Em primeiro lugar, a idéia de agrupamento
Refere-se o chamado algoritmo de agrupamento divide automaticamente os dados em uma pilha de etiquetas sem categorias método pertencentes ao método de aprendizagem não supervisionada, que é garantir que o mesmo tipo de dados com características semelhantes, como mostrado abaixo:
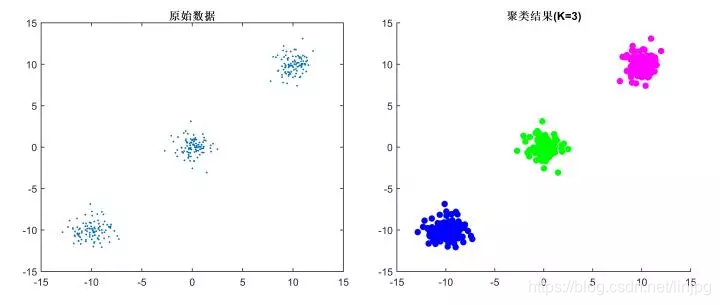
A distância entre a amostra ou uma similaridade (resistência proximidade), a mais semelhante, as amostras de diferença menor agrupados em um grupo (cluster), e finalmente formação de uma pluralidade de agrupamentos, o interior da amostra com uma alta similaridade aglomerados, diferente diferenças entre alta cluster.
algoritmo de agrupamento dois,-k meios
Conceitos Relacionados:
O número de cachos de ser obtido: valor K
Centróide: vector médio de cada grupo, isto é, o vector pode ser calculada a média para cada dimensão
medidas de distância: distância euclidiana e similaridade cosseno utilizado (a primeira) de normalização

processo algorítmico:
1, a determinação de um primeiro valor de k, i.e., queremos obter o conjunto de dados através de um conjunto de agrupamentos de k.
2, seleccionado aleatoriamente como os pontos de dados k de dados do centróide.
3, o conjunto de dados para cada ponto, para calcular a distância ao centróide cada (por exemplo, a distância Euclidiana), a partir do qual perto do centróide, para ser dividida no conjunto de centróide pertence.
4, depois de toda a boa recolha de normalização de dados, um total de conjuntos de k. E, em seguida, recalcular o centróide de cada set.
5, se a distância for menor do que alguma entre o novo centróide calculado e o centróide original de um valor limite ajustado (ou seja, não a posição recalculado mudança centróide, estabilizar, ou convergência), podemos assumir que o conjunto tenha sido atingido os resultados desejados, o algoritmo termina.
6, se o original e nova mudança distância centroid centroid muito, 3-5 requer um passo iterativo.
Em terceiro lugar, os princípios matemáticos

heuristicamente K-Means usa muito simples, com um conjunto de gráficos que serão descritos no seguinte imagem:
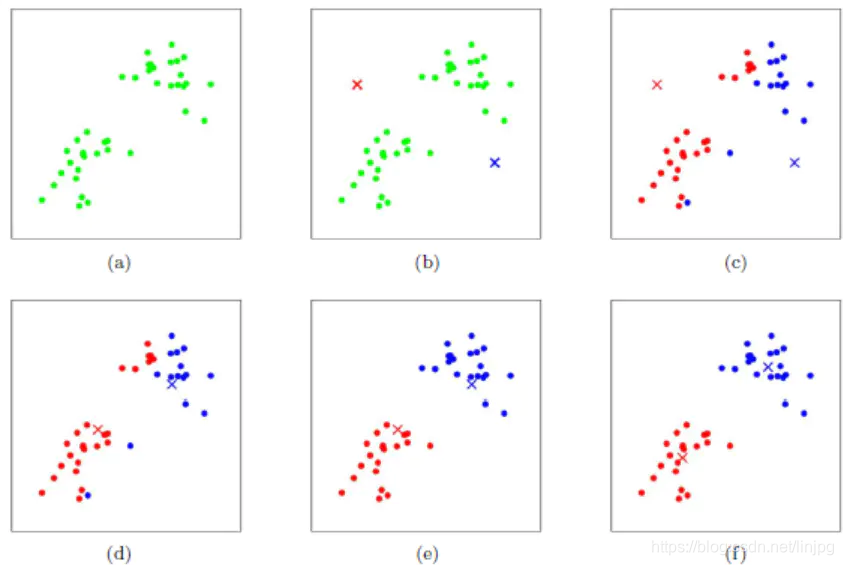
figura expressar um conjunto de dados iniciais, presume-se k = 2. Na figura b, seleccionámos aleatoriamente dois k classe correspondente ao centróide classe, isto é, o centróide vermelho da figura e o centróide azul e cada procurar distância, neste caso, todos os pontos de duas centroides, e marcar cada amostra a categoria da amostra e as menores categorias de distância centróide, como mostrado na FIG C, e depois a amostra é calculada a partir das centroides centróide vermelho e azul, que tem depois da primeira iteração para a categoria de todos os pontos de amostragem. Neste ponto, encontrar pontos vermelhos e azuis na nossa marca presente seus novos centroides são mostrados na FIG. D, ocorreu posição centróide da nova mudança centróide vermelho e azul. Figuras E e F na FIG c repetiu-se o processo e a d, isto é, todos os pontos marcados categoria categoria perto centróide e o centróide de novidade. Finalmente temos as duas categorias é mostrado na f.
