引言
在本系列中,我们将构建一个机器学习模型,使用PyTorch和TorchText为输入序列中的每个元素生成输出。具体来说,我们将输入一个文本序列,模型将为输入文本中的每个标记输出一个词性(PoS)标记。这也可以用于命名实体识别(NER),其中每个标记的输出将是实体的类型(如果有的话)。
在本笔记中,我们将实现一个多层双向LSTM (BiLSTM),以使用Universal Dependencies English Web Treebank (UDPOS)数据集预测PoS标记。
准备数据
首先,让我们导入必要的Python模块。
import torch
import torch.nn as nn
import torch.optim as optim
from torchtext import data
from torchtext import datasets
import spacy
import numpy as np
import time
import random
接下来,我们将为可重复性设置随机种子。
SEED = 1234
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
Field是TorchText的关键部分之一。Field用来处理您的数据集。
我们的TEXT 字段处理需要标记的文本。这里我们所做的是设置lower = True,这将所有文本都小写。
接下来,我们将为标记定义Fields 。这个数据集实际上有两组不同的标签,universal dependency (UD)标签和Penn Treebank (PTB)标签。我们将只在UD标签上训练我们的模型,但将加载PTB标签,以展示如何替代使用它们。
UD_TAGS处理UD标签应该如何处理。我们的TEXT vocabulary-我们将稍后构建-将有unknown 的标记在其中,即标记不在我们的vocabulary内。然而,我们不会有unknown 的标签,因为我们处理的是有限的可能标签集。TorchText字段初始化一个默认的unknown 标记,《unk》,我们通过设置unk_token = None来删除它。
PTB_TAGS的操作与UD_TAGS相同,但处理的是PTB标签。
TEXT = data.Field(lower = True)
UD_TAGS = data.Field(unk_token = None)
PTB_TAGS = data.Field(unk_token = None)
然后定义fields,它处理我们的fields 然后传递给数据集。
注意,顺序很重要,如果你只想加载PTB标签,你的字段将是:
fields = (("text", TEXT), (None, None), ("ptbtags", PTB_TAGS))
None告诉TorchText不要加载这些标签。
fields = (("text", TEXT), ("udtags", UD_TAGS), ("ptbtags", PTB_TAGS))
接下来,我们使用定义的字段加载UDPOS数据集。
train_data, valid_data, test_data = datasets.UDPOS.splits(fields)
我们可以通过检查它们的长度来检查数据集的每个部分中有多少示例。
print(f"Number of training examples: {len(train_data)}")
print(f"Number of validation examples: {len(valid_data)}")
print(f"Number of testing examples: {len(test_data)}")
Number of training examples: 12543 Number of validation examples: 2002
Number of testing examples: 2077
让我们打印一个例子:
print(vars(train_data.examples[0]))
{‘text’: [‘al’, ‘-’, ‘zaman’, ‘:’, ‘american’, ‘forces’, ‘killed’,
‘shaikh’, ‘abdullah’, ‘al’, ‘-’, ‘ani’, ‘,’, ‘the’, ‘preacher’, ‘at’,
‘the’, ‘mosque’, ‘in’, ‘the’, ‘town’, ‘of’, ‘qaim’, ‘,’, ‘near’,
‘the’, ‘syrian’, ‘border’, ‘.’], ‘udtags’: [‘PROPN’, ‘PUNCT’, ‘PROPN’,
‘PUNCT’, ‘ADJ’, ‘NOUN’, ‘VERB’, ‘PROPN’, ‘PROPN’, ‘PROPN’, ‘PUNCT’,
‘PROPN’, ‘PUNCT’, ‘DET’, ‘NOUN’, ‘ADP’, ‘DET’, ‘NOUN’, ‘ADP’, ‘DET’,
‘NOUN’, ‘ADP’, ‘PROPN’, ‘PUNCT’, ‘ADP’, ‘DET’, ‘ADJ’, ‘NOUN’,
‘PUNCT’], ‘ptbtags’: [‘NNP’, ‘HYPH’, ‘NNP’, ‘:’, ‘JJ’, ‘NNS’, ‘VBD’,
‘NNP’, ‘NNP’, ‘NNP’, ‘HYPH’, ‘NNP’, ‘,’, ‘DT’, ‘NN’, ‘IN’, ‘DT’, ‘NN’,
‘IN’, ‘DT’, ‘NN’, ‘IN’, ‘NNP’, ‘,’, ‘IN’, ‘DT’, ‘JJ’, ‘NN’, ‘.’]}
我们也可以分别查看文本和标签:
print(vars(train_data.examples[0])['text'])
[‘al’, ‘-’, ‘zaman’, ‘:’, ‘american’, ‘forces’, ‘killed’, ‘shaikh’,
‘abdullah’, ‘al’, ‘-’, ‘ani’, ‘,’, ‘the’, ‘preacher’, ‘at’, ‘the’,
‘mosque’, ‘in’, ‘the’, ‘town’, ‘of’, ‘qaim’, ‘,’, ‘near’, ‘the’,
‘syrian’, ‘border’, ‘.’]
