含timestamp和value
hbase(main):038:0> get 'company','R1'
COLUMN cell
depart_info:inner_tel timestamp=**, value=108
depart_info:level timestamp=**, value=9
depart_info:name timestamp=**, value=HR
staff_info:age timestamp=**, value=23
staff_info:name timestamp=**, value=Bery
staff_info:sex timestamp=**, value=Female
1 row(s)
Took 0.0427 seconds
hbase(main):039:0> get 'company','R2','staff_info'
COLUMN CELL
staff_info:age timestamp=** value=27
staff_info:name timestamp=**, value=Dery
staff_info:sex timestamp=**, value=Male
1 row(s)
hbase(main):> get 'company','R1','staff_info:age'
COLUMN CELL
staff_info:age timestamp=**, value=23
1 row(s)
# 计算company rowkey数目
hbase(main):041:0> count 'company'
2 row(s)
Took 0.1696 seconds
# 删除R2中的部门信息的level列 hbase(main):072:0> delete 'company','R2','depart_info:level'
# 清空表内容
hbase(main)> truncate 'company'
# 禁用表,之后drop表才有效
hbase(main):> disable 'company'
hbase(main):> drop 'company'
hbase(main):> exists 'company'
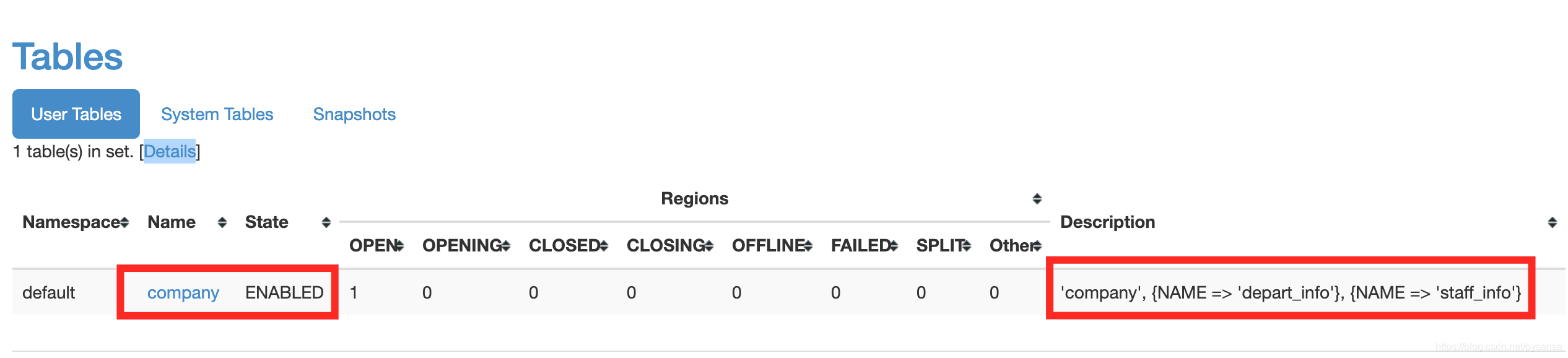
company表的信息也可以在HMaster web端查看
 以上为基本的hbase表操作,如果用shell的方式开发hbase数据应用,效率是非常低的,就像直接在mysql的shell写复杂sql、在Oracle的shell写sql那样,虽然很raw,但不友好。而对于mysql的sql开发,大家会用workbench或者DBeaver;对于Oracle的开发,大家会用PL/SQL Developer;在程序业务逻辑开发层面,大家会引入DB-API 第三方库实现业务逻辑开发。
以上为基本的hbase表操作,如果用shell的方式开发hbase数据应用,效率是非常低的,就像直接在mysql的shell写复杂sql、在Oracle的shell写sql那样,虽然很raw,但不友好。而对于mysql的sql开发,大家会用workbench或者DBeaver;对于Oracle的开发,大家会用PL/SQL Developer;在程序业务逻辑开发层面,大家会引入DB-API 第三方库实现业务逻辑开发。
那么对于HBase分布式数据库的开发,需要用到Hive工具。
Hive是建立在 Hadoop 上的数据仓库基础构架,它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),通过Hive,用户可以类 SQL 查询语言(又称 HQL)去“操作Hbase上的数据”,省去独自开发mapper 和 reducer 来处理计算任务(当然复杂的业务逻辑还是需要开发mapper和reducer)。
本博客将在后面的文章中,引入Hive组件,配合HBase进行某个主题的大数据实际项目开发。
