本文参考整理自:https://www.cnblogs.com/jackjoin/p/8878199.html
1. 数据的处理函数
1.1 数学函数
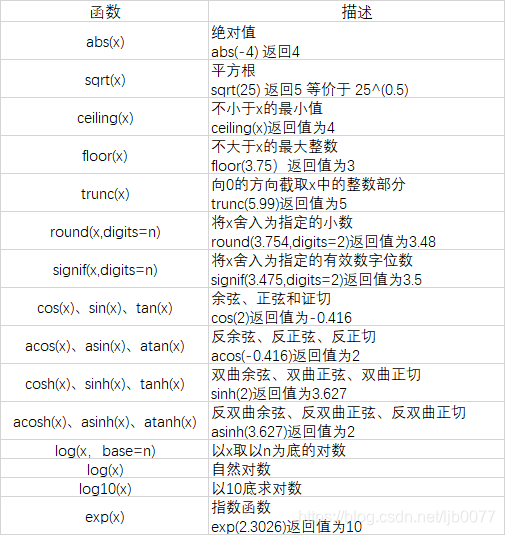
1.2 统计函数

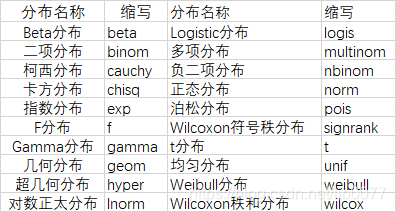
1.3 概率函数
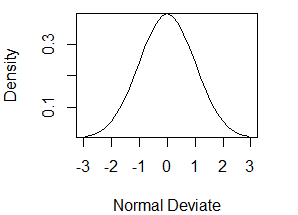
#绘制正太分布曲线
x<-pretty(c(-3,3),30)
y<-dnorm(x)
plot(x,y,type="l",xlab="Normal Deviate",ylab="Density",yaxs="i")
1.4 字符处理函数


a<-5
sqrt(a)
[1] 2.24
b<-c(1.243,5.654,2.99)
round(b)
[1] 1 6 3
c<-matrix(runif(12),nrow=3)
c
[,1] [,2] [,3] [,4]
[1,] 0.9636 0.216 0.289 0.913
[2,] 0.2068 0.240 0.804 0.353
[3,] 0.0862 0.197 0.378 0.931
log(c)
[,1] [,2] [,3] [,4]
[1,] -0.0371 -1.53 -1.241 -0.0912
[2,] -1.5762 -1.43 -0.218 -1.0402
[3,] -2.4511 -1.62 -0.972 -0.0710
mean(c)
[1] 0.465
#apply()函数的应用
apply(x,MARGIN,FUN,……)
x为数据对象,margin是维度的下标,FUN为自己制定的函数
mydata<-matrix(rnorm(30),nrow=6)
mydata
[,1] [,2] [,3] [,4] [,5]
[1,] 0.459 1.203 1.234 0.591 -0.281
[2,] -1.261 0.769 -1.891 -0.435 0.812
[3,] -0.527 0.238 -0.223 -0.251 -0.208
[4,] -0.557 -1.415 0.768 -0.926 1.451
[5,] -0.374 2.934 0.388 1.087 0.841
[6,] -0.604 0.935 0.609 -1.944 -0.866
#计算每行的平均值
apply(mydata,1,mean)
[1] 0.641 -0.401 -0.194 -0.136 0.975 -0.374
#计算每列的平均值
apply(mydata,2, mean)
[1] -0.478 0.777 0.148 -0.313 0.292
#计算每行的结尾均值
apply(mydata,2,mean,trim=0.2)
[1] -0.516 0.786 0.386 -0.255 0.291
数据处理难题的解决方案
#限定输出的小数点后的数字的位数为2
options(digits=2)
Student<-c("John Davis","Angela Williams","Bullwinkle Moose","David Jones","Janice Markhammer","Cheryl Cushing","Reuven Ytzrhak","Greg Knox","Joel England","Joel England")
Math<-c(502,600,412,538,512,492,410,625,573,522)
Science<-c(95,99,80,82,75,85,80,95,89,86)
English<-c(25,22,18,15,20,28,15,30,27,18)
roster<-data.frame(Student,Math,Science,English)
#将变量标准化
z<-scale(roster[,2:4])
#输出的结果为:
Math Science English
[1,] -0.234 1.078 0.587
[2,] 1.145 1.591 0.037
[3,] -1.500 -0.847 -0.697
[4,] 0.273 -0.590 -1.247
[5,] -0.093 -1.489 -0.330
[6,] -0.374 -0.205 1.137
[7,] -1.528 -0.847 -1.247
[8,] 1.497 1.078 1.504
[9,] 0.765 0.308 0.954
[10,] 0.048 -0.077 -0.697
#求各行的平均值
score<-apply(z,1,mean)
#将平均值放到花名册中
roster<-cbind(roster,score)
#寻找成绩的分界点
y<-quantile(score,c(0.8,0.6,0.4,0.2))
roster$grade[score>=y[1]]<-"A"
roster$grade[score<y[1]&score>=y[2]]<-"B"
roster$grade[score<y[2]&score>=y[3]]<-"C"