print(vars(train_data.examples[0])['udtags'])
[‘PROPN’, ‘PUNCT’, ‘PROPN’, ‘PUNCT’, ‘ADJ’, ‘NOUN’, ‘VERB’, ‘PROPN’,
‘PROPN’, ‘PROPN’, ‘PUNCT’, ‘PROPN’, ‘PUNCT’, ‘DET’, ‘NOUN’, ‘ADP’,
‘DET’, ‘NOUN’, ‘ADP’, ‘DET’, ‘NOUN’, ‘ADP’, ‘PROPN’, ‘PUNCT’, ‘ADP’,
‘DET’, ‘ADJ’, ‘NOUN’, ‘PUNCT’]
print(vars(train_data.examples[0])['ptbtags'])
[‘NNP’, ‘HYPH’, ‘NNP’, ‘:’, ‘JJ’, ‘NNS’, ‘VBD’, ‘NNP’, ‘NNP’, ‘NNP’,
‘HYPH’, ‘NNP’, ‘,’, ‘DT’, ‘NN’, ‘IN’, ‘DT’, ‘NN’, ‘IN’, ‘DT’, ‘NN’,
‘IN’, ‘NNP’, ‘,’, ‘IN’, ‘DT’, ‘JJ’, ‘NN’, ‘.’]
接下来,我们将构建vocabulary—tokens 到integers的映射。
我们想要一些unknown 的标记在我们的数据集,以复制如何使用这个模型在现实生活中,我们设置min_freq=2这意味着只有两次标记出现在训练集将被添加到词汇,其余将取而代之的是《unk》标记。
我们还加载了预先训练过的GloVe标记嵌入。具体来说,就是用60亿个标记训练的100维嵌入。使用预先训练的嵌入通常会提高性能——尽管不可否认,本教程中使用的数据集太小,无法利用预先训练的嵌入。
unk_init用于初始化不在预先训练的嵌入词汇表中的标记嵌入。默认情况下,会将这些嵌入设置为0,但是最好不要将它们都初始化为相同的值,因此我们从正态/高斯分布初始化它们。
这些预先训练好的向量现在已经加载到我们的词汇表中,我们将在以后用这些值初始化我们的模型。
MIN_FREQ = 2
TEXT.build_vocab(train_data,
min_freq = MIN_FREQ,
vectors = "glove.6B.100d",
unk_init = torch.Tensor.normal_)
UD_TAGS.build_vocab(train_data)
PTB_TAGS.build_vocab(train_data)
我们可以通过获取标记和标签的长度来检查词汇表中有多少标记和标签:
print(f"Unique tokens in TEXT vocabulary: {len(TEXT.vocab)}")
print(f"Unique tokens in UD_TAG vocabulary: {len(UD_TAGS.vocab)}")
print(f"Unique tokens in PTB_TAG vocabulary: {len(PTB_TAGS.vocab)}")
Unique tokens in TEXT vocabulary: 8866
Unique tokens in UD_TAG vocabulary: 18
Unique tokens in PTB_TAG vocabulary: 51
探索词汇,我们可以检查我们的文本中最常见的标记:
print(TEXT.vocab.freqs.most_common(20))
[(‘the’, 9076), (’.’, 8640), (’,’, 7021), (‘to’, 5137), (‘and’, 5002),
(‘a’, 3782), (‘of’, 3622), (‘i’, 3379), (‘in’, 3112), (‘is’, 2239),
(‘you’, 2156), (‘that’, 2036), (‘it’, 1850), (‘for’, 1842), (’-’,
1426), (‘have’, 1359), (’"’, 1296), (‘on’, 1273), (‘was’, 1244),
(‘with’, 1216)]
我们可以看到这两个标签的词汇表:
print(UD_TAGS.vocab.itos)
[’《pad》’, ‘NOUN’, ‘PUNCT’, ‘VERB’, ‘PRON’, ‘ADP’, ‘DET’, ‘PROPN’,
‘ADJ’, ‘AUX’, ‘ADV’, ‘CCONJ’, ‘PART’, ‘NUM’, ‘SCONJ’, ‘X’, ‘INTJ’,
‘SYM’]
print(PTB_TAGS.vocab.itos)
[’《pad》’, ‘NN’, ‘IN’, ‘DT’, ‘NNP’, ‘PRP’, ‘JJ’, ‘RB’, ‘.’, ‘VB’,
‘NNS’, ‘,’, ‘CC’, ‘VBD’, ‘VBP’, ‘VBZ’, ‘CD’, ‘VBN’, ‘VBG’, ‘MD’, ‘TO’,
‘PRP ′ , ′ − R R B − ′ , ′ − L R B − ′ , ′ W D T ′ , ′ W R B ′ , ′ : ′ , ′ ‘ ‘ ′ , " ′ ′ " , ′ W P ′ , ′ R P ′ , ′ U H ′ , ′ P O S ′ , ′ H Y P H ′ , ′ J J R ′ , ′ N N P S ′ , ′ J J S ′ , ′ E X ′ , ′ N F P ′ , ′ G W ′ , ′ A D D ′ , ′ R B R ′ , ′ ', '-RRB-', '-LRB-', 'WDT', 'WRB', ':', '``', "''", 'WP', 'RP', 'UH', 'POS', 'HYPH', 'JJR', 'NNPS', 'JJS', 'EX', 'NFP', 'GW', 'ADD', 'RBR', ' ′,′−RRB−′,′−LRB−′,′WDT′,′WRB′,′:′,′‘‘′,"′′",′WP′,′RP′,′UH′,′POS′,′HYPH′,′JJR′,′NNPS′,′JJS′,′EX′,′NFP′,′GW′,′ADD′,′RBR′,′’, ‘PDT’, ‘RBS’, ‘SYM’, ‘LS’, ‘FW’, ‘AFX’, ‘WP$’, ‘XX’]
我们也可以看到每个标签在我们的词汇表中有多少:
print(UD_TAGS.vocab.freqs.most_common())
[(‘NOUN’, 34781), (‘PUNCT’, 23679), (‘VERB’, 23081), (‘PRON’, 18577),
(‘ADP’, 17638), (‘DET’, 16285), (‘PROPN’, 12946), (‘ADJ’, 12477),
(‘AUX’, 12343), (‘ADV’, 10548), (‘CCONJ’, 6707), (‘PART’, 5567),
(‘NUM’, 3999), (‘SCONJ’, 3843), (‘X’, 847), (‘INTJ’, 688), (‘SYM’,
599)]
print(PTB_TAGS.vocab.freqs.most_common())
[(‘NN’, 26915), (‘IN’, 20724), (‘DT’, 16817), (‘NNP’, 12449), (‘PRP’,
12193), (‘JJ’, 11591), (‘RB’, 10831), (’.’, 10317), (‘VB’, 9476),
(‘NNS’, 8438), (’,’, 8062), (‘CC’, 6706), (‘VBD’, 5402), (‘VBP’,
5374), (‘VBZ’, 4578), (‘CD’, 3998), (‘VBN’, 3967), (‘VBG’, 3330),
