上篇相关文章:Zookeeper节点及客户端基本操作
1. Zookeeper选举的基本原理
Zookeeper集群模式下才需要选举,Zookeeper入门及单机及集群环境搭建。
Zookeeper领导者选择中的四个基本概念;
- 能力:Zookeeper是一个数据库,集群中节点的数据越新就代表此节点能力越强,Zookeeper中可以通事务id(zxid)来表示数据的新旧,zxid越大则该节点的数据越新。所以Zookeeper选举时首先会根据zxid的大小来作为投票的基本规则。
- 改票:Zookeeper集群中的某一个节点在开始进行选举时,首先认为自己的数据是最新的,会先投自己一票,并且把这张选票发送给其他服务器,这张选票里包含了两个重要信息:zxid和sid,sid表示这张选票投的服务器id,zxid表示这张选票投的服务器上最大的事务id,同时也会接收到其他服务器的选票,接收到其他服务器的选票后,可以根据选票信息中的zxid来与自己当前所投的服务器上的最大zxid来进行比较,如果其他服务器的选票中的zxid较大,则表示自己当前所投的机器数据没有接收到的选票所投的服务器上的数据新,所以本节点需要改票,改成投给和刚刚接收到的选票一样(如果其他服务器上的zxid较小则放弃收到的投票结果,如果zxid一样则会去比较四点的大小规则同zxid)。
- 投票箱:Zookeeper集群中会有很多节点并不会单独去维护一个投票箱应用,而是在每个节点内存里利用一个数组来作为投票箱。每个节点里都有一个投票箱,节点会将自己的选票以及从其他服务器接收到的选票放在这个投票箱中。因为集群节点是相互交互的,并且选票的PK规则是一致的,所以每个节点里的这个投票箱所存储的选票都会是一样的,这样也可以达到公用一个投票箱的目的。
- 领导者:Zookeeper集群中的每个节点,开始进行领导选举后,会不断的接收其他节点的选票,然后进行选票PK,将自己的选票修改为投给数据最新的节点,这样就保证了,每个节点自己的选票代表的都是自己暂时所认为的数据最新的节点,再因为其他服务器的选票都会存储在投票箱内,所以可以根据投票箱里去统计是否有超过一半的选票和自己选择的是同一个节点,都认为这个节点的数据最新,一旦整个集群里超过一半(过半机制)的节点都认为某一个节点上的数据最新,则该节点就是领导者。
通过对四个概念的在Zookeeper中的解析,也同时介绍了一下Zookeeper领导者选举的基本原理,只是说选举过程中还有更多的细节需要我们了解,下面我结合源码来给大家详细的分析一下Zookeeper的快速领导者选举原理。
2. 领导者选举入口
ZooKeeperServer表示单机模式中的一个zkServer。
QuoruPeer表示集群模式中的一个zkServer。
QuoruPeer类定义如下:定义表明QuorumPeer是一个ZooKeeperThread,表示是一个线程。
public class QuorumPeer extends ZooKeeperThread implements QuorumStats.Provider
当集群中的某一个台zkServer启动时QuorumPeer类的start方法将被调用。
public synchronized void start() {
if (!getView().containsKey(myid)) {
throw new RuntimeException("My id " + myid + " not in the peer list");
}
//zkServer中有一个内存数据库对象ZKDatabase, zkServer在启动时需要将已被持久化的数据加载进内存中,也就是加载至ZKDatabase。
loadDataBase();
// 这一步会开启一个线程来接收客户端请求,但是需要注意,这一步执行完后虽然成功开启了一个线程,并且也可以接收客户端线程,
//但是因为现在zkServer还没有经过初始化,实际上把请求拒绝掉,直到zkServer初始化完成才能正常的接收请求。
startServerCnxnFactory();
try {
adminServer.start();
} catch (AdminServerException e) {
LOG.warn("Problem starting AdminServer", e);
System.out.println(e);
}
//这个方法并没有真正的开始领导选举,而是进行一些初始化。
startLeaderElection();
// 启动线程,执性run()方法的逻辑包括进行领导者选举、zkServer初始化。
super.start();
}
3. 领导者选举策略
上文QuorumPeer类的startLeaderElection会进行领导者选举初始化。
首先,领导者选举在Zookeeper中有3种实现:
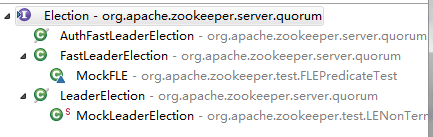
其中LeaderElection、AuthFastLeaderElection已经被标为过期,不建议使用,所以现在用的都是快速领导者选举FastLeaderElection,我们着重来介绍FastLeaderElection。
3.1 快速领导者选举
快速领导者选举实现架构如下图:
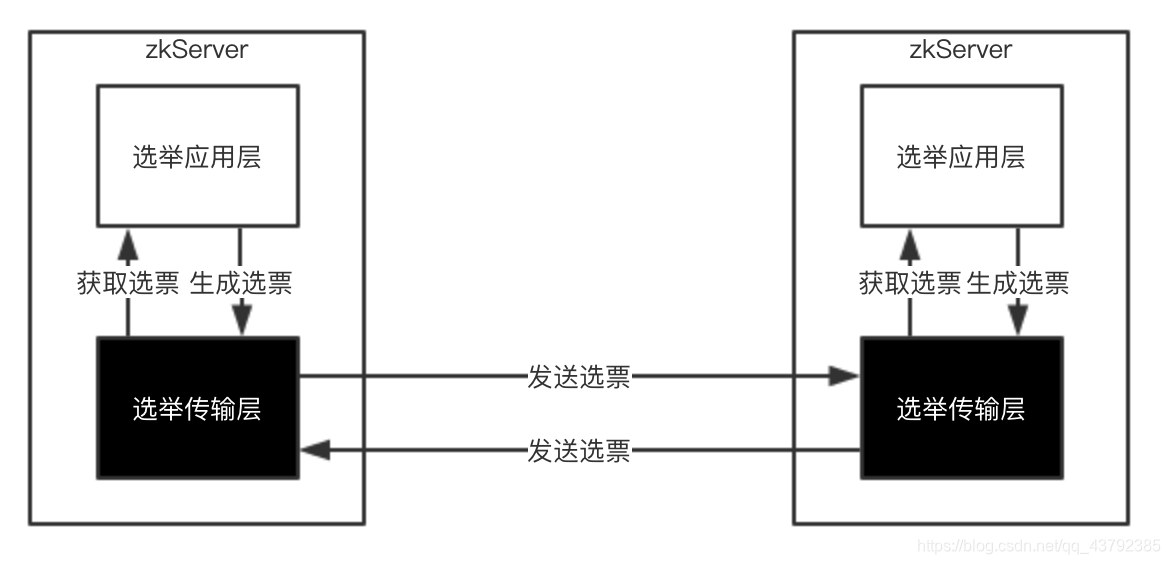
3.1.1 服务器状态
public enum ServerState {
LOOKING, FOLLOWING, LEADING, OBSERVING;
}
- LOOKING:表示当前集群处于无Leader状态,在选举中,启动投票开始的默认状态
- FOLLOWING :表明当前服务器角色是跟随者(follower)
- LEADING :表明当前服务器角色是领导者(leader)
- OBSERVING :表明当前服务器是观察者(observer)
3.1.2 投票信息
public class Vote {
public Vote(long id,
long zxid) {
this.version = 0x0;
this.id = id;//被选举的leader服务id
this.zxid = zxid;//被推举leader的事务id
this.electionEpoch = -1;//表示选举的轮次,没进入新的一轮投票都会加1
this.peerEpoch = -1;//被推荐为leader的任期
this.state = ServerState.LOOKING;
}
final private int version;
final private long id;
final private long zxid;
final private long electionEpoch;
final private long peerEpoch;
}
3.1.3 传输层初始化
快速领导者选举初始化核心就是初始化传输层。
protected Election createElectionAlgorithm(int electionAlgorithm){
Election le=null;
//LeaderElection和AuthFastLeaderElection已经过时不会使用
switch (electionAlgorithm) {
case 0:
le = new LeaderElection(this);
break;
case 1:
le = new AuthFastLeaderElection(this);
break;
case 2:
le = new AuthFastLeaderElection(this, true);
break;
case 3:
// 初始化QuorumCnxManager
QuorumCnxManager qcm = createCnxnManager();
QuorumCnxManager oldQcm = qcmRef.getAndSet(qcm);
if (oldQcm != null) {
LOG.warn("Clobbering already-set QuorumCnxManager (restarting leader election?)");
oldQcm.halt();
}
// 初始化QuorumCnxManager.Listener
QuorumCnxManager.Listener listener = qcm.listener;
if(listener != null){
// 运行QuorumCnxManager.Listener
listener.start();
//初始化快速选举类FastLeaderElection会对sendqueue、recvqueue队列进行初始化
FastLeaderElection fle = new FastLeaderElection(this, qcm);
//开始选举,会调用Messenger启动 WorkerSender和WorkerReceiver的线程。
fle.start();
le = fle;
} else {
LOG.error("Null listener when initializing cnx manager");
}
break;
default:
assert false;
}
return le;
}
3.1.3.1 QuorumCnxManager介绍
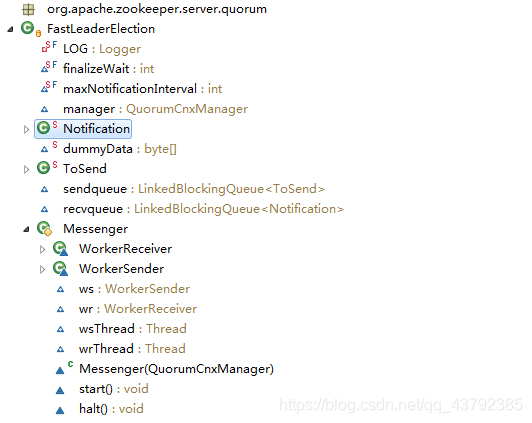
QuorumCnxManager就是传输层实现,QuorumCnxManager中几个重要的属性:
public class QuorumCnxManager {
private static final Logger LOG = LoggerFactory.getLogger(QuorumCnxManager.class);
/*
* Maximum capacity of thread queues
*/
static final int RECV_CAPACITY = 100;
// Initialized to 1 to prevent sending
// stale notifications to peers
static final int SEND_CAPACITY = 1;
static final int PACKETMAXSIZE = 1024 * 512;
/*
* Negative counter for observer server ids.
