行业热词解释
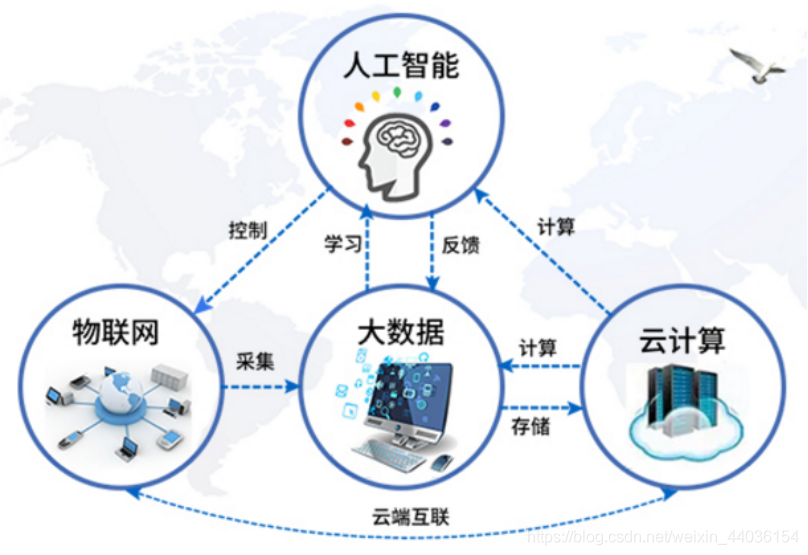

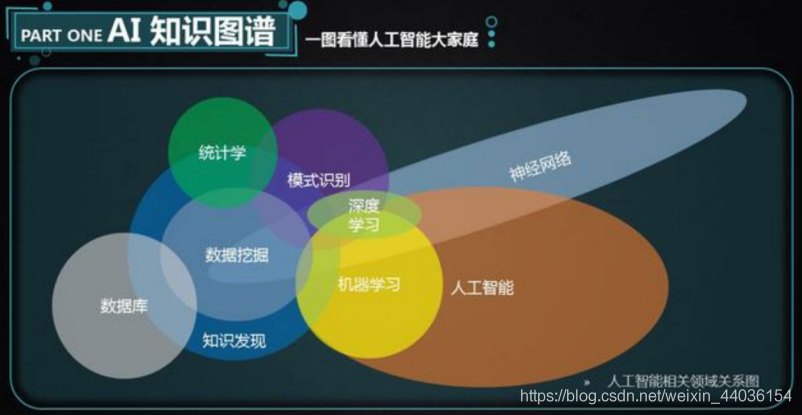

机器学习基本术语
假如我们有一组天气数据,是来自全世界不同国家和地区的每日天气,内容包括最高温度、最低温度、平均湿度、风速之类的相关数据,例如数据的一部分是这样的:
| 城市 |
最高温度 |
最低温度 |
相对湿度 |
某时刻风速 |
| A市 |
36℃ |
28℃ |
58% |
16.7km/h |
| B市 |
28℃ |
17℃ |
86% |
/ |
| C市 |
34℃ |
29℃ |
39% |
20.4km/h |
在这组数据中,我们将称A市、B市、C市等市以及其情况的总和称为数据集(data set)。表格中的每一行,也就是某城市和它的情况被称为一个样例(sample/instance)。表格中的每一列(不包括城市),例如最高温度、最低温度,被称为特征(feature/attribute),而每一列中的具体数值,例如36℃ 、28℃,被称为属性值(attribute value)。数据中也可能会有缺失数据(missing data),例如B市的某时刻风速,我们会将它视作缺失数据。
如果我们想预测城市的天气,例如是晴朗还是阴雨天,这些数据是不够的,除了特征以外,我们还需要每个城市的具体天气情况,也就是通常语境下的结果。在机器学习中,它会被称为标签(label),用于标记数据。值得注意的是,数据集中不一定包含标签信息,而这种区别会引起方法上的差别。我们可以给上述示例加上一组标签:
| 城市 |
天气 |
| A市 |
晴朗 |
| B市 |
阴雨 |
| C市 |
晴朗 |
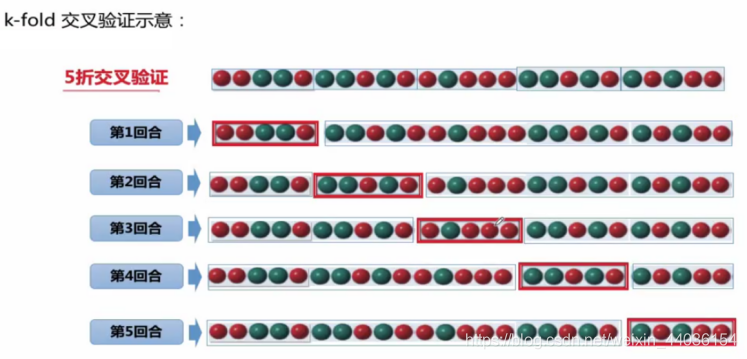
视具体情况,用来进行机器学习的一个数据集往往会被分为两个数据集——训练数据(training data)和测试数据(testing data)。 顾名思义,训练数据在机器学习的过程中使用,目的是找出一套机器学习的方法;而测试数据用于判断找出的方法是否足够有效。如果在训练的过程中需要确定方法的准确度,有时会将训练数据分成训练集(training set)和验证集(validation set)——验证集合测试数据不同的地方在于验证集在训练过程中使用,而测试数据事实上是在模型建立后才被使用的。
