hadoop概述
- 存储和分析网络数据
- 三大组件
- MapReduce
- 对海量数据的处理
- 思想:
- 分而治之
- 每个数据集进行逻辑业务处理map
- 合并统计数据结果reduce
- HDFS
- 储存海量数据
- 分布式存储
- 安全性高
- 副本数据
- YARN
- 分布式资源管理框架
- 管理整个集群的资源(内存、CPU核数)
- 分配调度集群资源
- 分布式资源管理框架
- Common
- 工具
- MapReduce
hadoop生态圈
- Hive(蜜蜂)通过使用sql语句来执行hadoop任务
- HBase 存储结构化数据的分布式数据库
- HBase放弃了事务特性,追求更高的扩展
- 和HDFS不同的,HBase提供数据的随机读写和实时访问,实现对表数据的读写功能
- zookeeper 维护节点状态
Hadoop安装
- 使用docker安装
docker run -i -t -p 50070:50070 -p 9000:9000 -p 8088:8088 -p 8040:8040 -p 8042:8042 -p 49707:49707 -p 50010:50010 -p 50075:50075 -p 50090:50090 sequenceiq/hadoop-docker:2.6.0 /etc/bootstrap.sh -bashHDFS基本概念
- 块 (Block)
- HDFS的文件被分成块进行存储
- HDFS块的默认大小64M
- 块是文件储存处理的逻辑单元
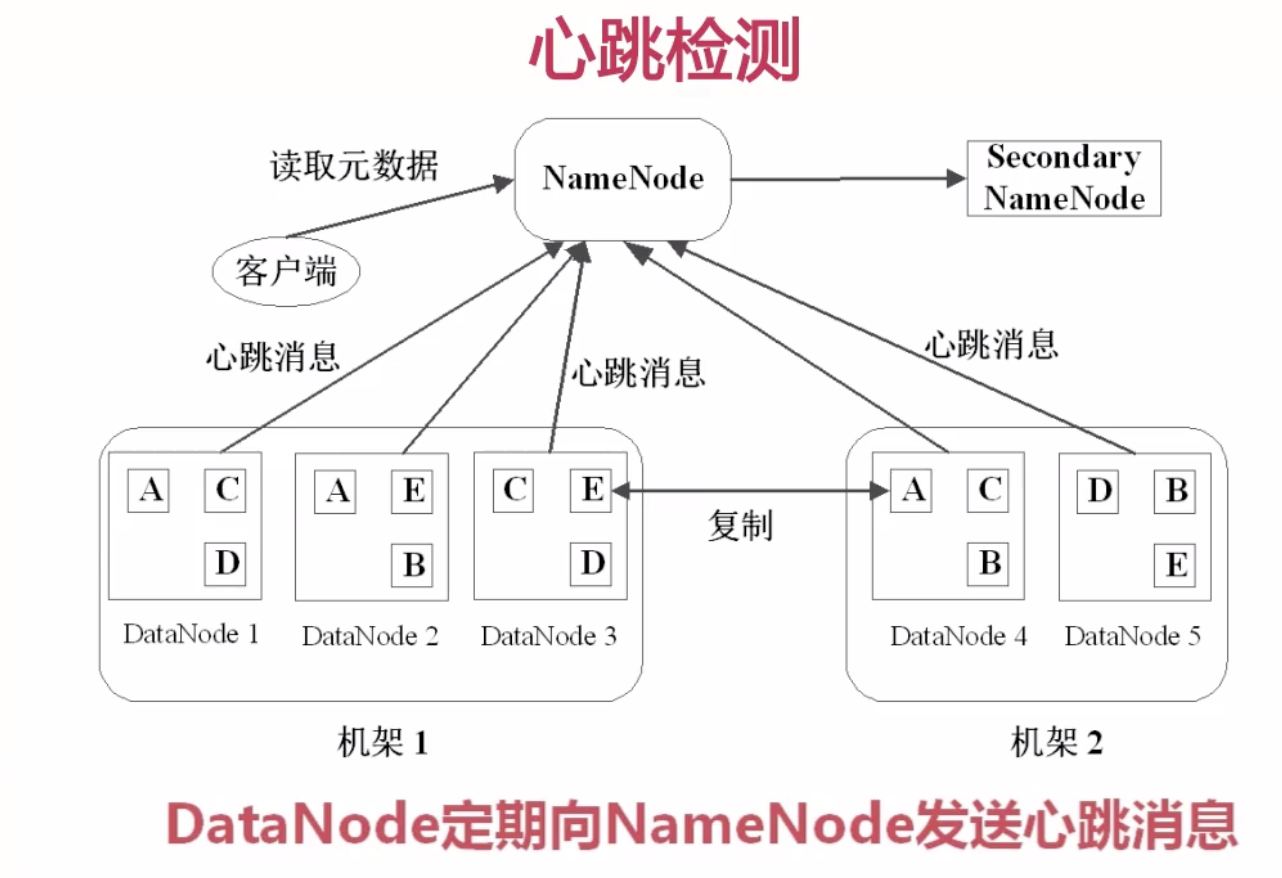
- NameNode
- NameNode是管理节点,存放文件元数据
- 文件与数据块的映射表
- 数据块与数据节点的映射表

- DataNode
- 是HDFS的工作节点,存放数据块
HDFS中数据管理与容错
