Em primeiro lugar, partindo do princípio linear (rede neural)
Os exemplos que se seguem visam ilustrar algoritmo de rede neural para resolver estes problemas são dependentes do estudo do classificador não linear complexo.
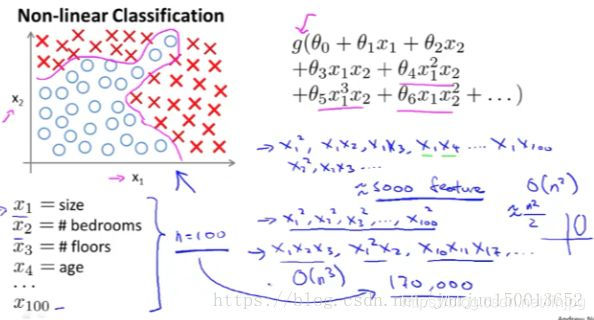
Considere o problema de classificação de aprendizagem supervisionada, temos o conjunto de treinamento correspondente, se o uso de algoritmo de regressão logística para resolver este problema. Primeiro necessidade de construir uma função de regressão logística contém muitos termo não-linear.
Na verdade, quando o número de termos polinomiais o suficiente, então você pode ser capaz de obter uma linha divisória separado entre amostras positivas e negativas quando apenas dois como x1, x2 este método pode realmente obter um resultado bom, porque você pode a combinação de x1 e x2 estão todos incluídos no polinômio, mas para muitos problemas de aprendizado de máquina sofisticados, muitas vezes envolvendo mais de dois mandatos.
Os preços das casas previu problema: Suponha agora ser processado é a probabilidade de que uma casa nos próximos seis meses, pode ser vendido, o que é um problema de classificação. Para casas diferentes existem centenas de características possíveis, para tais problemas, se o termo quadrático para incluir tudo, no caso de n = 100, em última análise, também o quadrática 5000, com o número de funcionalidades n aumentar. O número de itens secundários está prestes a aumentar a ordem n ^ 2, então você quiser incluir todo o termo quadrático é muito difícil, por isso pode não ser uma boa idéia.

E porque muitas entradas, o resultado final é provável que seja muito apto. Além disso, quando se lida com tantos, há também o problema de funcionamento excessiva. Claro, você também pode tentar incluir apenas um subconjunto destes top termo quadrático, mas devido a ignorar os muitos itens relacionados, em lidar com canto superior esquerdo semelhante dos dados, é impossível obter os resultados desejados. 5000 quadrática termo parece ter um monte, mas agora assumindo que incluiu três itens ou termos de terceira ordem, cerca de 17.000 termo cúbico, esta não é uma boa prática.
Por exemplo: em um problema em visão computacional. Suponha que você queira usar um algoritmo de aprendizado de máquina para treinar um classificador, ele detecta uma imagem para determinar se a imagem é um carro, nós removemos uma pequena parte da imagem, que é amplificado. Por exemplo, parte da figura na caixa vermelha, quando o olho humano para ver o carro, o computador realmente ver é que uma matriz de dados, que representa os valores de intensidade de pixel, deixe-nos saber valor de brilho de cada pixel da imagem . Portanto, para a visão de computador é a pergunta é: para nos dizer estes valores representam uma maçaneta da porta do carro de acordo com a luminosidade da matriz de pixel.

Especificamente, quando o algoritmo de aprendizagem constrói um máquinas identificador de veículo, queremos um conjunto de amostras com um rótulo. Algumas dessas amostras são todos os tipos de carros, a outra porção da amostra é outra coisa, esta amostra defina a entrada para o algoritmo de aprendizado para treinar um classificador. Após o treinamento for concluído, entramos numa nova imagem, para que o classificador determina que Idealmente, o classificador pode reconhecer que este é um carro "que é essa coisa?":
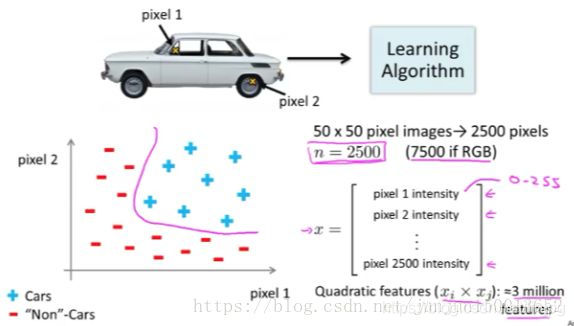
A fim de compreender a necessidade de introduzir classificadores não lineares, nós escolher algumas das imagens e algumas imagens do carro não-automotivos do algoritmo de aprendizagem amostra de treinamento, nós escolher um conjunto de pixels Pixel1 e pixel2 a partir do qual cada parte da imagem.
