一、概念
NoSQL 最开始表示反SQL运动,用新型的非关系数据库取代关系数据库。但是现在NoSQL变成了not only SQL,不仅仅是关系型SQL,现在表示关系和非关系数据库都有优缺点,彼此都无法互相取代。
二、NoSQL数据库特点
- 灵活的可扩展性
- 灵活的数据模型
- 与云计算的完美融合
三、NoSQL数据技术出现的原因
关系数据库在这个海量数据的时代情形下,无法满足Web2.0的需求,主要体现在:
- 无法满足海量数据的管理需求
- 无法满足数据高并发的需求
- 无法满足高扩展和高可用的需求

四、NoSQL技术和关系数据库的比较
| 比较标准 | RDBMS | NoSQL | 备注 |
|---|---|---|---|
| 数据库原理 | 完全支持 | 部分支持 | RDBMS有关系代数理论作为基础,NoSQL没有统一的理论基础 |
| 数据规模 | 大 | 超大 | RDBMS很难实现横向扩展,纵向扩展的空间也比较有限,性能会随着数据规模的增大而降低,NoSQL可以很容易通过添加更多设备来支持更大规模的数据 |
| 数据库模式 | 固定 | 灵活 | RDBMS需要定义数据库模式,严格遵守数据定义和相关约束条件;NoSQL不存在数据库模式,可以自由灵活定义并存储各种不同类型的数据 |
| 查询效率 | 快 | 可以实现高效的简单查询,但是不具备高度结构化查询等特征,复杂查询的性能较慢 | RDBMS借助于索引机制可以实现快速查询(包括记录查询和范围查询)很多NoSQL数据库没有面向复杂查询的索引,虽然NoSQL可以使用MapReduce来加速查询,但是,在复杂查询方面的性能仍然不如RDBMS |
| 一致性 | 强一致性 | 弱一致性 | RDBMS严格遵守事务ACID模型,可以保证事务强一致性,很多NoSQL数据库放松了对事务ACID四性的要求,而是遵守BASE模型,只能保证最终一致性 |
| 数据完整性 | 容易实现 | 很难实现 | 任何一个RDBMS都可以很容易实现数据完整性,比如通过主键或者非空约束来实现实体的完整性,通过主键、外键来实现参照完整性,通过约束和触发器来实现用户自定义完整性;但是NoSQL数据库很难以实现 |