*/
private AtomicLong observerCounter = new AtomicLong(-1);
/*
* Protocol identifier used among peers
*/
public static final long PROTOCOL_VERSION = -65536L;
/*
* Max buffer size to be read from the network.
*/
static public final int maxBuffer = 2048;
/*
* Connection time out value in milliseconds
*/
private int cnxTO = 5000;
/*
* Counter to count connection processing threads.
*/
private AtomicInteger connectionThreadCnt = new AtomicInteger(0);
/*
* Mapping from Peer to Thread number
*/
//SendWorker封装了Socket的发送器,senderWorkerMap用来记录其他服务器id以及对应的SendWorker
final ConcurrentHashMap<Long, SendWorker> senderWorkerMap;
//zkServer需要发送给其他服务器选票信息
final ConcurrentHashMap<Long, ArrayBlockingQueue<ByteBuffer>> queueSendMap;
//每个sid最近一次发送的信息
final ConcurrentHashMap<Long, ByteBuffer> lastMessageSent;
// 从其他服务器接收到的投票信息
public final ArrayBlockingQueue<Message> recvQueue;
/*
* Object to synchronize access to recvQueue
*/
private final Object recvQLock = new Object();
/*
* Shutdown flag
*/
volatile boolean shutdown = false;
// 监听线程,负责socket监听
public final Listener listener;
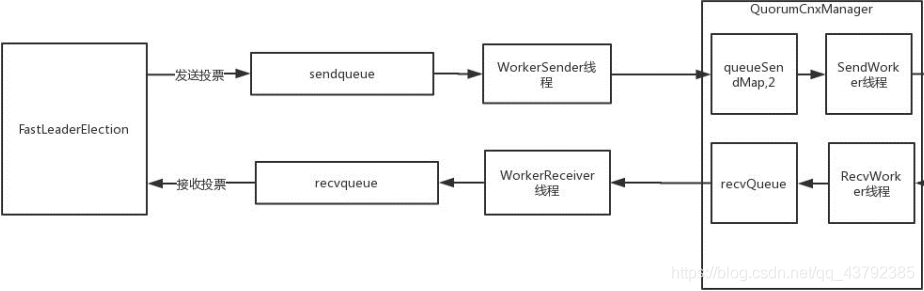
细化后的架构图如下:
3.1.3.2 建立连接
在集群启动时,为了能够相互之间接收和发送投票信息,所有的Zookeeper服务之间需要两两建立Socket连接进行通信。我们知道Socket是双向的,Socket的双方是可以相互发送和接收数据的,但是在投票选举过程中建立两条Socket是没有意义的,所以ZooKeeper只允许服务器ID(SID)较大者去连服务器ID较小者,小ID服务器去连大ID服务器会被拒绝:
if (sid < self.getId()) {
/*
* 如果接收到的sid小则关闭连接
*/
SendWorker sw = senderWorkerMap.get(sid);
if (sw != null) {
sw.finish();
}
/*
* Now we start a new connection
*/
LOG.debug("Create new connection to server: {}", sid);
closeSocket(sock);
if (electionAddr != null) {
connectOne(sid, electionAddr);
} else {
connectOne(sid);
}
} else { // 否则(接收到连接sid大)打开线程接收数据
SendWorker sw = new SendWorker(sock, sid);
RecvWorker rw = new RecvWorker(sock, din, sid, sw);
sw.setRecv(rw);
SendWorker vsw = senderWorkerMap.get(sid);
if (vsw != null) {
vsw.finish();
}
senderWorkerMap.put(sid, sw);
queueSendMap.putIfAbsent(sid,
new ArrayBlockingQueue<ByteBuffer>(SEND_CAPACITY));
sw.start();
rw.start();
}
3.1.3.3 SendWorker、RecvWorker介绍
上文介绍到了SendWorker,它是zkServer用来向其他服务器发送选票信息的。
/**
* Thread to send messages. Instance waits on a queue, and send a message as
* soon as there is one available. If connection breaks, then opens a new
* one.
