基于版本3.4.13
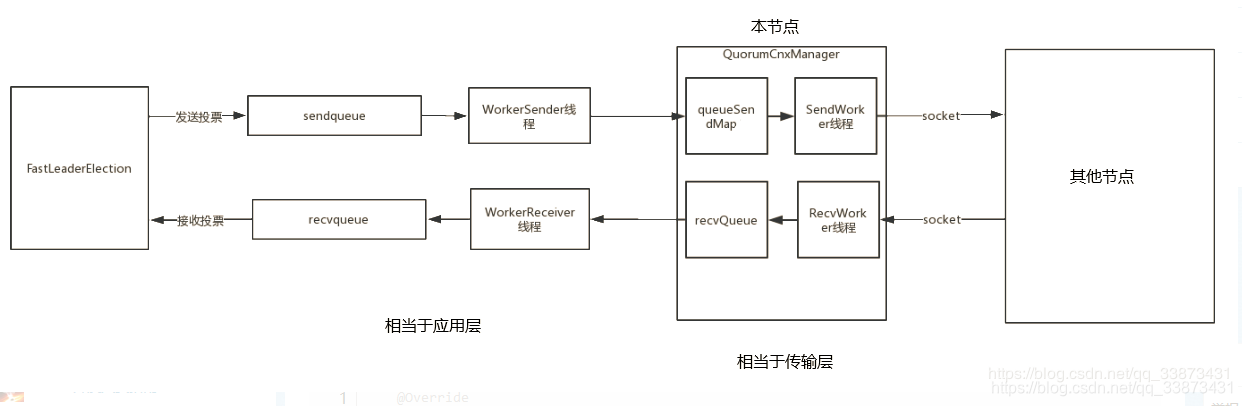
QuorumCnxManager主要负责和其他节点数据传输
sendqueue:选票发送队列,用于保存待发送的选票。
recvqueue:选票接收队列,用于保存接收到的外部投票。
WorkerReceiver:选票接收器。其会不断地从QuorumCnxManager中获取其他服务器发来的选举消息,并将其转换成一个选票,然后保存到recvqueue中,在选票接收过程中,如果发现该外部选票的选举轮次小于当前服务器的,那么忽略该外部投票,同时立即发送自己的内部投票。
WorkerSender:选票发送器,不断地从sendqueue中获取待发送的选票,并将其传递到底层QuorumCnxManager中。
recvQueue:当前节点接受信息的列队
senderWorkerMap:每台节点对应的senderworker,<Long, SendWorker>,Long为服务器myid,SendWorker用于从queueSendMap存的Queue取数据发送给其他节点的,是个线程
注意图里的recvqueue(FastLeaderElection类中)队列和recvQueue(QuorumCnxManager类中)是不一样的。
代码入口
QuorumPeerMain.main —> initializeAndRun方法—>runFromConfig方法里 quorumPeer.start() 启动QuorumPeer这个线程
QuorumPeer类:
@Override
public synchronized void start() {
// 加载数据
loadDataBase();
// 开启读取数据线程,取客户端数据
cnxnFactory.start();
// 进行领导者选举
startLeaderElection();
super.start();
}
leader选举细节
服务器状态
代码位于QuorumPeer的run方法
服务器有四种状态,分别是LOOKING、FOLLOWING、LEADING、OBSERVING。
- LOOKING:寻找leader状态。当服务器处于该状态时,它会认为当- 前集群中没有leader,因此需要进入leader选举状态。
- FOLLOWING:跟随者状态。表明当前服务器角色是follower。
- LEADING:领导者状态。表明当前服务器角色是leader。
- OBSERVING:观察者状态。表明当前服务器角色是observer。
投票数据结构
每个投票中包含了两个最基本的信息,所推举服务器的SID和ZXID,投票(Vote)在Zookeeper中包含字段如下
- id:被推举的Leader的SID。
- zxid:被推举的Leader事务ID。
- electionEpoch:逻辑时钟,用来判断多个投票是否在同一轮选举周期中,该值在服务端是一个自增序列,每次进入新一轮的投票后,都会对该值进行加1操作。
- peerEpoch:被推举的Leader的epoch。
- state:当前服务器的状态。
FastLeaderElection:选举算法
在3.4.0后的Zookeeper的版本只保留了FastLeaderElection选举算法。
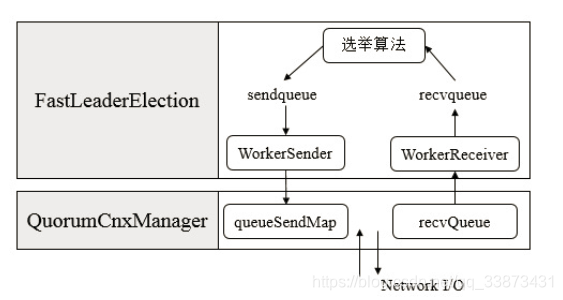
上图展示了FastLeaderElection模块是如何与底层网络I/O进行交互的。Leader选举的基本流程如下
- 自增选举轮次。Zookeeper规定所有有效的投票都必须在同一轮次中,在开始新一轮投票时,会首先对logicalclock进行自增操作。
- 初始化选票。在开始进行新一轮投票之前,每个服务器都会初始化自身的选票,并且在初始化阶段,每台服务器都会将自己推举为Leader。
- 发送初始化选票。完成选票的初始化后,服务器就会发起第一次投票。Zookeeper会将刚刚初始化好的选票放入sendqueue中,由发送器WorkerSender负责发送出去。
FastLeaderElection类的lookForLeader方法
public Vote lookForLeader() throws InterruptedException {
...
