

著者 | いつか
導入
この記事では主にビジネス インテリジェンス (BI) とチューリング データ分析 (TDA) の概念と応用について紹介します。 BI は、データを収集、整理、分析、提示することにより、企業がより適切な意思決定と戦略計画を立てるのに役立ちます。しかし、従来のBI構築の考え方には、ビジネスによるデータ要件の変更に伴う再開発の必要性や、基盤となるデータの分析効率の低さなどの問題がありました。そこで、TDAは、詳細なデータをもとに分析テーマに応じた公開データセットを構築し、ワンクリックで結果を保存し、共有することもできるワンストップのセルフサービス分析プラットフォームとして登場しました。その他は閲覧用です。ただし、TDA の構築は、包括的な分析ディメンション指標、正確なデータ品質、クエリ パフォーマンスなどの課題にも直面しています。これらの課題に対応するため、私たちは完全性、正確性、効率性、速度という目標を掲げ、MPP データ エンジンだけでなくプロセス メカニズムと機能構築を通じてこれらの目標を達成します。
全文は 4766 ワードで、推定読了時間は 15 分です。
01 背景と目的
BI は Business Intelligence の略で、データを収集、整理、分析、提示することで、企業が競合他社に先んじて、より適切なビジネス上の意思決定と戦略的計画を立てるのに役立ちます。収集と整理のプロセスはデータ ウェアハウスの構築であり、データの分析と提示は視覚的な分析プラットフォームの構築です。
業界で一般的な BI 構築のアイデア: 企業が特定の指標のデータ変更を確認したい場合、データ RD は ODS > DWD > DWS > ADS とレイヤーごとにモデル化され、その後カスタマイズされます。 ADS 結果テーブルは Palo/Mysql で開発および実装され、最終的に複数のグラフを構成してビジネス表示用にレポートに保存します。この構築アイデアは企業のデータ分析ニーズを満たしていますが、次の 2 つの問題に直面しています。 1. 企業がデータ要件を変更すると、ADS 結果テーブルを再度カスタマイズして開発する必要があり、研究開発の人的資源を繰り返し消費することになります。 2. 問題を解決するだけです。ビジネス分析の問題。変動の原因をさらに掘り下げて分析したい場合は、基になるテーブルが現在のチャート データのみを含む集計テーブルであるため、分析する必要がある場合はダウンロードするしかありません。詳細なデータを取得して Excel などの方法で分析することは、比較的非効率的です。
TDA (Turing Data Analysis) は、BI における長い分析リンクの問題を解決するために構築されたワンストップのセルフサービス分析プラットフォームです。
