rede neural totalmente conectado e rede neural convolução, que só pode ter um único processo de entrada por um, após uma entrada anterior e a entrada é totalmente irrelevante. No entanto, algumas tarefas precisa ser capaz sequência de processamento de uma melhor informação, isto é, a entrada e a frente de entrada do último, existe uma relação. Por exemplo, quando entendemos o significado de uma frase, isolada entender cada palavra desta frase não é suficiente, temos de lidar com toda a seqüência dessas palavras são ligados entre si; quando lidamos com o vídeo, não podemos simplesmente ir sozinho analisa cada quadro, e para analisar toda a sequência dos quadros são ligados entre si. Neste ponto, você precisa usar a profundidade de campo de estudo é importante em outro tipo de redes neurais: rede neural recorrente (Recurrent
Neural da rede).
RNN frequentemente usado em seqüência linguagem de processamento de um computador para entender a semântica de uma sentença, e de acordo com o texto antes e depois de entender a semântica alcançar os resultados que queremos.
rede neural cíclica básica
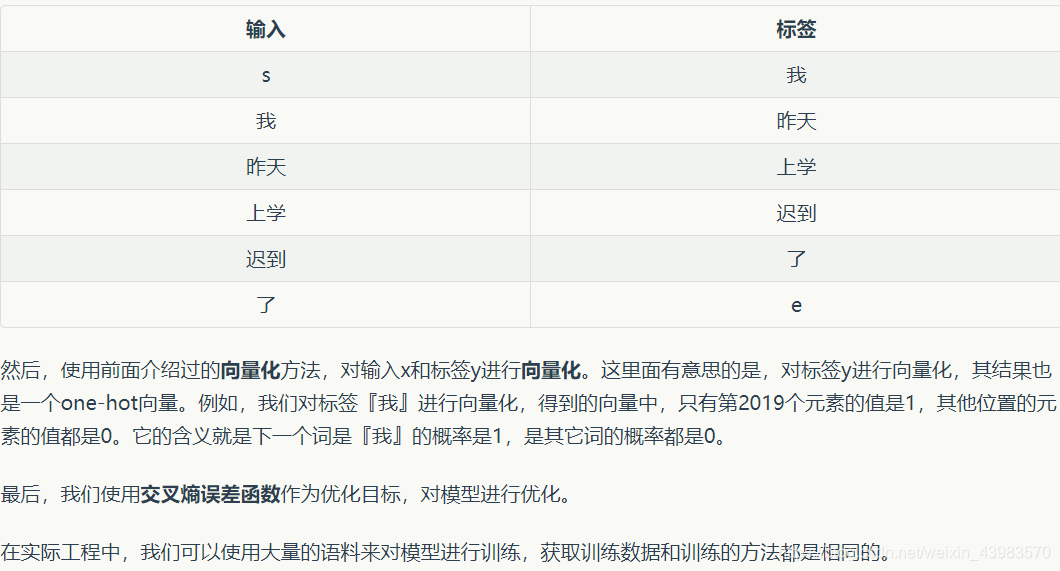
Abaixo está um circuito simples tais como uma rede neural, que consiste de uma camada de entrada, uma camada oculta e uma camada de saída:
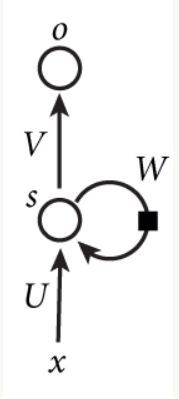
A figura pode ser visto implementado como um redes neurais totalmente ligados, mas na saída camada escondida serão tomadas quando o valor de saída armazenados em um nó, e isto constitui a entrada para fazer este cálculo na próxima camada oculta o valor da entrada de treinamento e o valor corrente de saída, e então armazenada no nó de saída quando a corrente de saída para fornecer a próxima utilização.
