相信很多人都用过Prisma这个app,可以将普通照片转换为想要的风格。其背后的原理,就是通过神经网络学习某个图像的风格,然后再将这种风格应用到其他图像上。

最近看了相关论文,A Neural Algorithm of Artistic Style还有Perceptual Losses for Real-Time Style Transfer and Super-Resolution,又参考了一些github上的相关项目,自己用tensorflow也实现了一个类似的网络。
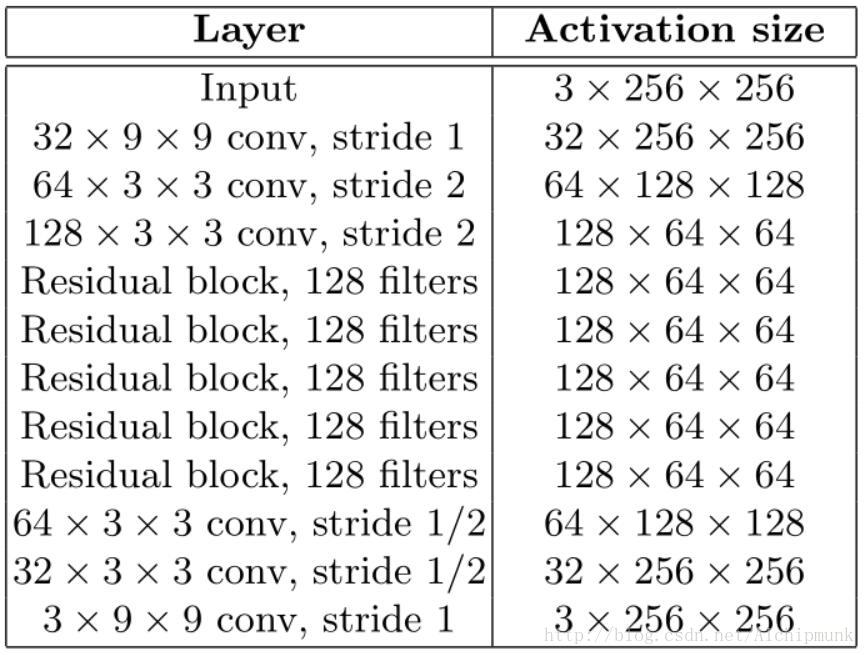
网络结构
网络结构几乎完全按照论文中的描述实现,不同的是将论文中的Batch Norm全部换成了Instance Norm,原因是这样做以后,生成的图像效果更好。同时,deconvolution(transposed convolution)也全部换成了resize-convolution,理由就和我的上一篇文章中说的一样,可以防止棋盘格纹理的产生。再者,通常的zero padding被reflect padding取代,为了减少边界效应。另外,在我参考的github实现当中,我发现其residual block中没有BN或IN,这一点是和论文不同的,我自己加上以后,发现对最后结果影响不大,但是学习率和loss function等需要仔细调整,否则训练容易发散。
Loss Functions
要实现快速的风格转换,关键是使用Perceptual Losses。一个训练好的CNN,每一层特征抽象程度是不同的,层数越深,其学得的特征就越抽象,对图像的表达就越高层。Perceptual Loss就利用了CNN的这个特点。将一副普通照片输入我们的网络生成一副图像,再将该图像输入一个预训练的网络中(称为损失网络,loss net),我们希望生成的图像在loss net高层的特征尽可能和原始照片一致(保留原始照片的内容和结构),而较低层的特征尽可能和风格图像一致(保留风格图像的色彩和纹理)。这样,通过不断的训练,我们的网络能同时兼顾以上两个要求,从而实现了照片风格的转换。
论文中的Perceptual Losses主要由3部分组成,第一部分被称为feature loss或content loss,它度量了生成的图像与原始照片在类容结构上的一致性。
其中
第二部分称为style loss,度量了生成的图像与风格图像在风格上的差异。但是如何度量风格呢,风格难以像content loss那样进行像素级的比较。论文中使用了Gram Matrix。
上式是loss net中第j层Gram Matrix的计算方法,c为该层输出的通道数,也即feature map的数量,所以Gram Matrix的大小与输入图像的大小无关,是一个c x c的矩阵。因此计算Gram Matrix时,也可以将大小为
这个loss看上去是神来之笔,但仔细分析后发现不难理解。Gram Matrix实际上可看做是feature之间的偏心协方差矩阵(即没有减去均值的协方差矩阵),在feature map中,每一个数字都来自于一个特定滤波器在特定位置的卷积,因此每个数字就代表一个特征的强度,而Gram计算的实际上是两两特征之间的相关性,哪两个特征是同时出现的,哪两个是此消彼长的等等,同时,Gram的对角线元素,还体现了每个特征在图像中出现的量,因此,Gram有助于把握整个图像的大体风格。有了表示风格的Gram Matrix,要度量两个图像风格的差异,只需比较他们Gram Matrix的差异即可。
在实际使用时,该loss的层级一般选择由低到高的多个层,比如VGG16中的第2、4、7、10个卷积层,然后将每一层的style loss相加。
第三个部分不是必须的,被称为Total Variation Loss。实际上是一个平滑项(一个正则化项),目的是使生成的图像在局部上尽可能平滑,而它的定义和马尔科夫随机场(MRF)中使用的平滑项非常相似。
其中
def total_variation_loss(inputs):
"""