TDAの構築思想:DWDの詳細ワイドテーブルをベースに、分析テーマに応じた公開データセットを構築(1日のデータは数千万件以上)、ユーザーは公開データセットをもとにドラッグ&ドロップで分析可能。分析結果は自由に個人ダッシュボードに保存したり、ワンクリックで公開したりできます。パブリック ダッシュボードを作成して他のユーザーと共有し、パブリック ダッシュボードで変動傾向を確認し、ビジュアル分析ページにドリルダウンして調査を続けることができます。変動の原因を探り、「傾向を見る・次元を分解する・細部を知る」をワンストップで分析できる3つの軸。
次の図は、TDA 構築のアイデアの全体的なプロセスを示しています。
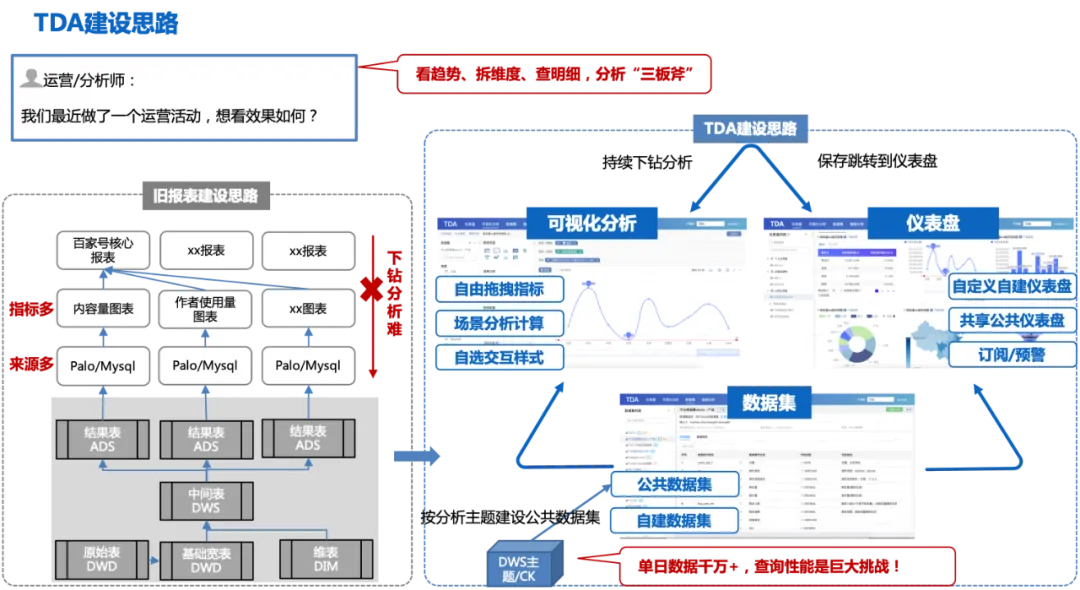
この建設アイデアには、次のようないくつかの課題もあります。
1. 分析ディメンション指標は完全でなければなりません。そうでない場合は、複数のデータセットを構築する必要があり、その結果、多数の分散したデータセットが生成され、前のレポート構築と同じ問題が発生します。
2. データ校正は正確かつ信頼できるものでなければなりません。
3. 1 日に数千万のデータがあるため、クエリのパフォーマンスは大きな課題です。
上記の課題に対応して、効率的なビジネス分析のニーズを満たすために、対応する目標も策定しました。
1. 完了 (分析ディメンション指標は完全であり、ビジネス ニーズの 80% 以上をカバーしている必要があります)。
2. 正確(均一な口径、正確なデータ)。
3.適時性(データ出力の適時性はT+10hです)。
4. 高速 (10 秒以内に 10 億レベルのデータクエリ)。
TDA プラットフォームは、プロセス メカニズムと機能構築の観点から完全かつ正確かつ効率的なデータ セット構築を保証し、MPP データ エンジンと組み合わせてクエリ パフォーマンスを確保し、BI のビジュアル ドラッグ アンド ドロップ、シーン分析、セルフサービス モデリングおよびその他の機能。
02 技術的ソリューション
上記の分析に基づいて、TDA の製品ポジショニングは、ユーザーが自由にデータ セットをドラッグ アンド ドロップし、視覚的なデータ分析を実行し、コア ダッシュボードを構築できるワンストップのセルフサービス クエリを実現できる BI プラットフォームです。ユーザーが次の観点からクエリ分析のワンストップ エクスペリエンスを実現できるように支援します。