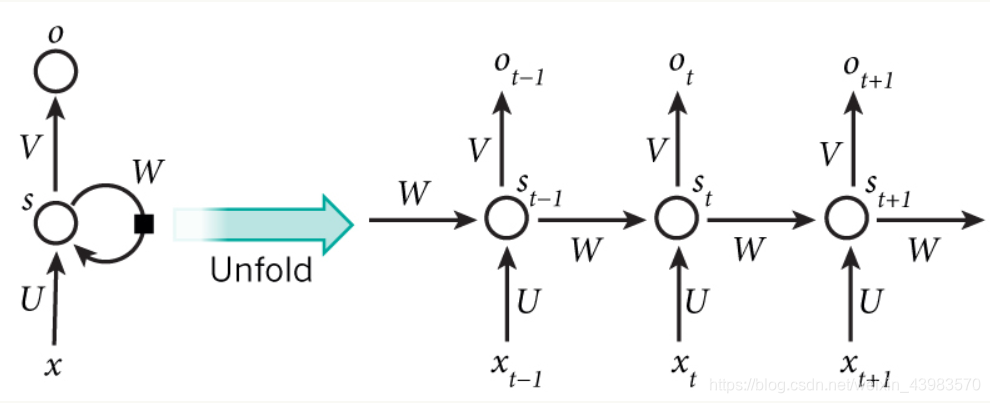
上图为每一次训练的过程,每次训练都会将输出作为下一次输入的参数,由此可提取出公式:
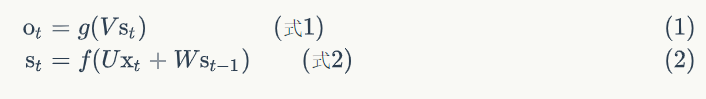
Fórmula 1 fórmula é a camada de saída, a camada de saída é uma camada completamente ligada, isto é, cada um dos seus nós e cada nó está ligado à camada escondida. V é a matriz de peso camada de saída, g é a função de activação. A equação 2 é calculada na camada oculta, a qual camada é cíclico. U é a matriz de entrada x peso de peso, W é o último valor de S (t-1) introduzido desta vez como o peso da matriz de ponderação, f é a função de activação.
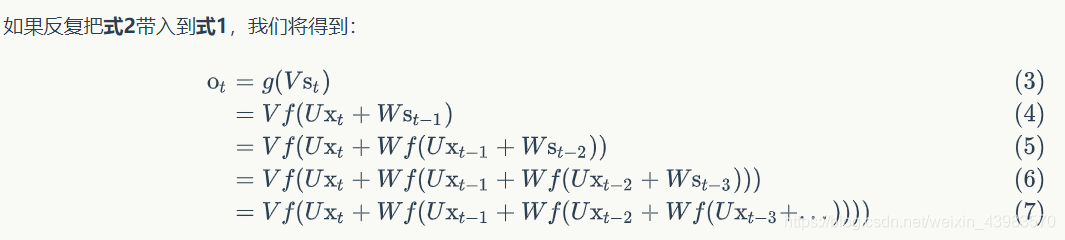
Mas só rede unidirecional RNN não é suficiente útil porque as necessidades sentença a ser definido de acordo com a semântica do texto antes e depois, em vez de simplesmente definir pelo acima exposto, existem rede neural, assim, de mão dupla circular
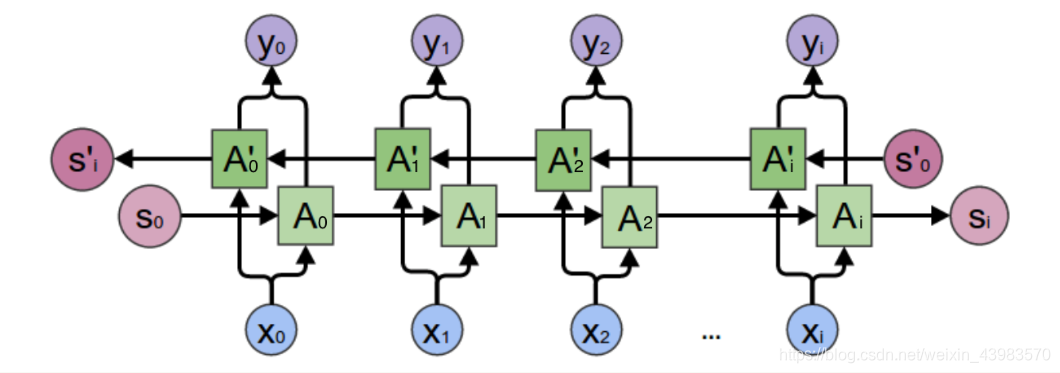
no qual as necessidades de informação de saída para armazenar dois nós , um e A`, um para a propulsão para a frente, uma para a propulsão inversa, a saída final depende de dois nós de armazenamento, o qual com uma palavra que tem a mesma semântica para seguir o texto.