Chamar mais novas amostras no sistema de coordenadas, usando o '' + "indica que a imagem do carro por" - "indica um imagens não-carro, precisamos agora de um classificador não-linear para tentar separar estes dois tipos de amostras.
A dimensão desta classificação no espaço recurso é quanto? Assumimos que 50 a 50 pixels, um total de 2500 pixels. Assim, temos que o número de elementos de um vector de característica n = 2500, o recurso de vector X compreende luminância valores de todos os pixels. Se usarmos uma imagem de cor RGB, cada pixel compreende vermelho, verde, azul e sub-pixels, em seguida, o número de elementos dos nossos vectores característicos torna-se n = 7500. Então, se temos que conter toda não-linear quadrática para resolver este problema, então esta é a fórmula em todas as condições. XI XJ início de 2500 pixels, juntamente com um total de cerca de 3 milhões. Este custo computacional é muito alto não é uma boa maneira de resolver problemas não-lineares complexas.
Em segundo lugar, os neurônios e cérebro
As redes neurais razão é que as pessoas querem tentar gerar um algoritmo projetado para imitar o cérebro. Em certo sentido, se quisermos construir sistema de aprendizagem, por que não aprender a imitar a máquina mais incrível que conhecemos - o cérebro humano não?
Redes Neurais aumento gradual na década de 1980 e 1990, é usado extensivamente. No entanto, devido a várias razões, a aplicação no final de 1990 reduzida. Mas, recentemente, a rede neural tem um retorno. Uma razão: a rede neural é um algoritmo computacional é um pouco grande demais. No entanto, nos últimos anos, provavelmente devido à velocidade de funcionamento do computador mais rápido, apenas o suficiente para realmente executar a partir das redes neurais em larga escala. É por esta razão, e outros que discutiremos mais tarde aos fatores técnicos. rede neural de hoje para muitas aplicações é a tecnologia mais avançada.
Quando você quer simular o cérebro, refere-se quer criar o mesmo efeito que o papel da máquina cérebro humano, certo?
O cérebro pode aprender a ir para ver e não que tipo de imagem, aprender a lidar com o nosso sentido do tato.
Podemos aprender matemática, aprender a fazer cálculos.
Cérebro pode lidar com uma variedade de coisas incríveis.
Se você quer imitar ao que parece, você tem que escrever um monte de software diferente para simular tudo, o cérebro nos diz este tipo de coisas maravilhosas. No entanto, o cérebro não se pode presumir que todos esses métodos fazem coisas diferentes. Para perceber a necessidade de usar milhares de programas diferentes. Em vez disso, o cérebro processa o método requer apenas um único algoritmo de aprendizagem sobre ele? Embora esta seja apenas uma hipótese.
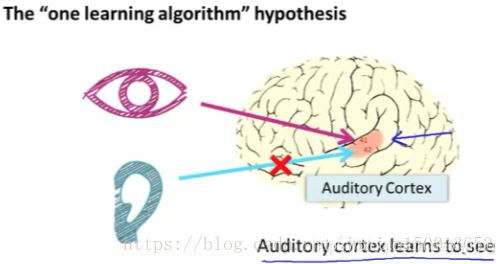
Mas deixe-me compartilhar com vocês algumas dessas evidências: Esta parte do cérebro, esta área é um pequeno pedaço de vermelho seu córtex auditivo. agora você entende as minhas palavras, este é pela orelha. Ear recebe sinais sonoros e transmite o som sinais para o córtex auditivo é por isso que você possa entender minhas palavras.
Os neurocientistas fazem o seguinte experimento interessante:
① orelha para nervo córtex auditivo é corte, neste caso, de um cérebro de re-animal, de modo que o sinal a partir do olho para o nervo óptico acabará por se espalhar para o córtex auditivo. Se isso for feito, os resultados mostraram que o córtex auditivo vai aprender a "ver". Aqui a "ver" cada um representa o significado do que sabemos, por isso, se você fizer isso a um animal, em seguida, o animal pode completar tarefa de discriminação visual, que pode ver a imagem, e tomar decisões adequadas com base na imagem, é através deles tecido cerebral do parcialmente concluída.