机器学习的整体流程


机器学习的过程就是一个数据流转、分析以及得到结果的过程,在使用的过程中很多
人花了很多时间在算法的选择或者调优上,但其实机器学习的每一个步骤都是至关重要的,其中特征工程部分尤其重要,甚至直接决定了机器学习项目的成败!

不会做特征工程的 AI 研究员不是好数据科学家!
http://www.sohu.com/a/217650404_114877
http://www.sohu.com/a/218158264_114877
(1)需求分析。场景解析就是先把整个业务逻辑想清楚,把自己的业务场景进行一个
抽象,例如我们做一个广告点击预测,其实是判断一个用户看到广告是点击还是不点击,这就可以抽象成二分类问题。然后我们根据是不是监督学习以及二分类场景,就可以进行算法的选择。总的来说,场景抽象就是把业务逻辑和算法进行匹配。

(2)数据预处理。数据预处理主要进行数据的清洗工作,针对数据矩阵中的空值和乱
码进行处理,同时也可以对整体数据进行拆分和采样等操作,也可以对单字段或者多字段进行归一化或者标准化的处理。数据预处理阶段的主要目标就是减少量纲和噪音数据对于训练数据集的影响。

(3)特征工程。特征工程是机器学习中最重要的一个步骤,这句话一点都没有错。
特别是目前随着开源算法库的普及以及算法的不断成熟,算法质量并不一定是决定结果的最关键因素,特征工程的效果从某种意义上决定了最终模型的优劣。通过一个例子说明一下特征工程的作用,2014 年某互联网巨头举办了一场大数据竞赛,参赛队伍
在 1000 个以上,到最后,这里面几乎所有的参赛队伍都用了相同的一套算法,因为算法的优劣是比较容易评判的,不同算法的特性是不一样的,而且可供选择的算法种类是有限的。但是特征的选取和衍生却有极大的不定性,100 个人眼中可能有 100 种不同的特征,所以这种大赛到了后期,往往大家比拼的就是特征选取的好坏。在算法相对固定的情况下,可以说好特征决定了好结果。

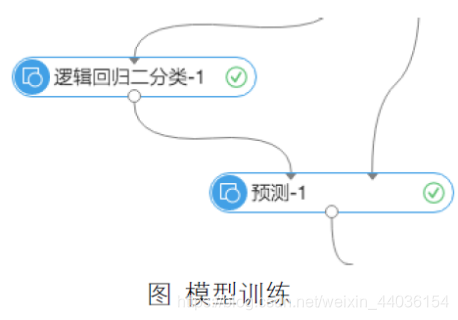