(‘MD’, 3294), (‘TO’, 3286), (‘PRP ′ , 3068 ) , ( ′ − R R B − ′ , 1008 ) , ( ′ − L R B − ′ , 973 ) , ( ′ W D T ′ , 948 ) , ( ′ W R B ′ , 869 ) , ( ′ : ′ , 866 ) , ( ′ ‘ ‘ ′ , 813 ) , ( " ′ ′ " , 785 ) , ( ′ W P ′ , 760 ) , ( ′ R P ′ , 755 ) , ( ′ U H ′ , 689 ) , ( ′ P O S ′ , 684 ) , ( ′ H Y P H ′ , 664 ) , ( ′ J J R ′ , 503 ) , ( ′ N N P S ′ , 498 ) , ( ′ J J S ′ , 383 ) , ( ′ E X ′ , 359 ) , ( ′ N F P ′ , 338 ) , ( ′ G W ′ , 294 ) , ( ′ A D D ′ , 292 ) , ( ′ R B R ′ , 276 ) , ( ′ ', 3068), ('-RRB-', 1008), ('-LRB-', 973), ('WDT', 948), ('WRB', 869), (':', 866), ('``', 813), ("''", 785), ('WP', 760), ('RP', 755), ('UH', 689), ('POS', 684), ('HYPH', 664), ('JJR', 503), ('NNPS', 498), ('JJS', 383), ('EX', 359), ('NFP', 338), ('GW', 294), ('ADD', 292), ('RBR', 276), (' ′,3068),(′−RRB−′,1008),(′−LRB−′,973),(′WDT′,948),(′WRB′,869),(′:′,866),(′‘‘′,813),("′′",785),(′WP′,760),(′RP′,755),(′UH′,689),(′POS′,684),(′HYPH′,664),(′JJR′,503),(′NNPS′,498),(′JJS′,383),(′EX′,359),(′NFP′,338),(′GW′,294),(′ADD′,292),(′RBR′,276),(′’, 258), (‘PDT’,
175), (‘RBS’, 169), (‘SYM’, 156), (‘LS’, 117), (‘FW’, 93), (‘AFX’,
48), (‘WP$’, 15), (‘XX’, 1)]
我们也可以看到每个标签在训练集中有多常见:
def tag_percentage(tag_counts):
total_count = sum([count for tag, count in tag_counts])
tag_counts_percentages = [(tag, count, count/total_count) for tag, count in tag_counts]
return tag_counts_percentages
print("Tag\t\tCount\t\tPercentage\n")
for tag, count, percent in tag_percentage(UD_TAGS.vocab.freqs.most_common()):
print(f"{tag}\t\t{count}\t\t{percent*100:4.1f}%")
Tag Count Percentage
NOUN 34781 17.0%
PUNCT 23679 11.6%
VERB 23081 11.3%
PRON 18577 9.1%
ADP 17638 8.6%
DET 16285 8.0%
PROPN 12946 6.3%
ADJ 12477 6.1%
AUX 12343 6.0%
ADV 10548 5.2%
CCONJ 6707 3.3%
PART 5567 2.7%
NUM 3999 2.0%
SCONJ 3843 1.9%
X 847 0.4%
INTJ 688 0.3%
SYM 599 0.3%
print("Tag\t\tCount\t\tPercentage\n")
for tag, count, percent in tag_percentage(PTB_TAGS.vocab.freqs.most_common()):
print(f"{tag}\t\t{count}\t\t{percent*100:4.1f}%")
Tag Count Percentage
NN 26915 13.2%
IN 20724 10.1%
DT 16817 8.2%
NNP 12449 6.1%
PRP 12193 6.0%
JJ 11591 5.7%
RB 10831 5.3%
. 10317 5.0%
VB 9476 4.6%
NNS 8438 4.1%
, 8062 3.9%
CC 6706 3.3%
VBD 5402 2.6%
VBP 5374 2.6%
VBZ 4578 2.2%
CD 3998 2.0%
VBN 3967 1.9%
VBG 3330 1.6%
MD 3294 1.6%
TO 3286 1.6%
PRP$ 3068 1.5%
-RRB- 1008 0.5%
-LRB- 973 0.5%
WDT 948 0.5%
WRB 869 0.4%
: 866 0.4%
`` 813 0.4%
'' 785 0.4%
WP 760 0.4%
RP 755 0.4%
UH 689 0.3%
POS 684 0.3%
HYPH 664 0.3%
JJR 503 0.2%
NNPS 498 0.2%
JJS 383 0.2%
EX 359 0.2%
NFP 338 0.2%
GW 294 0.1%
ADD 292 0.1%
RBR 276 0.1%
$ 258 0.1%
PDT 175 0.1%
RBS 169 0.1%
SYM 156 0.1%
LS 117 0.1%
FW 93 0.0%
AFX 48 0.0%
WP$ 15 0.0%
XX 1 0.0%
数据准备的最后一部分是处理迭代器。
这将被迭代以返回要处理的数据batchs。在这里,我们设置了batch大小和device——用于在GPU上放置批量tensors(如果我们有GPU的话)。
BATCH_SIZE = 128
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_iterator, valid_iterator, test_iterator = data.BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size = BATCH_SIZE,
device = device)
构建模型
接下来,我们定义我们的模型——一个多层双向LSTM。下图显示了模型的简化版本,其中只有一个LSTM层,为了清晰起见,省略了LSTM的单元状态。

模型接受标记序列, X = { x 1 , x 2 , … , x T } X = \{x_1, x_2,…,x_T\} X={
x1,x2,…,xT},通过嵌入层 e e e,获得标记嵌入,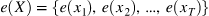
这些嵌入是由前向和后向LSTMs处理的——每时间步一次。正向LSTM从左到右处理序列,反向LSTM从右到左处理序列,即正向LSTM的第一个输入是 x 1 x_1 x1,反向LSTM的第一个输入是 x T x_T xT。
