14.1 uma motivação: compressão de dados
redução de dimensionalidade é um método de aprendizagem não-supervisionada, redução de dimensionalidade não requer o uso de dados de tag.
Um dos propósitos de redução de dimensão é a compressão de dados, compressão de dados só pode Compactar dados usando menos memória do computador ou espaço em disco, mas também acelerar o nosso algoritmo de aprendizagem.
redução de dimensionalidade pode ser um recursos de redundância bom negócio, tais como: Quando é que o projeto, há várias equipes de engenharia diferentes, talvez a primeira equipe do projeto para dar-lhe duzentos recurso, a segunda equipe de engenharia para dar-lhe um outro trezentos recurso, uma terceira equipe do projeto para dar-lhe quinhentos recurso, mais de 1.000 apresenta todos juntos, esses recursos, muitas vezes há uma enorme redundância, mas também para manter o controle de um grande número desses recursos vai ser extremamente difícil.

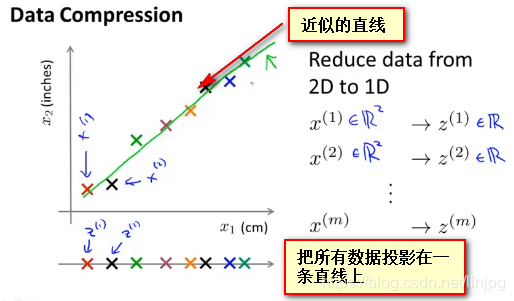
As dimensões de recursos 2-dimensionais para baixo para 1
ou menos, por exemplo, se um item de medição do comprimento, o eixo horizontal indica o uso cm, como um resultado das unidades de medida, e o eixo vertical representa a utilização de pé como um resultado das unidades de medida, caracterizado pelo facto dos dois no entanto, uma grande quantidade de redundância devido ao arredondamento durante resultados das medições nos resultados de medição pode não ser igual, portanto, deseja remover a redundância do caminho redução dimensão dados
Neste ponto parece querer encontrar uma maioria, de acordo com a sua linha de queda próximo, de modo que todos os dados podem ser projetadas em apenas on-line, através desta prática, eu era capaz de medir a posição de cada amostra, a fim de criar uma nova linha em que Z1, isto é, os dados originais que preciso x (1), X (2 ) representa um duas características dimensionais e, agora, apenas um valor de Z dos novos recursos pode ser expresso pelo teor das duas características originais
projectada na amostra por uma aproximação linear, pode ser representado pelos dados originais podem ser definidos por um valor real para todas as amostras em que X (1), X (2 ), X (3), X (4) ... x (m ) para indicar o conjunto de amostra de dados, x1, x2 representa o conjunto de dados original para a característica, z (i) representa o i-ésimo amostra utilizada pela nova redução de dimensão característica obtido.
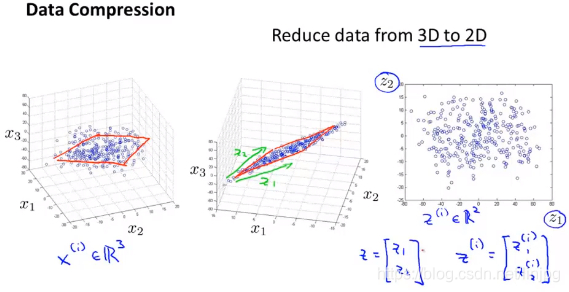
O 3-dimensional de características de 2-dimensionais
do vector tridimensional projectados sobre um plano bi-dimensional, forçando todos os dados sobre o mesmo plano, para baixo para os vectores de características bidimensionais. Originais pontos de dados tridimensionais em um plano bidimensional, os dados bidimensionais de posição que indicam os pontos característicos em um plano bidimensional. Em que as características primitivas utilizando três X1, X2, X3 representa uma nova utilização característica de Z1, Z2 representa, o que significa que dois eixos de projecção plano, $ Z ^ {(i) } indica o i-ésimo amostra para cair através novos recursos de manutenção de paz obtido.