ビジネスカンバンの繰り返しと効率化(セルフサービス):データレポートの繰り返しモードが変更され、PMリクエストRDスケジューリングモードから段階的にPM/オペレーションセルフサービスオペレーション(カンバン作成/データ分析)に変換されます。
データ洞察分析効率の向上 (非常に高速) : 単一のデータクエリが数分から数秒に短縮され、指標変動分析の効率が 20 倍向上し、単一指標変動属性のエンドツーエンド分析が 2 時間以内に完了します。 -> 5分。
ワンストップのセルフサービスビジネス分析 (ワンストップ) : データ傾向の観察、次元ドリルダウン分析、詳細エクスポートなどの機能を実現し、データ監視とデータ分析の統合されたエクスペリエンスを実現します。
本製品の機能マトリクスは以下の通りです。
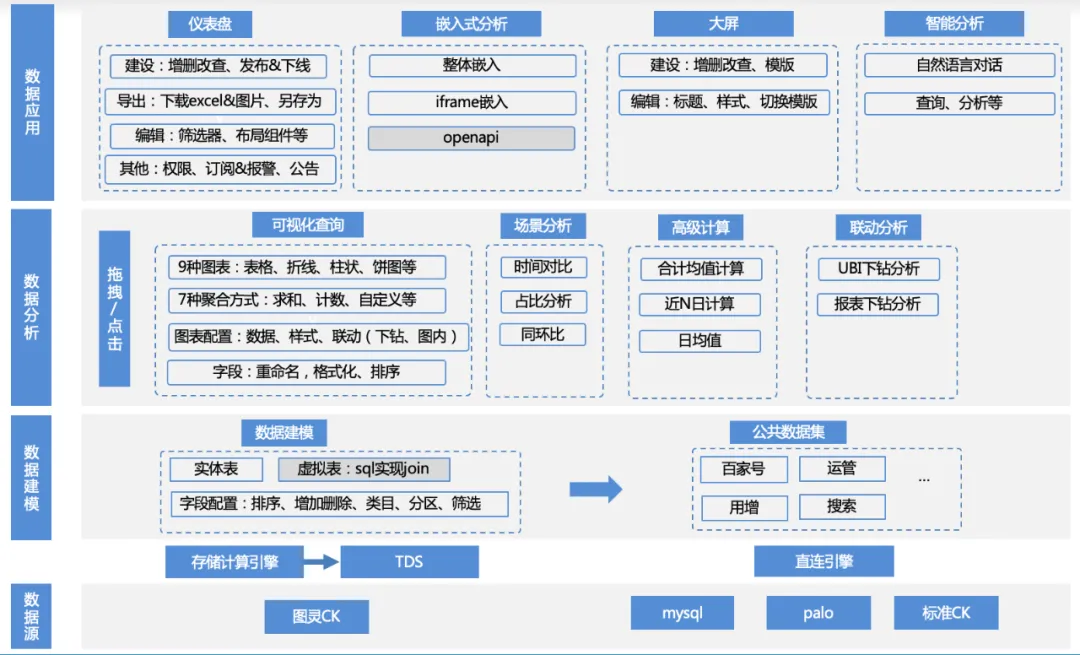
1. データ ソース アクセス: 企業は TDS を使用して、計算エンジンを通じて上流のチューリング テーブル データを計算し、そのデータを clickhouse/mysql/palo などのエンジンに書き込み、直接接続を通じてそれにアクセスするか、企業が独自の palo を提供します。 /mysqlデータソースへのアクセス。
a. データ ソース管理: データ ソースの追加、削除、変更、クエリ、クリックハウス/mysql/palo およびその他のエンジン ドライバーの適応
2. データ モデリング: データ ソースに接続した後、SQL を記述して元のテーブルから直接データを製品にロードできます。ただし、これらのテーブルは通常、分析可能なデータ セットに変換するための単純な二次処理が必要です。
a. データセット管理: 追加、削除、変更、データプレビュー、スキーマ表示、ワンクリック視覚分析などの機能。
b. データセットフィールドの管理: 追加、削除、変更、フィールドの並べ替え、カスタムフィールドなど。
c. データセットのカテゴリ管理: フィールドが属するカテゴリの追加、削除、変更、カスタム並べ替えなど。
d. データセットディレクトリ管理: データセットディレクトリの追加、削除、変更、カスタムソートなど。
3. データ分析:データセットに基づいて、ユーザーはインジケーター、ディメンション、フィルターを自由にドラッグアンドドロップし、適切なチャートの種類とシナリオ分析方法を選択し、分析と計算を実行できます。
a. データ構成: データセットの切り替え、カスタムフィールドの追加
b. グラフの設定: 表、折れ線グラフ、棒グラフ、円グラフ、その他のグラフの種類の設定、凡例の色の設定、データ形式の設定など。
c. シナリオ分析: 日次平均値、前年比、割合、合計などの複数のシナリオ分析機能をサポートします。