*/
class SendWorker extends ZooKeeperThread {
Long sid;
Socket sock;
RecvWorker recvWorker;
volatile boolean running = true;
DataOutputStream dout;
}
它封装了socket并且是一个线程,SendWorker线程会不停的从queueSendMap中获取选票信息然后发送到Socket上。
基于同样的思路,我们还需要一个线程从Socket上获取数据然后添加到recvQueue中,这就是RecvWorker的功能。
class RecvWorker extends ZooKeeperThread {
Long sid;
Socket sock;
volatile boolean running = true;
final DataInputStream din;
final SendWorker sw;
}
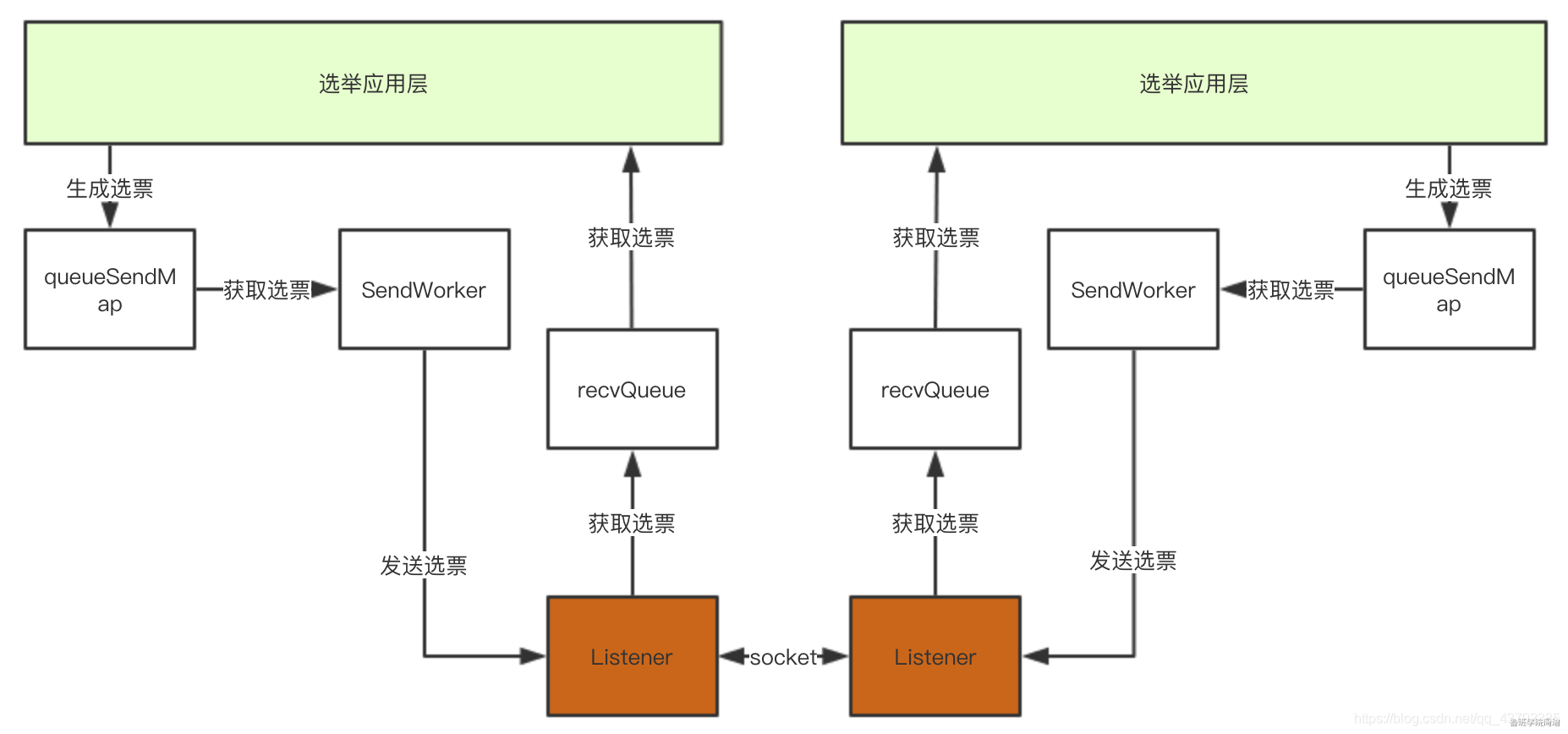
所以架构可以演化为下图,通过这个架构,选举应用层直接从recvQueue中获取选票,或者选票添加到queueSendMap中既可以完成选票发送:
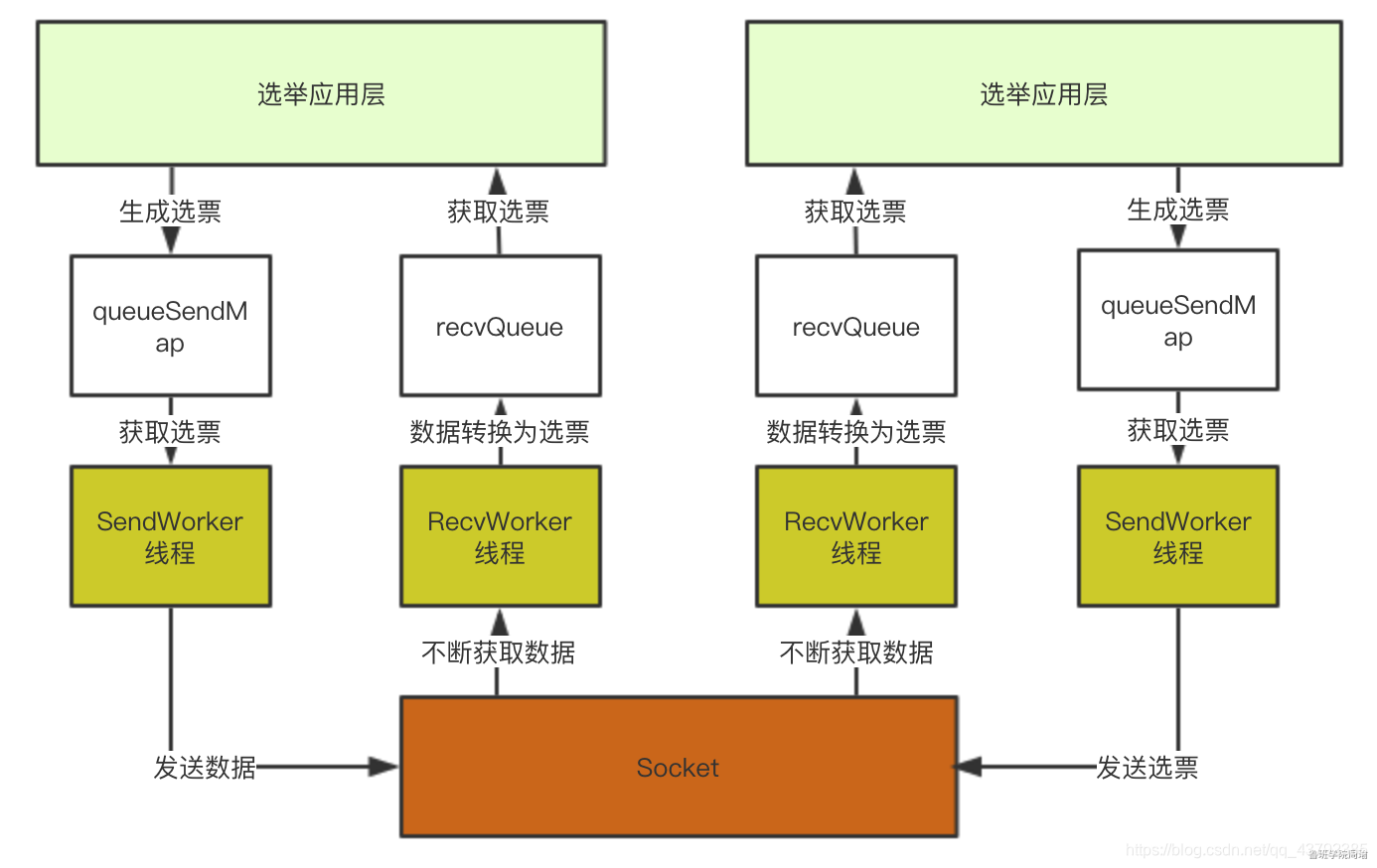
3.1.4 应用层初始化
FastLeaderElection类介绍
服务器在进行领导者选举时,在发送选票时也会同时接受其他服务器的选票,FastLeaderElection类也提供了和传输层类似的实现,将待发送的选票放在sendqueue中,由Messenger.WorkerSender发送到传输层queueSendMap中。同样,由Messenger.WorkerReceiver负责从传输层获取数据并放入recvqueue中。这样在应用层,只需要将待发送的选票信息添加到sendqueue中即可完成选票信息发送,或者从recvqueue中获取元素即可得到选票信息。此时架构图如下:
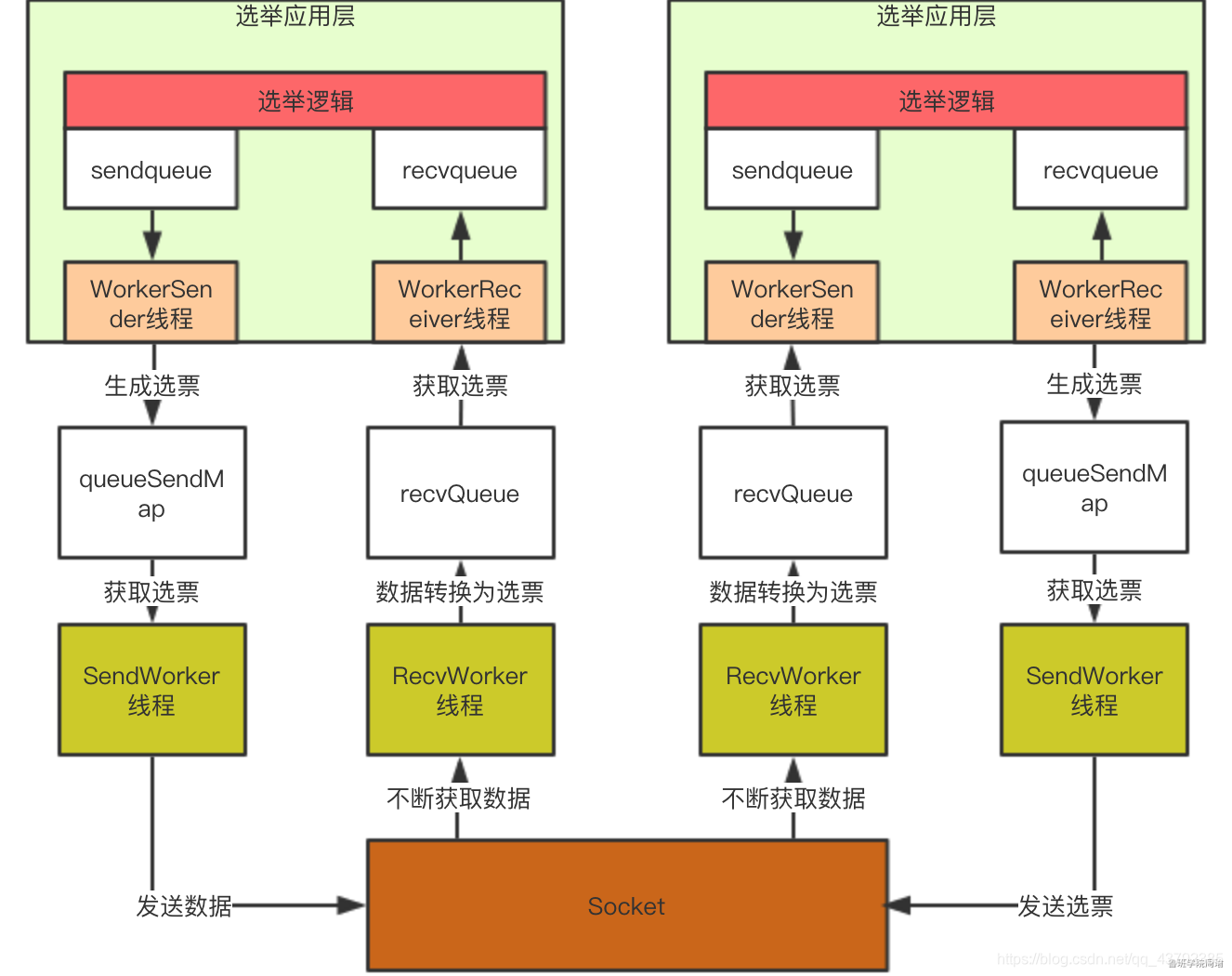
到这里,QuorumPeer类的startLeaderElection方法已经执行完成,完成了传输层和应用层的初始化。
3.1.5 快速领导者选举实现
QuorumPeer类的start方法前三步分析完,接下来我们来看看第四步:super.start();
QuorumPeer类是一个ZooKeeperThread线程,上述代码实际就是运行一个线程,相当于运行QuorumPeer类中的run方法,这个方法也是集群模式下Zkserver启动最核心的方法。
接下来我们着重来分析一下主线程内的逻辑。