LSTMs还接受来自前一个时间步的隐藏状态 h h h和 c c c
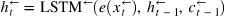
在处理完整个序列之后,hidden状态和cell状态将被传递到LSTM的下一层。
每个方向和层的初始隐藏状态和细胞状态 h 0 h_0 h0和 c 0 c_0 c0被初始化为一个全是0的张量。
然后我们将LSTM的最后一层的前向和后向隐藏状态连接起来, H = { h 1 , h 2 , … h T } H = \{h_1, h_2,…h_T\} H={ h1,h2,…hT},其中 h 1 = [ h 1 r i g h t t a r r o w ; h T ← ] h_1 = [h^{\ righttarrow}_1;h^{\leftarrow}_T] h1=[h1 righttarrow;hT←], h 2 = [ h 2 r i g h t t a r r o w ; h T − 1 ← ] h_2 = [h^{\ righttarrow}_2;h^{\leftarrow}_{T-1}] h2=[h2 righttarrow;hT−1←],等等,并通过一个线性层 f f f,用于预测哪个标签应用到该标记, y ^ T = f ( h T ) \hat{y} _T = f(h_T) y^T=f(hT)。
当训练模型时,我们将比较我们预测的标签 Y ^ \hat{Y} Y^与实际的标签 Y Y Y,以计算损失,梯度w.r.t.该损失,然后更新我们的参数。
我们实现了上面在BiLSTMPOSTagger类中详细描述的模型。
nn.Embedding是一个嵌入层,输入维度应该是输入(文本)词汇表的大小。我们告诉它填充标记的索引是什么,这样它就不会更新填充标记的内嵌条目。
nn.LSTM即LSTM。我们应用dropout作为layers间的正则化,如果我们使用多个layers的话。
nn.Linear定义使用LSTM输出进行预测的线性层。如果我们使用的是双向LSTM,我们将输入的大小加倍。输出尺寸应该是标签词汇表的大小。
我们还用nn.Dropout定义了一个dropout 层。我们使用forward 方法将Dropout应用于LSTM的嵌入和最后一层的输出。
class BiLSTMPOSTagger(nn.Module):
def __init__(self,
input_dim,
embedding_dim,
hidden_dim,
output_dim,
n_layers,
bidirectional,
dropout,
pad_idx):
super().__init__()
self.embedding = nn.Embedding(input_dim, embedding_dim, padding_idx = pad_idx)
self.lstm = nn.LSTM(embedding_dim,
hidden_dim,
num_layers = n_layers,
bidirectional = bidirectional,
dropout = dropout if n_layers > 1 else 0)
self.fc = nn.Linear(hidden_dim * 2 if bidirectional else hidden_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, text):
#text = [sent len, batch size]
#pass text through embedding layer
embedded = self.dropout(self.embedding(text))
#embedded = [sent len, batch size, emb dim]
#pass embeddings into LSTM
outputs, (hidden, cell) = self.lstm(embedded)
#outputs holds the backward and forward hidden states in the final layer
#hidden and cell are the backward and forward hidden and cell states at the final time-step
#output = [sent len, batch size, hid dim * n directions]
#hidden/cell = [n layers * n directions, batch size, hid dim]
#we use our outputs to make a prediction of what the tag should be
predictions = self.fc(self.dropout(outputs))
#predictions = [sent len, batch size, output dim]
return predictions
训练模型
接下来,我们实例化模型。我们需要确保嵌入尺寸与之前加载的Glove嵌入尺寸相匹配。
其余的超参数已经被选择为合理的默认值,尽管可能会有一个组合在这个模型和数据集上表现得更好。
输入和输出维度直接取自各自词汇表的长度。填充索引是使用词汇表和文本字段获得的。
INPUT_DIM = len(TEXT.vocab)
EMBEDDING_DIM = 100
HIDDEN_DIM = 128
OUTPUT_DIM = len(UD_TAGS.vocab)
N_LAYERS = 2
BIDIRECTIONAL = True
DROPOUT = 0.25
PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token]
model = BiLSTMPOSTagger(INPUT_DIM,
EMBEDDING_DIM,
HIDDEN_DIM,
OUTPUT_DIM,
N_LAYERS,
BIDIRECTIONAL,
DROPOUT,
PAD_IDX)
我们从一个简单的正态分布初始化权值。同样,这个模型和数据集可能有更好的初始化方案。
def init_weights(m):
for name, param in m.named_parameters():
nn.init.normal_(param.data, mean = 0, std = 0.1)
model.apply(init_weights)
BiLSTMPOSTagger(
(embedding): Embedding(8866, 100, padding_idx=1)
(lstm): LSTM(100, 128, num_layers=2, dropout=0.25, bidirectional=True)
(fc): Linear(in_features=256, out_features=18, bias=True)
(dropout): Dropout(p=0.25, inplace=False)
)
接下来,一个小函数告诉我们模型中有多少参数。用于比较不同的模型。
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters')
The model has 1,522,010 trainable parameters
现在,我们将用之前加载的预先训练好的嵌入值初始化模型的嵌入层。
这是通过从vocab’s .vectors属性中获取它们,然后执行.copy来覆盖嵌入层的当前权重来实现的。
pretrained_embeddings = TEXT.vocab.vectors
