一. 研究背景
文字识别是CV领域应用最广,最接地气的方向之一,从证件识别到智慧医疗,从拍照识别到无人驾驶,从车牌识别到物流分拣,几乎涵盖了AI的所有场景。
通常文字识别分成两步,文本位置检测 + 识别。
> 论文参考:
> 常用数据集:
| 数据集名称 | 内容说明 | 下载 | 中英文 |
| ICDAR2011 | 2011, Localization,Recognition 2013, Localization, Segmentation, Recoginition. 2015/17, Localization, Recognition, End-to-end. 2017增加了中文检测识别RCTW |
【下载】 | 英文 |
| ICDAR2013 | 【下载】 | 英文 | |
| ICDAR2015 | 【下载】 | 英文 | |
| ICDAR2017 | 【下载】 | 中英文 | |
| COCO Text | 包含63,686张图片,但标注质量并不是太好。 |
【下载】 | 中英文 |
| MSRA-TD500 | 共500张自然场景图片,含倾斜图片 Training 300 + Test 200。 |
【下载】 | 中英文 |
| CTW | 清华大学、腾讯 联合推出,32285张高清街景图,>1 Million 字符。 论文:【Chinese Text in the Wild】 |
【下载】 | 中文 |
| ICPR MTWI |
阿里和ICPR联合推出的Challenge: 提供20000张图像,50%训练+50%测试。数据来源于网络图像,由合成图像,产品描述,网络广告构成。 |
【下载】 | 中文 |
| Synth | 合成数据,参考论文: 【Synthetic Data for Text Localisation in Natural Images】 【代码下载】 【Synthetic Data and Artificial Neural Networks for Natural Scene Text Recognition】 |
【80k】 【90k】 |
中英文 |
关于ICDAR数据集的详细说明,请参考文档【ICDAR 2017】
二. OCR检测之EAST
EAST算法是一个比较简单的方法,来自旷世的一篇文章。
论文:EAST: An Efficient and Accurate Scene Text Detector【下载】【code】
其关键在于能满足实时应用的要求,首先来看一张OCR检测 对比图:
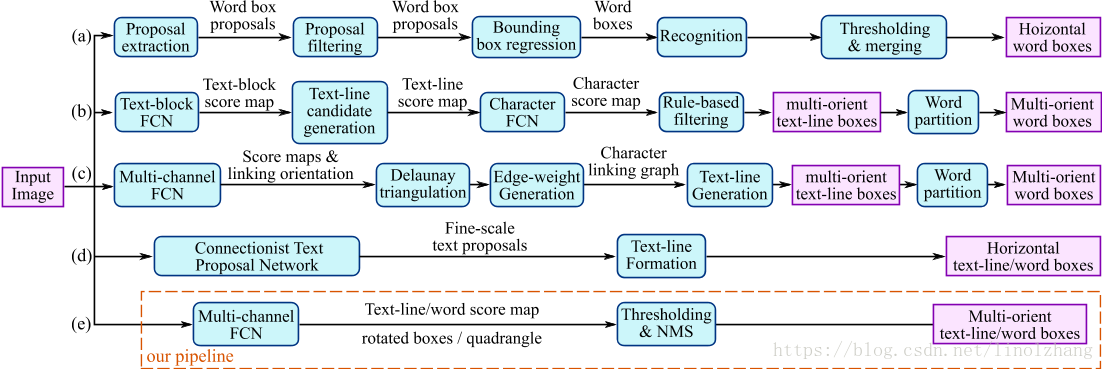
基于DNN的传统OCR检测方法通常包括:生成候选目标(candidate proposal)、文字区域(text region formation)、字符分割(word partition)等过程。
EAST的核心思想在于直接回归目标位置,跳过了上述中间过程,后续过程仅包含阈值划分(Thresholding)和 非最大值抑制(NMS)。
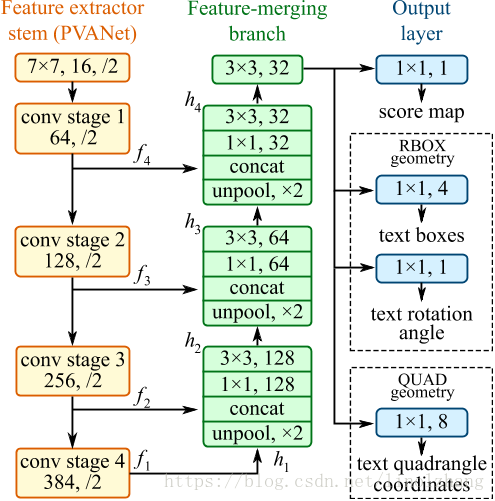
2.1 网络结构图
EAST网络结构图比较简单,分成3个部分:
1)特征提取主干网
文中采用的是基于PVANet的FCN网络,也尝试了VGG作为backbone,当然你也可以选择resnet;
2)特征合并分支
意义在于通过反卷积(Deconv)实现不同层之间的特征叠加,通过金字塔特征merge来提高多尺度的适应性。
3)输出层
采用1 channel作为score map;5个channel(4+1)的RBOX定义矩形框;或者8 channel的QUAD定义多边形。
2.2 精简的Branch
EAST网络的merging brach采用了逐层减少的特征层,虽然少,但起到了上层特征传播的目的,如上图所示,3个branch层的channel分别是128、64、32,没有明显增加计算复杂性。

