1.数组切片和列表切片最大的区别是
数组切片不会创建原数组的副本,而列表切片是创建原数组的副本再进行操作
import numpy as np a = np.array([0,1,2,3]) b = a[:2] b[:] = 5 #必须写成b[:]切片形式才有此效果,如果写成b=5,相当于重新定义了变量b,a不会发生修改 print(a) #输出[5 5 2 3]
此外还需要注意numpy数组没有append,insert等操作
对于列表:
a = [0, 1, 2, 3] b = a[:2] b[1] = 0 #列表不可以写成b[:]=0,多对一无法实现,只能写成一对一的形式 print(a) #输出[0, 1, 2, 3]
2.布尔型数值组成的Numpy数组不能使用and,or等逻辑语句,只能使用&,| 等符号进行与,或运算
import numpy as np a = np.array([True,True,False]) b = np.array([False,False,False]) print(a and b) #报错 ValueError: The truth value of an array with more than one element is ambiguous. Use a.any() or a.all()
print(a & b)
输出:[False False False]
布尔型数值组成的列表可以使用and,or等语句,但是不能使用&,| 等符号
3.numpy中的meshgrid()函数
给定值是两个一维数组,返回两个2维数组,规模是n*m,其中m是第一个一维数组的元素个数,n为第二个一维数组的元素个数
import numpy as np x = np.array([1,2,3]) y = np.array([4,5]) X,Y = np.meshgrid(x,y) #输入只要是两个向量,x.T和y.T,x.T和y,或者x,y.T都可以 print(X) print(Y)
输出:
[[1 2 3]
[1 2 3]]
[[4 4 4]
[5 5 5]]

目的就是为了形成(1,4),(1,5),(2,4),(2,5),(3,4),(3,5)
图片加以理解:
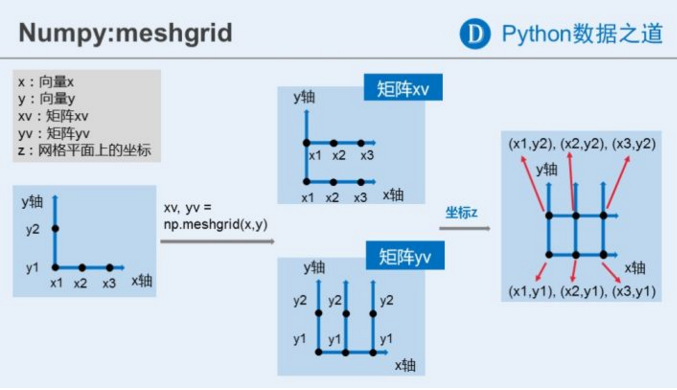
此时我们要求每个点的(x**2 + y**2)再开根号就方便了:
z = np.sqrt(X**2 + Y**2) print(z)
输出:
[[ 4.12310563 4.47213595 5. ]
[ 5.09901951 5.38516481 5.83095189]]
4.numpy中的where()函数,使用方法是where(c, x, y),表达的意思是x if c else y
import numpy as np a = np.array([1.1, 1.2, 1.3, 1.4, 1.5]) b = np.array([2.1, 2.2, 2.3, 2.4, 2.5]) cond = np.array([True, False, True, True, False]) c = np.where(cond, a, b) print(c)
输出:[ 1.1 2.2 1.3 1.4 2.5]
5.数据进行统计计算的函数sum(),mean()等既可以作为数组的实例方法调用,也可以当作numpy函数使用
import numpy as np a = np.array( [ [1,2,3],[4,5,6],[7,8,9] ] ) print(a.mean()) #也可以mean(a) print(a.sum()) #也可以sum(a)输出:5,45 输出的都是单个的值,表明是对整个数组数据进行求平均和求和
当然,也可以设定axis的值来对行或者对列求统计值:
import numpy as np a = np.array( [ [1,2,3],[4,5,6],[7,8,9] ] ) print(a.mean(axis=0)) #0是对列 print(a.sum(axis=1)) #1是对行[ 4. 5. 6.]