| 扩展性 | 一般 | 好 | RDBMS很难实现横向扩展,纵向扩展的空间也比较有限NoSQL在设计之初就充分考虑了横向扩展的需求,可以很容易通过添加廉价设备实现扩展 |
| 可用性 | 好 | 很好 | RDBMS在任何时候都以保证数据一致性为优先目标,其次才是优化系统性能,随着数据规模的增大,RDBMS为了保证严格的一致性,只能提供相对较弱的可用性大多数NoSQL都能提供较高的可用性 |
| 标准化 | 是 | 否 | RDBMS已经标准化(SQL),NoSQL还没有行业标准,不同的NoSQL数据库都有自己的查询语言,很难规范应用程序接口,可能会拉慢NoSQL的发展 |
| 技术支持 | 高 | 低 | RDBMS经过十几年的发展,已经非常成熟了,Oracle等大型厂商都可以提供很好的技术支持;NoSQL在技术支持方面仍处于起步阶段,还不够成熟,缺乏有力的技术支持 |
| 可维护性 | 复杂 | 复杂 | RDBMS需要专门的数据管理员(DBA)维护 NoSQL数据库虽然没有RDBMS复杂,但是也难以维护 |
五、NoSQL数据库的主要类型
按照存储方式分类
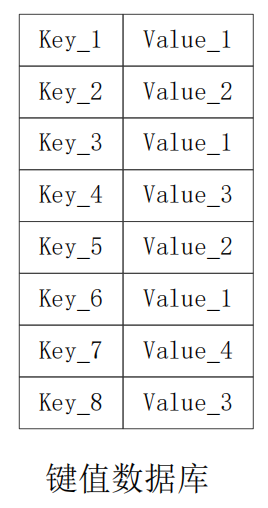
- 键值数据库
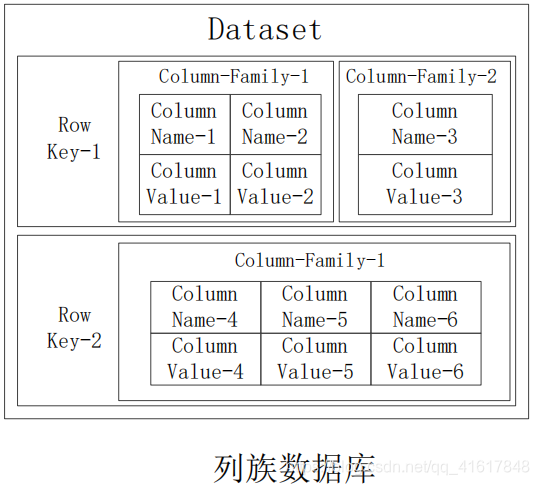
- 列族数据库
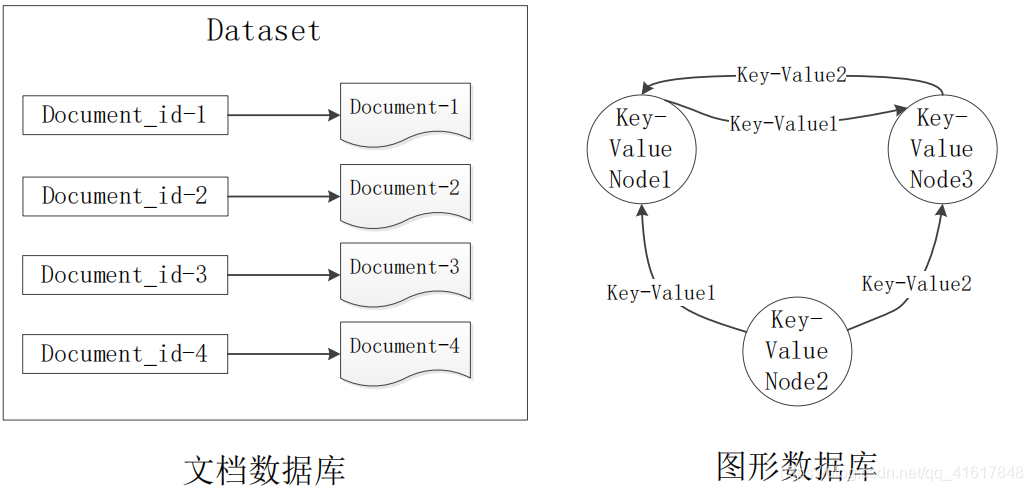
- 文档数据库
- 图形数据库
六、NoSQL数据库的代表产品

七、简单谈不同类型的NoSQL
| 相关产品 | Redis、Riak、SimpleDB、Chordless、Scalaris、Memcached |
|---|---|
| 数据模型 | 键/值对 键是一个字符串对象 值可以是任意类型的数据,比如整型、字符型、数组、列表、集合等 |
| 典型应用 | 涉及频繁读写、拥有简单数据模型的应用 内容缓存,比如会话、配置文件、参数、购物车等 存储配置和用户数据信息的移动应用 |
| 优点 | 扩展性好,灵活性好,大量写操作时性能高 |
| 缺点 | 无法存储结构化信息,条件查询效率较低 |