数据块副本

心跳检测
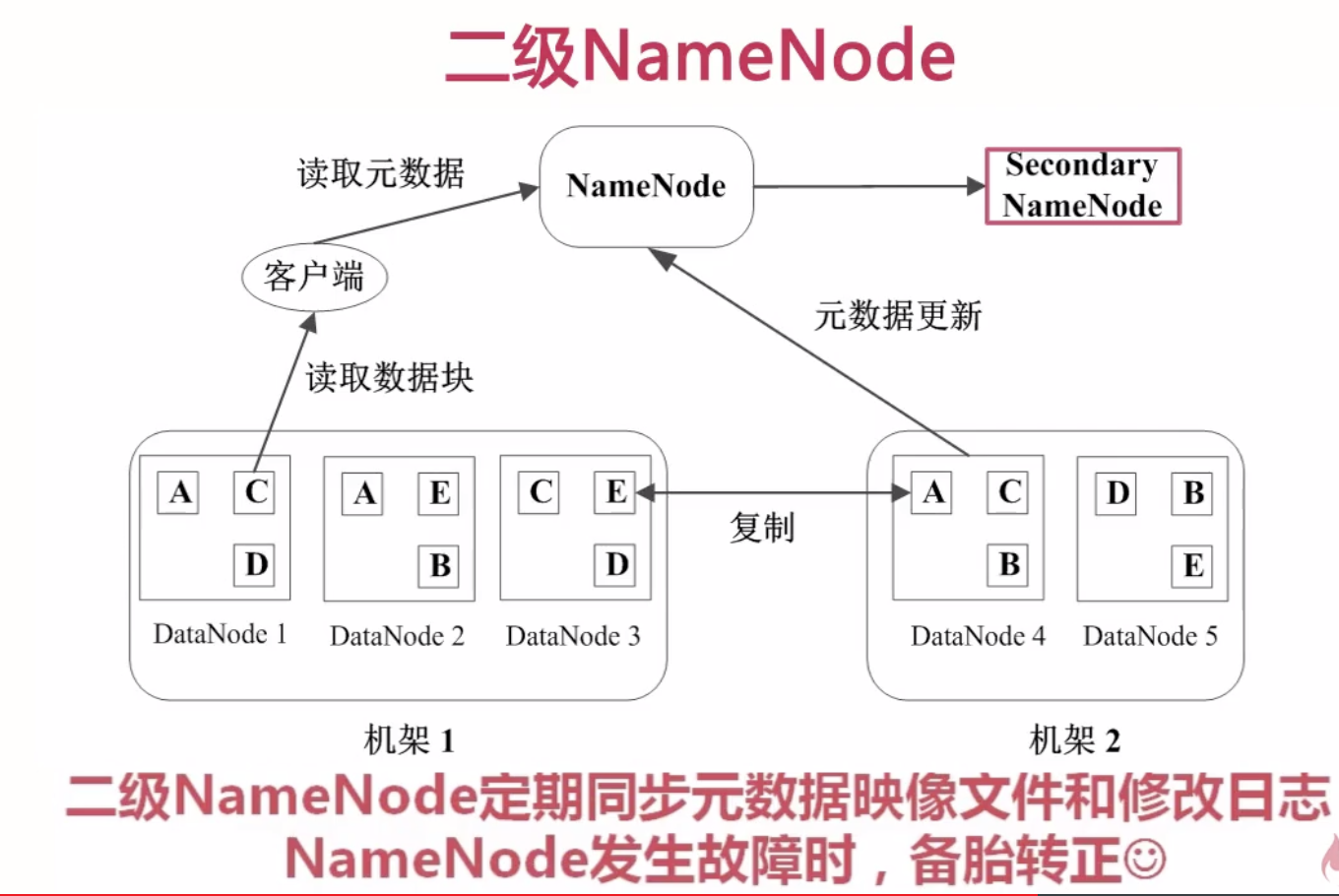
二级NameNode
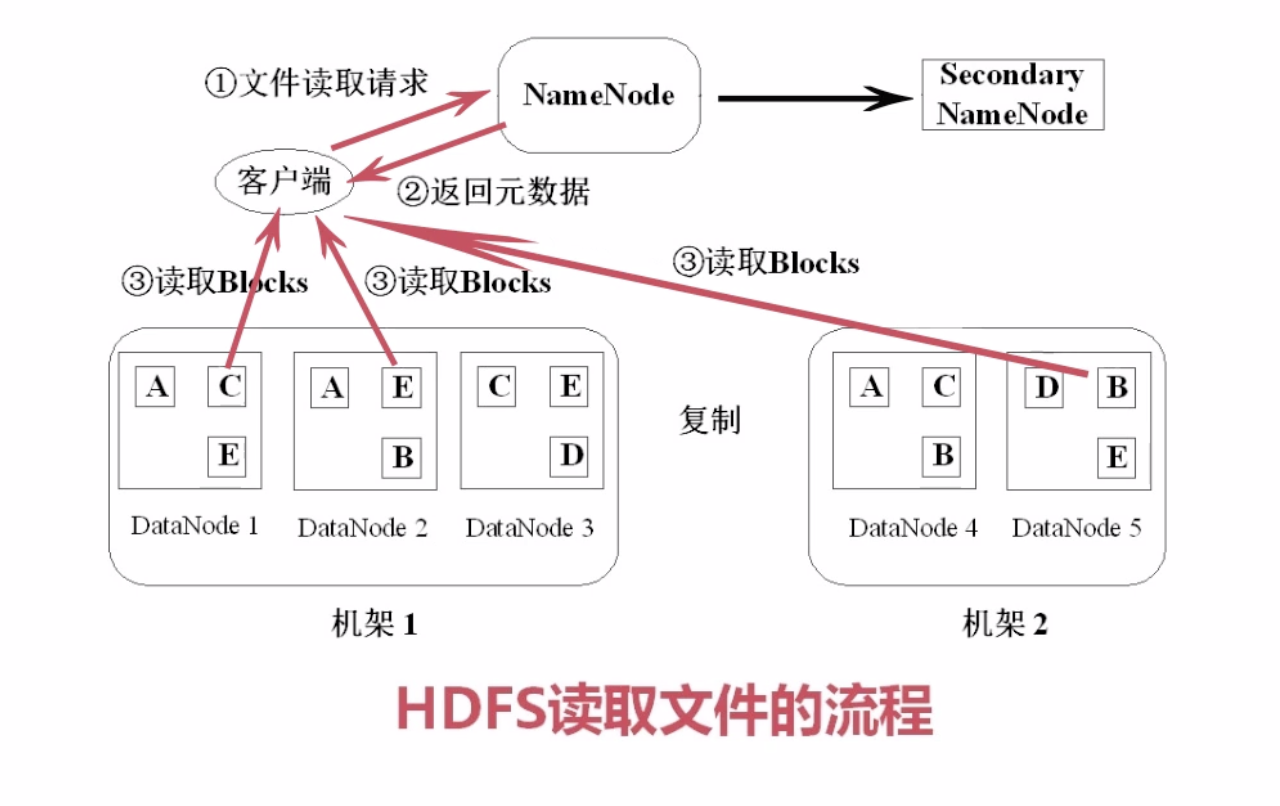
HDFS中文件读写的流程
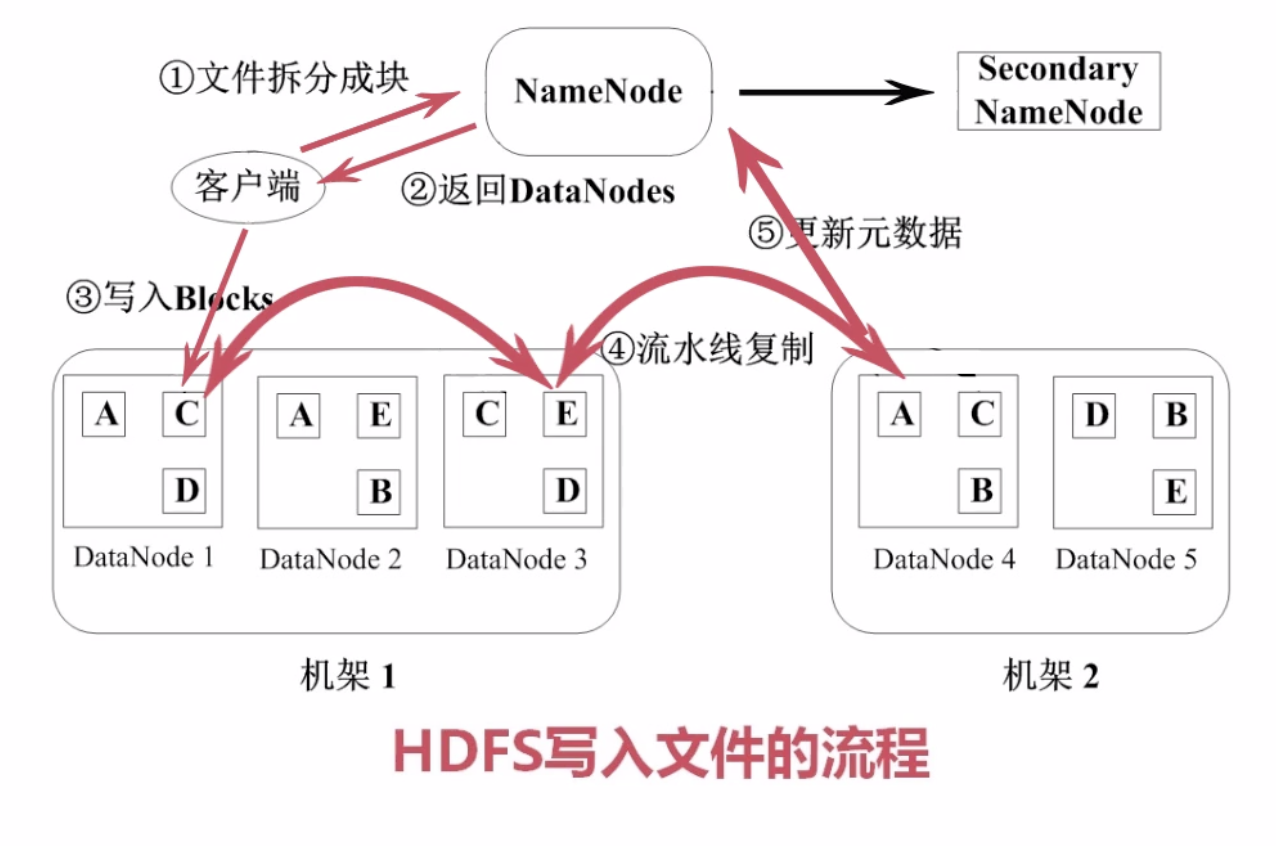
HDFS写入文件的流程
HDFS的特点
- 数据冗余,硬件容错
- 流式的数据访问
- 适合存储大文件
- 适合数据批量读写,吞吐量高
- 不适合交互式应用,低延迟很难满足
- 适合一次写入多次读取,顺序读写
- 不支持多用户并发写相同文件
HDFS命令行操作
- hadoop fs -ls /
- hadoop namenode -format 格式化操作
- hadoop fs -ls /user
- hadoop fs -put hadoop-env.sh /user/root 把文件放入hadoop