② o direito Outro exemplo: peça vermelha do tecido cerebral é o seu córtex somatossensorial, que é usado para processar o sentido do tato, e se você acabou de fazer uma reconexão experiência semelhante. Em seguida, o córtex somatossensorial pode aprender a "ver" esta experiência e outras experiências semelhantes, conhecido como experimento reconexão do nervo.
Neste sentido, se o corpo humano tem o mesmo pedaço de tecido do cérebro pode lidar com luz, som ou sinal táctil, então talvez haja um algoritmo de aprendizagem pode lidar com visual, auditiva e tátil, ao invés da necessidade de executar milhares de diferentes programas, ou milhares de diferentes algoritmos para fazer estes cérebro feito por milhares de coisas belas, talvez o que precisamos fazer é encontrar algum algoritmo de aprendizagem cérebro aproximada ou real, e, em seguida, implementá-lo.
Cérebro através de auto-estudo para aprender a lidar com esses diferentes tipos de dados, em grande medida, se podemos imaginar quase qualquer tipo de acesso sensor para quase qualquer parte do cérebro, em seguida, o cérebro vai aprender a lidar com isso.
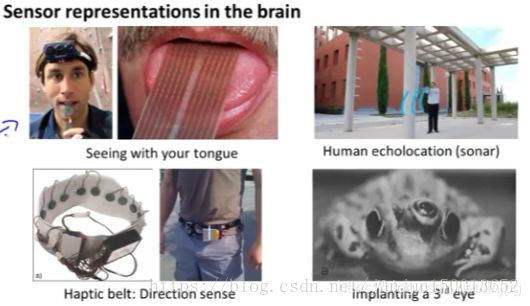
O primeiro exemplo: no canto superior esquerdo da imagem é um exemplo para aprender a "ver" com a língua. Seu princípio: Este é realmente um sistema chamado BrainPort, que é agora FDA (US Food and Drug Administration) em ensaios clínicos, pode ajudar pessoas cegas ver as coisas. Seu princípio é: você pega uma câmera de cinza na testa, para a frente, ele vai ser capaz de obter a imagem da escala de baixa resolução cinza de algo na frente de você. Ligar um fio para o conjunto de eléctrodos está montado sobre a língua. Cada pixel é então mapeado para um local em sua língua, pode ser o valor de tensão alta que corresponde a um ponto de pixel escuro, A corresponde baixo valor de tensão para um ponto brilhante pixel. Mesmo que agora está contando com as funções, você pode fazer uso deste sistema que eu aprendi a usar nossas línguas para "ver" algo em dezenas de minutos.
Um segundo exemplo: na ecolocalização humana ou corpo humano sonar, há duas maneiras que você pode conseguir. Você pode se referir a rotura ou a cabeça de framboesa, mas há pessoas cegas fazer aceitar essa formação na escola e aprender a interpretar as ondas sonoras se recuperar de um modelo ambiental - que de sonar. Se, depois de pesquisar YouTube, você vai encontrar: algum vídeo surpreendente conta a história de uma criança, ele foi brutalmente removido por causa do câncer do olho, embora a perda do olho, mas por estalar os dedos, ele pode se mover sem bater em nada. Ele pode skate, ele pode colocar a bola de basquete na cesta, nota que este não é o olho de uma criança.
Um terceiro exemplo: Correia de toque. Se você usá-lo em torno da cintura, a campainha soará, e sempre zumbido quando voltada para o norte. Ele pode fazer as pessoas têm um senso de direção, de forma semelhante às aves percebem direção.
Existem alguns exemplos de bizarro: Se você inserir o terceiro olho em rãs, rã pode aprender a usar esse olho.
Estes exemplos são muito surpreendente se você pode acessar praticamente qualquer sensor para o cérebro, algoritmo de aprendizagem do cérebro será capaz de encontrar uma maneira de aprender de dados e processa os dados. Em certo sentido, se podemos encontrar algoritmo de aprendizagem do cérebro, e em seguida, executar algoritmo de aprendizagem cérebro ou com um algoritmo semelhante em um computador. Talvez seria melhor para tentar fazer nosso movimento para a inteligência artificial. O sonho da inteligência artificial é um dia ser capaz de criar uma máquina verdadeiramente inteligente.