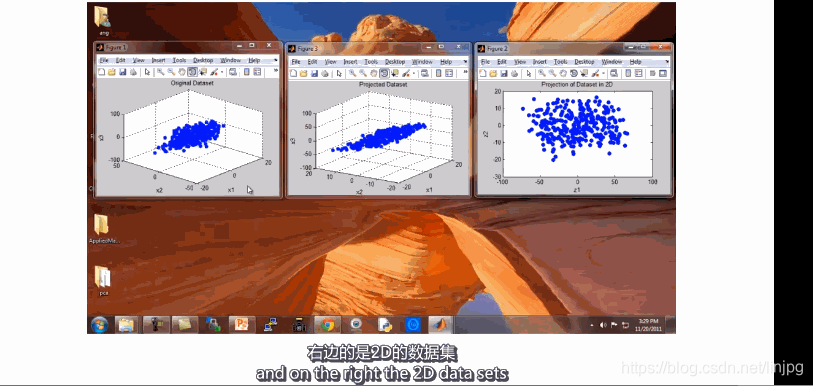
14,2 motivação II: visualização de dados
Actualmente, podemos apenas 2-3 visualização de dados dimensional, uma vez que os dados se torna grandes dimensões, não podemos excluir dados de descoberta intuitiva. Neste ponto, a redução da dimensão tornou-se um trabalho muito intuitiva e muito importante.
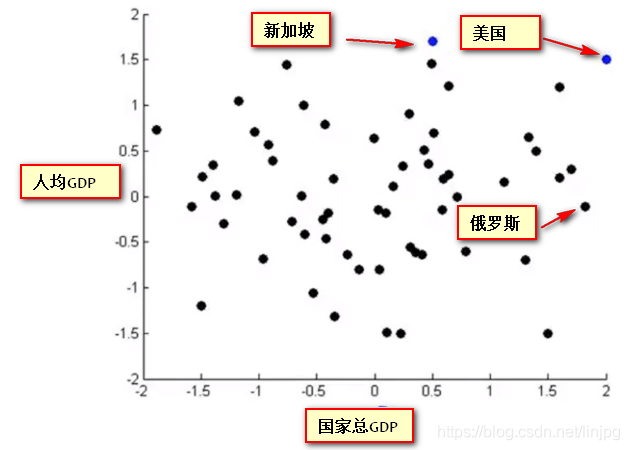
O seguinte é um relatório do nível de desenvolvimento nacional, a avaliação do país por 50 indicadores, que queremos ver com métodos de visualização intuitivas, mas os dados de 50-dimensionais é impossível usar renderização de gráficos, para o qual usamos redução de dimensionalidade ser reduzido para o método de vista 2-dimensional.
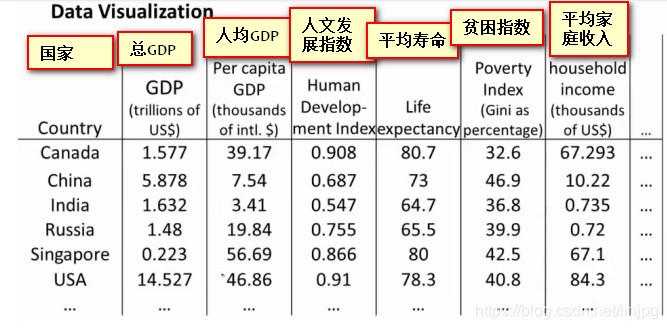
É integrado em dois novos recursos Z1 e Z2 por meio de dimensionalidade redução de 50 dimensões, mas o significado dos nossos novos recursos, nós não sabemos. Essa redução dimensão só pode reduzir as dimensões das necessidades de dados para redescobrir o significado e definição dos novos recursos.

