感谢李奥诃弗斯基的悉心教导完成编译部分工作,万分感谢!
本文使用开源项目chineseocr_lite,已上传百度网盘(2020/3/16),提取码:oade
以下适合Windows系统,需要使用VS进行简单编译,若用Linux系统可直接参考原项目,应该更简单。


安装
1. PyTorch
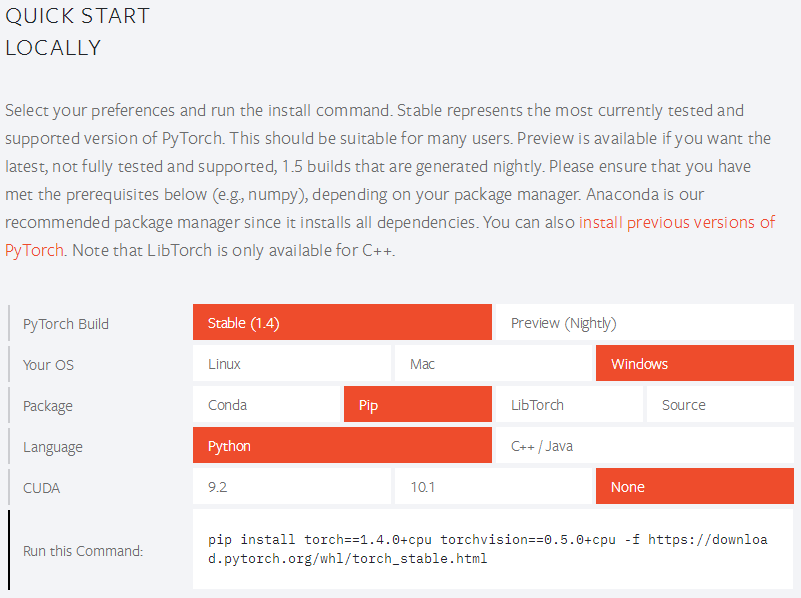
进入PyTorch官网,选择合适自己的版本。
如笔者使用pip且仅CPU环境,执行命令安装:pip install torch==1.4.0+cpu torchvision==0.5.0+cpu -f https://download.pytorch.org/whl/torch_stable.html
2. Python库
pip install web.py==0.40.dev0
3. VS2015及以上
必须装上VC++模块,用于后面编译。
编译PSENET
本人编译好的pse.pyd已上传CSDN,在Win7和Win10的Python3.6版本下测试通过,需要的亲自取。
这步是重头戏
1.打开VS2015→新建项目→Visual C++→项目命名为pse

2.勾上空项目
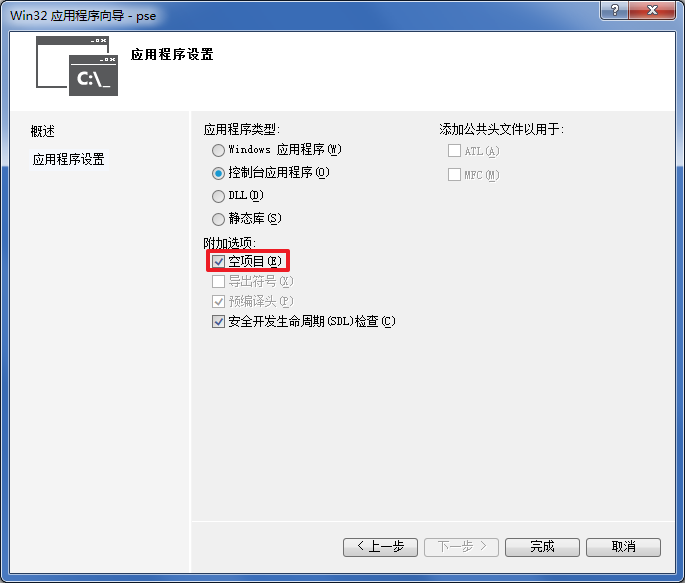
3.配置属性(常规):右键项目pse→属性→配置Release→平台x64→目标文件扩展名.pyd→配置类型动态库(.dll)