roster$grade[score<y[3]&score>=y[4]]<-"D"
#拆分字符串
name<-strsplit((roster$Student)," ")
#提取拆分的字符串
Lastname<-sapply(name, "[",2)
Firstname<-sapply(name, "[",1)
#将拆分的字符串添加到花名册中,并删除name
roster<-cbind(Firstname,Lastname,roster[,-1])
roster<-roster[order(Lastname,Firstname),]
roster
#输出结果
Student Math Science English score grade
John Davis 502 95 25 0.48 B
Angela Williams 600 99 22 0.92 A
Bullwinkle Moose 412 80 18 -1.01 <NA>
David Jones 538 82 15 -0.52 D
Janice Markhammer 512 75 20 -0.64 D
Cheryl Cushing 492 85 28 0.19 C
Reuven Ytzrhak 410 80 15 -1.21 <NA>
Greg Knox 625 95 30 1.36 A
Joel England 573 89 27 0.68 B
Joel England 522 86 18 -0.24 C
1.5 其他实用函数
书上的函数有length():获取向量或数组的长度
seq():生成一个数组序列,如seq(1,10,2):生成从1-10之间的数,每次递增2
rep(1:3, 3):将1-3重复生成3次
cut()、pretty()、cat()函数。
1.6 将函数应用于矩阵和数据框
就在说apply()函数,写一下:
apply(X, MARGIN, FUN, ...) #对阵列行或者列使用函数
#X是一个数组、矩阵或者数据框
#MARGIN 1或者2 表示行或者列
#FUN是作用于每一行或列的函数
#如果FUN是R中的函数,函数名称后面接着加参数就行
#如果是自己编的就自己编好了,这个函数用的很多
apply {base}
通过对数组或者矩阵的一个维度使用函数生成值得列表或者数组、向量。
apply(X, MARGIN, FUN, …)
X 阵列,包括矩阵
MARGIN 1表示矩阵行,2表示矩阵列,也可以是c(1,2)
例:
> xxx<-matrix(1:20,ncol=4)
> apply(xxx,1,mean)
[1] 8.5 9.5 10.5 11.5 12.5
> apply(xxx,2,mean)
[1] 3 8 13 18
> xxx
[,1] [,2] [,3] [,4]
[1,] 1 6 11 16
[2,] 2 7 12 17
[3,] 3 8 13 18
[4,] 4 9 14 19
[5,] 5 10 15 20
lapply 和 sapply 是应用在list上的函数。
- lapply {base}
通过对x的每一个元素运用函数,生成一个与元素个数相同的值列表
lapply(X, FUN, …)
X表示一个向量或者表达式对象,其余对象将被通过as.list强制转换为list
例:
> x <- list(a = 1:10, beta = exp(-3:3), logic = c(TRUE,FALSE,FALSE,TRUE))
> x
$a
[1] 1 2 3 4 5 6 7 8 9 10
$beta
[1] 0.04978707 0.13533528 0.36787944 1.00000000 2.71828183 7.38905610
[7] 20.08553692
$logic
[1] TRUE FALSE FALSE TRUE
> lapply(x,mean)
$a
[1] 5.5
$beta
[1] 4.535125
$logic
[1] 0.5
- sapply {base}
这是一个用户友好版本,是lapply函数的包装版。该函数返回值为向量、矩阵,如果simplify=”array”,且合适的情况下,将会通过simplify2array()函数转换为阵列。sapply(x, f, simplify=FALSE, USE.NAMES=FALSE)返回的值与lapply(x,f)是一致的。
sapply(X, FUN, …, simplify = TRUE, USE.NAMES = TRUE)
X表示一个向量或者表达式对象,其余对象将被通过as.list强制转换为list
simplify 逻辑值或者字符串,如果可以,结果应该被简化为向量、矩阵或者高维数组。必须是命名的,不能是简写。默认值是TRUE,若合适将会返回一个向量或者矩阵。如果simplify=”array”,结果将返回一个阵列。
USE.NAMES 逻辑值,如果为TRUE,且x没有被命名,则对x进行命名。
例:
> sapply(k, paste,USE.NAMES=FALSE,1:5,sep="...")