Use cair representação gráfica dos novos recursos da dimensão:
o eixo horizontal representa cerca de força econômica geral do país / países PIB PIB
eixo vertical representa cerca de índice de felicidade / PIB per capita
14,3 principais princípio análise de componentes
Formulação Proncipal Componente Análise Problema
análise de componentes principais (PCA) é o algoritmo de redução de dimensão mais comum
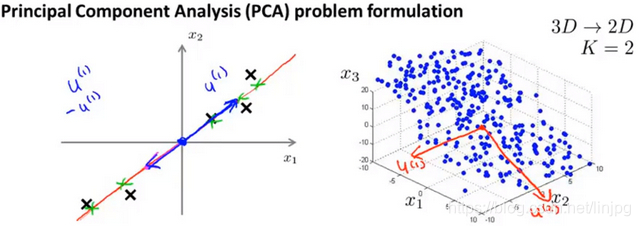
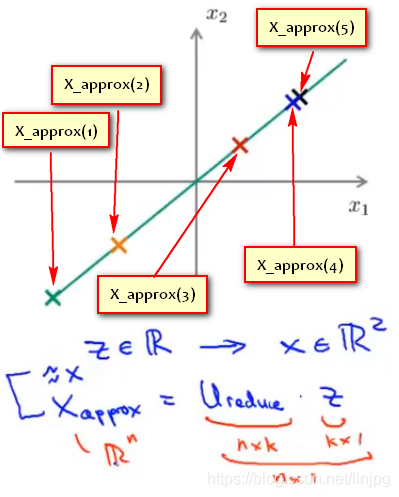
quando o componente principal do número de K = 2, o nosso objectivo é encontrar um plano de projecção de baixa dimensão, quando todos os dados são projectados sobre o plano dimensional baixo quando a esperança de que todas as amostras do erro médio de projecção pode ser tão pequena quanto possível. Dois plano de projecção é um plano longitudinal que passa através da origem do vector a partir do plano, o erro de projecção é feito perpendicular ao plano de projecção a partir do vector característico.
Quando o número de componentes principais K = 1, o nosso objectivo é encontrar um vector de direcção (direcção Vector), quando se colocar todos os dados sobre o vector, é desejável que todas as amostras do erro médio de projecção pode ser tão pequena quanto possível. Direcção vector é um vector que passa pela origem, o erro de projecção (erro de projecção) a partir do vector característico, a ser o comprimento do vector de uma direcção perpendicular.
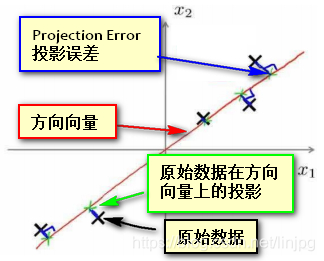
Se os dados de projecção ilustrado no caso de figura, onde um espaço bidimensional, a FIG preto × representa os pontos de amostra original, é o vector de direcção do vermelho, erro projecção azul, um ponto verde representa os dados de projecção na direcção do vector. E objectivo é encontrar o PCA isto é, um vector de direcção de tal modo que todos os dados de projecção que se projecta na direcção do erro mínimo vector de
característica normalizada APC Nota antes da utilização, e necessidade de ser normalizada
princípio análise de componentes principais
um encontrar abaixo de uma dimensão a partir de um de dois dados dimensionais sobre uma projecção pode ser feita sobre o erro mínimo do vector de direcção (μ (1) ∈Rn).
Caiu a partir dos vectores de k-dimensional n-dimensional encontrado μ k (1), μ (2 ), μ (3) ... μ (k), de modo que os dados originais é projectada para o mínimo linear erro projecção subespaço destes vectores.
PCA e regressão linear é diferente
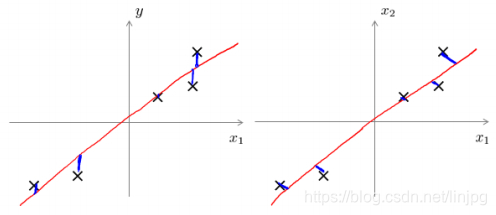
do mecanismo e os resultados ponto de vista, muito parecido com o PCA e regressão linear, aparentemente é encontrar uma linha ou de avião pode ser aproximada por ajuste dos dados originais, embora parecia muito semelhante, mas na verdade, completamente diferente.
Erro principal de projecção de Análise de Componentes é minimizado (ProjectedError), e a tentativa de regressão linear é para minimizar o erro de predição. Análise de componentes principais é um método de aprendizagem não supervisionada, a regressão linear é um método de aprendizagem supervisionada, o objetivo é prever o resultado da regressão linear e análise de componentes principais não faz nenhuma previsão, todas as propriedades características dos dados originais é o mesmo em análise de componentes principais tratada. A seguir, a esquerda é o erro de regressão linear (eixo horizontal perpendicular à projecção), o direito é o principal componente de erro análise (direcção perpendicular ao vector de projecção).
vantagens e desvantagens de PCA
as vantagens de
uma grande tecnologia vantagem PCA é reduzir a dimensionalidade do processamento de dados. Efeito podemos classificar a importância Vector "pivot" recém-determinada, de acordo com o precedente, a necessidade de ter a parte mais importante, a dimensão desta última é omitida, de modo que a redução da dimensão pode ser realizada ou a compressão de dados modelo simplificado . Embora mantendo o maior grau de informação dos dados originais.