| 不适用情形 | 不是通过键而是通过值来查:键值数据库根本没有通过值查询的途径 需要存储数据之间的关系:在键值数据库中,不能通过两个或两个以上的键 来关联数据 需要事务的支持:在一些键值数据库中,产生故障时,不可以回滚 |
| 使用者 | 百度云数据库(Redis)、GitHub(Riak)、BestBuy(Riak)、Twitter (Redis和Memcached)、StackOverFlow(Redis)、Instagram (Redis)、Youtube(Memcached)、Wikipedia(Memcached) |
| 相关产品 | BigTable、HBase、Cassandra、HadoopDB、GreenPlum、PNUTS |
| 数据模型 | 列族 |
| 典型应用 | 分布式数据存储与管理 数据在地理上分布于多个数据中心的应用程序 可以容忍副本中存在短期不一致情况的应用程序 拥有动态字段的应用程序 拥有潜在大量数据的应用程序,大到几百TB的数据 |
| 优点 | 查找速度快,可扩展性强,容易进行分布式扩展,复杂性低 |
| 缺点 | 功能较少,大都不支持强事务一致性 |
| 不适用情形 | 需要ACID事务支持的情形,Cassandra等产品就不适用 |
| 使用者 | Ebay(Cassandra)、Instagram(Cassandra)、NASA(Cassandra)、Twitter(Cassandra and HBase)、Facebook(HBase)、Yahoo!(HBase) |
| 相关产品 | MongoDB、CouchDB、Terrastore、ThruDB、RavenDB、SisoDB、RaptorDB、CloudKit、Perservere、Jackrabbit |
|---|---|
| 数据模型 | 键/值 值(value)是版本化的文档 |
| 典型应用 | 存储、索引并管理面向文档的数据或者类似的半结构化数据 比如,用于后台具有大量读写操作的网站、使用JSON数据结构的应用、使用嵌套结构等非规范化数据的应用程序 |
| 优点 | 性能好(高并发),灵活性高,复杂性低,数据结构灵活 提供嵌入式文档功能,将经常查询的数据存储在同一个文档中 既可以根据键来构建索引,也可以根据内容构建索引 |
| 缺点 | 缺乏统一的查询语法 |
