HBase的原型是Google的BigTable论文,可以在我的资源里下载中文版的paper。
本不想设置积分可供免费下载,可是CSDN改版后不能自定义积分了,是系统根据资源动态分配的。
这一改版实在是不人性化,市场应该是自由的,更何况这种共享的资源。
https://download.csdn.net/download/xdsxhdyy/10801955
在Hadoop生态系统中HBase扮演的角色是:解决大规模数据的离线批量处理问题
HBase的四维坐标[行键,列族,列限定符,时间戳] 来确定一个单元格。
HBase系统架构
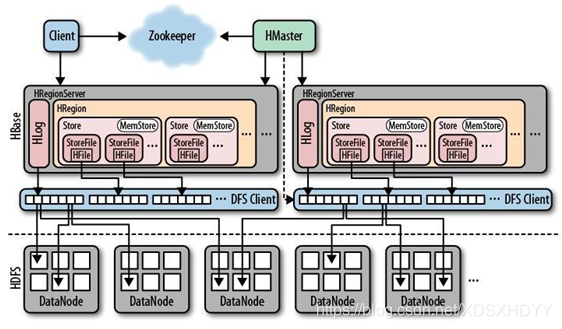
1.客户端
- 客户端包含访问HBase的接口,在缓存中维护着已经访问过的Region位置信息,加快后续访问过程
2.ZooKeeper服务器
- ZooKeeper是一个很好的集群管理工具,保证任何时刻总有唯一一个Master作为集群的总管,被大量用于分布式计算、提供配置维护、域名服务、分布式同步、组服务等
3.Master
- 主服务器Master主要负责监控RegionServer,处理RegionServer故障转移,
- 处理元数据的变更,处理region的分配或移除
- 实现不同Region服务器之间的负载均衡
- 通过Zookeeper发布自己的位置给客户端
4.RegionServer
- 是HBase中最核心的模块,负责维护分配给自己的Region,并响应用户的读写请求
- 负责存储HBase的实际数据,刷新缓存到HDFS,维护HLog
5.HFile
- 在磁盘上保存原始数据的实际的物理文件,是实际的存储文件。
6.Store
- HFile存储在Store中,一个Store对应HBase表中的一个列族。
7.MemStore
- 内存存储,位于内存中,用来保存当前的数据操作。
8.Region
- Hbase表的分片,HBase表会根据RowKey值被切分成不同的region存储在RegionServer中,在一个RegionServer中可以有多个不同的region。
HBase读写数据流程
-
HRegionServer保存着一张.META.的元数据信息表,读取和写入数据之前一般client会先去访问zookeeper获取-ROOT-表的位置进而找到.META.表在哪个HRegionServer上保存着,通过元数据信息表,就可以确定当前将要读写的数据所对应的RegionServer服务器和Region
-
当用户读取数据时,Region服务器会首先访问MemStore缓存,如果找不到再去磁盘上面的StoreFile中寻找
-
用户写入数据时,被分配到相应的Region服务器去执行
用户数据首先被写入到MemStore(缓存)和Hlog(日志)中
只有当操作写入Hlog之后,commit()调用才会将其返回给客户端
HBase与传统关系数据库的对比分析
1.数据类型:关系数据库采用关系模型,有丰富的数据类型和存储方式;HBase采用简单数据模型,存储未经解释的字符串
2.数据操作:关系数据库有丰富的操作,涉及多表连接。HBase只有简单的操作
3.存储模式:关系数据库是基于行模式存储;HBase是基于列存储的
4.数据索引:关系数据库针对不同列构建复杂的多个索引;HBase只有一个索引---行键
5.数据维护:关系数据库中更新是用新值换旧值;HBsae更新不会删除旧版本,而是新旧同时保留
6.可伸缩性:关系数据库很难实现横向扩展;HBase分布式数据库可灵活实现水平扩展