(4)模型训练。“逻辑回归二分类”表示的是算法训练过程,训练数据经过了数据预处理和特征工程之后进入算法训练模块,并且生成模型。在“预测”中,读取模型和预测集数据进行计算,生成预测结果。

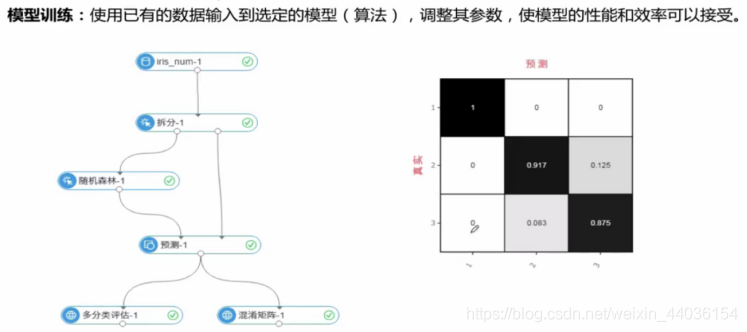
(5)模型评估。机器学习算法的计算结果一般是一个模型,模型的质量直接影响接下来的数据业务。对于模型的成熟度的评估,其实就是对于整套机器学习流程的评估。

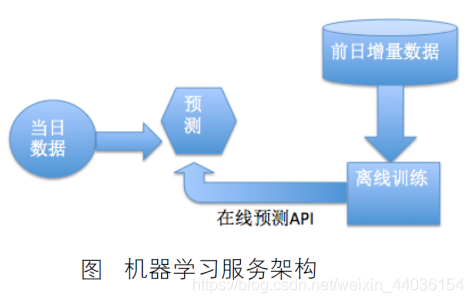
(6)离线/在线服务。在实际的业务运用过程中,机器学习通常需要配合调度系统来使用。具体的案例场景如下:每天用户将当日的增量数据流入数据库表里,通过调度系统启动机器学习的离线训练服务,生成最新的离线模型,然后通过在线预测服务(通常通过Restful API,发送数据到服务器的算法模型进行计算,然后返回结果)进行实时的预测。如图:
机器学习算法分类
机器学习算法包含了聚类、回归、分类和文本分析等几十种场景的算法,常用的算法种类为 30 种左右,而且还有很多的变形,我们将机器学习分为 4 种,分别是监督学习、无监督学习、半监督学习和增强学习(强化学习)。
(1)监督学习。监督学习(Supervised Learning),是指每个进入算法的训练数据样本都有对应的期望值也就是目标值,进行机器学习的过程实际上就是特征值和目标队列映射的过程。例如,我们已知一只股票的历史走势以及它的一些公司盈利、公司人数等信息,想要预测这只股票未来的走势。那么在训练算法模型的过程中,就是希望通过计算得到一个公式,可以反映公司盈利、公司人数这些信息对于股票走势的影响。通过过往的一些数据的特征以及最终结果来进行训练的方式就是监督学习法。监督学习算法的训练数据源需要由特征值以及目标队列两部分组成。
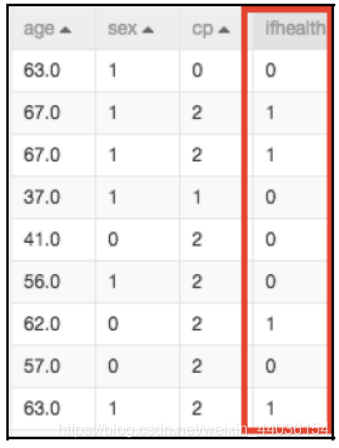
如图所示,ifhealth 是目标队列,age、sex 和cp 为特征队列,这就是一个典型的监督学习的训练数据集。因为监督学习依赖于每个样本的打标,可以得到每个特征序列映射到的确切的目标值是什么,所以常用于回归以及分类场景。