d. アトリビューション分析: セルフサービスのアトリビューション分析機能
e. インタラクティブ分析:ドリルダウン分析など
4. データアプリケーション:ユーザーは分析結果をダッシュボードに保存したり、サードパーティのプラットフォームに埋め込んだり、大画面に保存したり、インテリジェントな分析に直接使用したりできます。
a. ダッシュボード管理: ダッシュボードの追加、削除、変更、カスタム並べ替え、公開とオフライン、データのエクスポート、サブスクリプション アラートなど。
b. 埋め込み分析: ifame 埋め込み、SDK 埋め込み、およびその他の埋め込みモード
c. 大画面: リアルタイム大画面
d. インテリジェント分析: LUI 会話分析
2.1 全体設計
TDA の全体的なアーキテクチャを次の図に示します。
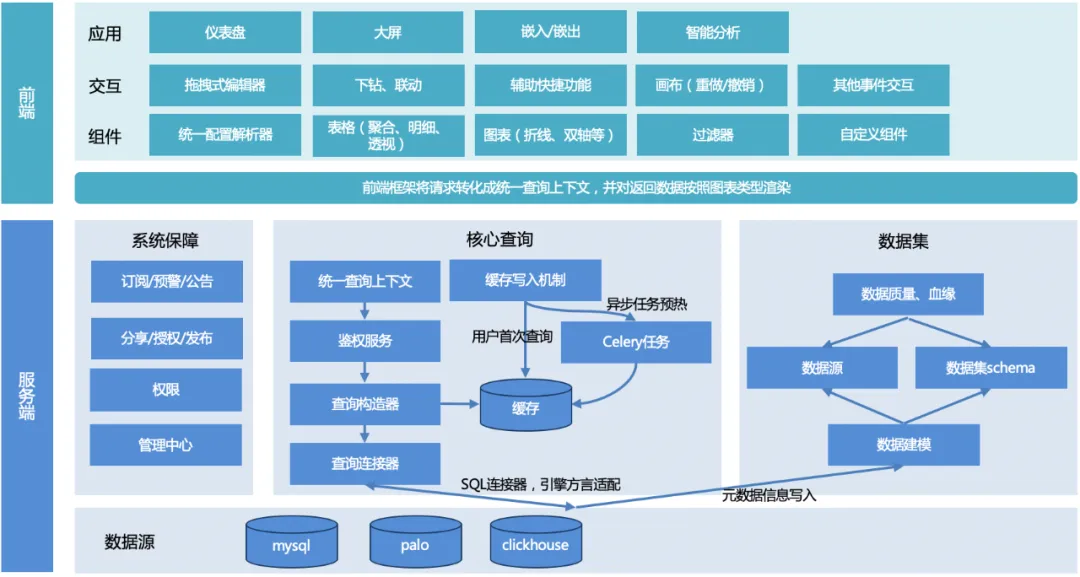
全体的なプロセス: ユーザーがクエリを開始し、サーバーがクエリ コンテキストを統合し、クエリ オブジェクトを構築し、基礎となるエンジン言語を適応させ、統一されたデータ形式を返します。その後、フロントエンド レンダリング フレームワークがグラフの種類に応じて適応してレンダリングします。 。
サーバ:
1. 統一されたクエリ コンテキスト: 後で他のチャート機能を拡張するときに共通関数の再利用を容易にするために、統一されたクエリ コンテキストが設計されています。
2. クエリ コンストラクター: リクエストに従ってクエリ オブジェクトを構築します (複数にすることができます。たとえば、テーブルをページ分割するには、2 つのクエリ オブジェクトを構築する必要があります。1 つはページング クエリ オブジェクトで、もう 1 つはカウント クエリ オブジェクトです)。フロントエンドから渡されるパラメータ。
3. クエリコネクタ:
a. 現在のところ、SQL クエリのエンジン (mysql、palo、clickhouse など) を満たすために使用される SQL コネクタのみがあり、エンジン、構文、または一部の機能が異なる場合があり、それらは異なるエンジンを通じて適合させる必要があります。ルール構成。
b. 将来、非 SQL クエリを満たすために他のコネクタを拡張することができます。
4. キャッシュ書き込み: クエリのパフォーマンスを確保するには、ユーザーが初めてアクセスするときに書き込む方法と、セロリのスケジュールされたタスクを通じてキャッシュを予熱する方法の 2 つの書き込み方法があります。
5. データセットモジュール: データサポートを提供し、基礎となるデータソースとのリンクを確立し、データ品質を保証します。
