Hadoop基础及演练
导航
一. 初始大数据
1.1 大数据方向介绍
- 什么是大数据?
- 大数据是一个概念也是一门技术,是在以Hadoop为代表的大数据平台框架上进行各种数据分析的技术。
- 大数据包括了以Hadoop和Spark为代表的基础大数据框架
- 还包括了实时数据处理,离线数据处理;数据分析,数据挖掘和用机器算法进行预测分析等技术。
- 大数据方向好不好?
- 时代发展变化图如下:
大数据是未来发展的趋势,学习大数据是一个很正确的方向!
- 时代发展变化图如下:
1.2 课程简介及目标
- 应用知识:
- 实战:HDFS实际操作(通过Shell命令/Python程序)
- 实战:MapReduce程序开发实例
- 课程目标:
- 掌握Hadoop框架的基础原理及使用方式
- 掌握基于Hadoop框架进行数据处理与分析的应用程序开发
- 课程学习建议
- 实践很重要,搭建一套测试环境,配合文章进行练习。
- 从应用入手,在使用过程中深入了解其原理及运行机制
- 坚持,并下定要以此在职业生涯中更上一层楼的决心。
- 课程预备知识:
- Linux常用命令
- 有一定的Python或者java的编程基础
- 对Hadoop有一定的了解,可以搭建自己的测试环境
二. Hadoop核心HDFS
2.1 HDFS概念及其优缺点
2.1.1 Hadoop是什么?
- Hadoop是一个开源的大数据框架
- Hadoop是一个分布式计算的解决方案
- Hadoop = HDFS(分布式文件系统)+ MapReduce(分布式计算)
2.1.2 Hadoop核心
- HDFS分布式文件系统:存储是大数据技术的基础
- MapReduce编程模型:分布式计算是大数据应用的解决方案
- 举个例子:一个目标文件(100M),在此文件过滤出含有Hadoop字符串的行。有两个解决方案:1.使用Linux grep命令 2. 编写Java/Python程序。 但是有一个目标文件有1000G的文件怎么办呢? 我们就需要使用Hadoop来解决了。
2.1.3 HDFS总结
- 普通的成百上千的机器
- 按TB甚至PB为单位的大量的数据
- 简单便捷的文件获取
2.1.4 HDFS概念:
- 数据块
- 数据块是抽象块而非整个文件作为存储单元
- 默认大小为64MB,一般设置为128M,备份X3
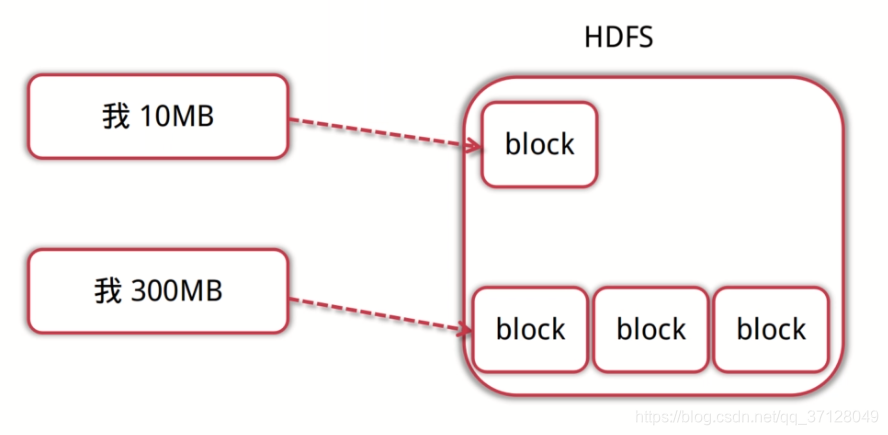