Em quarto lugar, exemplos
Sistema de coordenadas tem seis pontos:
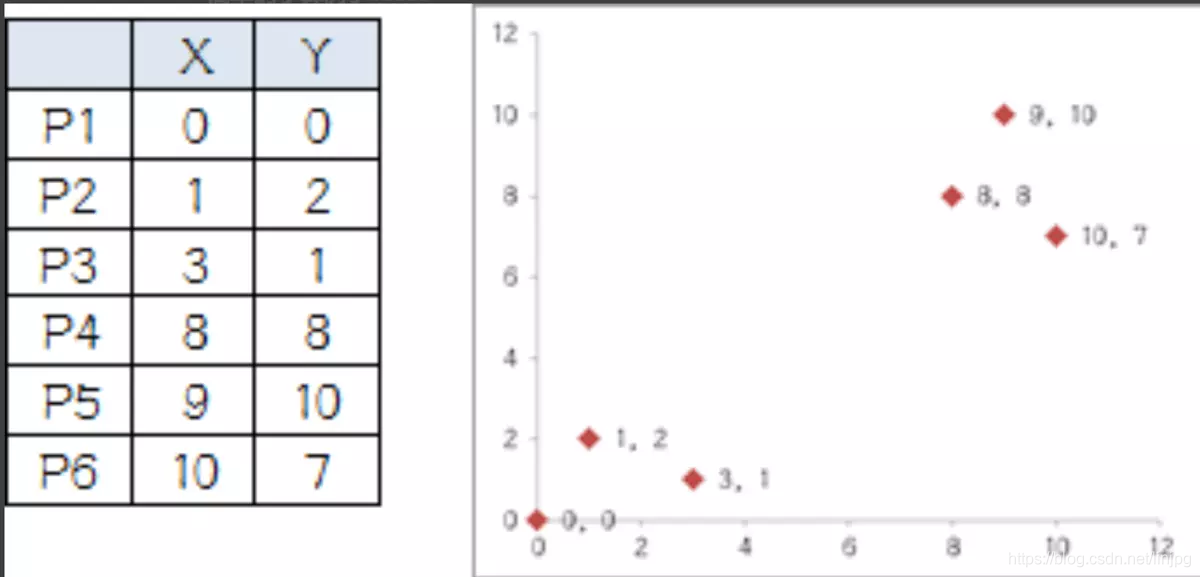
1, que dividida em dois grupos, de modo que K é igual a 2, seleccionámos aleatoriamente dois pontos: P1 e P2
2, os restantes pontos são calculados pelo teorema de Pitágoras para os dois pontos deste:

3, depois de o primeiro resultado agrupamento:
组A:P1
组B:P2、P3、P4、P5、P6
4, o cálculo do grupo A e do grupo B centróide:
A组质心还是P1=(0,0)
B组新的质心坐标为:P哥=((1+3+8+9+10)/5,(2+1+8+10+7)/5)=(6.2,5.6)
5, cada ponto é calculado novamente a distância centróide:
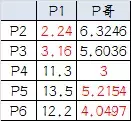
6, o resultado segundo agrupamento:
组A:P1、P2、P3
组B:P4、P5、P6
7, o centróide é calculado novamente:
P哥1=(1.33,1)
P哥2=(9,8.33)
8, de novo calculada para cada ponto da distância ao centróide:
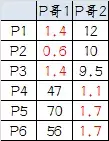
9, os resultados do terceiro agrupamento:
组A:P1、P2、P3
组B:P4、P5、P6
Podem ser encontrados, os resultados do terceiro grupo e os resultados do segundo grupo de explicação coerente convergiu agrupamento final.
Cinco, K-means vantagens e desvantagens
vantagens:
1, o princípio é simples, é muito fácil de alcançar a convergência rápida.
2, quando o resultado é um conjunto denso, ea diferença entre o cluster eo cluster, obviamente, é melhor.
3, os principais parâmetros precisa ajustar os parâmetros de apenas o número de grupos k.
desvantagens:
1, valor K exigido antecipadamente dado o valor estimado de K em muitos casos, é muito difícil.
2, K-means para seleccionar o centróide sensíveis, diferentes resultados iniciais obtidos agrupamento ponto semente aleatória é completamente diferente, uma grande influência nos resultados.
3, mais sensível ao ruído e outliers. Para a detecção de valores extremos.
4, método iterativo, pode ter apenas parcial solução óptima, mas não é possível obter a solução óptima global.
Sexto, detalhes
1, valor K dada como?
A: várias categorias, dependendo da experiência pessoal e sentimentos, a prática usual é tentar um valor K poucos, divididos em várias categorias olhar melhor interpretação dos resultados, mais em linha com o propósito de análise e assim por diante. Os vários valores de K, ou pode ser calculada para comparar E, K tem um valor mínimo de E.
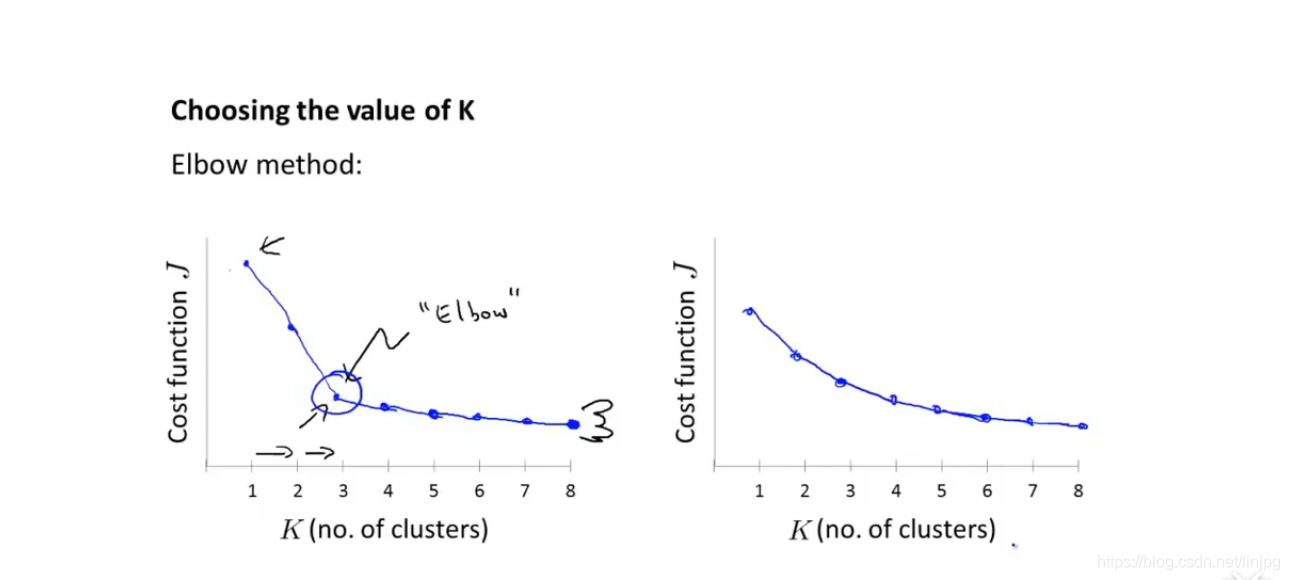
O professor pode referir-se a Andrew Ng disse que o vídeo dentro do método cotovelo, o custo de cada função para se mete em uma função, quando a curva torna-se suave, o número de K pode ser uma constante
2, a inicial K centróide como a eleição?
A: O método mais comum é a seleção aleatória, a seleção do centro inicial da massa do agrupamento final, afetar os resultados, de modo que o algoritmo deve executá-lo várias vezes, o que resulta mais razoáveis, que usará os resultados. Claro que existem alguns métodos de optimização, a primeira consiste em seleccionar um ponto mais afastado uma da outra, especificamente, para seleccionar o primeiro ponto e o segundo ponto é seleccionado a partir de quando o primeiro ponto mais distante, e seleccionar a terceira pontos, o terceiro ponto para a primeira, a segunda e a distância mínima entre dois pontos, e assim por diante. A segunda é a de obter os resultados de agrupamento com base em outros algoritmos de agrupamento (tais como agrupamento hierárquico), os resultados de cada categoria para escolher um ponto.
3, sobre os valores discrepantes?
A: O outlier está longe de ser o todo, muito incomuns, pontos de dados muito específicos antes da aglomeração desses valores atípicos deve ser "grande", "muito pequeno" e similares são removidos, caso contrário os resultados agrupamento afetados. No entanto, os outliers muitas vezes sobre o valor da sua própria análise, outliers podem ser analisados separadamente como uma classe.
4, a unidade para ser coerente!
A: Por exemplo, a unidade é m X, Y é os metros, a distância calculada em unidades ou arroz, faz sentido. Mas se X é m, Y t é calculada utilizando a fórmula de distância será "metros quadrados", com "toneladas de praça" para abrir a praça, a última coisa não é calculado sentido matemático, que é um problema.
5, a normalização
A: Se os dados X, como um todo, são relativamente pequenos, tais como o número situa-se entre 1 e 10, Y é grande, tal como o número é mais do que 1,000, então, o cálculo da distância Y quando o papel do que o grande X muitos, X distância do impacto é quase insignificante, é também um problema. dados Assim, se o cálculo da distância Euclidiana seleccionado a partir do agrupamento K-Means, o conjunto de dados tem aparecido no caso do acima exposto, deve ser normalizada (normalização), escalar os dados sobre a fazê-la cair uma seção específica pequena.
Referência K-Means algoritmo de agrupamento
[legendas em Inglês] cursos de aprendizagem de máquina Andrew Ng