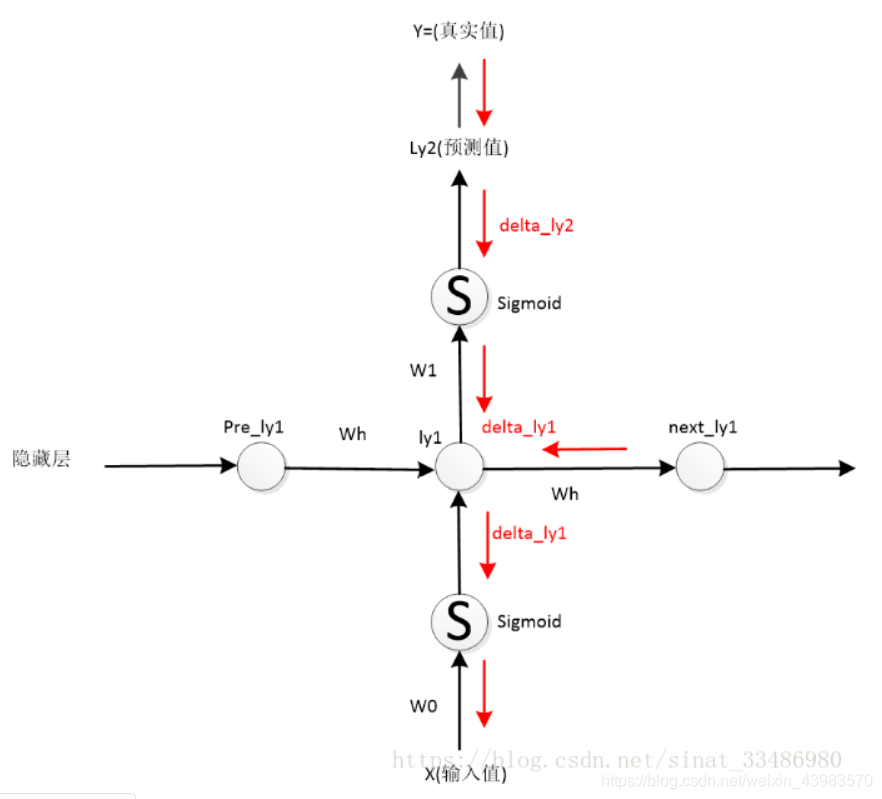
propagação para a frente (direcção indicada pela seta preta):
x de entrada,
camada escondida: Ly1 = sigmóide (x * W0) + pre_ly1 * Wh,
Consiste em duas partes, uma parte é o valor de entrada por um peso, e, em seguida, através de uma função de activação (sigmóide expressa aqui utilizado temporariamente), a outra parte é a camada da frente é uma resultados escondidos estado guardados.
camada de saída: LY2 = sigmóide (Ly-1 * w1),
Multiplicando a saída a partir dos valores de peso e da camada de saída escondidos, obtida através da função de activação.