print(pretrained_embeddings.shape)
torch.Size([8866, 100])
model.embedding.weight.data.copy_(pretrained_embeddings)
tensor([[-0.1117, -0.4966, 0.1631, ..., 1.2647, -0.2753, -0.1325],
[-0.8555, -0.7208, 1.3755, ..., 0.0825, -1.1314, 0.3997],
[-0.0382, -0.2449, 0.7281, ..., -0.1459, 0.8278, 0.2706],
...,
[ 0.9261, 2.3049, 0.5502, ..., -0.3492, -0.5298, -0.1577],
[-0.5972, 0.0471, -0.2406, ..., -0.9446, -0.1126, -0.2260],
[-0.4809, 2.5629, 0.9530, ..., 0.5278, -0.4588, 0.7294]])
通常将pad标记的嵌入初始化为所有零。再加上在模型的嵌入层中设置padding_idx,这意味着当输入一个填充标记时,嵌入应该总是输出一个满是0的张量。
model.embedding.weight.data[PAD_IDX] = torch.zeros(EMBEDDING_DIM)
print(model.embedding.weight.data)
tensor([[-0.1117, -0.4966, 0.1631, ..., 1.2647, -0.2753, -0.1325],
[ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[-0.0382, -0.2449, 0.7281, ..., -0.1459, 0.8278, 0.2706],
...,
[ 0.9261, 2.3049, 0.5502, ..., -0.3492, -0.5298, -0.1577],
[-0.5972, 0.0471, -0.2406, ..., -0.9446, -0.1126, -0.2260],
[-0.4809, 2.5629, 0.9530, ..., 0.5278, -0.4588, 0.7294]])
然后定义优化器,用于更新参数w.r.t.它们的梯度。我们使用Adam 的默认学习速率。
optimizer = optim.Adam(model.parameters())
接下来,我们定义我们的损失函数,交叉熵损失。
即使在我们的标签词汇表中没有《unk》标记,我们仍然有《pad》标记。这是因为批处理中的所有句子都需要具有相同的大小。然而,当目标是《pad》标记时,我们不想计算损失,因为我们没有训练我们的模型识别填充标记。
我们通过将loss函数中的ignore_index设置为标签词汇表中填充标记的索引来处理这个问题。
TAG_PAD_IDX = UD_TAGS.vocab.stoi[UD_TAGS.pad_token]
criterion = nn.CrossEntropyLoss(ignore_index = TAG_PAD_IDX)
然后我们把我们的模型和损失函数放在我们的GPU上,如果我们有GPU的话。
model = model.to(device)
criterion = criterion.to(device)
我们将使用预测标签和实际标签之间的损失值来训练网络,但理想情况下,我们希望用一种更可解释的方式来查看我们的模型表现如何——准确率。
问题是,我们不想计算《pad》标记的精度,因为我们对预测它们不感兴趣。
下面的函数仅计算非填充标记的精度。non_pad_elements是一个张量,包含输入批处理中非填充标记的索引。然后,我们将这些元素的预测与标签进行比较,以得到有多少预测是正确的。然后除以非衬垫元素的数量,以获得批处理的精度值。
def categorical_accuracy(preds, y, tag_pad_idx):
"""
Returns accuracy per batch, i.e. if you get 8/10 right, this returns 0.8, NOT 8
"""
max_preds = preds.argmax(dim = 1, keepdim = True) # get the index of the max probability
non_pad_elements = (y != tag_pad_idx).nonzero()
correct = max_preds[non_pad_elements].squeeze(1).eq(y[non_pad_elements])
return correct.sum() / torch.FloatTensor([y[non_pad_elements].shape[0]])
接下来是处理训练和评估模型的函数。
def train(model, iterator, optimizer, criterion, tag_pad_idx):
epoch_loss = 0
epoch_acc = 0
model.train()
for batch in iterator:
text = batch.text
tags = batch.udtags
optimizer.zero_grad()
#text = [sent len, batch size]
predictions = model(text)
#predictions = [sent len, batch size, output dim]
#tags = [sent len, batch size]
predictions = predictions.view(-1, predictions.shape[-1])
tags = tags.view(-1)
#predictions = [sent len * batch size, output dim]
#tags = [sent len * batch size]
loss = criterion(predictions, tags)
acc = categorical_accuracy(predictions, tags, tag_pad_idx)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
def evaluate(model, iterator, criterion, tag_pad_idx):
epoch_loss = 0
epoch_acc = 0
model.eval()
with torch.no_grad():
for batch in iterator:
text = batch.text
tags = batch.udtags
predictions = model(text)
predictions = predictions.view(-1, predictions.shape[-1])
tags = tags.view(-1)
loss = criterion(predictions, tags)
acc = categorical_accuracy(predictions, tags, tag_pad_idx)
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
接下来,我们有一个小函数,告诉我们一个epoch需要多长时间。
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
最后,我们训练我们的模型!