监督学习的一个问题就是获得目标值的成本比较高。例如,我们想预测一个电影的好坏,那么在生成训练集的时候要依赖于对大量电影的人工标注,这样的人力代价使得监督学习在一定程度上是一种成本比较高的学习方法。如何获得大量的标记数据一直是监督学习面临的一道难题。
(2)无监督学习。无监督学习(Unsupervised Learning),学习上面讲的监督学习的概念之后,其实无监督学习就比较好理解了。无监督学习就是指训练样本不依赖于打标数据的机器学习算法(自己学习)。既然是没有目标队列,也就缺少了特征环境下的最终结果,那么这样的数据可能对一些回归和分类的场景就不适合了。无监督学习主要是用来解决一些聚类场景的问题,因为当我们的训练数据缺失了目标值之后,能做的事情就只剩下比对不同样本间的距离关系。
相较于监督学习,无监督学习的一大好处就是不依赖于打标数据,在很多特定条件下,
特别是打标数据需要依靠大量人工来获得的情况下可以尝试使用无监督学习或者半监督学习来解决问题。
(3)半监督学习。半监督学习(Semi-supervised Learning),是最近几年逐渐开始流行的一种机器学习种类。上文中也提到,在一些场景下获得打标数据是很耗费资源的,但是无监督学习对于解决分类和回归这样场景的问题又有一些难度。所以人们开始尝试通过对样本的部分打标来进行机器学习算法的使用,这种部分打标样本的训练数据的算法应用,就是半监督学习。目前很多半监督学习算法都是监督学习算法的变形。其实目前半监督算法已经有很多的应用了,大家感兴趣的话可以课下去深入了解。
(4)强化学习。强化学习(Reinforcement Learning),是一种比较复杂的机器学习种类,强调的是系统与外界不断地交互,获得外界的反馈,然后决定自身的行为。强化学习目前是人工智能领域的一个热点算法种类,典型的案例包括无人汽车驾驶和阿尔法狗下围棋。分词算法隐马尔科夫就是一种强化学习的思想。
上面就是关于监督学习、无监督学习、半监督学习和强化学习的一些介绍。监督学习
主要解决的是分类和回归的场景,无监督学习主要解决聚类场景,半监督学习解决的是一些打标数据比较难获得的分类场景,强化学习主要是针对流程中不断需要推理的场景
- SparkMLlib中支持的机器学习算法
https://ifeve.com/spark-mllib/