procedimento volta-propagação (direcção da seta vermelha):
O valor real de Y, o valor previsto de saída do LY2 camada de saída, tanto a diferença: Y-LY2 = err, calculado erro total Err = 1/2 (Y-LY2) ^ 2, que é o erro quadrado. O passo seguinte é a utilização do derivado de cadeia regra, uma propagação de erro voltar, em primeiro lugar, a saída a partir da última LY2 erro, derivados parciais Err LY2 é calculado para obter:
delta_ly2 = (Y-LY2) * sigmóide '(LY2),
Note-se que esta função é um derivado de LY2 sigmóide. E Y-LY2 = err, assim ERR = delta_ly2 sigmóide (LY2), o seguinte erro da camada oculta é calculada, pode ser visto a partir do desenho, a passagem inversa através da camada escondida existem dois erros, um é um estado escondido depois camada de erro (propagação para trás para os próximos necessidades estaduais para retornar a um estado anterior): next_ly1 Wh, e o outro é transmitido a saída de erro camada: delta_ly1 delta_ly2 = W1 de sigmóide '(lyi),
Esta equação é derivada da regra da cadeia, cada passo requer o cálculo do erro actual multiplicada pelo passo anterior de erro, de modo que há uma delta_ly2, porque então sigmóide = LY2 (lyi W1 de), de acordo com a regra da cadeia para calcular LY2 lyi derivados obter W1 de singmoid '(lyi).
Semelhante a retropropagação totalmente ligado, mas após a introdução da influência de um contra-propagação na camada escondida propagação.
Entretanto, quando a sequência é demasiado longo propenso a gradiente de explosão ou desaparece inclinação, porque a perda de função é uma função exponencial, pode levar a aumentar ou diminuir o valor do parâmetro é muito grande, a explosão ocorreu gradiente ou desaparece gradiente.
palavra vetorização
entrada de rede neural é a palavra, podemos entrar vetorização utilizando os seguintes passos:
1, para criar um dicionário contendo todas as palavras, cada palavra no dicionário que tem um número único.
2, uma palavra pode ser qualquer vector um-quente com uma N-dimensional que representa. Em que, n é o número de palavras contidas no dicionário. Palavra número em um vetor-quente, a posição 1 está localizado, as restantes posições são 0
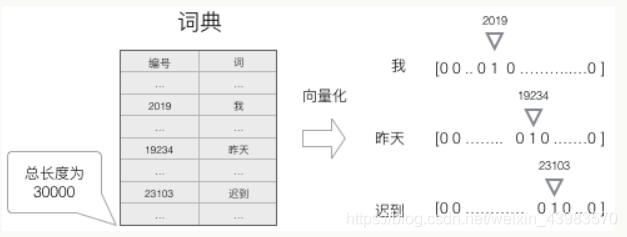 O uso deste método para quantificar, obtemos um escasso vector de alta-dimensional (esparso refere-se ao valor da maior parte dos elementos é 0). Ela exige um método especial para reduzir a dimensionalidade.
O uso deste método para quantificar, obtemos um escasso vector de alta-dimensional (esparso refere-se ao valor da maior parte dos elementos é 0). Ela exige um método especial para reduzir a dimensionalidade.
função de probabilidade softmax é então usado para calcular o próximo mandato, os
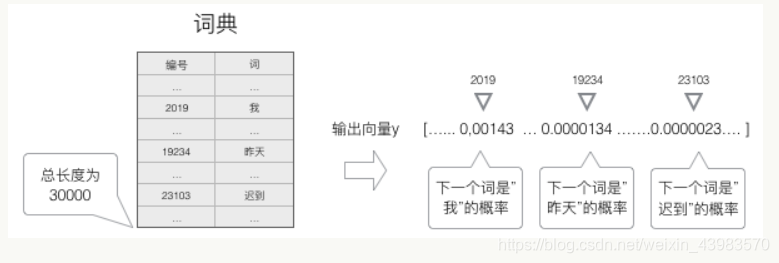
treinamento do modelo
necessidades modelo de treinamento para ser treinados e, em seguida, colocado no modelo de segmentação declaração, digite uma palavra antes, e depois de uma palavra como um estudo de rótulo