Antes de compreender aprendizado supervisionado e aprendizagem não supervisionada, vamos conversar o que é a aprendizagem de máquina (ML)?
Machine Learning:
Primeiro de tudo, a aprendizagem pode ser chamado de um processo de replicação, dar castanha: Muitas vezes participar em questões do exame estudante, exame da sala de exame antes de nós pode não ter feito, mas antes do exame normalmente escovar um monte de problemas, por tópicos escova aprendeu métodos de resolução de problemas e, portanto, enfrentam a estranha pergunta sobre o teste também pode calcular a resposta.
ideias máquina de aprendizagem são semelhantes: podemos usar alguns dos dados de treinamento (título já feito), para que a máquina possa usá-los (abordagem de resolução de problemas) análise de dados desconhecidos (exame assunto). Como o professor antes do exame para exame exame que nós esperamos o mesmo.

frase simples: aprendizagem de máquina é permitir que a máquina para se concentrar em aprender com grandes quantidades de dados, e em seguida, obter um modelo mais realista da lei, através da utilização do modelo faz com que a máquina melhor do que o desempenho de sempre.
aprendizagem supervisionada:
Definição: O conjunto de dados existente, conhecer a relação entre entrada e saída. De acordo com esta relação conhecida, para obter um modelo de formação ideal. Em outras palavras, ambos supervisionados aprender a característica de dados de treinamento (recurso) outro rótulo (label), através da formação, para que a máquina pode fazer uma conexão entre as características e etiquetas, em face de não só as características dos dados da etiqueta, tag pode ser julgado.
De acordo com o vídeo professor Andrew Ng no Resumo palavras:
Agora vamos recordar esta lição que introduziu o aprendizado supervisionado. A idéia básica é que o nosso conjunto de dados para cada amostra tem um correspondente "resposta certa". Em seguida, fazer previsões com base nessas amostras, como no exemplo casas e tumores fazer.
Temos também introduziu o problema de regressão, ou seja, por meio de regressão para lançar uma saída contínua, depois que introduziu o problema de classificação, o objetivo é a introdução de um conjunto discreto de resultados
Claramente, a aprendizagem de máquina pode ser entendida como nós ensinamos máquinas como fazer as coisas.
Supervisionado classificação aprendizagem: Regressão (Regressão), classificação (Classificação)
Regressão (Regressão)
retorno à sua pergunta é em variáveis contínuas.
Para castanha: prever os preços das casas
Suponha que você queira prever os preços das casas, tornando tais conjuntos de dados abaixo. O eixo horizontal, o tamanho da casa é diferentes pés quadrados no eixo vertical, é diferentes preços da habitação, a unidade (fazer $). Considerando os dados, assumindo que uma pessoa tem uma casa, a 750 pés quadrados, ele quer vender a casa, eu quero saber quanto vender.