A smooth loss in fact. Like the smooth prior in MRF.
V(y) = || y_{n+1} - y_n ||_2
:param inputs:
:return:
"""
dy = inputs[:, :-1, ...] - inputs[:, 1:, ...]
dx = inputs[:, :, :-1, ...] - inputs[:, :, 1:, ...]
size_dy = tf.size(dy, out_type=tf.float32)
size_dx = tf.size(dx, out_type=tf.float32)
return tf.nn.l2_loss(dy) / size_dy + tf.nn.l2_loss(dx) / size_dx.
最终我们优化的目标,就是这三者的加权求和。而对于loss net,直接选择tensorflow中提供的VGG16或者VGG19即可。这几个loss以及loss net的具体实现可以看看github上的代码。
训练
训练的过程很坎坷,我的电脑GPU太弱,使用Adam,batch size设为4时,只能勉强使用192x192的图像作为输入,由于风格图像也需要缩小到这个尺度,所以过小的尺寸会影响最后生成图像的风格质量。在训练过程中,一些奇异图像(比如纯色或有大量噪声)会导致很大的loss,使训练很不稳定。改进方法之一是修改loss函数,上文所说的3个loss都使用了2范数作为度量,而2范数对噪声是很敏感的,因此,可以将loss中使用的2范数全部换为Huber loss(soft L1),在tensorflow中可以如下实现:
def _huber_loss(delta):
delta = tf.abs(delta)
less = tf.boolean_mask(delta, delta < 1)
greater = tf.boolean_mask(delta, delta >= 1)
return 0.5 * tf.reduce_sum(tf.pow(less, 2)) + tf.reduce_sum(greater - 0.5)使用了Huber Loss后,每个loss的weight都要做相应的减小,差不多等于原来权重的开方,也可以考虑将weight变成动态递减的,否则content loss几乎不会下降。
令一个方法是在数据预处理阶段减少这类奇异图像的产生,尤其是纯黑或纯白的无类容图像。可以设定一个缩放范围,这个范围应该大于网络的输入大小,但也不能太大,在我的实现中,设定为网络输入大小的2倍,然后将所有图像(较短边)都随机的缩放到这一范围内,再进行random crop,这样可以降低裁剪到无类容区域的概率,加快收敛速度。
三个不同loss的权重,对最终效果的影响很大,一般而言,往往固定feature loss,将其权重设为1,然后调整style loss的权重,要让两个loss加权后的值在一个数量级上,这个权重通过少量的训练一般就可以看出来,比如训练一段时间后,发现feature loss大概在
另外,由于训练时间较长,在训练过程中保存所有变量(包括Adam中的变量和global step)是非常有必要的,中途若有突发情况打断了训练,还能恢复现场继续训练。训练采用的数据集是MS COCO,12G大小,共8万多张照片,在我这弱小的机器上训练了40000个iterations,花费了将近20小时。
使用
目标风格

风格迁移

目标风格

风格迁移

在进一步的使用中,我发现当照片中有大量纯色区域时,输出会出现灰色的“死区”,如下图

解决方法也很简单,在输入网络前,对照片加入一些随机噪声即可,比如标准差为5个像素的高斯噪声:

对原始照片加入噪声,不仅可以解决“死区”问题,还可以使每次生成的风格纹理都有一定的随机性。
最后,这种Perceptual Losses也可以用于图像的超分辨率,只需去掉style loss,而content loss一般取loss net中较低层的特征进行度量,比如VGG16的第二个卷积层。使用Perceptual Loss后产生的图像,边缘往往更清晰,图像细节更多,当放大倍数较高时尤为明显。