[ 6 15 24]
输出的都是一维数组,跟矩阵不一样
cumsum():累加,cumprod():累乘
import numpy as np a = np.array( [ [1,2,3],[4,5,6],[7,8,9] ] ) print(a.cumsum()) print(a.cumprod())[ 1 3 6 10 15 21 28 36 45]
[ 1 2 6 24 120 720 5040 40320 362880]
也可以设置axis=0或1来表示对列或行进行累加或累乘
import numpy as np a = np.array( [ [1,2,3],[4,5,6],[7,8,9] ] ) print(a.cumsum(0)) print(a.cumprod(1))
[[ 1 2 3]
[ 5 7 9]
[12 15 18]]
[[ 1 2 6]
[ 4 20 120]
[ 7 56 504]]
6.用于布尔值数组的方法:
import numpy as np a = np.random.randn(100) b = (a > 0).sum() #计算True的个数 print(b) c = np.array([False,False,True,False]) print(c.any()) #判断是否存在True 返回True或False print(c.all()) #判断是否全是True 返回True或False
7.numpy排序
import numpy as np a = np.array([3,2,1]) print(np.sort(a)) print(a.sort())
[1 2 3]
None
a.sort()返回的不是排序后的数组,所以打印后显示None,此外还可以设置sort(0)或sort(1)
一般情况下,使用numpy中的函数就可以了,即使用np.函数处理数据
8.numpy的unique()和inld()函数
unique()函数作用是找出数组中的唯一值并返回已经排序的结果
import numpy as np a = np.array([7,7,9,8,9,3,2,2,1]) print(np.unique(a))
[1 2 3 7 8 9]
inld()函数作用是测试一个数组中的值是否在另一个数组中
import numpy as np a = np.array([2,2,6]) b = np.array([1,2,3,4,5,6]) print(np.in1d(b,a)) #a,b也可以是列表
[False True False False False True]
9.数组文件的输入输出
np.save()和np.load()
import numpy as np
a = np.arange(10)
np.save('a',a) #会生成一个a.npy的文件
b = np.load('a.npy')
print(b)
print(type(b))[0 1 2 3 4 5 6 7 8 9]
<class 'numpy.ndarray'>
用np.savez()函数将多个数组文件保存,需要将数组以关键字形式传入
import numpy as np
a1 = np.arange(10)
b2 = np.array([5,6,7,8,9])
np.savez('array.npz', first=a1, second=b2) #直接写成a1,b1无效,必须有关键字
c = np.load('array.npz') #读取后c和字典很类似
print(c['first'])
print(c['second'])[0 1 2 3 4 5 6 7 8 9]
[5 6 7 8 9]
10.存取文本文件
loadtxt()函数:
def loadtxt(fname, dtype=float, comments='#', delimiter=None,
converters=None, skiprows=0, usecols=None, unpack=False,
ndmin=0)
读取文本数据并以','进行分隔,返回一个数组
import numpy as np
arr = np.loadtxt('array_ex.txt', delimiter=',')
print(arr)
print(type(arr))[[ 0.580052 0.18673 1.040717 1.134411]
[ 0.194163 -0.636917 -0.938659 0.124094]
[-0.12641 0.268607 -0.695724 0.047428]
[-1.484413 0.004176 -0.744203 0.005487]
[ 2.302869 0.200131 1.670238 -1.88109 ]
[-0.19323 1.047233 0.482803 0.960334]]
<class 'numpy.ndarray'>
savetxt()函数将数组写入以某种分隔符隔开的文本文件中
def savetxt(fname, X, fmt='%.18e', delimiter=' ', newline='\n', header='',
footer='', comments='# ')
import numpy as np
a = np.array([ [1,2,3],[4,5,6],[7,8,9] ])
np.savetxt('a.txt', a, delimiter=',')
生成一个a.txt,各数据以逗号分隔
11.数组的矩阵运算
np.dot()
import numpy as np a = np.ones(3) b = np.array([ [1,2,3], [4,5,6] ]) c = np.dot(a,b.T) print(c)
[ 6. 15.]
numpy的linalg中含有很多矩阵操作功能
求逆矩阵:
import numpy as np a = np.array([ [1,0,0],[0,2,0],[0,0,4] ]) b = np.linalg.inv(a) print(b)[[ 1. 0. 0. ]
[ 0. 0.5 0. ]
[ 0. 0. 0.25]]
12.随机数生成
numpy中的random随机数生成函数功能比python内置的random功能更多,生成数据的速度更快
如生成正太分布数据的函数 normal(loc=0.0, scale=1.0, size=None),默认均值为0,方差为1
import numpy as np a = np.random.normal( size=(4,4) ) print(a)[[ 0.37423214 0.10064227 -0.32502402 1.05846288]
[ 1.06319701 0.64538982 -0.26448237 1.76489601]
[ 0.00886072 -0.4398564 0.38044241 -1.89089555]
[ 1.10915967 0.17004274 0.44308969 0.49378569]]
13.实例:模拟随机漫步
import numpy as np nsteps = 1000 draws = np.random.randint(0, 2, size=nsteps) steps = np.where(draws>0, 1, -1) #生成1000个随机1,-1,1相当于向前走,-1相当于向后走 walk = np.cumsum(steps) #累加后可以看出最多向前走了多少步,向后走了多少步 print(np.min(walk)) print(np.max(walk))
想要知道第一次走了里起点超过10步(正负方向都可以),可以利用np.argmax()函数
def argmax(a, axis=None, out=None),返回第一个最大值的索引,即如有2个最大值,则返回第一个最大值索引,也可以作用于布尔值数组,返回的是第一个True的索引
firstmax = np.abs(walk >= 10).argmax() print(firstmax)
同时模拟5000组1000次的随机漫步:
import numpy as np nsteps = 1000 num = 5000 draws = np.random.randint(0, 2, size=(num, nsteps)) steps = np.where(draws>0, 1, -1) walk = np.cumsum(steps, axis=1) print(walk.max()) #找到全部组的最大值 print(walk.min()) #找到全部组的最小值
#判断每组是否有达到离起点30步的 reach30 = np.abs(walk >= 30).any(1) total = reach30.sum() print(total)
输出共有1680组随机漫步达到了离起点30步
#选出达到30步的组别,然后再找到每组的最短时间 times = np.abs( walk[reach30] >= 30).argmax(1) mean_time = np.mean(times) print(mean_time) #计算平均时间