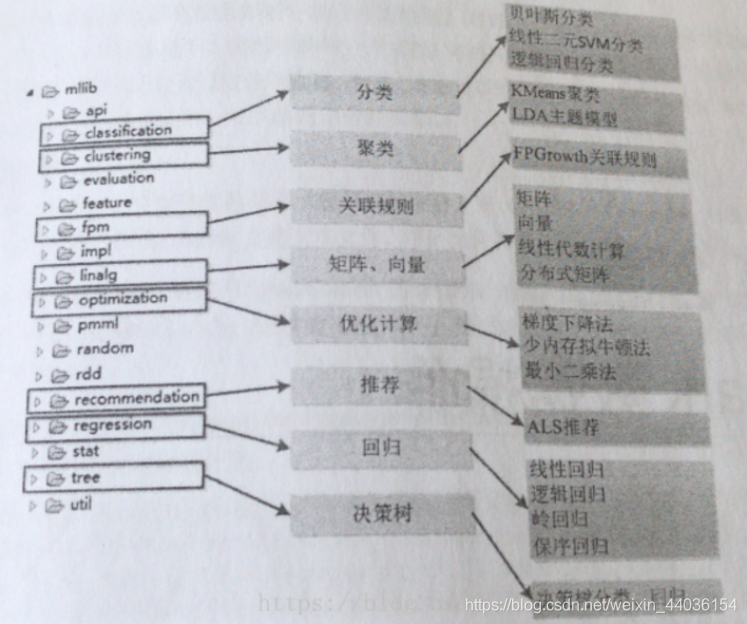
- 分类算法
- 基本分类算法
- 决策树分类:DecisionTreeClassifier
- 支持向量机:LinearSVC
- 朴素贝叶斯:NaiveBayes
- 逻辑回归:LogisticRegression
- 其他算法:MultilayerPerceptronClassifier、OneVsRest
- 集成分类算法:基于决策树之上的算法
- 梯度提升树:GBTClassifier
- 随机森林:RandomForestClassifier
- 回归算法
- 基本回归算法
- 线性回归:LinearRegression
- 其他算法:IsotonicRegression、AFTSurvivalRegression、AFTRegression
- 决策树回归:DecisionTreeRegressor
- 保存回归:
- 集成回归算法
- 梯度提升数:GBTRegressor
- 随机森林:RandomForestRegressor
- 聚类算法
- 聚类算法:KMeans、BisectingKMeans、GaussianMixture、LDA
- 降维算法:PCA
- 推荐算法
- 协同过滤算法:ALS
- 关联规则:AssociationRules、FPGrowth
机器学习结果评估问题
二分类问题
衡量结果精度的有一些相关术语,首当其冲的是准确率(Accuracy)、精确率(Precision)和召回率(Recall)。这三个词汇应用于二分类问题:将数据分为正例(Positive Class)和反例(Negative Class)
一张形象的维基百科图:
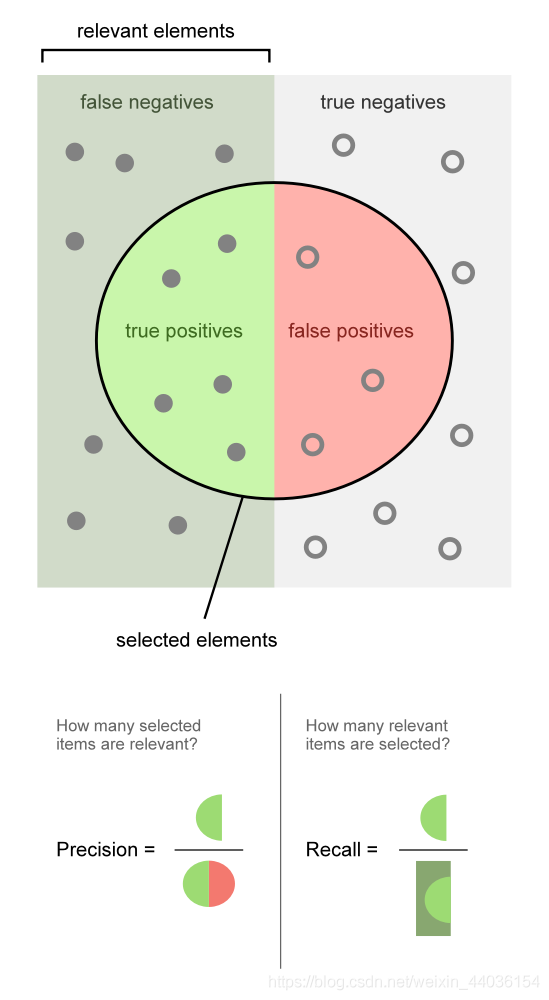
也就是说,准确率是预测和标签一致的样本在所有样本中所占的比例;精确率是你预测为正类的数据中,有多少确实是正类;召回率是所有正类的数据中,你预测为正类的数据有多少。这三个数据往往用来衡量一个二分类算法的优劣。
回归问题
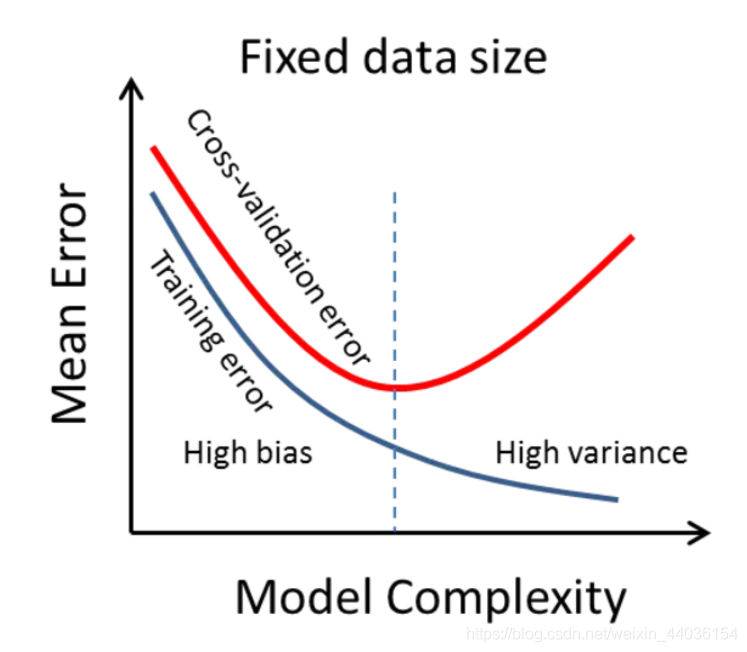