- 比如说我们存储一个10M文件,那么就占一个数据块;如果存储一个300MB的文件,就占三个数据块,如图所示:
- NameNode
- 管理文件系统的命名空间,存放文件元数据
- 维护着文件系统的所有文件和目录,文件与数据块的映射
- 记录每个文件中各个块所在数据节点的信息
- DataNode
- 存储并检索数据快
- 向NameNode更新所存储块的列表
2.1.5 HDFS优点
- 适合大文件存储,支持TB、PB级的数据存储,并有副本策略
- 可以构建在廉价的机器上,并有一定的容错和恢复机制
- 支持流式数据访问,一次写入,多次读取最高效
2.1.6 HDFS缺点
- 不适合大量小文件存储
- 不适合并发写入,不支持文件随机修改
- 不支持随机读等低延时的访问方式
2.2 HDFS写流程和读流程
2.2.1 HDFS写流程
- 文字描述:
- 客户端向NameNode发起写数据请求
- 分块写入DataNode节点,DataNode自动完成副本备份
- DataNode向NameNode汇报存储完成,NameNode通知客户端
- 图示:
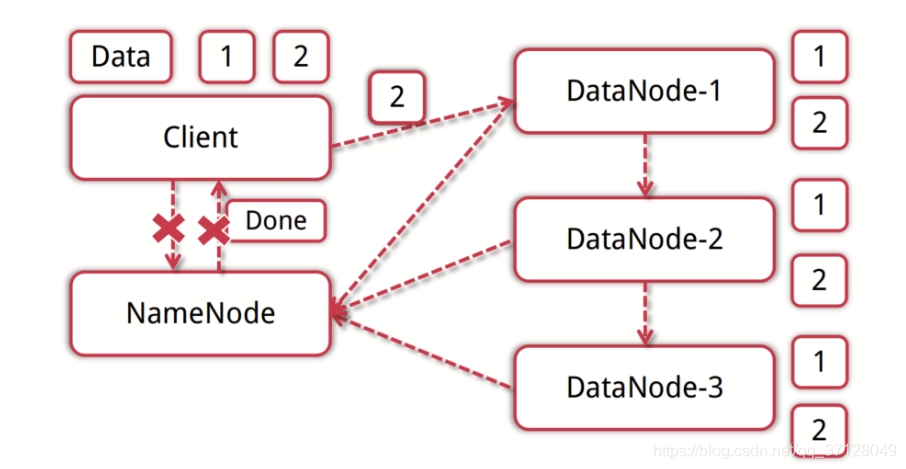
简单来讲,客户端接收到文件后,会将文件拆分成几个数据块,然后通知NameNode进行存储。NameNode会查看DataNode有哪些地方可以提供存储,然后将数据块给予DataNode进行存储。一般一处节点会有三个(其他两个备份),然后存储成功后会将地址以及元数据等信息返回给NameNode。NameNode接收到了会告诉客户端已存储成功并返回相关信息,然后结束;
2.2.2 HDFS读流程
- 文字描述:
- 客户端向NameNode发起读数据请求
- NameNode找出距离近的DataNode节点信息
- 客户端从DataNode分块下载文件
- 图示:
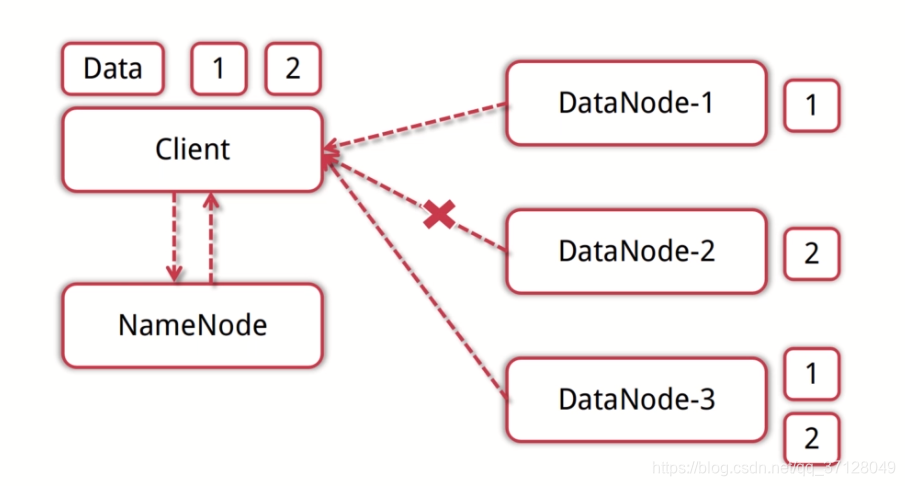
简单来说,读流程就是客户端向NameNode发送读取文件请求,然后NameNode会通过存储在自身的DataNode信息数据找出所要寻找的文件存储在哪些DataNode上面。然后NameNode会去到指定的DataNode上找到所需要的数据块。如果其中一个节点挂掉了会自动找其他的节点上存储的这个数据块。如图中DataNode2 节点挂掉了,但是需要一个2数据块,就会重新到DataNode3 上去寻找这个2数据块。