A tecnologia grande vantagem PCA é que é limites completamente não-paramétricos. APC durante o cálculo dos parâmetros definidos completamente sem intervenção humana ou calculados de acordo com qualquer um dos modelos empíricos, o resultado final é somente relacionado com os dados, o utilizador é independente.
A desvantagem
que pode também ser visto como uma desvantagem. Se tiver algum conhecimento prévio do objecto a ser observado, para dominar algumas das características dos dados, mas não pode intervir no processo por métodos paramétricos, não pode ser o efeito desejado, a eficiência não é alta.
14,4 principais algoritmo de análise de componentes algoritmo Proncipal Análise de Componentes
Suponhamos que os dados originais usando o método de APC de dados n-dimensional estabelecidas para o K-dimensional
normalização média calculada significativo UJ todas as características, em seguida, os dados originais por subtracção da média UJ todas as dimensões da dimensão, e mesmo se xj = xj-μj, Se o número de características em diferentes fases, mas também precisam de ser divididas por dimensão desvio σ2 padrão própria
matriz de covariância cálculo de um conjunto de amostras (covariância matriz), cada vector N-dimensional de dimensão (Nl), multiplicado por si só dimensão ( 1N) de transposição, para dar a (N * N) matrizes simétricas, e matrizes Todas as amostras obtidas após a adição do conjunto de amostras de covariância matrizes [Sigma
i.e .:
[Sigma = 1N 1mΣi = (X (I)) (x (i)) t
Nota Se x (i) em si é armazenados vector da linha, assumindo que X é a amostra x (i) uma camada de matriz de camada de empilhamento da amostra, existem:
[Sigma XT * X * = 1M
isto é,
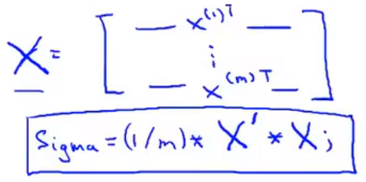
cálculo da matriz de covariância [características Sigma de vetor (Autovetores), pode ser utilizada a decomposição do valor singular (decomposição em valores singulares) é resolvida utilizando a instrução em Matlab [L, S, V] = SVD (Sigma), onde sigma representa Σ matriz de covariância i.e. conjunto de amostras,
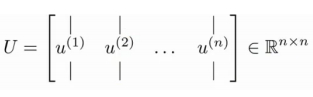
a fórmula acima a matriz U é um vector de direcção que tem o menor erro entre a configuração de dados de projecção. Se pretender que os dados de dimensão reduzida N-dimensional K, que simplesmente selecionar a primeira K L na figura acima i.e. vectores de U (1), L (2 ), L (3), ... u (K) de, para se obter uma dimensão N × K de uma matriz, utilizando Ureduce expresso e obtido o requerido pelo cálculo de um novo vector de características z (i), isto é
z (i) = UTreduce * x (i)
, onde X (i) representa N * 1 vectores de amostra de dimensão, e UT é uma matriz de configuração direcção vector de K * N-dimensional, de modo que o resultado definitiva Z ^ {(i)} é um K * 1-dimensional vectores, isto é, o novo vector de características por APC obtidos
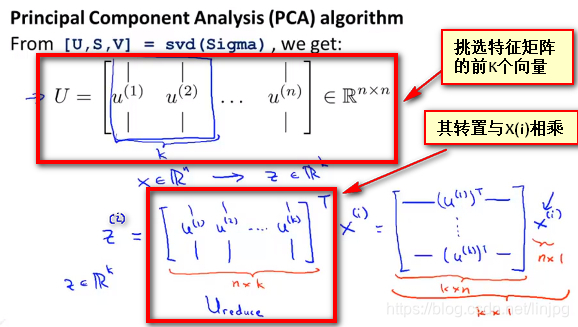
são resumidos

14,5 reconstruir a representação comprimida
Reconstrução do comprimido Representação
utilizando o APC, 1000 pode comprimir dados para dimensões de recursos 100-dimensional, ou de dados tridimensionais comprimido para uma representação bidimensional. Assim, se o PCA se a tarefa é um algoritmo de compressão deve ser capaz de voltar para este formulário antes da compressão do referido retorno a uma aproximação dos dados originais de alta dimensão. A figura é usado para mapear as amostras PCA x (i) para o z (I)
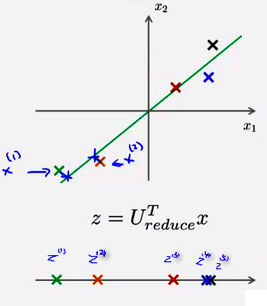
isto é, se é possível retomar alguma maneira para uso x (1) e x (2) os dados representados por forma bidimensional sobre o ponto z.