Em terceiro lugar, o modelo de rede neural
Quando usando a rede neural, como podemos expressar nossas hipóteses ou modelos:
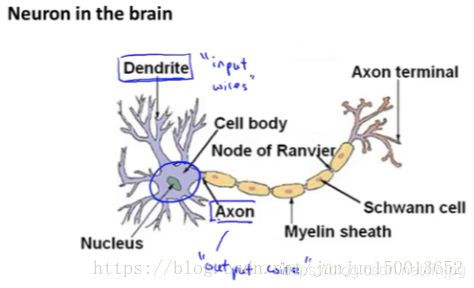
rede neural foi inventado imitando os neurônios do cérebro ou rede neural, portanto, para explicar como para representar os pressupostos do modelo, vamos olhar para o que os neurônios individuais no cérebro.
Nosso cérebro está cheio de tais neurônios, os neurônios são as células do cérebro, em que há dois pontos dignos de nota: Em primeiro lugar, há corpos celulares neuronais como esta, e segundo neurônio tem um número de neurônios de entrada.
Estes neurônios de entrada, chamados dendrites, podemos pensar neles como fios de entrada. Eles recebem informações de outros neurônios. neurônios de saída chamadas de axônios, neurais Estas saídas são usados para sinais de transmissão para outros neurônios ou informações a transmitir.
Resumidamente, os neurónios são uma unidade de computação. Ele aceita um certo número de informações a partir de neurônios de entrada e fazer alguns cálculos. O resultado é, então, transmitido através do seu axónio para outros nós ou outros neurónios no cérebro.
Este é o modelo de tudo o pensamento humano: nossos neurônios colocar a sua mensagem está sujeita a cálculo e outras yuan neurológicos entregar a mensagem.
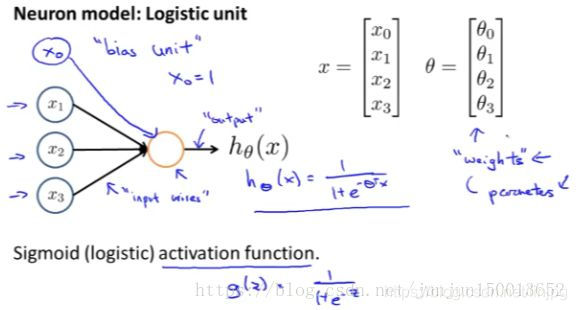
x1 entrada, x2, x3, hθ saída (x) = 1 / (1 + E (-θTX)), que é um modelo muito simples para simular o trabalho de neurónios. Nós neuronal modelada como uma unidade lógica, semelhante aos neurónios círculo amarelo, uma função em forma de S ou função lógica como uma funções de activação dos neurónios artificial, a terminologia de rede neural, a função de excitação semelhante apenas função não linear g (z ) outra chamada prazo. θ são os parâmetros do modelo, às vezes chamado de "peso", x0 é tendenciosa células nervosas, porque x0 é sempre igual a 1, por vezes, pintado, por vezes, não elaborado, por exemplo, dependendo se benéfica. , X1 x2 x3 nervo semelhante à de entrada, de h (x) representa os neurónios de saída.
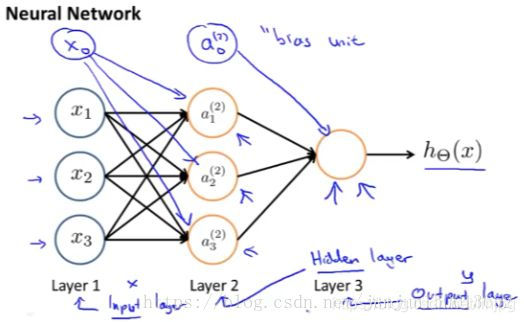
Na verdade, é uma colecção destes rede neural combinado neuronal diferente. Especificamente, aqui é x0 x1 x2 e x3, um neurónio (2) 1-A (2) 2 e um (2) 3 (A (2) 0, é a unidade de polarização adicional, a unidade de entrada nos valor é 1), a função de saída H última camada é assumido que o resultado (x) o cálculo.