N_EPOCHS = 10
best_valid_loss = float('inf')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss, train_acc = train(model, train_iterator, optimizer, criterion, TAG_PAD_IDX)
valid_loss, valid_acc = evaluate(model, valid_iterator, criterion, TAG_PAD_IDX)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'tut1-model.pt')
print(f'Epoch: {epoch+1:02} | Epoch Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train Acc: {train_acc*100:.2f}%')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. Acc: {valid_acc*100:.2f}%')
Epoch: 01 | Epoch Time: 0m 2s
Train Loss: 1.328 | Train Acc: 58.55%
Val. Loss: 0.672 | Val. Acc: 78.66%
Epoch: 02 | Epoch Time: 0m 2s
Train Loss: 0.473 | Train Acc: 85.14%
Val. Loss: 0.500 | Val. Acc: 83.76%
Epoch: 03 | Epoch Time: 0m 2s
Train Loss: 0.344 | Train Acc: 89.11%
Val. Loss: 0.437 | Val. Acc: 85.39%
Epoch: 04 | Epoch Time: 0m 2s
Train Loss: 0.284 | Train Acc: 91.03%
Val. Loss: 0.405 | Val. Acc: 86.31%
Epoch: 05 | Epoch Time: 0m 1s
Train Loss: 0.248 | Train Acc: 92.18%
Val. Loss: 0.390 | Val. Acc: 86.75%
Epoch: 06 | Epoch Time: 0m 2s
Train Loss: 0.222 | Train Acc: 92.90%
Val. Loss: 0.376 | Val. Acc: 87.10%
Epoch: 07 | Epoch Time: 0m 2s
Train Loss: 0.203 | Train Acc: 93.48%
Val. Loss: 0.366 | Val. Acc: 87.35%
Epoch: 08 | Epoch Time: 0m 2s
Train Loss: 0.187 | Train Acc: 93.99%
Val. Loss: 0.356 | Val. Acc: 88.26%
Epoch: 09 | Epoch Time: 0m 2s
Train Loss: 0.175 | Train Acc: 94.37%
Val. Loss: 0.347 | Val. Acc: 88.39%
Epoch: 10 | Epoch Time: 0m 2s
Train Loss: 0.165 | Train Acc: 94.64%
Val. Loss: 0.347 | Val. Acc: 88.79%
然后,我们加载“最佳”参数,并在测试集中评估性能。
model.load_state_dict(torch.load('tut1-model.pt'))
test_loss, test_acc = evaluate(model, test_iterator, criterion, TAG_PAD_IDX)
print(f'Test Loss: {test_loss:.3f} | Test Acc: {test_acc*100:.2f}%')
Test Loss: 0.360 | Test Acc: 88.32%
推理
88%的准确率看起来相当不错,但让我们看看我们的模型标记一些实际的句子。
def tag_sentence(model, device, sentence, text_field, tag_field):
model.eval()
if isinstance(sentence, str):
nlp = spacy.load('en')
tokens = [token.text for token in nlp(sentence)]
else:
tokens = [token for token in sentence]
if text_field.lower:
tokens = [t.lower() for t in tokens]
numericalized_tokens = [text_field.vocab.stoi[t] for t in tokens]
unk_idx = text_field.vocab.stoi[text_field.unk_token]
unks = [t for t, n in zip(tokens, numericalized_tokens) if n == unk_idx]
token_tensor = torch.LongTensor(numericalized_tokens)
token_tensor = token_tensor.unsqueeze(-1).to(device)
predictions = model(token_tensor)
top_predictions = predictions.argmax(-1)
predicted_tags = [tag_field.vocab.itos[t.item()] for t in top_predictions]
return tokens, predicted_tags, unks
我们将从训练集中获得一个已经标记化的示例,并测试我们的模型的性能。
example_index = 1
sentence = vars(train_data.examples[example_index])['text']
actual_tags = vars(train_data.examples[example_index])['udtags']
print(sentence)
[’[’, ‘this’, ‘killing’, ‘of’, ‘a’, ‘respected’, ‘cleric’, ‘will’,
‘be’, ‘causing’, ‘us’, ‘trouble’, ‘for’, ‘years’, ‘to’, ‘come’, ‘.’,
‘]’]
tokens, pred_tags, unks = tag_sentence(model,
device,
sentence,
TEXT,
UD_TAGS)
print(unks)
['respected', 'cleric']
然后我们可以检查它的性能。令人惊讶的是,它正确地得到了每个标记,包括两个未知的标记!