O método de
utilizar Xappox representa um vector n-dimensional (n * 1) reconstruído amostras, utilizando Ureduce representa uma matriz característica (N * k) seleccionada usando vectores próprios composição APC algoritmo K, utilizando a redução de dimensão APC indicação Z após as amostras de dados a nova funcionalidade (k * 1) tem :.
Xappox a Z * = Ureduce
i.e.
Selecione o número de componentes principais 14.6
Escolhendo o número de componentes pricipal
do erro quadrático médio do mapeamento (Média erro quadrado de projecção), e a variação total (total Variação)
objecto da PCA consiste em reduzir o erro quadrado médio do mapeamento ,, isto é, para reduzir o x amostra original (i) e reconstituídas pela significa da appox amostras de diferença de quadrados x (i) (de baixo ponto de mapeamento tridimensional) de
1mΣi = 1m || x (i) -x (i) a aproximadamente 2 ||
dados variação total (variação total) é definido como: o comprimento médio das amostras de dados originais:
1mΣi 1M = || X (I) || 2
meios: em média a partir dos dados brutos do vector zero.
A regra empírica consiste em seleccionar o valor de K
a uma razão de erro quadrado médio do mapeamento e como variação total é pequeno (tipicamente 0,01 selecção) seleccionar o menor valor possível de K para esta proporção é inferior a 0,01, para profissionais: reservados dados 99 % da diferença (99% da variância é retido)
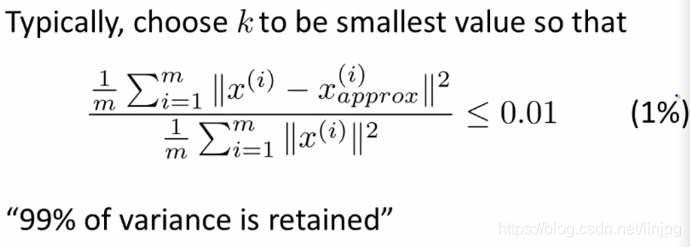
Selecção de um parâmetro K, e 99% das diferenças é mantido
normalmente têm outros valores de 0,05 e 0,10, é de 95% e 90% da diferença é preservada.
Número principal algoritmo de selecção de componentes
método menos eficiente
Shilling K = 1, em seguida, submetidos a análise de componente principal para se obter Ureduce e Z (1), Z (2 ), ... Z (m), e, em seguida, calcular a baixa dimensão ponto de mapeamento x ( i) a aproximadamente, em seguida, calculou-se a razão entre o erro quadrático médio do mapeamento e a variação total é inferior a 1%. Se não, novamente fazendo K = 2, e assim por diante, até que encontre o valor mínimo de K pode ser tal que a proporção de menos do que 1%

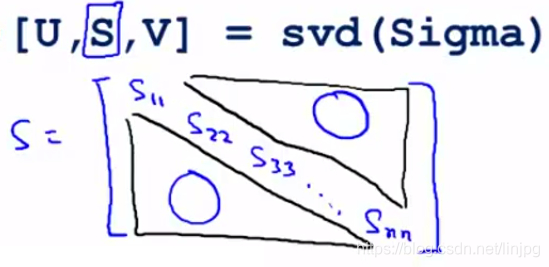
Uma maneira melhor
e alguns melhor maneira para seleccionar K, quando o cálculo da matriz covariância Sigma função, chamada "SVD", que tem três parâmetros:
[a U, S, V] = SVD (Sigma)
, em que L são vectores próprios, e S é uma matriz diagonal de elementos diagonais S11, S22, S33 ... e os elementos restantes da matriz são 0 Snn.