6. システム保証モジュール: サブスクリプション、早期警告、およびアナウンスにより、データの共有、公開、および承認機能が実現され、管理センターと権限によりデータの基本的な管理と権限のサポートが提供されます。
フロントエンド:
1. コンポーネント ライブラリ: 構成分析、さまざまなチャート レンダリング コンポーネント、フィルター コンポーネント、およびカスタム コンポーネント機能を提供します。
2. インタラクション: ドラッグ アンド ドロップ エディター、ドリルダウン リンク、補助ショートカット機能、キャンバス機能、その他のイベント インタラクションを含むページ インタラクション機能をカプセル化します。
3. アプリケーション: ダッシュボード、大画面など、さまざまなユーザーや使用シナリオに合わせてさまざまなビジュアル アプリケーションを実装します。
2.2 詳細設計
2.2.1 コアクエリ
ワンストップのセルフサービス BI は、パブリック データセットのモデリングのアイデアを通じて、「トレンド、ディメンション、詳細」の 3 点分析のアイデアを実現しますが、これには次のような多くの課題が伴います。
-
マルチソース データ、マルチ グラフのプレゼンテーション、およびマルチ シナリオの分析と計算: BI システムには複数の基礎となるデータ ソース エンジンがあり、データ ソースを柔軟に拡張するために、プレゼンテーション スタイルには豊富なグラフのサポートも必要です。同時に、さまざまなシナリオでの分析に対応するために、計算では前月比や日次平均値などの一般的な分析機能をサポートする必要があります。
-
数千万のデータを数秒でクエリする: 公開データセットを構築するというアイデアは分析を容易にしますが、同時に新たな課題も生じます。 1 日に何千万ものデータが発生するため、クエリのパフォーマンスに大きな課題が生じます。
上記の問題に対応して、対応する解決策が策定されました。
-
統合クエリ: クエリ コンテキストを統合し、クエリ オブジェクトを構築し、基礎となるエンジン言語を適応させ、統一されたデータ形式を返します。フロントエンド レンダリング フレームワークは、グラフの種類に応じてレンダリングを適応させます。
-
クエリの最適化: Ⅰ> キャッシュ + 自動ローリング、パブリック ダッシュボード リクエストの 70% をカバー; Ⅱ> SQL クエリの構築を最適化し、エンジン側の集約機能を最大限に活用します。 III> 複数のドメイン名の同時リクエストと複数のコルーチン応答処理。 。
統合クエリ:
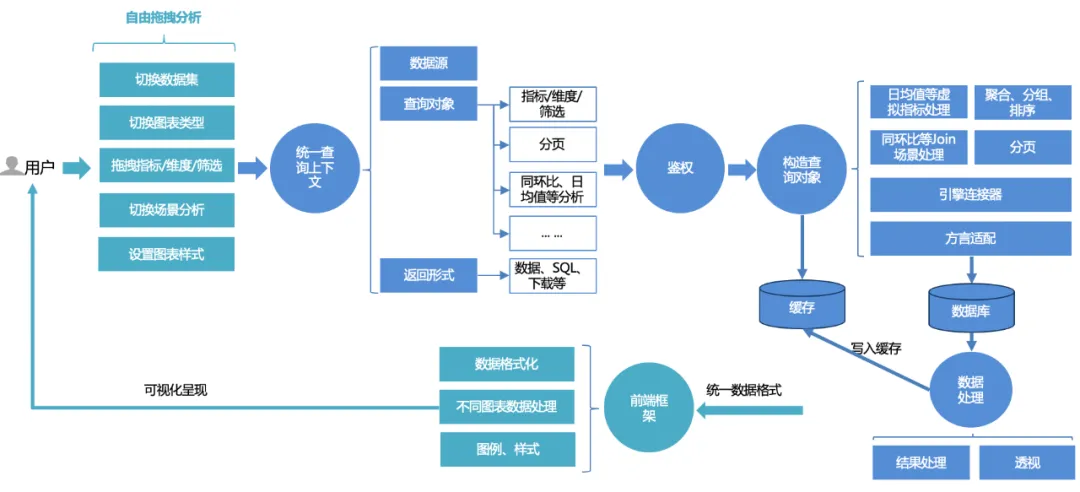