| 不适用情形 | 在不同的文档上添加事务。文档数据库并不支持文档间的事务,如果对这方面有需求则不应该选用这个解决方案 |
| 使用者 | 百度云数据库(MongoDB)、SAP (MongoDB)、Codecademy(MongoDB)、Foursquare (MongoDB)、NBC News (RavenDB) |
八、图数据库
| 相关产品 | Neo4J、OrientDB、InfoGrid、Infinite Graph、GraphDB |
|---|---|
| 数据模型 | 图结构 |
| 典型应用 | 专门用于处理具有高度相互关联关系的数据,比较适合于社交网络、模型识别、依赖分析、推荐系统路径寻路等问题 |
| 优点 | 灵活性高,支持复杂的图算法,可用于构建复杂的关系图谱 |
| 缺点 | 复杂性高,只能支持一定的数据规模 |
| 使用者 | Adobe(Noe4j)、Cisco(Neo4J)、T-Mobile(Neo4J) |
九、NoSQL的三大基石
- C(Consistency):一致性
- A:(Availability):可用性
- P:(Tolerance of Network Partition):分区容忍性
但是一个分布式系统不可能同时满足一致性、可用性、分区容忍性这三个需求,最多只能同时满足其中两个,正所谓“鱼和熊掌不可兼得”!
不同的产品在CAP的理论下的不同设计原则:

十、HBase分布式数据库
今天着重学习Hbase分布式的架构和使用原理!
1.HBase访问的接口:
| 类型 | 特点 | 场合 |
|---|---|---|
| Native Java API | 最常规和高效的访问方式 | 适合Hadoop MapReduce作业并行批处理HBase表数据 |
| HBase Shell | HBase的命令行工具,最简单的接口 | 适合HBase管理使用 |
| Thrift Gateway | 利用Thrift序列化技术,支持C++、PHP、Python等多种语言 | 适合其他异构系统在线访问HBase表数据 |
| REST Gateway | 解除了语言限制 | 支持REST风格的Http API访问HBase |