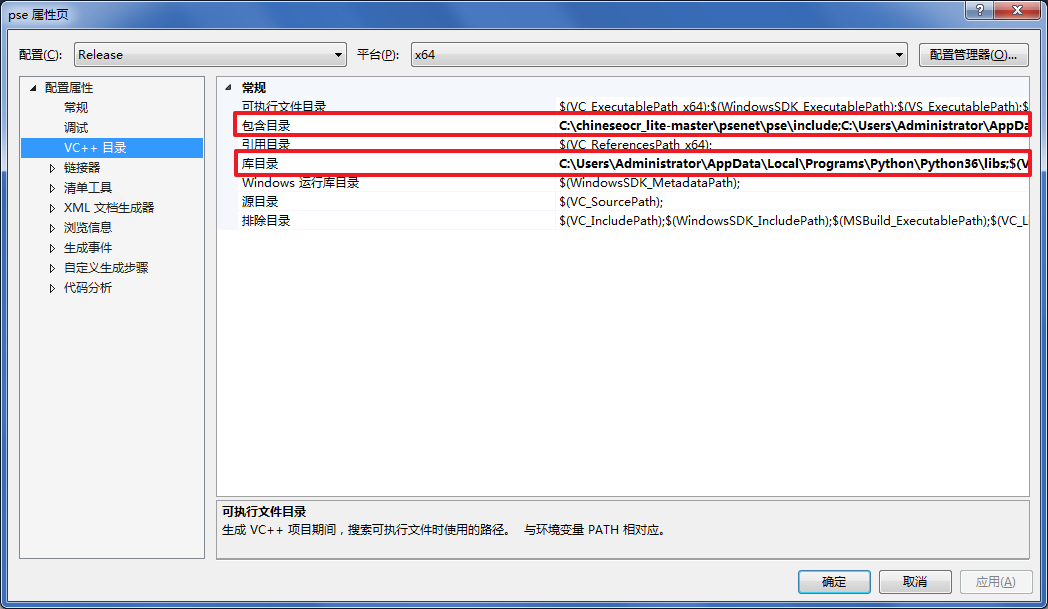
4.配置属性(VC++目录):包含目录添加C:\chineseocr_lite-master\psenet\pse\include(项目文件)和C:\Users\Administrator\AppData\Local\Programs\Python\Python36\include(你的Python),库目录添加C:\Users\Administrator\AppData\Local\Programs\Python\Python36\libs(注意,是libs不是Lib)
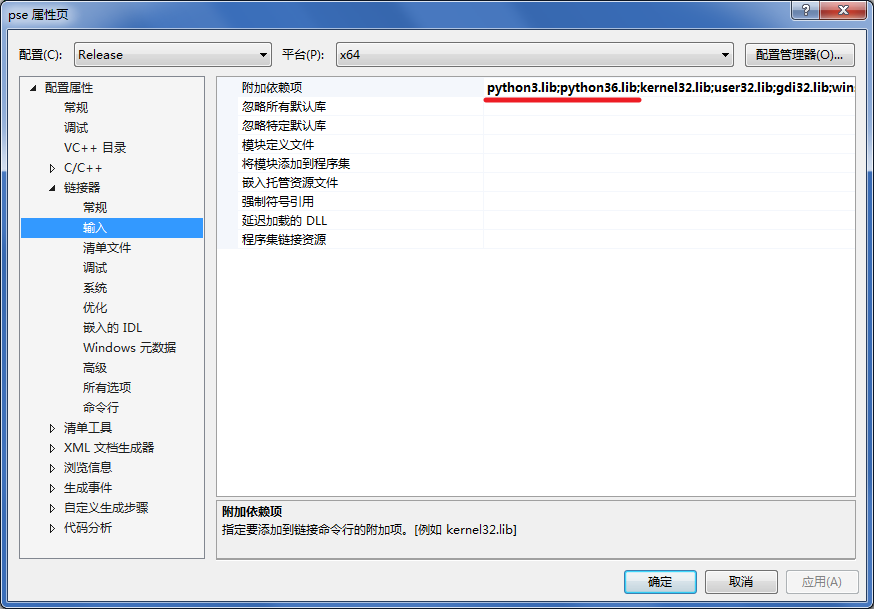
5.附加依赖项:添加python3.lib;python36.lib;
4.配置管理器→活动解决方案配置Release→活动解决方案平台x64

5.把项目\psenet\pse\pse.cpp复制到源文件里→右键项目pse→重新生成
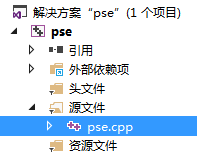
6.在VS项目pse\x64\Release就编译好了我们要的库文件pse.pyd
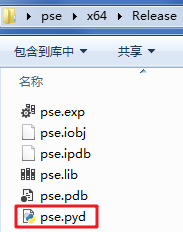
7.将pse.pyd复制到与项目\psenet\pse\pse.cpp同一文件夹下