[,1] [,2] [,3]
[1,] "a...1" "b...1" "c...1"
[2,] "a...2" "b...2" "c...2"
[3,] "a...3" "b...3" "c...3"
[4,] "a...4" "b...4" "c...4"
[5,] "a...5" "b...5" "c...5"
> sapply(k, paste,USE.NAMES=TRUE,1:5,sep="...")
a b c
[1,] "a...1" "b...1" "c...1"
[2,] "a...2" "b...2" "c...2"
[3,] "a...3" "b...3" "c...3"
[4,] "a...4" "b...4" "c...4"
[5,] "a...5" "b...5" "c...5"
> sapply(k, paste,USE.NAMES=TRUE,1:5,sep="...",simplyfy=TRUE)
a b c
[1,] "a...1...TRUE" "b...1...TRUE" "c...1...TRUE"
[2,] "a...2...TRUE" "b...2...TRUE" "c...2...TRUE"
[3,] "a...3...TRUE" "b...3...TRUE" "c...3...TRUE"
[4,] "a...4...TRUE" "b...4...TRUE" "c...4...TRUE"
[5,] "a...5...TRUE" "b...5...TRUE" "c...5...TRUE"
> sapply(k, paste,simplify=TRUE,USE.NAMES=TRUE,1:5,sep="...")
a b c
[1,] "a...1" "b...1" "c...1"
[2,] "a...2" "b...2" "c...2"
[3,] "a...3" "b...3" "c...3"
[4,] "a...4" "b...4" "c...4"
[5,] "a...5" "b...5" "c...5"
> sapply(k, paste,simplify=FALSE,USE.NAMES=TRUE,1:5,sep="...")
$a
[1] "a...1" "a...2" "a...3" "a...4" "a...5"
$b
[1] "b...1" "b...2" "b...3" "b...4" "b...5"
$c
[1] "c...1" "c...2" "c...3" "c...4" "c...5"
2. 控制流
2.1 重复和循环
for和while格式:
for(i in c(1:10)) {expr}
while(cond) {expr}
例:
> for(i in 1:5) print("Hello")
[1] "Hello"
[1] "Hello"
[1] "Hello"
[1] "Hello"
[1] "Hello"
> x <- 3
> while(x > 0) {print("Hello");x <- x-1}
[1] "Hello"
[1] "Hello"
[1] "Hello"
注意:尽量避免循环,尽量使用R内置函数,比如apply族函数。
2.2 条件执行
-
语句(
statement)是一条单独的R语句或者一组符合的语句(包含在花括号{}中的一组R语句,使用分号分隔) -
条件(
cond)是一条最终被解释为真或假的表达式 -
表达式(
expr)是一天数值或字符串的求值语句 -
序列(
seq)是一个数值或字符串序列 -
if-else结构
格式:
if(cond)
statement1
else
statement2
示例:
> x <- 1
> if(x !=1) print("male") else print("female")
[1] "female"
- ifelse结构
格式:ifelse(cond, statement1, statement2)
示例:
> ifelse(x>1, print("male"), print("female"))
[1] "female"
[1] "female"
- switch结构
格式:
switch(expr,...)
#这里的expr是判断条件,后面的...是对应expr的不同情况的执行情况
示例:
> feeling <- c("sad", "afraid")
> for(i in feeling)
+ print(switch(i, happy="I am glad", afraid="fear", sad="cheer up"))
[1] "cheer up"
[1] "fear"
如果i是happy,就输出I am glad,如果i是afraid,就输出fear,如果i是sad,就输出cheer up。
#for循环重复执行一个语句,直到某个变量的值不再包含在序列seq中为止。
for(var in seq) statement
for(i in 1:10) print("Hello")
#单词Hello被输出了10次
#while结构
#while循环从重复地执行一个语句,直到条件不为真为止。
while(cond) statement
i<-10
while(i>0){print("Hello");i<-i-1}
#if-else结构
#控制结构if-else在某个给定条件为真时执行语句。也可以同时在条件为假时执行另一条语句。
if(cond) statement
if(cond) statement1 else statement2
if(is.character(grade)) grade<-as.factor(grade)
if(!is.factor(grade)) grade<-as.factor(grade) else print("Grade already is a factor")
#ifelse结构是if-else结构比较紧凑的向量画版本
ifelse(cond,statement1,statement2)
ifelse(score>0.5,print("Passed"),print("Failed"))
#switch根据一个表达式的值选择语句执行
switch(expr,……)
feelings<-c("sad","afraid")
feelings<-c("sad","afraid")
for(i in feelings)
print(
switch(i,
happy="I am glad you are happy",