プラットフォーム ユーザー向けの統合クエリ プロセスは次のとおりです。
1. ユーザーはページ上で自由に分析をドラッグ アンド ドロップできます。データ セットの切り替え、さまざまなチャート タイプの切り替え、インジケーター、ディメンション、フィルター、クエリのドラッグ アンド ドロップ、または高度なシーン分析機能を使用したい場合は切り替えることができます。ワンクリックで設定を行えます。
2. フロントエンド リクエストは、データ ソース、クエリ オブジェクト、リターン フォームを含む統合クエリ コンテキストに処理されます。クエリ オブジェクトには、基本的な指標、ディメンション、フィルタリング情報、および前年比などの高度な分析構成がカプセル化されます。比較と日次平均値。
3. 統合認証サービス: ダッシュボードとデータセットの二重認証のコアに基づいて、行と行の権限のより詳細な権限制御もサポートします。
4. クエリ オブジェクトを構築します。まず、インジケーター、ディメンション、フィルタリング トリプルに基づいて基本的な SQL 構築 (集計、グループ化、フィルタリング) を完了します。次に、並べ替えルールに従って並べ替えロジックを組み立て、いくつかの高度な分析オプション (たとえば、データをクエリするときは、異なるエンジンに応じて異なるデータベース (mysql、palo、clickhouse など) をクエリします。追加のアセンブリ ロジックとページング処理を組み合わせる必要があります。リンカー。
5. データのクエリと処理: リンカーを通じてデータをクエリした後、データを処理します (日付形式の処理、折れ線グラフの視点など)。
6. キャッシュ: 処理されたデータはキャッシュに書き込まれます。クエリ中にキャッシュが直接ヒットした場合は、キャッシュされたデータが直接読み取られて返されます。
7. フロントエンド レンダリング フレームワークの統合レンダリング: 統一されたデータ形式を返し、フロントエンドはチャート、スタイルなどの適応レンダリングを完了します。
クエリの最適化: Ⅰ>キャッシュ + 自動ロールアップ。パブリック ダッシュボード リクエストの 70% をカバーします。
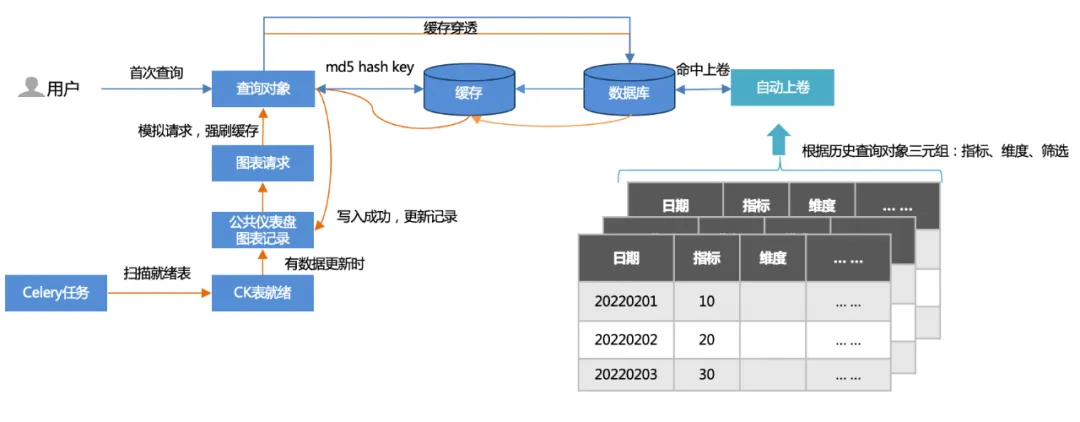
1. 2 つのキャッシュ方法:
最初のクエリ: ユーザーは最初にアクセス (キャッシュ侵入) し、データベースにクエリを実行してから、キャッシュに書き込みます。
オフライン タスクのウォームアップ: パブリック ダッシュボードのチャート レコードをスキャンし、チャート リクエスト (更新ごとに 500 以上) をシミュレートして、キャッシュを強制的にフラッシュします。