print("Pred. Tag\tActual Tag\tCorrect?\tToken\n")
for token, pred_tag, actual_tag in zip(tokens, pred_tags, actual_tags):
correct = '✔' if pred_tag == actual_tag else '✘'
print(f"{pred_tag}\t\t{actual_tag}\t\t{correct}\t\t{token}")
Pred. Tag Actual Tag Correct? Token
PUNCT PUNCT ✔ [
DET DET ✔ this
NOUN NOUN ✔ killing
ADP ADP ✔ of
DET DET ✔ a
ADJ ADJ ✔ respected
NOUN NOUN ✔ cleric
AUX AUX ✔ will
AUX AUX ✔ be
VERB VERB ✔ causing
PRON PRON ✔ us
NOUN NOUN ✔ trouble
ADP ADP ✔ for
NOUN NOUN ✔ years
PART PART ✔ to
VERB VERB ✔ come
PUNCT PUNCT ✔ .
PUNCT PUNCT ✔ ]
就性能而言,BiLSTM并不是最先进的模型,但是对于PoS任务来说,它是一个强大的基线,并且是您可以拥有的一个很好的工具。
完整代码
import torch
import torch.nn as nn
import torch.optim as optim
from torchtext import data
from torchtext import datasets
import spacy
import numpy as np
import time
import random
SEED = 1234
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
TEXT = data.Field(lower=True)
UD_TAGS = data.Field(unk_token=None)
PTB_TAGS = data.Field(unk_token=None)
fields = (("text", TEXT), ("udtags", UD_TAGS), ("ptbtags", PTB_TAGS))
train_data, valid_data, test_data = datasets.UDPOS.splits(fields)
print(f"Number of training examples: {len(train_data)}")
print(f"Number of validation examples: {len(valid_data)}")
print(f"Number of testing examples: {len(test_data)}")
print(vars(train_data.examples[0]))
print(vars(train_data.examples[0])['text'])
print(vars(train_data.examples[0])['udtags'])
print(vars(train_data.examples[0])['ptbtags'])
MIN_FREQ = 2
TEXT.build_vocab(train_data,
min_freq = MIN_FREQ,
vectors='glove.6B.100d',
unk_init=torch.Tensor.normal_)
UD_TAGS.build_vocab(train_data)
PTB_TAGS.build_vocab(train_data)
print(f"Unique tokens in TEXT vocabulary: {len(TEXT.vocab)}")
print(f"Unique tokens in UD_TAG vocabulary: {len(UD_TAGS.vocab)}")
print(f"Unique tokens in PTB_TAG vocabulary: {len(PTB_TAGS.vocab)}")
print(TEXT.vocab.freqs.most_common(20))
print('hello')
print(UD_TAGS.vocab.itos)
print(PTB_TAGS.vocab.itos)
def tag_percentage(tag_counts):
total_count = sum([count for tag, count in tag_counts])
tag_counts_percentages = [(tag, count, count / total_count) for tag, count in tag_counts]
return tag_counts_percentages
print("Tag\t\tCount\t\tPercentage\n")
for tag, count, percent in tag_percentage(UD_TAGS.vocab.freqs.most_common()):
print(f"{tag}\t\t{count}\t\t{percent*100:4.1f}%")
print("Tag\t\tCount\t\tPercentage\n")
for tag, count, percent in tag_percentage(PTB_TAGS.vocab.freqs.most_common()):
print(f"{tag}\t\t{count}\t\t{percent*100:4.1f}%")
BATCH_SIZE = 128
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_iterator, valid_iterator, test_iterator = data.BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size=BATCH_SIZE,
device=device
)
class BiLSTMPOSTagger(nn.Module):
def __init__(self,
input_dim,
embedding_dim,
hidden_dim,
output_dim,
n_layers,
bidirectional,
dropout,
pad_idx):
super(BiLSTMPOSTagger, self).__init__()
self.embedding = nn.Embedding(input_dim, embedding_dim, padding_idx=pad_idx)
self.lstm = nn.LSTM(embedding_dim,
hidden_dim,
num_layers=n_layers,
bidirectional=bidirectional,
dropout = dropout if n_layers > 1 else 0
)
self.fc = nn.Linear(hidden_dim * 2 if bidirectional else hidden_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, text):
# text = [sent_len, batch_size]
# pass text through embedding layer
embedded = self.dropout(self.embedding(text))
# embedded = [sent_len, batch_size, emb_dim]
# pass embeddings into LSTM
outputs, (hidden, cell) = self.lstm(embedded)
# outputs holds the backward and forward hidden states in the final layer
# hidden and cell are the backward and forward hidden and cell states at the final time-step
# we use our outputs to make a prediction of what the tag should be
predictions = self.fc(self.dropout(outputs))
# predictions = [sent_len, batch_size, output_dim]
return predictions
INPUT_DIM = len(TEXT.vocab)
EMBEDDING_DIM = 100
HIDDEN_DIM = 120
OUTPUT_DIM = len(UD_TAGS.vocab)
N_LAYERS = 2
BIDIRECTIONAL = True
DROPOUT = 0.25
PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token]
model = BiLSTMPOSTagger(INPUT_DIM,
EMBEDDING_DIM,
HIDDEN_DIM,
OUTPUT_DIM,
N_LAYERS,
BIDIRECTIONAL,
DROPOUT,
PAD_IDX)
def init_weights(m):
for name, param in m.named_parameters():
nn.init.normal_(param.data, mean=0, std=0.1)
model.apply(init_weights)