public void run() {
//...........省略部分源码
try {
/*
* Main loop
*/
while (running) {
switch (getPeerState()) {
case LOOKING:
LOG.info("LOOKING");
if (Boolean.getBoolean("readonlymode.enabled")) {
// 省略部分启动只读ZKServe的逻辑
} else {
// 开启领导者选举
try {
reconfigFlagClear();
if (shuttingDownLE) {
shuttingDownLE = false;
startLeaderElection();
}
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
setPeerState(ServerState.LOOKING);
}
}
break;
case OBSERVING:
try {
// 初始化为观察者
LOG.info("OBSERVING");
setObserver(makeObserver(logFactory));
observer.observeLeader();
} catch (Exception e) {
LOG.warn("Unexpected exception",e );
} finally {
observer.shutdown();
setObserver(null);
updateServerState();
}
break;
case FOLLOWING:
try {// 初始化为跟随者
LOG.info("FOLLOWING");
setFollower(makeFollower(logFactory));
follower.followLeader();
} catch (Exception e) {
LOG.warn("Unexpected exception",e);
} finally {
follower.shutdown();
setFollower(null);
updateServerState();
}
break;
case LEADING:
LOG.info("LEADING");
try {
// 初始化为领导者
setLeader(makeLeader(logFactory));
leader.lead();
setLeader(null);
} catch (Exception e) {
LOG.warn("Unexpected exception",e);
} finally {
if (leader != null) {