Neste exemplo, que tem uma camada de entrada - a primeira camada, uma camada oculta - a segunda camada, uma camada de saída - camada 3. Mas, na verdade, a camada de entrada ou qualquer camada da camada de não-saída é chamada de camada escondida.
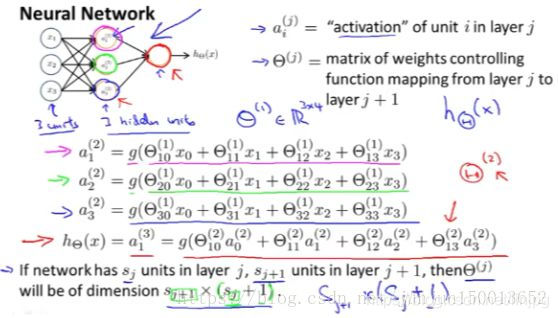
Sob um sobrescrito (j) representa o índice i: j-th camada ou o i-ésimo excitação neurónio, o chamado excitação (Activação) significa um valor de um determinado neurónio lê, calcula e saídas.
Aqui, temos três unidades de entrada e três unidades ocultas. Como controlo nós matriz parâmetros a partir de três unidades de entrada, o mapeamento de três unidades escondidos. Assim θ (1) torna-se uma matriz de três dimensões por 4.
De modo mais geral, se uma rede de unidades de camada Sj j-th, as células j + 1 camada Sj + 1, a matriz [teta] (j), isto é, a camada matriz de controlo j para j + 1-camada dimensão mapeamento para Sj + 1 * (Sj + 1)
Finalmente, na camada de saída, que tem uma unidade que calcula h (x) Esta também pode ser escrito um (3) 1 (terceira camada, o primeiro elemento)
Em quarto lugar, o modelo representa
Para alcançar quantificados antes da disseminação de

Estes valores são uma combinação linear de Z, é o valor de entrada θ0 θ1 θ2 θ3 ponderada combinação linear com x3 x0 x1 x2, que pode definir uma (1) ser igual ao vector x. O h, calculado (x) do processo é também referida como de propagação para a frente (para a frente de propagação). Assim chamado porque nós começamos a partir da camada de entrada de excitação para a camada escondida e depois se espalhou para a frente e foram calculados camada de excitação escondido. Então, antes de continuar a se espalhar, e calcular a camada de saída de excitação. O antigo a partir da camada de entrada para a camada escondida e processo de excitação, em seguida, para a camada de saída, são sequencialmente calculado é chamado de propagação.
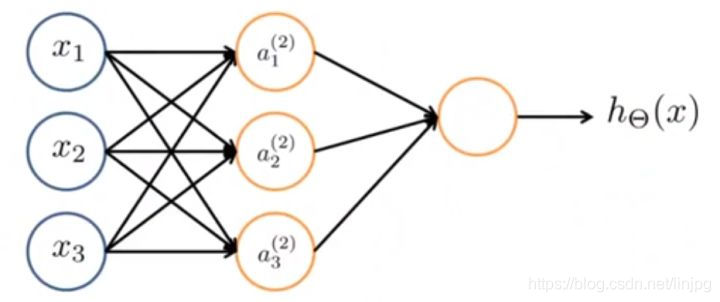
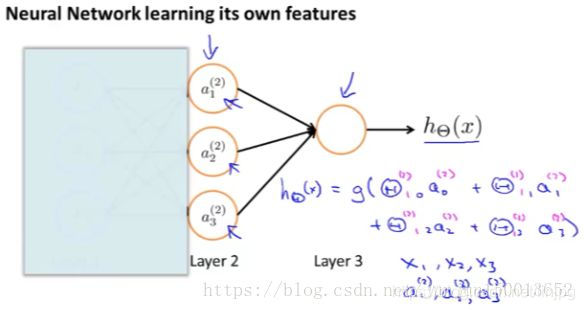
Nós esconder a camada de entrada, itens de recurso visíveis a1 a3 a2 como eles são de entrada para aprender. Especificamente, é a função de mapeamento a partir da primeira camada para a segunda camada, a função é determinado por outro conjunto de parâmetros θ (1).