回归问题往往会通过计算误差(Error)来确定模型的精确性。误差由于训练集和验证集的不同,会被分为训练误差(Training Error)和验证误差(Validation Error)。但值得注意的是,模型并不是误差越小就一定越好,因为如果仅仅基于误差,我们可能会得到一个过拟合(Overfitting)的模型;但是如果不考虑误差,我们可能会得到一个欠拟合(Underfitting)的模型,用图像来说的话大致可以这样理解:
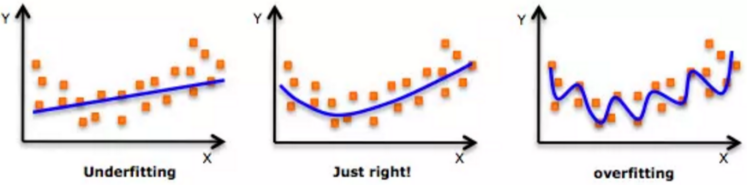
如果模型十分简单,往往会欠拟合,对于训练数据和测试数据的误差都会很大;但如果模型太过于复杂,往往会过拟合,那么训练数据的误差可能相当小,但是测试数据的误差会增大。
欠拟合(underfitting),也称为高偏差(high bias)
过拟合(overfitting),也称为高方差(high variance)
好的模型应当平衡于这两者之间:
聚类问题
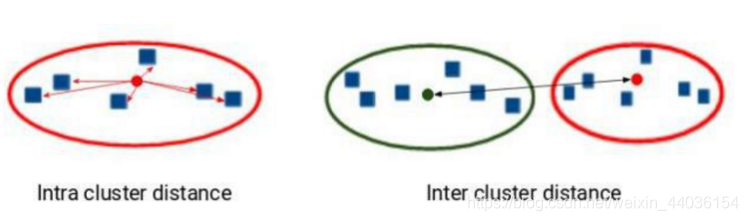
聚类问题的标准一般基于距离:簇内距离(Intra-cluster Distance)和簇间距离(Inter-cluster Distance)。根据常识而言,簇内距离是越小越好,也就是簇内的元素越相似越好;而簇间距离越大越好,也就是说簇间(不同簇)元素越不相同越好。
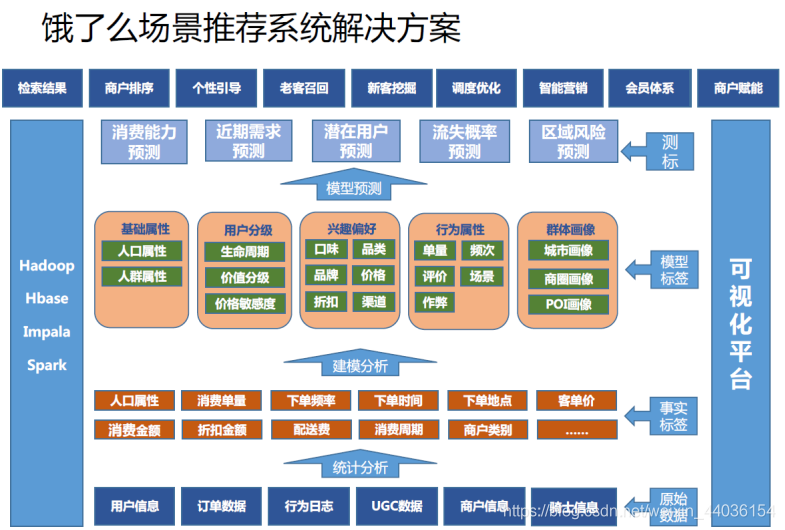
机器学习在大数据项目中的位置
扩展补充:
大数据平台的数据源集中来源于三个方面:
60%来源于关系数据库的同步迁移: 大多数公司都是采用MySQL和Oracle,就拿电商平台来说,这些数据大部分是用户基本信息,订单交易数据以及商品数据。
30%来源于平台埋点数据的采集:渠道有PC、Wap、安卓和IOS,通过客户端产生请求,采集用户行为数据,经过日志服务器服务器处理,再进Kafka接受数据并解码,最后到Spark Streaming划分为离线和实时清洗。
10%来源于第三方数据:做电商还可能会整合第三方数据源,大体有竞品公司商品数据(爬虫),用户征信信息(支付宝、京东白条等业务需要)等等
机器学习的基础知识暂且回顾到这里,感兴趣的同学课下再多去复习回顾
接下来开始用户画像系统算法挖掘标签部分的开发!