try {
//投票箱<Long, Vote> Long:其他节点sid Vote:其他节点投的票
HashMap<Long, Vote> recvset = new HashMap<Long, Vote>();
HashMap<Long, Vote> outofelection = new HashMap<Long, Vote>();
int notTimeout = finalizeWait;
synchronized(this){
// 时钟+1
logicalclock.incrementAndGet();
// 更新提议(投票),包含(myid,LastZxid, epoch), 投自己
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
}
// 把投票发送出去,写到sendqueue
sendNotifications();
...
}
-
接收外部投票。每台服务器会不断地从recvqueue队列中获取外部选票。如果服务器发现无法获取到任何外部投票,那么就会立即确认自己是否和集群中其他服务器保持着有效的连接,如果没有连接,则马上建立连接,如果已经建立了连接,则再次发送自己当前的内部投票。
-
判断选举轮次。在发送完初始化选票之后,接着开始处理外部投票。在处理外部投票时,会根据选举轮次来进行不同的处理。
扫描二维码关注公众号,回复: 11299158 查看本文章
- 外部投票的选举轮次大于内部投票。若服务器自身的选举轮次落后于该外部投票对应服务器的选举轮次,那么就会立即更新自己的选举轮次(logicalclock),并且清空所有已经收到的投票,然后使用初始化的投票来进行PK以确定是否变更内部投票。最终再将内部投票发送出去。
- 外部投票的选举轮次小于内部投票。若服务器接收的外选票的选举轮次落后于自身的选举轮次,那么Zookeeper就会直接忽略该外部投票,不做任何处理,并返回步骤4。
- 外部投票的选举轮次等于内部投票。此时可以开始进行选票PK。
-
选票PK。在进行选票PK时,符合任意一个条件就需要变更投票。
-
若外部投票中推举的Leader服务器的选举轮次大于内部投票,那么需要变更投票。
-
若选举轮次一致,那么就对比两者的ZXID,若外部投票的ZXID大,那么需要变更投票。
-
若两者的ZXID一致,那么就对比两者的SID,若外部投票的SID大,那么就需要变更投票。
-
-
变更投票。经过PK后,若确定了外部投票优于内部投票,那么就变更投票,即使用外部投票的选票信息来覆盖内部投票,变更完成后,再次将这个变更后的内部投票发送出去。
-
选票归档。无论是否变更了投票,都会将刚刚收到的那份外部投票放入选票集合recvset中进行归档。recvset用于记录当前服务器在本轮次的Leader选举中收到的所有外部投票(按照服务队的SID区别,如{(1, vote1), (2, vote2)…})。
-
统计投票。完成选票归档后,就可以开始统计投票,统计投票是为了统计集群中是否已经有过半的服务器认可了当前的内部投票,如果确定已经有过半服务器认可了该投票,则终止投票。否则返回步骤4。
-
更新服务器状态。若已经确定可以终止投票,那么就开始更新服务器状态,服务器首选判断当前被过半服务器认可的投票所对应的Leader服务器是否是自己,若是自己,则将自己的服务器状态更新为LEADING,若不是,则根据具体情况来确定自己是FOLLOWING或是OBSERVING。
以上10个步骤就是FastLeaderElection的核心,其中步骤4-9会经过几轮循环,直到有Leader选举产生。