2.3 Shell命令操作HDFS
2.3.1 本节要点
- 通过Shell命令对HDFS进行操作:与Linux操作文件类似
- 通过编写Python程序对HDFS进行操作
2.3.2 常用HDFS Shell命令
- 类Linux系统: ls、cat、mkdir、rm、chmod、chown等
- HDFS文件交互:copyFromLocal、copyToLocal、get、put
2.4 Python程序操作HDFS
2.4.1 MapReduce简介
- MapReduce是一种编程模型,是一种编程方法,是抽象的理论。
2.4.2 YARN概念
- ResourceManager
- 分配和调度资源
- 启动并监控ApplicationMaster
- 监控NodeManager
- ApplicationMaster
- 为MR类型的程序申请资源,并分配给内部任务
- 负责数据的切分
- 监控任务的执行及容错
- NodeManager
- 管理单个节点的资源
- 处理来自ResourceManager的命令
- 处理来自ApplicationMster的命令
实际上就是ResourceManager 监控另外两个,并且将任务下发。而ApplicationMaster则为任务申请资源,对数据进行切分,将任务交给NodeManger。而NodeManager处理单个节点的资源,并处理来自上面两层的命令。
2.4.3 MapReduce编程模型
- 输入一个大文件,通过Split之后,将其分为多个分片。
- 每个文件分片由单独的机器去处理,这就是Map方法。
- 将各个机器计算的结果进行汇总并得到最终的结果,这就是Reduce方法。
三. Hadoop 核心MapReduce
3.1 Mapreduce和Yarn简介
3.1.1 实战MapReduce程序
- 通过Python程序演示Map方法和Reduce方法
- 提交基于MapReduce模型的WordCount程序并执行
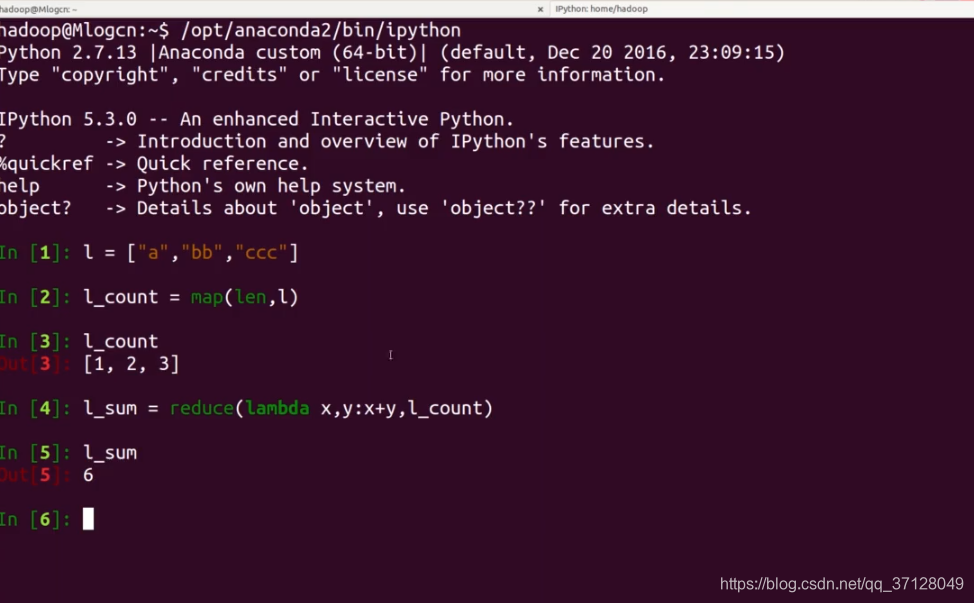
- 简单示例:
示例中,是先定义一个集合l 。 然后将此集合l 进行 map 映射。 映射后 l_count 得到了集合l 的数据。然后再通过reduce进行计算。 计算后得到l_sum ,而 l_sum则为通过计算得到的结果;
四. Hadoop生态圈介绍
4.1 Hadoop总结及延伸思考
- 如何通过Hadoop存储小文件?