Desta vez, supervisionado aprender algoritmo será capaz de voltar a vir a calhar, podemos traçar uma linha reta ou uma função de segunda ordem, etc. De acordo com os conjuntos de dados para ajustar os dados.
Através da imagem, podemos ver montagem em linha reta fora 150k, curva arranjo é 200k, de modo a continuar a formação e aprendizagem, para encontrar o modelo mais adequado foi ajustada aos dados (preços).
Regressão ponto popular é o ponto (os dados de treinamento) modelo de análise existente encaixando uma função apropriada y = f (x), onde y é dados da etiqueta, e por uma nova variável x independente, pela função modelos obter rótulo y.
Classification (Classificação)
e regressão maior diferença é que, para a classificação é o resultado de saída discreta é limitado.
Para castanha: a natureza estimado do tumor
Suponhamos que alguém descoberto um tumor de mama, existe uma protuberância na z mama tumor maligno é perigoso, prejudicial; tumores benignos são inofensivos.
Suponhamos que no conjunto de dados, o eixo horizontal representa o tamanho do tumor, o eixo vertical é 0 ou 1, e Y pode ser ou N. Na amostra de tumor conhecido, um marcado maligno, benigno 0 marcados. Assim, medida que a amostra é benigna azul, vermelho é maligna.
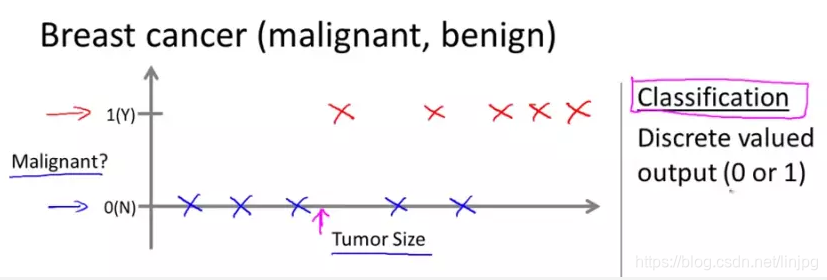
Desta vez, a tarefa de aprendizagem de máquina é estimar a natureza do tumor é maligno ou benigno.
A classificação veio a calhar neste caso é modelar amostra de treinamento de entrada humano vários dados (aqui é o tamanho do tumor, é claro, a vida real usará mais dados, como idade, etc.), resultando em "input dados de uma pessoa para determinar "o resultado, o resultado deve ser discreta, apenas" se o sofrimento de sim câncer "ou" não ".
Então ele simplesmente é classificada, através da análise do vector recurso de entrada, para um novo vetor de obter seu rótulo.
Aprender sem supervisão:
Definição: Não sabemos a relação entre os dados centralizado de dados, características, mas para obter a relação entre o agrupamento ou dados com base em determinados modelos.
Por assim dizer, do que a aprendizagem supervisionada, aprendizagem não supervisionada é mais como uma auto-estudo, deixar a máquina aprender a fazer as coisas, não há label (etiqueta) é.
Basta dar o exemplo usado acima, a interpretação de aprendizagem de máquina para melhor compreender a diferença entre os dois:
Para o exame de costume, o equivalente a aprendizagem supervisionada temos feito uma série de problemas todo sabe que é a resposta padrão, assim, no processo de aprendizagem, podemos controlar as respostas, para encontrar uma maneira de analisar o problema, a próxima vez que não existe uma resposta em face quando o problema muitas vezes pode ser resolvido com precisão. Sem aprendizado supervisionado, não sabemos qualquer uma das respostas, não sei que fiz a coisa certa, mas não causa o processo, se não souber a resposta, podemos linguagem mais ou menos separado, Matemática, Inglês estes temas, porque estes problemas inerentes ou ter alguma ligação.
Como mostrado abaixo, na aprendizagem não supervisionada, estamos apenas dado um conjunto de dados, o nosso objectivo é encontrar esse grupo especial de estrutura de dados. Por exemplo, podemos usar o algoritmo de aprendizado não supervisionado vai esse conjunto de dados é dividido em dois grupos distintos ,, tal algoritmo chamado cluster algoritmo.

Aplicação de vida:
1.Google Notícias De acordo com a diferente estrutura de conteúdo dividido em diferentes finanças etiqueta, entretenimento, esportes, e isso não é o agrupamento supervisionado aprendendo.
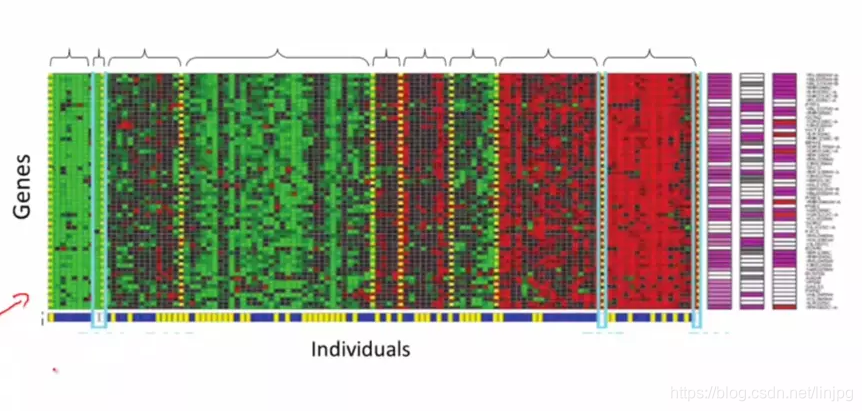
2. dado gene são classificados de acordo com a multidão. FIG dados de ADN é para um conjunto diferente de pessoas medimos o seu grau de express do ADN para um determinado gene. Em seguida, os resultados de medição do algoritmo de agrupamento podem ser divididos em diferentes tipos. Este é um aprendizado não supervisionado, porque estamos apenas dado alguns dados, mas não sei qual é o primeiro tipo de pessoa, que é o segundo tipo de pessoa, e assim por diante.