afraid="There is nothing to fear",
sad="Cheer up",
angry="Calm down now"
)
)
[1] "Cheer up"
[1] "There is nothing to fear"
2.3 用户自定义函数
格式:
#函数的基本结构
myfunction<-function(arg1,arg2,……){
statements
return(object)
}
#函数实例
#函数实例
mystats<-function(x,parametric=TRUE,print=FALSE){
if(parametric){
center<-mean(x);
spread<-sd(x)
}else{
center<-median(x);
spread<-mad(x)
}
if(print¶metric){
cat("Mean=",center,"\n","SD=",spread,"\n")
}else if(print&!parametric){
cat("Median=",center,"\n","MAD=",spread,"\n")
}
result<-list(center=center,spread=spread)
return(result)
}
set.seed(1234)
x<rnorm(500)
y<-mystats(x)
print(y)
#输出结果
print(y)
80% 60% 40% 20%
0.73 0.30 -0.35 -0.71
#含有switch的自定义函数
mydate<-function(type="long"){
switch(type,
long=format(Sys.time(),"%A %B %Y"),
short=format(Sys.time(),"%m-%d-%y"),
cat(type,"is not a recognized type\n"))
}
mydate("long")
[1] "星期四 四月 2018"
mydate("short")
[1] "04-19-18"
mydate()
[1] "星期四 四月 2018"
mydate("medium")
medium is not a recognized type
3. 整合和重构
#数据集的转置
> cars<-mtcars[1:5,1:4]
> cars
mpg cyl disp hp
Mazda RX4 21.0 6 160 110
Mazda RX4 Wag 21.0 6 160 110
Datsun 710 22.8 4 108 93
Hornet 4 Drive 21.4 6 258 110
Hornet Sportabout 18.7 8 360 175
> #利用t()函数转置
> t(cars)
Mazda RX4 Mazda RX4 Wag Datsun 710 Hornet 4 Drive Hornet Sportabout
mpg 21 21 22.8 21.4 18.7
cyl 6 6 4.0 6.0 8.0
disp 160 160 108.0 258.0 360.0
hp 110 110 93.0 110.0 175.0
#数据集的整合
> options(digits=3)
> attach(mtcars)
> aggdata<-aggregate(mtcars,by=list(cyl,gear),FUN=mean,na.rm=TRUE)
> aggdata
Group.1 Group.2 mpg cyl disp hp drat wt qsec vs am gear carb
1 4 3 21.5 4 120 97 3.70 2.46 20.0 1.0 0.00 3 1.00
2 6 3 19.8 6 242 108 2.92 3.34 19.8 1.0 0.00 3 1.00
3 8 3 15.1 8 358 194 3.12 4.10 17.1 0.0 0.00 3 3.08
4 4 4 26.9 4 103 76 4.11 2.38 19.6 1.0 0.75 4 1.50
5 6 4 19.8 6 164 116 3.91 3.09 17.7 0.5 0.50 4 4.00
6 4 5 28.2 4 108 102 4.10 1.83 16.8 0.5 1.00 5 2.00
7 6 5 19.7 6 145 175 3.62 2.77 15.5 0.0 1.00 5 6.00
8 8 5 15.4 8 326 300 3.88 3.37 14.6 0.0 1.00 5 6.00
在结果中,Group.1表示气缸数量(4,6,8),Group.2代表档位数(3,4,5)。举例来说,拥有4个气缸和3个档位车型的每加仑汽油行驶英里数均值为21.5
重构和整合数据集的万能工具-reshape2
ID<-c(1,1,2,2)
Time<-c(1,2,1,2)
X1<-c(5,3,6,2)
X2<-c(6,5,1,4)
mydata<-data.frame(ID,Time,X1,X2)
mydata
#输出结果为
ID Time X1 X2
1 1 5 6
1 2 3 5
2 1 6 1
2 2 2 4
library(reshape2)
md<-melt(mydata,id=c("ID","Time"))
md
#输出结果
ID Time variable value
1 1 X1 5
1 2 X1 3
2 1 X1 6
2 2 X1 2
1 1 X2 6
1 2 X2 5
2 1 X2 1
2 2 X2 4
#执行整合
dcast(md,ID~variable,mean)
ID X1 X2
1 4 5.5
2 4 2.5
dcast(md,Time~variable,mean)
Time X1 X2
1 5.5 3.5
2 2.5 4.5
dcast(md,ID~Time,mean)
ID 1 2
1 5.5 4
2 3.5 3
dcast(md,ID+Time~variable)
ID Time X1 X2
1 1 5 6
1 2 3 5
2 1 6 1
2 2 2 4
dcast(md,ID+variable~Time)
ID variable 1 2
1 X1 5 3
1 X2 6 5
2 X1 6 2
2 X2 1 4
dcast(md,ID~variable+Time)
ID X1_1 X1_2 X2_1 X2_2
1 5 3 6 5
2 6 2 1 4