- 当有节点故障的时候,集群是如何继续提供服务的,如何读,如何写?
- 哪些是影响MapReduce性能的因素?
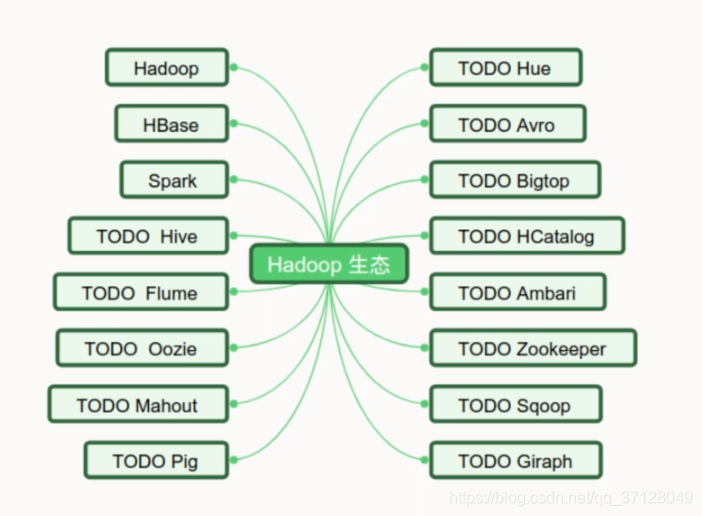
4.2 Hadoop生态圈简介
- 生态圈内容如下:
图里只是部分。
4.3 HBase简介
- 简单介绍:
- 高可靠,高性能,面向列,可伸缩,实时读写的分布式数据库
- 利用HDFS作为其文件存储系统,支持MR程序读取数据
- 存储非结构化和半结构化数据
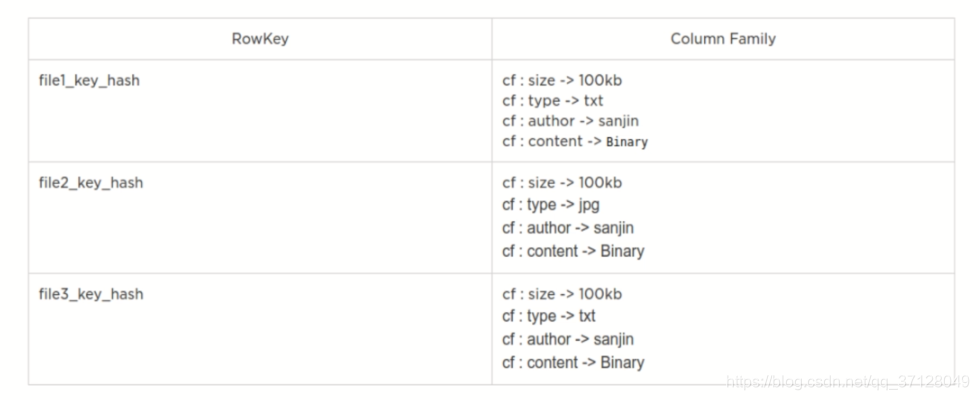
- 结构如下:
- RowKey:数据唯一标识,按字典排序
- Column Family:列族,多个列的集合,最多不要超过3个
- TimeStamp时间戳:支持多版本数据同时存在
- 如图所示:
4.4 Spark简介
4.4.1 Spark简介
- 基于内存计算的大数据并行计算框架
- Spark是MapReduce的替代解决方案,兼容HDFS,HIVE等数据源。
4.4.2 Spark的优势
- 基于内存计算的分布式计算框架
- 抽象出分布式内存存储数据库结构 弹性分布式数据集RDD
- 基于事件驱动,通过线程池复用线程池提高性能
