一,基础
1,熵
如果X 是一个离散型随机变量,其概率分布为
p(x)=P(X=x)
,
x∈R
。X 的熵H(X) 为
H(X)=−∑x∈Rp(x)log2p(x)
其中,约定0log 0 = 0。
H(X) 也可以写为H(p)。通常熵的单位为二进制位比特(bit)。
熵值度量的是随机变量不确定性的大小或者说是为确定随机变量所需的信息量,随机变量的熵越大,它的不确定性也就越大,为确定随机变量所需的信息量也就越大。
最大熵模型:在只掌握未知分布的部分知识的情况下,符合已知知识的概率分布可能有很多个,但使熵值最大的概率分布最大真实地反映了时间的分布情况。也就是说在已知部分知识的前提下,关于未知分布最合理的推断应该是符合已知知识最不确定或最大随机的推断。
2,联合熵
如果X, Y 是一对离散型随机变量X, Y ~ p(x, y),X, Y 的联合熵H(X, Y) 为:
H(X,Y)=−∑x∈X∑y∈Yp(x,y)logp(x,y)
联合熵实际上就是描述一对随机变量平均所需的信息量。
3,条件熵
给定随机变量X的情况下,随机变量Y的条件熵的定义如下:
H(Y|X)=∑x∈Xp(x)H(Y|X=x)=∑x∈Xp(x)[−∑y∈Yp(y|x)logp(y|x)]=−∑x∈X∑y∈Yp(x,y)logp(y|x)
联合熵与条件熵的关系:
H(X,Y)=−∑x∈X∑y∈Yp(x,y)logp(x,y)=−∑x∈X∑y∈Yp(x,y)[logp(x)+logp(y|x)]=H(X)+H(Y|X)
可以这样理解,随机变量X,Y所需的信息量=随机变量X所需的信息量+已知X的信息后,Y所需的信息量。
4,熵的连锁规则
H(X1,X2,...,Xn)=H(X1)+H(X2|X1)+...+H(Xn|X1,...,Xn−1)
5,互信息
根据熵的连锁规则,有:
H(X,Y)=H(X)+H(Y|X)=H(Y)+H(X|Y)
因此,
H(X)−H(X|Y)=H(Y)−H(Y|X)
这个差就是随机变量X,Y的互信息,记做
I(X;Y)
。
或者定义为,如果(X,Y)~p(x,y),则X,Y之间的互信息为:
I(X;Y)=H(X)−H(X|Y)
。
I(X;Y)反映的是在知道了Y的值之后,X的不确定性的减少量。可以理解为Y的值透漏了多少X的信息量。
下图很清楚的表示出了它们之间的关系:
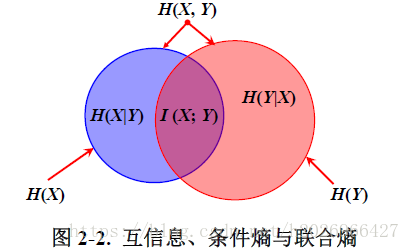
点式互信息可能未负,但平均互信息是非负的。
因为I(X;X)=H(X)-H(X|X)=H(X),所以熵又称为自信息。这也说明了两个完全依赖的变量之间的互信息并不是一个常量,而是取决于它们的熵。
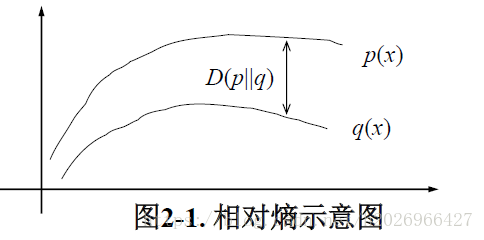
6,相对熵(KL散度或KL距离)
相对熵常用来衡量两个概率分布的距离。
两个概率分布p(x)和q(x)的相对熵定义为:
D(p||q)=∑x∈Xp(x)logp(x)q(x)
当两个概率分布完全相同时,相对熵为0,差别越大,相对熵期望值也越大。
相对熵是不对称的。
互信息与相对熵的关系:
I(X;Y)=D(p(x,y)||p(x)p(y))
即互信息实际上衡量的是一个联合分布与独立性差距的多大的测度。
7,交叉熵
对于某件事情我们知道的越多,它的熵就越小。交叉熵的概念就是衡量估计模型和真实概率分布之间差异情况的。
如果一个随机变量X~p(x),q(x)为用于近似p(x)的概率分布,那么随机变量X和模型q之间的交叉熵定义为:
H(X,q)=H(X)+D(p||q)=−∑xp(x)logq(x)=Ep(log1q(x))
8,噪声信道模型
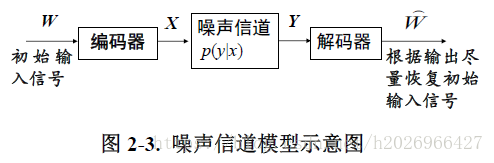
在语言处理中,我们不需要进行编码,只需要进行解码,使系统的输出更接近于输入,如机器翻译。
二,最大熵模型
1,最大熵模型的原理与形式
最大熵模型的学习等价于如下的约束最优化问题:
min−H(P)s.t. =∑x,yP(x)^P(y|x)logP(y|x)Ep(fi)=Ep̂ (fi)i=1,2,...,n∑yP(y|x)=1
其中,
Ep(fi)=∑x,yP(x)^P(y|x)f(x,y),Ep̂ (f)=P(x,y)^f(x,y)
。
H(P)
其实是满足约束的模型分布在条件概率分布
P(Y|X)
的条件熵!
通过拉格朗日对偶法的转化可得到它的更一般化的形式:
Pw(y|x)Zw(x)=exp∑ni=1wifi(x,y)Zw(x)=∑yexp∑i=1nwifi(x,y)
其中,
Zw(x)是规范化因子,fi是特征函数,wi是特征的权重。
最大熵模型的学习一般采用极大似然估计或者正则化的极大似然估计,通过将其转化为无约束最优化问题,利用改进的迭代尺度法即IIS、梯度下降法或者拟牛顿法(DFP、BFGS)来求解该最优化问题。
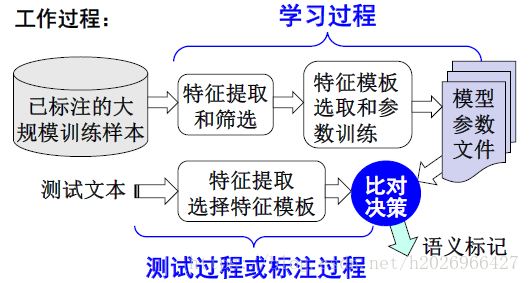
2,基于最大熵模型的词义消歧方法
(1)确定特征函数

(2)上下文信息特征的选择
三种类型:
- 特征的类型:词型特征、词性特征、词形+词性特征。
- 上下文窗口的大小
- 是否考虑上下文字词的位置信息

(3)工作过程与实验实例