一、HBase简介
1.HBase – Hadoop Database,是一个高可靠、高性能、面向列、
实时读写的分布式数据库。
2.HBase是谷歌BigTable的开源实现,主要用来存储非结构化和半结构化的松散数据。HBase的目标是处理非常庞大的表,可以通过水平扩展的方式,利用廉价计算机集群处理超过10亿行数据和数百万列元素组成的数据表。
二、HBase的特点
1.海量存储
Hbase适合存储PB级别的海量数据,在PB级别的数据以及采用廉价PC存储的情况下,能在几十到百毫秒内返回数据。
2.列式存储
面向列表(簇)的存储和权限控制,列(簇)独立检索。
3.极易扩展
Hbase的扩展性主要体现在两个方面,一个是基于上层处理能力(RegionServer)的扩展,一个是基于存储的扩展(HDFS)。
4.高并发
在并发的情况下,Hbase的单个IO延迟下降并不多。能获得高并发、低延迟的服务。
5.无模式
每行都有一个可排序的主键和任意多的列,列可以根据需要动态的增加,同一张表中不同的行可以有截然不同的列;
6.稀疏
对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
7.数据多版本
每个单元中的数据可以有多个版本,默认情况下版本号自动分配,是单元格插入时的时间戳
8.数据类型单一
Hbase中的数据都是字节数组 byte[]。
三、Hbase系统架构
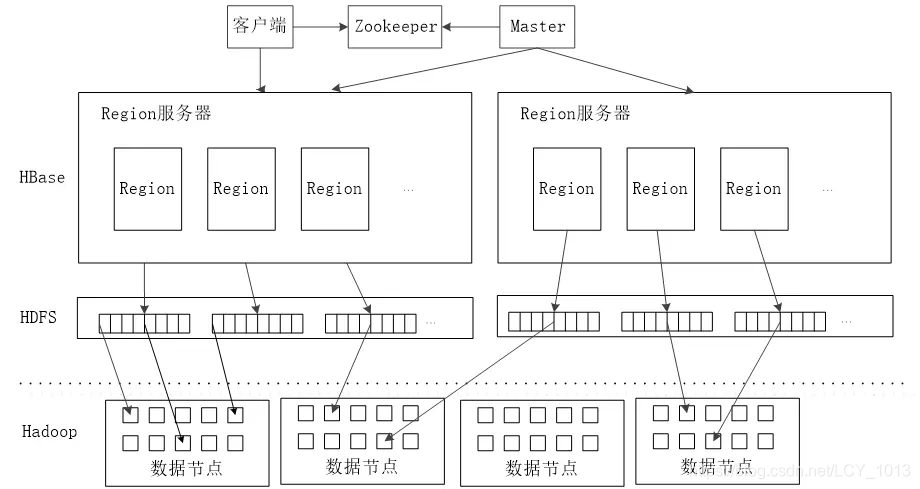
Hbase系统架构如图所示,由客户端(Client)、Zookeeper服务器、Master主服务器、Region服务器、HDFS等组件组成。
1.客户端
客户端包含访问HBase的接口,同时在缓存中维护着已经访问过的Region位置信息,用来加载后续数据访问过程。
2.Zookeeper服务器
Zookeeper不仅能够帮助维护当前的集群中机器的服务状态,而且能够帮助选举出一个Master作为集群的总管,并保证在任何时刻总有一个Master在运行,这就避免了Master的“单点失效”问题。
3.Master服务器
主服务器Master主要负责表和Region的管理工作:
(1)管理用户对表的增加、删除、修改、查询等操作
(2)实现不同Region服务器之间的负载均衡
(3)在Region分裂或合并后,负责重新调整Region分布
(4)对发生故障失效的Region服务器上Region进行迁移
4.Region服务器
Region服务器是HBase中最核心的模块,负责维护分配给自己的Region,并影响用户的读写需求。
5.HDFS
HDFS为Hbase提供最终的底层数据存储服务,同时为HBase提供高可用(Hlog存储在HDFS)的支持,具体功能概括如下:
(1)提供元数据和表数据的底层分布式存储服务
(2)数据多副本,保证的高可靠和高可用性
四、HBase中的角色
1.HMater
(1)监控RegionServer
(2)处理RegionServer故障转移
(3)处理元数据的变更
(4)处理region的分配或转移
(5)在空闲时间进行数据的负载均衡
(6)通过Zookeeper发布自己的位置给客户端
2.HRegionServer
(1)负责存储HBase的实际数据
(2)处理分配给它的Region
(3)刷新缓存到HDFS
(4)维护Hlog
(5)执行压缩
(6)负责处理Region分片
3.Zookeeper
(1)HRegionServer向zookeeper注册,提供是否还在线的信息;
(2)Hbase启动的时候将hbase系统表加载到zk cluster,zk cluster获取当前表上有的regionserver信息;
(3)Hmaster提供是否在线,避免单点故障;
五、HBase数据模型
Hbase是一个稀疏、多维度、排序的映射表,这张表是行键、列族、列限定符和时间戳。
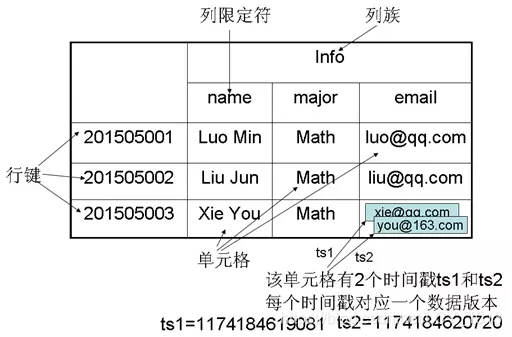
表:HBase采用表来组织数据,表由行和列组成,列划分为若干列族。
行:每个HBase表都由若干行组成,每个行由行键(row key)来标识
列族:一个HBase表被分组成许多“列族”(Column Family)的集合,它是基本的访问控制单元。
列限定符:列族里的数据通过限定符(或列)来定位
单元格:在Hbase表中,通过行、列族和列限定符确定一个“单元格”(cell),单元格中存储的数据没有数据类型,总被视为字节数组byte[]
时间戳:每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引。
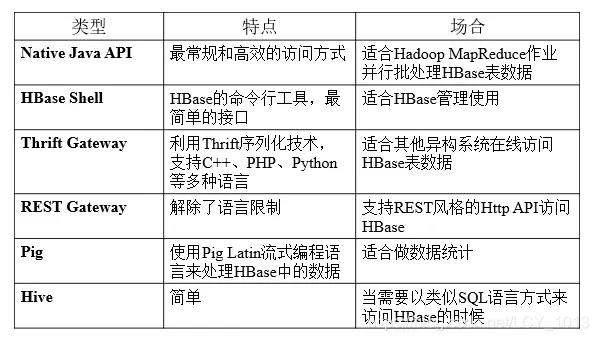
六、HBase访问接口