2.3 输出层与label定义
常用的标注类型有三种,AABB、RBOX、QUAD,与标注数据有关:

RBOX:Box(1x1,4)+ Roation(1x1, 1)
Box描述(1x1,4)对应输出的geometry_map,即4个通道分别对应每个像素点到矩形框上、右、下、左边界的距离。
Rotation描述(1x1, 1)对应矩形框的旋转角。
QUAD:(1x1,8)
QUAD对应输出的geometry_map,8个通道分别代表每个像素点到任意四边形的四个顶点的距离。
来看示意图,对应输出映射:

2.4 定义loss函数
loss函数分两部分,score map的分类误差 和 geometry map的位置回归误差:
L = Ls + λg Lg , λg=1
> Score Loss
Score Loss 采用了balanced cross-entropy,用来处理正负样本不均衡的问题。
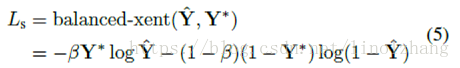
其中平衡参数β代表 负样本比例(=负样本数量/总样本数量 ):

> Geometry Loss
对于RBOX,定义Loss :
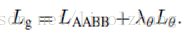
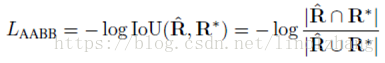


对于QUAD ,采用Smooth L1 Loss:
假设顶点坐标 CQ = {x1,y1,x2,y2,x3,y3,x4,y4} ,那么:
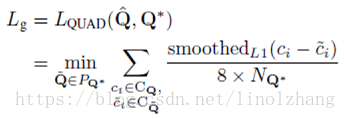
其中 NQ 表示4变形最短边的长度,参考公式:
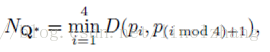
2.5 基于NMS的几何过滤
这里采用的是 Locality-Aware NMS 策略,通过假设临近像素的几何位置具有高相关性,对每一行的geometry进行merge,当IoU大于某个阈值时,采用 weigte_merge策略,公式描述为:
weighted_merge(g, p) = (k1*g+k2*p) / (k1+k2)
weighted_merge是指基于得分的Rect合并,新的位置是基于score的加权平均,这种方法能够讲所有回归的Rect按照权重进行整合,有效减少误差,因此是比较准确稳定的。
作者程序中提供了python和c++两种实现方式,其中,c++实现的 locality_aware_nms 相比python实现的速度快了近120倍。
2.6 训练及结果
文中实现了基于RBOX的训练,效果和效率都不错。
对于EAST的固有缺陷,会存在一些问题,一是特征层不够准确;二是受限于感受野的问题,对长文本的检测效果不好。
对于特征层的问题,一般可以通过增加训练数据,增大主干网网络等方式,长文本改进的一种方式是 AdvancedEAST。
三. OCR改进之 AdvancedEAST
Advanced EAST 算法【Paper】【Github】
考虑到原始的 EAST 采用所有矩形框像素来回归Geometry,问题在于不同距离带来的误差不同,特别是中间像素,因此将像素分为两部分,内部像素(白色)+ 边缘像素(黄+绿),如下图所示:

简单的说,只用 边缘像素(黄+绿)来回归矩形框的位置,
3.1 改进后的结构图
只看输出部分(output)的变化:
- 1位 score map, 是否在文本框内; 【与原算法一致】
- 2位 vertex code,是否属于文本框边界像素以及是头还是尾;【像素标记位】
- 4位 vertex geo,边界像素可以预测的2个顶点坐标。【边缘顶点】
用所有的边界像素预测值的加权平均来预测头或尾的短边两端的两个顶点。头和尾部分边界像素分别预测2个顶点,最后得到4个顶点坐标。

3.2 代码分析及应用
待更新~