leader.shutdown("Forcing shutdown");
setLeader(null);
}
updateServerState();
}
break;
}
start_fle = Time.currentElapsedTime();
}
} finally {
LOG.warn("QuorumPeer main thread exited");
MBeanRegistry instance = MBeanRegistry.getInstance();
instance.unregister(jmxQuorumBean);
instance.unregister(jmxLocalPeerBean);
for (RemotePeerBean remotePeerBean : jmxRemotePeerBean.values()) {
instance.unregister(remotePeerBean);
}
jmxQuorumBean = null;
jmxLocalPeerBean = null;
jmxRemotePeerBean = null;
}
}
根据伪代码可以看到,当服务器状态为LOOKING时会进行领导者选举,所以我们着重来看领导者选举。当服务器状态为LOOKING时会调用FastLeaderElection类的lookForLeader方法,这就是领导者选举的应用层。
public Vote lookForLeader() throws InterruptedException {
try {
self.jmxLeaderElectionBean = new LeaderElectionBean();
MBeanRegistry.getInstance().register(self.jmxLeaderElectionBean, self.jmxLocalPeerBean);
} catch (Exception e) {
LOG.warn("Failed to register with JMX", e);
self.jmxLeaderElectionBean = null;
}
if (self.start_fle == 0) {
self.start_fle = Time.currentElapsedTime();
}
try {
// 1.初始化一个投票箱
HashMap<Long, Vote> recvset = new HashMap<Long, Vote>();
HashMap<Long, Vote> outofelection = new HashMap<Long, Vote>();
int notTimeout = finalizeWait;
synchronized (this) {