- hadoop fs -rm input
- hadoop fs -rm hadoop-env.sh
- hadoop fs -mkdir input
- hadoop fs -cat input/hadoop-env.sh
- hadoop fs -get input/hadoop-env.sh hadoop-env2.sh
- hadoop dfsadmin -report
MapReduce原理
- 分而治之,一个大人物分成多个小的子任务(map),并行执行后,合并结果(reduce)
- 比如:100GB的网站访问日志文件,找出访问次数最多的IP地址
- 根据日期切分,比如按周,每周一份进行统计
- 再合并到某几个机器进行分析合并
MapReduce运行流程
- 基本概念
- Job & Task 一个job就例如上面的例子,task可以分为map task和reduce task
- JobTracker
- 作业调度
- 分配任务、监控任务执行进度
- 监控TaskTracker的状态
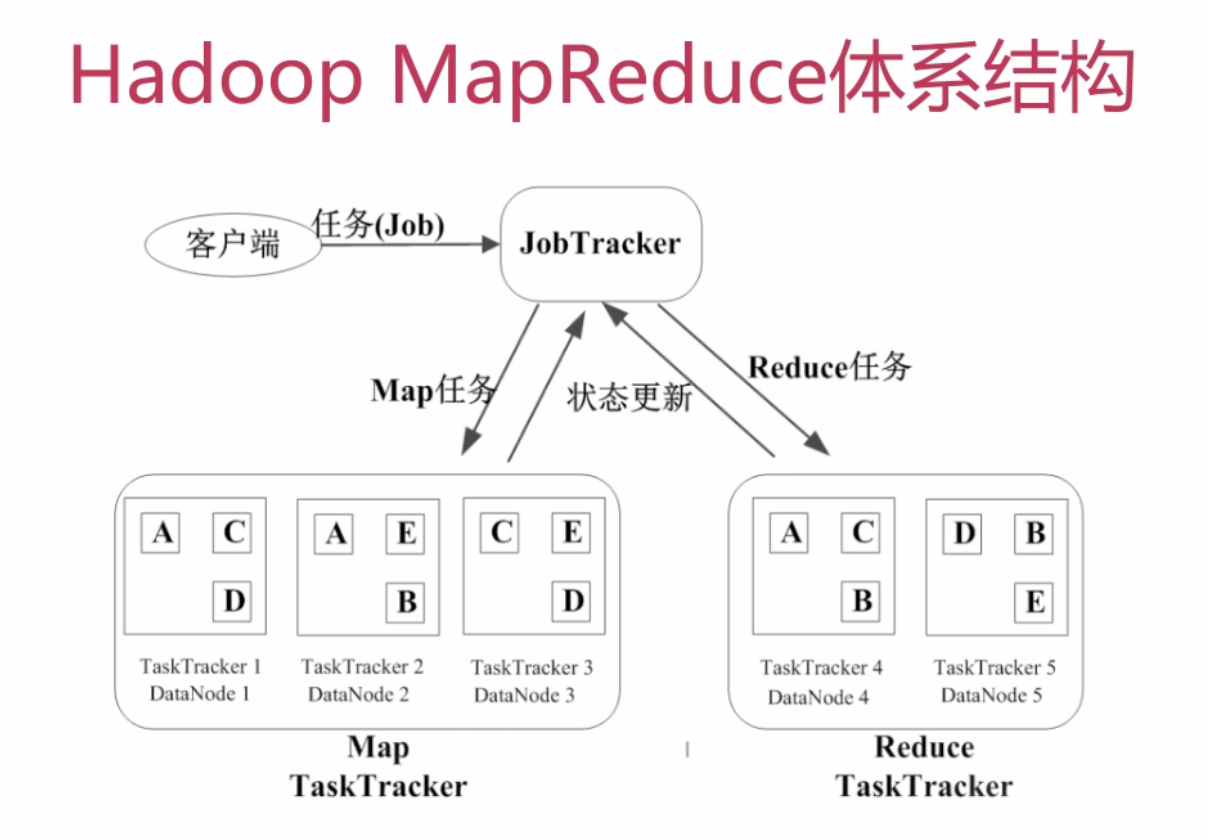
- TaskTracker
- 执行任务
- 汇报任务状态
- MapReduce作业执行过程

MapReduce的容错机制
- 重复执行
- 重复4次仍旧失败放弃
- 推测执行
- 假设有个TaskTracker执行特别慢,它会启动另一个TaskTracker执行相同的任务,两个谁先执行完,就放弃另一个
MapReduce应用
WordCount单词计数
由于我是docker安装,具体例子可以参考如下
docker安装的容器里,自带了例子,位置是/usr/local/hadoop-2.6.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar