Resumo da primeira semana do segundo curso de Andrew Ng sobre aprendizagem profunda
Vamos primeiro ao índice:
No

índice, podemos ver que dois problemas foram resolvidos principalmente na primeira semana: overfitting e prevenção do desaparecimento/explosão do gradiente. Agora vamos discutir e implementar o código separadamente.
1. Desaparecimento/explosão de gradiente e soluções
Ao treinar uma rede neural, às vezes a derivada ou inclinação (dW, db) torna-se particularmente grande ou pequena, o que chamamos de explosão de gradiente ou desaparecimento de gradiente. Como resultado, o algoritmo de descida de gradiente demora mais ou até falha no treinamento. Para evitar esta situação, o método de inicialização de peso pode ser usado de forma que W não seja muito maior que 1 nem muito menor que 1.
Nos cursos anteriores, geralmente usamos o método np.random.randn() para inicializar a matriz de peso W, que faz amostragem da distribuição normal padrão unitária com média 0, mas com um determinado valor na rede neural como entrada da camada aumenta, a variância na distribuição dos dados de saída também aumentará, portanto, há um método de inicialização de peso aprimorado, ou seja, escalonando o vetor de peso de acordo com a raiz quadrada da entrada, cada neurônio A variância de saída é normalizada para 1 para garantir que todos os neurônios da rede sejam inicialmente distribuídos aproximadamente da mesma forma e melhorar empiricamente a velocidade de convergência.
Se a função de ativação for uma função tanh, a fórmula é:, isso é chamado de inicialização de Xavier;
Se a função de ativação for uma função relu, a fórmula é:, isso é chamado de inicialização de Xavier,
def init_parameters(layer_dims,initialization):
np.random.seed(3)
parameters = {}
if initialization=='zeros':
for i in range(1,len(layer_dims)):
parameters['W'+str(i)] = np.zeros((layer_dims[i],layer_dims[i-1]))
parameters['b'+str(i)] = np.zeros((layer_dims[i],1))
elif initialization=='random':
for i in range(1,len(layer_dims)):
parameters['W'+str(i)] = np.random.randn(layer_dims[i],layer_dims[i-1])
parameters['b'+str(i)] = np.zeros((layer_dims[i],1))
elif initialization=='he': #这是由He等人在所写的Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification论文中得到的结论
for i in range(1,len(layer_dims)):
parameters['W'+str(i)] = np.random.randn(layer_dims[i],layer_dims[i-1]) * np.sqrt(2/layer_dims[i-1])
parameters['b'+str(i)] = np.zeros((layer_dims[i],1))
else:
print("错误的初始化参数!程序退出")
exit()
assert(parameters['W'+str(i)].shape == (layer_dims[i],layer_dims[i-1]))
assert(parameters['b'+str(i)].shape == (layer_dims[i],1))
return parameters
1.layer_dims = [train_X.shape[0],10,10,1],learning_rate=0,5
- inicialização='zeros'
 Figura 1 curva de mudança de valor de custo
Figura 1 curva de mudança de valor de custo
|
 Figura 2 Resultados do treinamento
Figura 2 Resultados do treinamento
|
- inicialização='aleatório'
 Figura 1 curva de mudança de custos
Figura 1 curva de mudança de custos
|
 Figura 2 Resultados do treinamento
Figura 2 Resultados do treinamento
|
- inicialização='ele'
 Figura 1 curva de mudança de custos
Figura 1 curva de mudança de custos
|
 Figura 2 Resultados do treinamento
Figura 2 Resultados do treinamento
|
2.layer_dims = [train_X.shape[0],100,100,1],learning_rate=0,5
- inicialização='zeros'
|
Figura 1 curva de mudança de valor de custo
|
Figura 2 Resultados do treinamento
|
- inicialização='aleatório'
 Figura 1 curva de mudança de custos
Figura 1 curva de mudança de custos
|
 Figura 2 Resultados do treinamento
Figura 2 Resultados do treinamento
|
- inicialização='ele'
 Figura 1 curva de mudança de custos
Figura 1 curva de mudança de custos
|
 Figura 2 Resultados do treinamento
Figura 2 Resultados do treinamento
|
Pode-se observar que o termo de correção para multiplicar np.sqrt(2/layer_dims[n]) afeta principalmente o valor do custo inicial.Quando o número de neurônios em cada camada da rede é pequeno, multiplicar este termo terá um impacto maior no efeito final. O impacto é pequeno. À medida que o número de neurônios aumenta, o valor do custo inicial sem termos de correção aumenta gradualmente, e a assimetria dos resultados do treinamento torna-se cada vez mais óbvia. No entanto, à medida que o número de neurônios com o aumento dos prazos de correção, o treinamento final Os resultados não serão particularmente afetados.
2. Método de regularização
A primeira coisa a entender aqui é o conceito de viés e variação no aprendizado de máquina. De acordo com a explicação do Sr. Ng Enda, o desvio é o tamanho do erro do conjunto de treinamento e a variância é a comparação do tamanho do erro do conjunto de treinamento e do conjunto de teste. A figura mostra o mesmo conjunto de treinamento:
para concluir:
A precisão do conjunto de treinamento é um desvio baixo - alto.
Avalie o desempenho do conjunto de treinamento. Se o desvio for muito alto, pode ser necessário tentar substituí-lo por uma nova rede.
A precisão do conjunto de treinamento é muito alta, mas a precisão do conjunto de teste é baixa.O
primeiro é expandir seu próprio conjunto de dados e o segundo é a regularização.
La la la, vamos direto ao ponto! Como resolver o problema do overfitting por meio da regularização? Tomemos a regressão logística como exemplo.
1. Regularização L1/L2
Regularização é adicionar um termo de regularização à função de custo J. Existem dois termos comumente usados: regularização L1 e regularização L2.
-
Regularização L1
em:
-
Regularização L2
Entre eles:
Em relação à escolha de L1 e L2, segue uma citação do Professor Ng Enda:
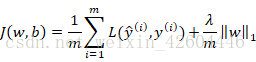
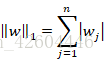
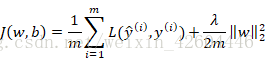
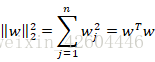
Se a regularização L1 for usada, W acabará sendo esparso, o que significa que há muitos 0s no vetor W. Algumas pessoas dizem que isso é benéfico para compactar o modelo, porque os parâmetros no conjunto são todos 0 e o modelo de armazenamento leva menos memória. Na verdade, embora a regularização L1 torne o modelo esparso, ela não reduz muito a memória de armazenamento, então acho que esse não é o propósito da regularização L1, pelo menos não compactar o modelo. As pessoas estão cada vez mais inclinadas a fazer isso ao treinar redes .Use regularização L2.
Adicione termos de regularização à função de custo da rede neural:
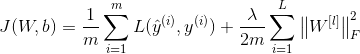
Porque W é um n [ l ] × n [ l − 1 ] n^{[l]}\times n^{[l-1]}n[ eu ]×nMatriz de [ l − 1 ] , n [ l ] n^{[l]}n[ l ] representao número de neurônios na camadaln [ l − 1 ] n^{[l-1]}n[ l − 1 ] representao número de neurônios na camadal-1
∑ i = 1 L ∥ W [ l ] ∥ F 2 = ∑ i = 1 n [ l ] ∑ j = 1 n [ l − 1 ] ( wij [ l ] ) 2 \sum_{i=1}^{L} \esquerda\| W^{[l]} \right \|_{F}^{2}=\sum_{i=1}^{n^{[l]}}\sum_{j=1}^{n^{[ l-1]}}(w_{ij}^{[l]})^2∑eu = 1eu∥∥C[ eu ]∥∥F2=∑eu = 1n[ eu ]∑j = 1n[ eu − 1 ]( weu j[ eu ])2
Ou seja, representa a soma de todos os elementos de uma matriz. Ao usar esta norma para implementar a descida gradiente, com base nos resultados originais, um termo regular precisa ser adicionado para obter a derivada parcial de w, ou seja
d W [ l ] = ∂ L ∂ W [ l ] + λ m W [ l ] dW^{[l]}=\frac{\partial L}{\partial W^{[l]}}+\frac{ \lambda}{m}W^{[l]}d W[ eu ]=∂ W[ eu ]∂ eu+eueuC[ eu ]
Atualização de peso:
W [ l ] = W [ l ] − α d W [ l ] = W [ l ] − α ( ∂ L ∂ W [ l ] + λ m W [ l ] ) = ( 1 − α λ m ) W [ l ] − α d W [ l ] W^{[l]}=W^{[l]}-\alpha dW^{[l]}=W^{[l]}-\alpha(\frac{\partial L}{\partial W^{[l]}}+\frac{\lambda }{m}W^{[l]})=(1-\frac{\alpha \lambda }{m})W^{ [l]}-\alfa dW^{[l]}C[ eu ]=C[ eu ]-αdW _ _[ eu ]=C[ eu ]-um (∂ W[ eu ]∂ eu+eueuC[ eu ] )=( 1-euum eu) W[ eu ]-αdW _ _[ eu ]
Como pode ser visto na fórmula acima, a regularização tenta fazer W [ l ] W^{[l]}C[ l ] é multiplicado por um coeficiente de peso menor que 1, tornando-o menor, então a regularização L2 também é chamada de "decadência de peso". Para razões específicas pelas quais a regularização é benéfica para prevenir overfitting, consulte a Seção 1.5 da primeira semana do segundo curso (link de referência: http://www.ai-start.com/dl2017/html/lesson2-week1.html# cabeçalho -n89).
Vamos dar uma olhada em como implementá-lo usando código e qual é o efeito?
Tomemos a segunda classificação como exemplo. Para tornar o efeito mais óbvio, alteramos para outro conjunto de dados (link de referência: https://blog.csdn.net/weixin_42604446/article/details/81369224)
 Figura 1 Conjunto de treinamento
Figura 1 Conjunto de treinamento
|
 Figura 2 Conjunto de testes
Figura 2 Conjunto de testes
|
Código de referência:
def datagen(m,lambd,is_plot):
np.random.seed(1)
N = int(m/2) #分为两类
D = 2 #样本的特征数或维度
X = np.zeros((m,D)) #初始化样本坐标
Y = np.zeros((m,1)) #初始化样本标签
for j in range(2):
ix = range(N*j,N*(j+1))
t = np.random.randn(N)*lambd
r = np.random.randn(N)*lambd
if j==0:
X[ix] = np.c_[t-0.4, r-0.4]
else:
X[ix] = np.c_[t+0.4, r+0.4]
Y[ix] = j #red or blue
if is_plot:
fig = plt.figure()
plt.rcParams['figure.figsize']=(7.0,4.0)
plt.rcParams['image.interpolation']='nearset'
plt.rcParams['image.cmap']='gray'
plt.title('training dataset')
plt.scatter(X[:, 0], X[:, 1], c=np.squeeze(Y), s=40, cmap=plt.cm.Spectral)
plt.show()
return X.T,Y.T
Código atualizado após adicionar regularização:
- Calcular custo
def compute_cost_with_regulation(A,Y,parameters,lambd):
m = Y.shape[1]
sum = 0.
cross_entropy_cost = compute_cost(A[len(A)-1],Y)
for i in range(len(A)):
sum += np.sum(np.square(parameters["W"+str(i+1)]))
L2_regularization_cost = lambd * sum / (2 * m)
cost = cross_entropy_cost + L2_regularization_cost
return cost
- Retropropagação
def backward_propagation_with_regulation(X,Y,Z,A,W,lambd,derivate_function):
l = len(W)
dZ = list(range(l))
dA = list(range(l))
dW = list(range(l))
db = list(range(l))
m = Y.shape[1]
grads = {}
dZ[l-1] = A[l-1] - Y
for i in range(l-1,-1,-1):
if i>0:
dW[i] = (1/m)*np.dot(dZ[i],A[i-1].T) + ((lambd * W[i] / m))
else:
dW[i] = (1/m)*np.dot(dZ[i],X.T) + ((lambd * W[i] / m))
db[i] = (1/m)*np.sum(dZ[i],axis=1,keepdims=True)
dA[i-1] = np.dot(W[i].T,dZ[i])
dZ[i-1] = np.multiply(dA[i-1],np.int64(A[i-1]>0))
for i in range(len(dW)):
grads["dW"+str(i+1)] = dW[i]
grads["db"+str(i+1)] = db[i]
return grads
Vamos dar uma olhada nos resultados experimentais:
- Nenhuma regularização adicionada
 Figura 1 Resultados da classificação do conjunto de treinamento
Figura 1 Resultados da classificação do conjunto de treinamento
|
 Figura 2 Resultados da classificação do conjunto de testes
Figura 2 Resultados da classificação do conjunto de testes
|
- Adicione regularização, λ = 0,5 \lambda =0,5eu=0 . 5
 Figura 1 Resultados da classificação do conjunto de treinamento
Figura 1 Resultados da classificação do conjunto de treinamento
|
 Figura 2 Resultados da classificação do conjunto de testes
Figura 2 Resultados da classificação do conjunto de testes
|
2. O princípio da regularização do dropout
é definir a probabilidade de eliminação de nós em cada camada da rede neural. Em seguida, o dropout percorrerá cada camada da rede e reterá e eliminará aleatoriamente os nós correspondentes com a probabilidade definida e, finalmente, obterá um nó com menos nós. , redes menores. Como cada nó tem a mesma possibilidade de ser eliminado, evita que a rede neural dependa de determinados nós específicos, reduzindo assim a variância, comprimindo pesos e evitando o sobreajuste.
|
|
|
O método mais comumente usado para implementar o dropout é o dropout invertido (desativação aleatória reversa). Este método requer definir a probabilidade de desativação para cada camada da rede, representada por keep-prob. Por exemplo, keep-prob = 0,8 e, em seguida, elimine qualquer unidade A probabilidade é 0,2. Tome uma rede de três camadas como exemplo:
primeiro defina um vetor d. Se o dropout for implementado na terceira camada da rede, então:
d 3 = np . random . rand ( A [ 3 ] . shape [ 0 ] , A [ 3 ] .forma [ 1 ] ) <manter − prob d3=np.random.rand(A^{[3]}.forma[0],A^{[3]}.forma[1])< manter-probd3 _=np . _ aleatório . _ _ _ _ _ r e d ( A _[ 3 ] . forma[0],____A[ 3 ] . forma[1])____<k e e p-p r o b
A [ 3 ] = np . multiplicar ( A [ 3 ] , d 3 ) / manter − prob A^{[3]}=np.multiply(A^{[3]},d3)/keep-probA[ 3 ]=np . _ m u l t i p l y ( A[ 3 ] ,d 3 ) / k e e p-p r o bO
d3 obtido pela fórmula na primeira linha é uma matriz booleana e o valor é True ou False.<keep-prob significa que se for menor que keep-prob, será definido como True, e se é maior que keep-prob, será definido como False.A segunda linha A fórmula é para eliminar os nós correspondentes, e dividir por keep-prob é para compensar a parte eliminada, de modo que A [ 3 ] A^ {[3]}AO valor esperado de [ 3 ] permanece inalterado.
Vamos dar uma olhada em como implementá-lo com código e os resultados experimentais (ainda tomando o conjunto de treinamento na regularização L2 como exemplo):
O dropout não é implementado para a última camada e os códigos para propagação direta e retropropagação são os seguintes:
- propagação direta
def forward_propagation_with_dropout(X,parameters,activate_fun,keep_prob):
#retrieve parameters
W = []
b = []
for i in range(1,len(parameters)//2+1):
W.append(parameters["W"+str(i)])
b.append(parameters["b"+str(i)])
#compute forward_propagation
Z = []
A = []
D = []
for i in range(len(W)):
if i==0:
sZ = np.dot(W[i],X)+b[i]
else:
sZ = np.dot(W[i],A[i-1])+b[i]
sA = activate_fun[i](sZ)
if i<(len(W)-1):
sD = np.random.rand(sA.shape[0],sA.shape[1]) < keep_prob
sA = np.multiply(sA,sD) / keep_prob
Z.append(sZ)
A.append(sA)
D.append(sD)
return Z,A,W,D
- Retropropagação
def backward_propagation_with_dropout(X,Y,Z,A,W,D,keep_prob):
l = len(W)
dZ = list(range(l))
dA = list(range(l-1))
dW = list(range(l))
db = list(range(l))
m = Y.shape[1]
grads = {}
dZ[l-1] = A[l-1] - Y
for i in range(l-1,0,-1):
if i>0:
dW[i] = (1/m)*np.dot(dZ[i],A[i-1].T)
else:
dW[i] = (1/m)*np.dot(dZ[i],X.T)
db[i] = (1/m)*np.sum(dZ[i],axis=1,keepdims=True)
dA[i-1] = np.dot(W[i].T,dZ[i])*D[i-1]/keep_prob
dZ[i-1] = np.multiply(dA[i-1],np.int64(A[i-1]>0))
for i in range(len(dW)):
grads["dW"+str(i+1)] = dW[i]
grads["db"+str(i+1)] = db[i]
return grads
Resultados do treinamento:
- Não implemente dropout, ou seja, keep_prob=1
 Figura 1 Resultados da classificação do conjunto de treinamento
Figura 1 Resultados da classificação do conjunto de treinamento
|
 Figura 2 Resultados da classificação do conjunto de testes
Figura 2 Resultados da classificação do conjunto de testes
|
- Implementar abandono, keep_prob=0,6
 Figura 1 Resultados da classificação do conjunto de treinamento
Figura 1 Resultados da classificação do conjunto de treinamento
|
 Figura 2 Resultados da classificação do conjunto de testes
Figura 2 Resultados da classificação do conjunto de testes
|
Como pode ser visto na figura acima, se a regularização do dropout não for implementada, ocorrerá o problema de overfitting, mas após a implementação do dropout, o overfitting será basicamente eliminado.
Terminar! ! !
Download de recursos relacionados: https://download.csdn.net/download/weixin_42149550/11666926
******************************* **************************** Esta é a linha divisória ***************** *************************************************
Em anexo:
- Corrigida a seção backward_propagation da tarefa da terceira semana do primeiro curso
def backward_propagation_with_regulation(X,Y,Z,A,W,lambd):
l = len(W)
dZ = list(range(l))
dA = list(range(l-1)) #更正前为dA = list(range(l)),实际需要记录的dA不需要包括最后一层,因为代码直接算出了最后一层的dZ
dW = list(range(l))
db = list(range(l))
m = Y.shape[1]
grads = {}
dZ[l-1] = A[l-1] - Y
for i in range(l-1,0,-1): #更正前为 range(l-1,-1,-1),后面计算的dA,dZ的索引值包括i-1,如果为-1,最后dA的索引就有负数了,显然不行
if i>0:
dW[i] = (1/m)*np.dot(dZ[i],A[i-1].T) + ((lambd * W[i] / m))
else:
dW[i] = (1/m)*np.dot(dZ[i],X.T) + ((lambd * W[i] / m))
db[i] = (1/m)*np.sum(dZ[i],axis=1,keepdims=True)
dA[i-1] = np.dot(W[i].T,dZ[i])
dZ[i-1] = np.multiply(dA[i-1],np.int64(A[i-1]>0))
for i in range(len(dW)):
grads["dW"+str(i+1)] = dW[i]
grads["db"+str(i+1)] = db[i]
return grads
- Como centralizar várias imagens lado a lado no editor Markdown?
<table>
<tr>
<td ><center><img src="https://img-blog.csdnimg.cn/20190904211338386.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MjE0OTU1MA==,size_16,color_FFFFFF,t_70" width=480 >图1 训练集分类结果</center></td>
<td ><center><img src="https://img-blog.csdnimg.cn/2019090421135561.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MjE0OTU1MA==,size_16,color_FFFFFF,t_70" width=480 >图2 测试集分类结果</center></td>
</tr>