logicalclock.incrementAndGet();
// 2.更新选票,将票投给自己
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
}
LOG.info("New election. My id = " + self.getId() + ", proposed zxid=0x" + Long.toHexString(proposedZxid));
//3.发送选票
sendNotifications();
/*
* Loop in which we exchange notifications until we find a leader
*/
//4.不断获取其他服务器的投票信息,直到选出Leader
while ((self.getPeerState() == ServerState.LOOKING) && (!stop)) {
/*
* Remove next notification from queue, times out after 2 times the termination
* time
*/
Notification n = recvqueue.poll(notTimeout, TimeUnit.MILLISECONDS);
/*
* Sends more notifications if haven't received enough. Otherwise processes new
* notification.
*/
if (n == null) {
if (manager.haveDelivered()) {
sendNotifications();
} else {
//5.连接其他服务器
manager.connectAll();
}
/*
* Exponential backoff
*/
int tmpTimeOut = notTimeout * 2;
notTimeout = (tmpTimeOut < maxNotificationInterval ? tmpTimeOut : maxNotificationInterval);
LOG.info("Notification time out: " + notTimeout);
} else if (validVoter(n.sid) && validVoter(n.leader)) {
/*
* Only proceed if the vote comes from a replica in the current or next voting
* view for a replica in the current or next voting view.