运行app.py
访问http://127.0.0.1:8080/ocr
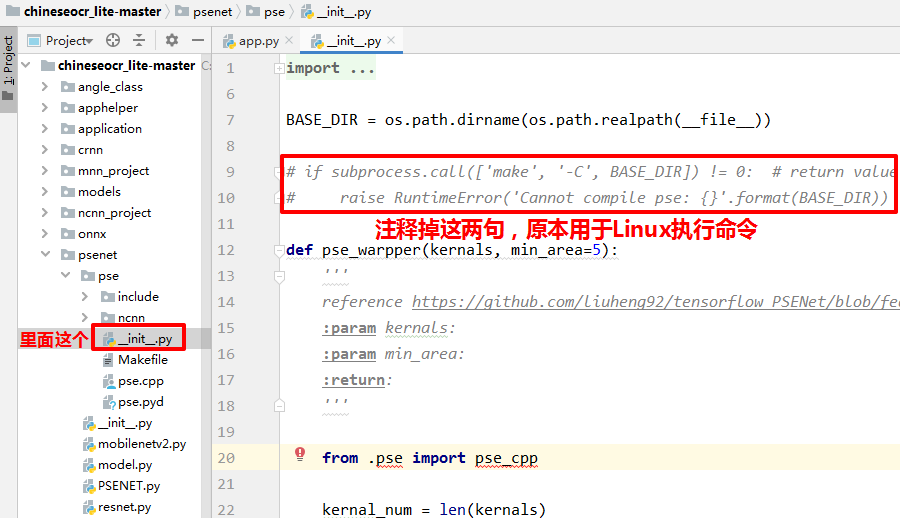
1.报错RuntimeError: Cannot compile pse: C:\chineseocr_lite-master\psenet\pse
注释掉psenet\pse\__init__.py的两行代码
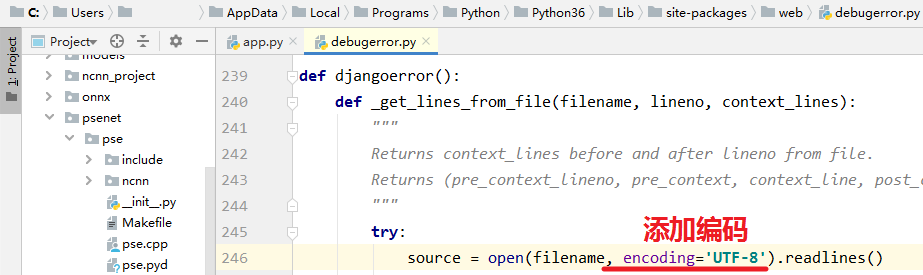
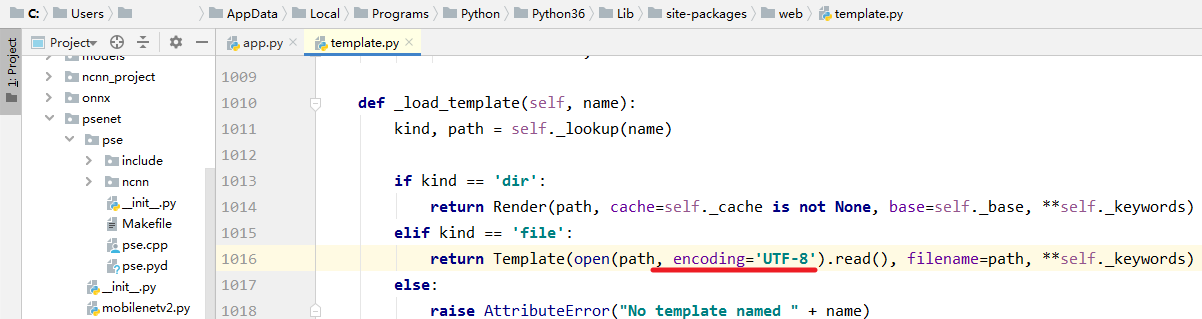
2.报错UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0xab in position 551: illegal multibyte sequence
点进报错所在代码,添加编码, encoding='UTF-8'
3.报错UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0xa7 in position 982: illegal multibyte sequence
同上,添加编码, encoding='UTF-8'
GPU版本
- 安装CUDA+cuDNN
- GPU版本PyTorch
- 执行命令
nvidia-smi查看GPU的ID - 修改config.py的GPU_ID