| Pig | 使用Pig Latin流式编程语言来处理HBase中的数据 | 适合做数据统计 |
| Hive | 简单 | 当需要以类似SQL语言方式访问HBase的时候 |
2.HBase数据模型
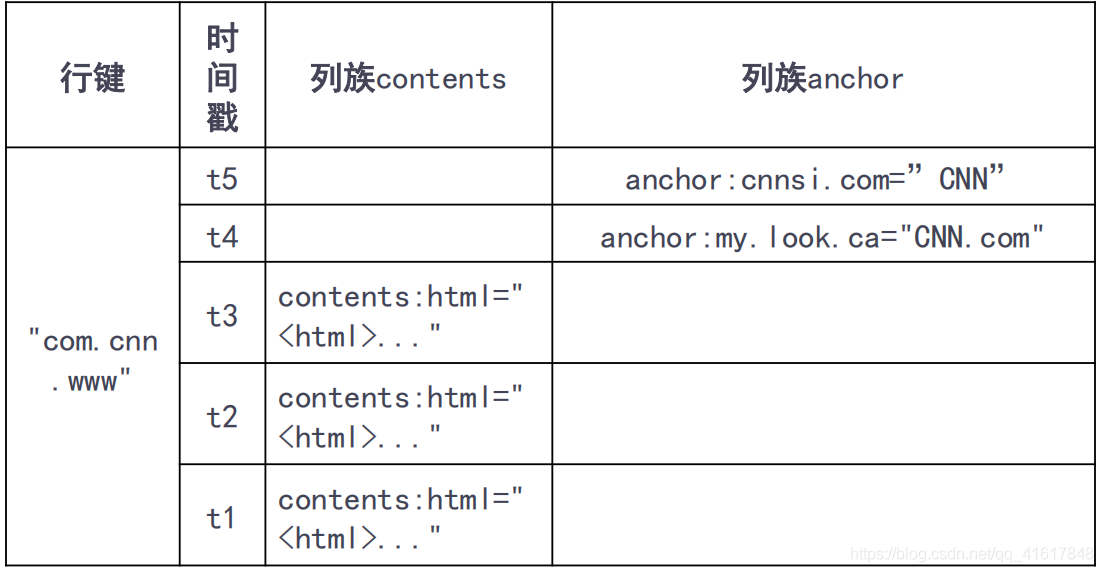
- Hbase是一个稀疏、多维度、排序的映射表,这张表的索引是行键、列族、列限定符和时间戳,每个值是一个未经解释的字符串,没有数据类型
- 用户在表中存储数据,每一行都有一个可排序的行键和任意多的列
- 表在水平方向由一个或者多个列族组成,一个列族中可以包含任意多个列,同一个列族里面的数据存储在一起
- 列族支持动态扩展,可以很轻松地添加一个列,无需预先定义列的数量以及类型,所有列均以字符串形式存储,用户需要自己进行数据类型的转换
- HBase中执行更新操作时,并不会删除数据旧的版本,而是生成一个新的版本,旧有的版本仍然保留(这是和HDFS只允许追加不允许修改的特性相关的****这个是what?)
- 表: HBase采用表来组织数据,表由行和列组成,列划分为若干个列族
- 行: 每个HBase表都由若干行组成,每个行由行键(row key)来标识。
- 列族: 一个HBase表被分组成许多“列族”(Column Family)的集合,它是基本的访问控制单元
- 列限定符: 列族里的数据通过列限定符(或列)来定位
- 时间戳: 每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引
- **单元格:**在HBase表中,通过行、列族和列限定符确定一个“单元格”(cell),单元格中存储的数据没有数据类型,总被视为字节数组byte[]
- HBase需要根据行键、列族、列限定符和时间戳来确定一个单元格
- 可以视为一个“四位坐标”,即 [行键,列族,列限定符,时间戳]

3.HBase的概念视图
4.HBase的物理视图
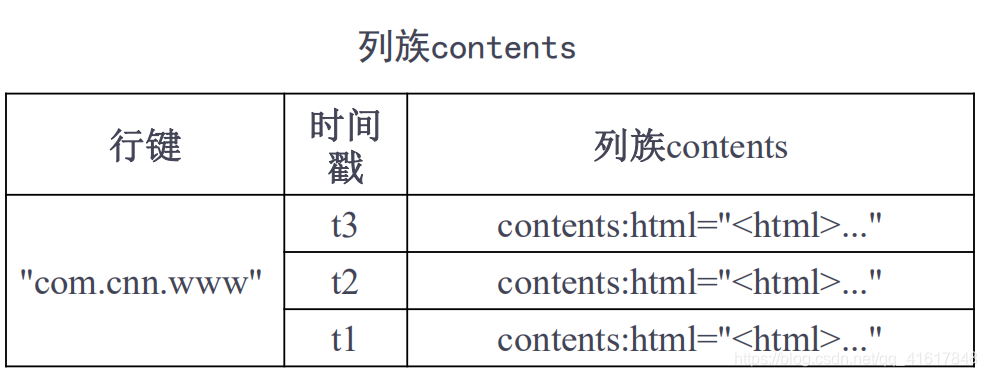
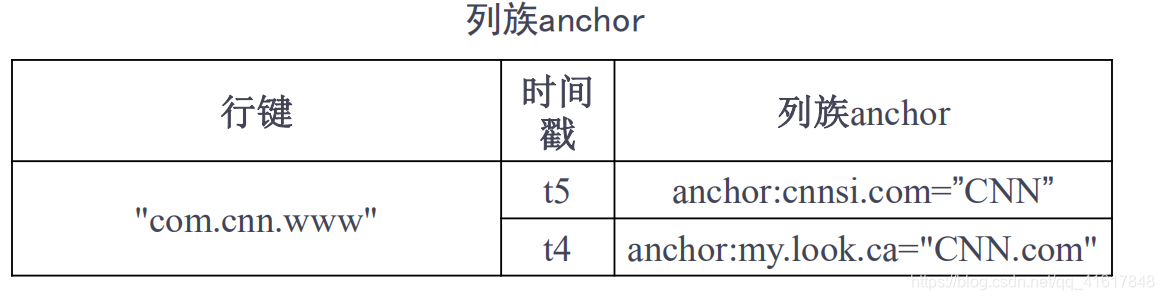
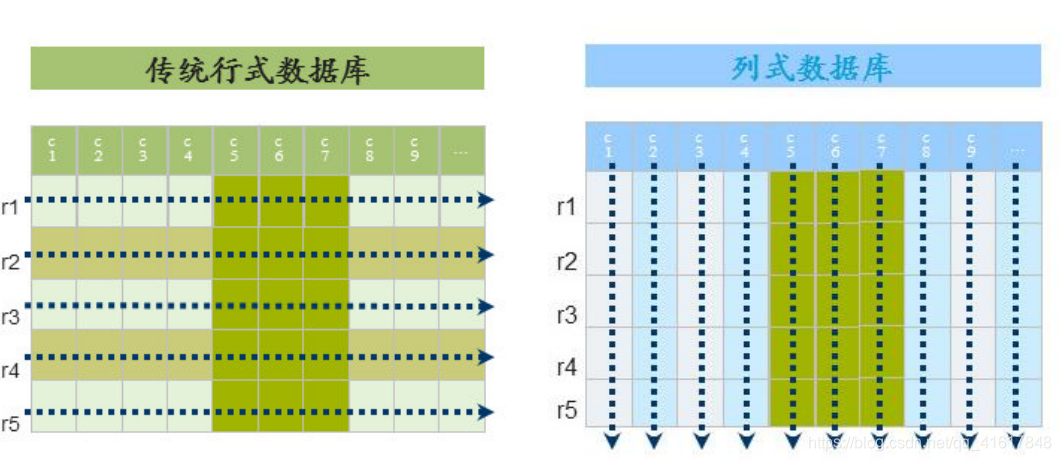