*/
// 6.判断接收到的投票所对应的服务器的状态,也就是投此票的服务器的状态
switch (n.state) {
case LOOKING:
// PK选票、过半机制验证等
/**
* if (接收到的投票的选举周期 > 本服务器当前的选举周期) {
// 修改本服务器的选举周期为接收到的投票的选举周期
// 清空本服务器的投票箱(表示选举周期落后,重新开始投票)
// 比较接收到的选票所选择的服务器与本服务器的数据谁更新,本服务器将选票投给数据较新者
// 发送选票
} else if(接收到的投票的选举周期 < 本服务器当前的选举周期){
// 接收到的投票的选举周期落后了,本服务器直接忽略此投票
} else if(选举周期一致) {
// 比较接收到的选票所选择的服务器与本服务器当前所选择的服务器的数据谁更新,本服务器将选票投给数据较新者
// 发送选票
}
*/
if (n.electionEpoch > logicalclock.get()) {
logicalclock.set(n.electionEpoch);
recvset.clear();
if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, getInitId(), getInitLastLoggedZxid(),
getPeerEpoch())) {
updateProposal(n.leader, n.zxid, n.peerEpoch);
} else {
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
}
sendNotifications();
} else if (n.electionEpoch < logicalclock.get()) {
if (LOG.isDebugEnabled()) {
LOG.debug(
"Notification election epoch is smaller than logicalclock. n.electionEpoch = 0x"
+ Long.toHexString(n.electionEpoch) + ", logicalclock=0x"
+ Long.toHexString(logicalclock.get()));
}
break;
} else if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, proposedLeader, proposedZxid,
proposedEpoch)) {
updateProposal(n.leader, n.zxid, n.peerEpoch);
sendNotifications();
}
if (LOG.isDebugEnabled()) {
LOG.debug("Adding vote: from=" + n.sid + ", proposed leader=" + n.leader
+ ", proposed zxid=0x" + Long.toHexString(n.zxid) + ", proposed election epoch=0x"
+ Long.toHexString(n.electionEpoch));
}
// don't care about the version if it's in LOOKING state
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));
if (termPredicate(recvset,
new Vote(proposedLeader, proposedZxid, logicalclock.get(), proposedEpoch))) {
// Verify if there is any change in the proposed leader
while ((n = recvqueue.poll(finalizeWait, TimeUnit.MILLISECONDS)) != null) {
if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, proposedLeader, proposedZxid,
proposedEpoch)) {
recvqueue.put(n);
break;
}
}
/*
* This predicate is true once we don't read any new relevant message from the
* reception queue
*/
if (n == null) {
self.setPeerState(
(proposedLeader == self.getId()) ? ServerState.LEADING : learningState());
Vote endVote = new Vote(proposedLeader, proposedZxid, logicalclock.get(),
proposedEpoch);
leaveInstance(endVote);
return endVote;
}
}
break;
case OBSERVING:
// 观察者节点不应该发起投票,直接忽略
LOG.debug("Notification from observer: " + n.sid);
break;
case FOLLOWING:
case LEADING:
// 如果接收到跟随者或领导者节点的选票,则可以认为当前集群已经存在Leader了,直接return,退出lookForLeader方法。
if (n.electionEpoch == logicalclock.get()) {
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));
if (termPredicate(recvset,
new Vote(n.version, n.leader, n.zxid, n.electionEpoch, n.peerEpoch, n.state))
&& checkLeader(outofelection, n.leader, n.electionEpoch)) {
self.setPeerState((n.leader == self.getId()) ? ServerState.LEADING : learningState());
Vote endVote = new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch);
leaveInstance(endVote);
return endVote;
}
}
/*
* Before joining an established ensemble, verify that a majority are following
* the same leader.
*/
outofelection.put(n.sid,
new Vote(n.version, n.leader, n.zxid, n.electionEpoch, n.peerEpoch, n.state));
if (termPredicate(outofelection,
new Vote(n.version, n.leader, n.zxid, n.electionEpoch, n.peerEpoch, n.state))
&& checkLeader(outofelection, n.leader, n.electionEpoch)) {
synchronized (this) {
logicalclock.set(n.electionEpoch);
self.setPeerState((n.leader == self.getId()) ? ServerState.LEADING : learningState());
}
Vote endVote = new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch);
leaveInstance(endVote);
return endVote;
}
break;
default:
LOG.warn("Notification state unrecoginized: " + n.state + " (n.state), " + n.sid + " (n.sid)");
break;
}
} else {
if (!validVoter(n.leader)) {
LOG.warn("Ignoring notification for non-cluster member sid {} from sid {}", n.leader, n.sid);
}
if (!validVoter(n.sid)) {
LOG.warn("Ignoring notification for sid {} from non-quorum member sid {}", n.leader, n.sid);
}
}
}
return null;
} finally {
try {
if (self.jmxLeaderElectionBean != null) {
MBeanRegistry.getInstance().unregister(self.jmxLeaderElectionBean);
}
} catch (Exception e) {
LOG.warn("Failed to unregister with JMX", e);
}
self.jmxLeaderElectionBean = null;
LOG.debug("Number of connection processing threads: {}", manager.getConnectionThreadCount());
}
}
过半机制验证: 本服务器的选票经过不停的PK会将票投给数据更新的服务器,PK完后,将接收到的选票以及本服务器自己所投的选票放入投票箱中,然后从投票箱中统计出与本服务器当前所投服务器一致的选票数量,判断该选票数量是否超过集群中所有跟随者的一半(选票数量 > 跟随者数量/2),如果满足这个过半机制就选出了一个准Leader。
最终确认: 选出准Leader之后,再去获取其他服务器的选票,如果获取到的选票所代表的服务器的数据比准Leader更新,则准Leader卸职,继续选举。如果没有准Leader更新,则继续获取投票,直到没有获取到选票,则选出了最终的Leader。
注:ZooKeeper集群在进行领导者选举的过程中不能对外提供服务
参考文章:https://www.yuque.com/renyong-jmovm/kb/fukd3b#adEns
源码地址https://github.com/qqxhb/zookeeper