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters')
pretrained_embeddings = TEXT.vocab.vectors
print(pretrained_embeddings.shape)
model.embedding.weight.data.copy_(pretrained_embeddings)
model.embedding.weight.data[PAD_IDX] = torch.zeros(EMBEDDING_DIM)
print(model.embedding.weight.data)
optimizer = optim.Adam(model.parameters())
TAG_PAD_IDX = UD_TAGS.vocab.stoi[UD_TAGS.pad_token]
criterion = nn.CrossEntropyLoss(ignore_index=TAG_PAD_IDX)
model = model.to(device)
criterion = criterion.to(device)
def categorical_accuracy(preds, y, tag_pad_idx):
"""
Returns accuracy per batch, i.e. if you get 8/10 right, this returns 0.8, NOT 8
"""
max_preds = preds.argmax(dim = 1, keepdim = True) # get the index of the max probability
non_pad_elements = (y != tag_pad_idx).nonzero()
correct = max_preds[non_pad_elements].squeeze(1).eq(y[non_pad_elements])
return correct.sum() / torch.FloatTensor([y[non_pad_elements].shape[0]])
def train(model, iterator, optimizer, criterion, tag_pad_idx):
epoch_loss = 0
epoch_acc = 0
model.train()
for batch in iterator:
text = batch.text
tags = batch.udtags
# text = [sent_len, batch_size]
optimizer.zero_grad()
predictions = model(text)
# predictions = [sent_len, batch_size, output_dim]
# tags = [sent_len, batch_size]
predictions = predictions.view(-1, predictions.shape[-1])
tags = tags.view(-1)
# predictions = [sent_len * batch_size, output_dim]
# tags = [sent_len * batch_size]
loss = criterion(predictions, tags)
acc = categorical_accuracy(predictions, tags, tag_pad_idx)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
def evaluate(model, iterator, criterion, tag_pad_idx):
epoch_loss = 0
epoch_acc = 0
model.eval()
with torch.no_grad():
for batch in iterator:
text = batch.text
tags = batch.udtags
predictions = model(text)
predictions = predictions.view(-1, predictions.shape[-1])
tags = tags.view(-1)
loss = criterion(predictions, tags)
acc = categorical_accuracy(predictions, tags, tag_pad_idx)
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
N_EPOCHS = 10
best_valid_loss = float('inf')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss, train_acc = train(model, train_iterator, optimizer, criterion, TAG_PAD_IDX)
valid_loss, valid_acc = evaluate(model, valid_iterator, criterion, TAG_PAD_IDX)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'tut1-model.pt')
print(f'Epoch: {epoch + 1:02} | Epoch Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train Acc: {train_acc * 100:.2f}%')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. Acc: {valid_acc * 100:.2f}%')
model.load_state_dict(torch.load('tut1-model.pt'))
test_loss, test_acc = evaluate(model, test_iterator, criterion, TAG_PAD_IDX)
print(f'Test Loss: {test_loss:.3f} | Test Acc: {test_acc*100:.2f}%')
def tag_sentence(model, device, sentence, text_field, tag_field):
model.eval()
if isinstance(sentence, str):
nlp = spacy.load('en_core_web_sm')
tokens = [token.text for token in nlp(sentence)]
else:
tokens = [token for token in sentence]
if text_field.lower:
tokens = [t.lower() for t in tokens]
numericalized_tokens = [text_field.vocab.stoi[t] for t in tokens]
unk_idx = text_field.vocab.stoi[text_field.unk_token]
unks = [t for t, n in zip(tokens, numericalized_tokens) if n == unk_idx]
token_tensor = torch.LongTensor(numericalized_tokens)
token_tensor = token_tensor.unsqueeze(-1).to(device)
predictions = model(token_tensor)
top_predictions = predictions.argmax(-1)
predicted_tags = [tag_field.vocab.itos[t.item()] for t in top_predictions]
return tokens, predicted_tags, unks
example_index = 1
sentence = vars(train_data.examples[example_index])['text']
actual_tags = vars(train_data.examples[example_index])['udtags']
print(sentence)
tokens, pred_tags, unks = tag_sentence(model,
device,
sentence,
TEXT,
UD_TAGS)
print(unks)
print("Pred. Tag\tActual Tag\tCorrect?\tToken\n")
for token, pred_tag, actual_tag in zip(tokens, pred_tags, actual_tags):
correct = '✔' if pred_tag == actual_tag else '✘'
print(f"{pred_tag}\t\t{actual_tag}\t\t{correct}\t\t{token}")
sentence = 'The Queen will deliver a speech about the conflict in North Korea at 1pm tomorrow.'
tokens, tags, unks = tag_sentence(model,
device,
sentence,
TEXT,
UD_TAGS)
print(unks)
print("Pred. Tag\tToken\n")
for token, tag in zip(tokens, tags):
print(f"{tag}\t\t{token}")