传统数据库是以行来存储的,HBase是以列来存储的。
传统的行存储就是为了可以规范化列的数量,方便于关系的建立,以及满足实体完整性、参照完整性、用户个性完整性;
HBase使用列来存储,那么是为了使数据库可以容易被扩展,方便存储海量的数据,但是无法分辨数据类型和难以建立数据与数据之间的关系;
我想:为什么不可以做一个三维的数据库呢?用两维来规定数据的类型和数据与数据之间的关系,用剩下的一维来进行扩展!这样的思想会不会可以既获得传统数据库的关系优点,又可以发挥可扩展的高性能优点呢?
5.HBase的系统架构

HBase的底层其实还是HDFS,所以HDFS是HBase的基础呀!
1. 客户端:
- 客户端包含访问HBase的接口,同时在缓存中维护着已经访问过的Region位置信息,用来加快后序数据访问过程
2. Zookeeper服务器
- Zookeeper可以帮助选举出一个Master作为集群的总管,并保证在任何时候总有唯一一个Master在运行,这就避免了Master的“单点失效”问题

3. Master主服务器
主服务器HMaster主要负责表和HRegion的管理工作:
- 管理用户对表的增加、删除、修改、查询等操作
- 实现不同HRegion服务器之间的负载均衡
- 在HRegion分裂或合并后,负责重新 调整HRegion的分布
- 对发生故障失效的HRegion服务器上的HRegion进行迁移,不会导致单点故障就导致整个集群宕机
4. HRegion服务器
- HRegion服务器是HBase中最核心的模块,负责维护分配给自己的Region,并响应用户的读写请求
HBase中Region服务器的工作原理
- 用户读写数据过程
- 缓存的刷新
- StoreFile的合并
下图是Region服务器向HDFS文件系统中读写数据
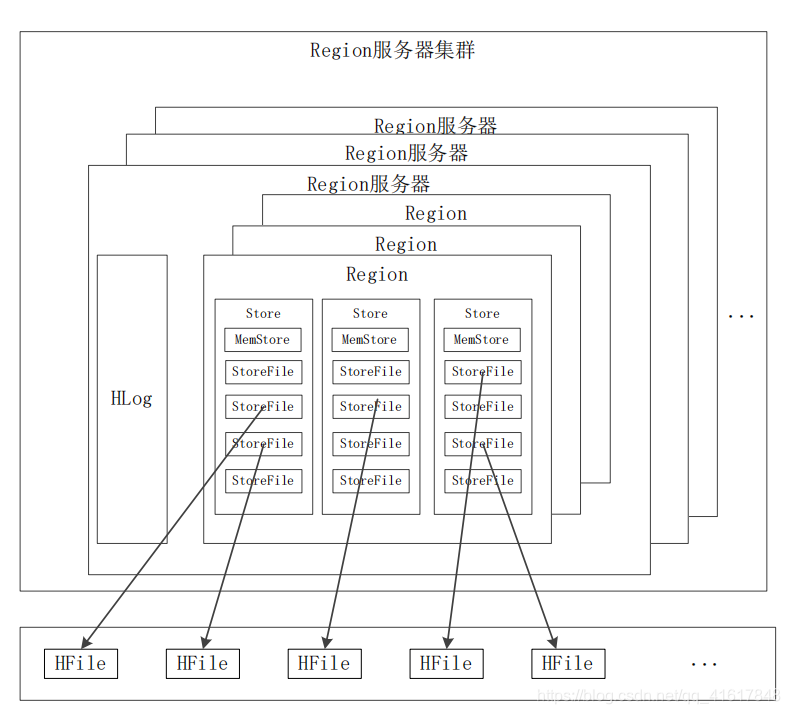
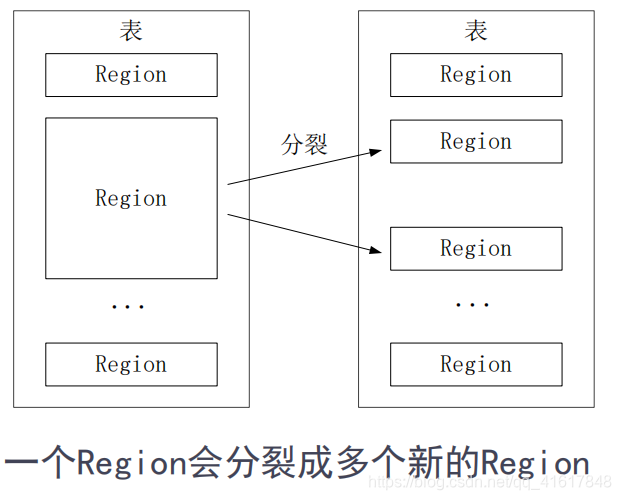
- 开始Region只有一个,后来不断分裂
- Region拆分操作非常快,接近于瞬间,因为拆分之后的Region读取的仍然是原存储文件,直到“合并”过程把存储文件异步地写到独立的文件之后,才会读取新文件