Pode ser provado (nesta fórmula apenas mostra a prova não é dada), as duas equações seguintes são iguais, ou seja:
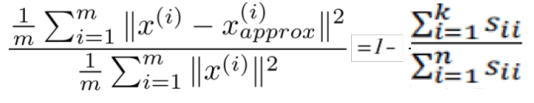
Por conseguinte, a condição original pode ser convertido para: 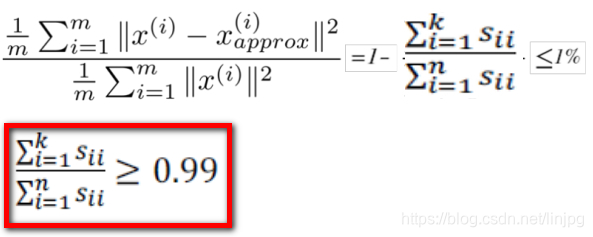
encontrar o menor valor de K condição de que satisfaçam de acordo com a fórmula .
Recomendações de Aplicação 14,7 principal Análise de Componente de
Teste e conjuntos de validação e deve ser usado como um conjunto de treinamento de vetores de características Ureduce
se estamos sendo uma visão de computador para uma imagem de pixel aprendizagem de máquina 100 × 100, ou seja, um total de 10000 recursos.
O primeiro passo é a utilização de análise de componente principal para a característica de compressão de dados 1000
e o conjunto de treino executando um algoritmo de aprendizagem
na previsão, utilizando um conjunto de treino de aprendizagem característica vem entrada Ureduce x é convertido num vector de características Z, então predição
Nota que, se temos um conjunto de teste de definir validação cruzada, também usado conjunto de treinamento Ureduce de aprender com
APC não está resolvido método para a montagem de
um erro comum o uso de análise de componentes principais da situação é que a APC para reduzir o excesso de montagem (por redução do número de recursos). Isso é muito ruim, devemos usar o processo de regularização. A razão é que a principal análise de componentes só é aproximada descartadas algumas das características, e não leva em consideração qualquer variável de resultado y (ie, etiqueta previsto) informações e, portanto, pode estar faltando uma característica muito importante. PCA, afinal, nenhum método de aprendizagem supervisionada, qualquer recurso, se o atributo de entrada ou tag atributos, que são tratados da mesma, não levam em conta o impacto de reduzir a informação de entrada na etiqueta y por PCA parte descarte da propriedade de entrada não foi feito na etiqueta qualquer compensação. No entanto, quando a regularização processo, devido à regressão logística ou redes neurais ou SVM levará em conta a regularização e impacto sobre variáveis de resultados (rótulo previsto) alterações nos atributos de entrada e dar um feedback, de modo a regularização não vai perder dados importantes características.
PCA não é necessário método
PCA é quando grandes volumes de dados, por assim dimensões Compactar dados, dados, reduzindo ocupam memória e acelerar o uso de treinamento de velocidade, ou quando a necessidade de compreender os dados usando a visualização de dados, em vez de uma forma exigida. Padrão adicionados ao sistema de aprendizagem de máquina PCA independentemente do desempenho do PCA não é adicionado quando o sistema está errado. Desde o PCA vai perder parte dos dados, os dados é talvez a dimensão crítica, deve primeiro sistema de aprendizagem de máquina não considera o uso de PCA, enquanto apenas métodos de treinamento convencionais (algoritmo rodando muito lento ou ocupar quando necessário muita memória) antes de considerar o uso de análise de componentes principais.
Referências [máquina Andrew Ng Notas aprendizagem] 14 1-2 redução dimensionalidade aplicada redução de dimensão de compressão de dados e de visualização de dados
Andrew Ng aprendizagem máquina de redução de dimensionalidade notas alvo 48-
13 Machine Learning (Andrew Ng): redução dimensionalidade