Assim, em uma rede neural, ele não usa o recurso de entrada x3 x1 x2 treinados regressão logística, regressão logística, mas a sua formação como entrada. Se a1 a2 a3 concebível para selecionar um θ parâmetro diferente (1), por vezes, pode aprender algumas características interessantes e complexos. Você pode obter uma melhor hipótese, x2 x1 ou x3 obtido quando assumindo que melhor do que a entrada original, a próxima seção irá falar sobre o porquê.
Você também pode usar outros tipos de diagramas para representar a rede neural, a forma como os neurônios de redes neurais estão conectados é chamado de arquitetura de rede neural, de modo que a arquitetura refere-se a como os diferentes neurônios são conectados uns aos outros.
V. Aplicação
Exemplos descreve a forma como a rede neural é uma função não linear complexo da introdução de um cálculo
Vamos olhar duas perguntas simples:
E uma primeira operação ou uma segunda operação
PS: números sobre uma linha recta, por exemplo -30, + 30, é uma θ peso. Função g (x) é um padrão sobre a função em forma de S.
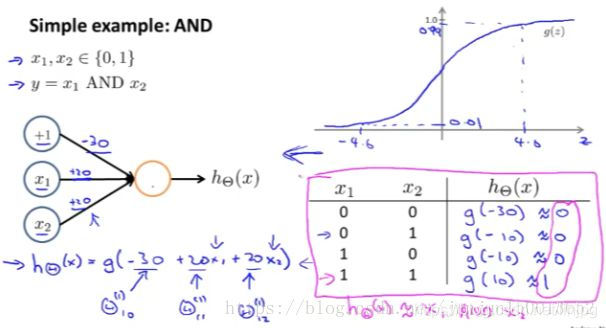

O seguinte não execução e funcionamento e, em seguida, o primeiro

A acima mencionada operação de ligação, ou para alcançar a mesma operação
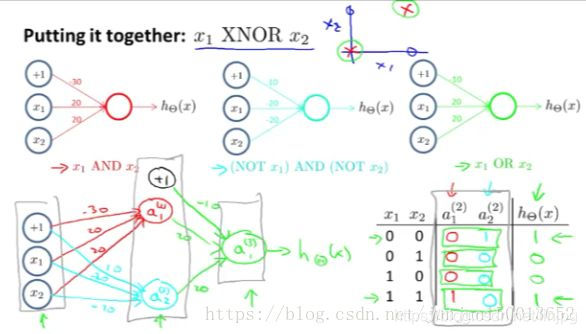
Idéias, ou com o mesmo resultado binário é de dois para um. É o mesmo que x1, x2 (primeira camada) e depois de operação (uma segunda camada de neurónio), operação X (uma segunda camada de um segundo neurónio), e, em seguida, através da operação (neurónios terceira camada) ou depois ou para se obter a mesma operação (saída).
Na camada de entrada, só temos os valores de entrada originais, em seguida, nós estabelecemos uma camada escondida usado para calcular o número de grandezas de entrada funções um pouco mais complexo, e adicionando outra camada escondida, temos a função um pouco mais complicado, que é rede neural pode ser calculado com alguma função mais complexo de interpretação visual.
classificação de seis multi-classe
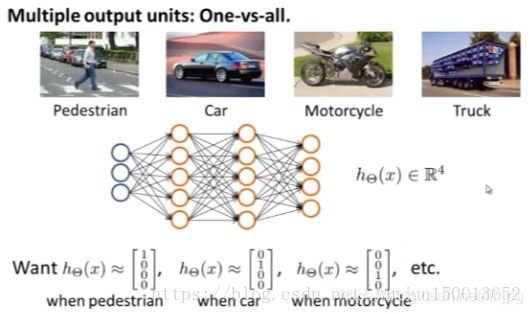
Como rede neural de classificação multi-classe, antes se trata de classificação binária, que pode ser representado por uma saída, 0 ou 1.
Para problema de classificação multivariada, não usamos uma saída expresso como 1,2, ... 10; ela é representada utilizando o vector, como segue:
Um exemplo final, o primeiro neurónios da camada de saída, que indica que é uma pessoa, que indica 0 n humano. Os neurónios de segunda camada de saída, indica que se trata de um automóvel, não automóvel ... 0 indica que ele possa determinar o que é por meio do vector de saída final, isto é, para a classificação de várias classes.
Referência 07 Machine Learning (Andrew Ng): hipótese de não-linear (modelo de rede neural)
Andrew Ng aprendizagem de máquina - a aprendizagem da rede neural