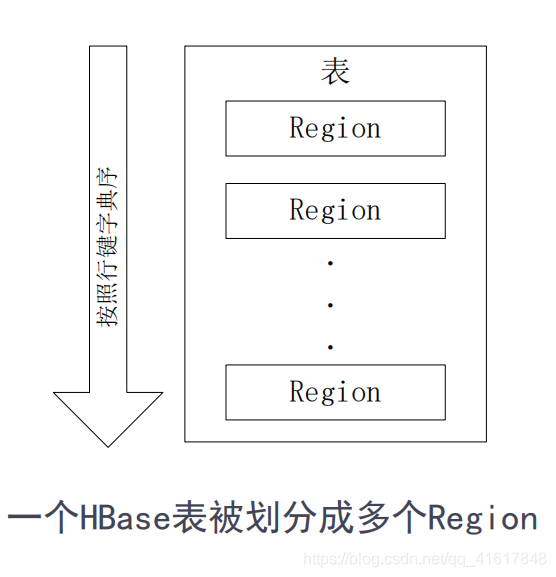
6.HBase表和Regsion
- 每个Regsion的默认大小是100M到200M
- 每个Regsion的最佳大小取决于单台服务器的有效处理能力
- 目前Regsion最佳大小建议1GB-2GB
- 同一个Region不会被分拆到多个Regsion服务器,每个Regsion服务器存储10-1000个Regsion
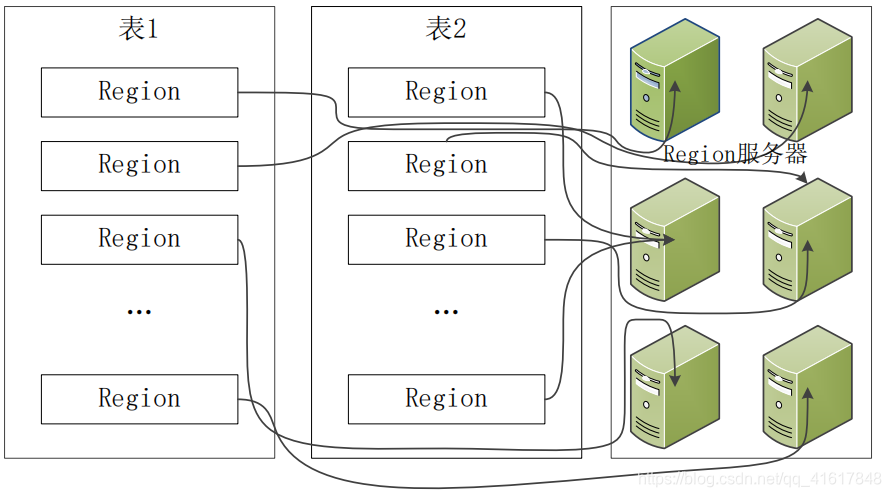
7. HBase中Region的定位
-
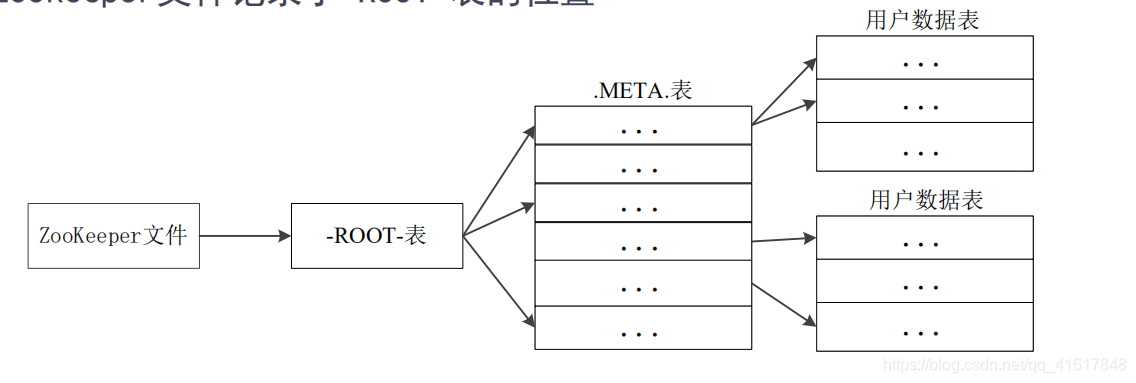
元数据表,又名.META.表,存储了Region和Region服务器的映射关系
-
当HBase表很大时, .META. 表也会被分裂成多个Regsion
-
根数据表,又名为root表,记录着所有元数据的具体位置
-
root表只有唯一一个Region,名字是在程序中被写死的,无法修改
-
Zookeeper文件记录了root表的位置
哈哈哈! 感觉很像Linux的目录结构,每个用户对应相应的用户文件目录 -
HBase的三层结构中各层次的名称和作用
| 层次 | 名称 | 作用 |
|---|---|---|
| 第一层 | Zookeeper文件 | 记录了root表的位置信息 |
| 第二层 | root表 | 记录了.META. 表的Region位置信息 root表只能有一个Region。通过root表,就可以访问.META表中的数据 |
| 第三层 | .META.表 | 记录了用户数据表的Region位置信息,.META.表可以有多个Region,保存了HBase中所有数据表的Region位置信息 |
客户端访问数据时的“三级寻址”
- 为了加速寻址,客户端会缓存位置信息,同时,需要解决缓存失效问题
- 寻址过程中客户端只需要询问Zookeeper服务器,不需要连接Master服务器
第一篇超过一万字的博客,小小庆祝一下下,嘻嘻!开心!以后会更加努力的学习丫!
当你的才华还撑不起你的野心的时候,
你就应该静下心来学习;
当你的能力还驾驭不了你的目标时,
就应该沉下心来,历练.