2.自動巻き:
履歴クエリのトリプル (インジケーター、ディメンション、フィルタリング) に基づいてロールアップ テーブルが確立され、クエリがロールアップ テーブルにヒットします。クエリされるデータの量が大幅に削減され、パフォーマンスが向上します。
クエリの最適化: Ⅱ> SQL クエリの構築を最適化し、MPP アーキテクチャ エンジン (clickhouse/palo など) の集計機能を最大限に活用します。

パブリックデータセットの分析シナリオでは、データをクエリした後、それをメモリ内で集計して計算することはほとんど不可能です(たとえば、(a + b) / c は、詳細なデータ a、b に基づいて集計して計算する必要があります) 、c)、エンジン側の MPP を使用する必要があります。アーキテクチャのクエリ機能により、月ごとの集計と同様に、エンジン側での実行のために集計計算が洗練され、データ量は数百億に及びます。エンジン側の集計計算後の体積は数十倍に削減され、パフォーマンスも数倍向上します。
クエリの最適化: III>複数のドメイン名の同時リクエスト、マルチコルーチン応答処理。
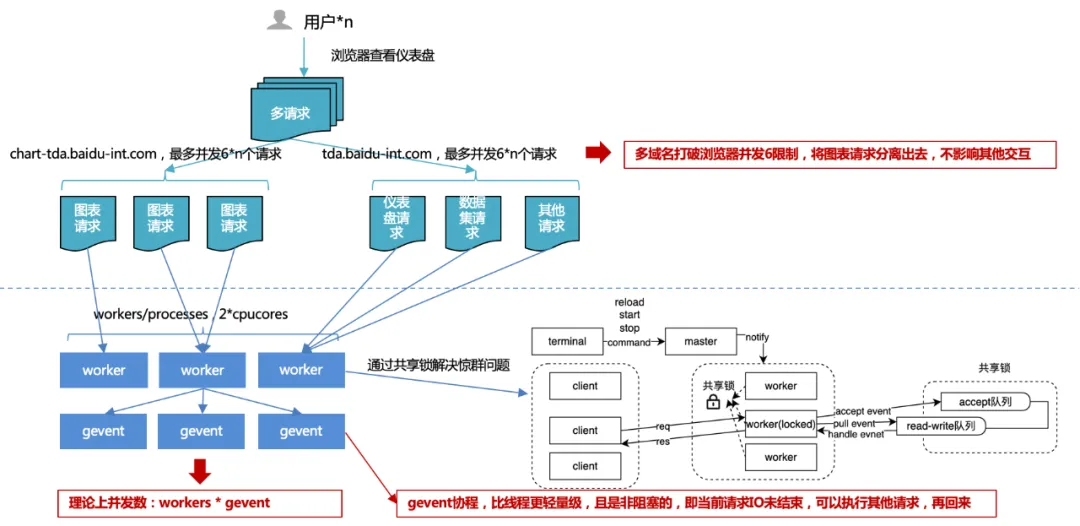
1. ブラウザーの同時実行制限 6 : 複数のドメイン名を使用することで、チャート リクエストが他のリクエストからオフロードされ、スムーズなプラットフォーム インタラクションとチャート リクエストの同時実行性が向上し、全体的なパフォーマンスが向上します。
オペレーティング システムのポート リソースを考慮してください。PC ポートの合計数は 65536 であるため、TCP (http は TCP でもあります) リンクが 1 つのポートを占有します。通常、オペレーティング システムは、ポート数がすぐに枯渇するのを防ぐために、外部リクエストに対して合計ポートの半分を開きます。
過剰な同時実行は、頻繁な切り替えとパフォーマンスの問題につながります。1 つのスレッドが 1 つの http リクエストを処理するため、同時実行の数が膨大な場合、頻繁なスレッド切り替えが発生します。また、スレッド コンテキストの切り替えは軽量のリソースではない場合があります。これにより、利益よりも損失の方が多くなるため、以前の接続を再利用するためにリクエスト コントローラーで接続プールが生成されます。したがって、同一ドメイン名下のコネクションプールの最大数は4~8と考えられます。コネクションプールをすべて使用すると、後続のリクエストタスクがブロックされ、リンクに空きがある場合に後続のタスクが実行されます。
同じクライアントからの多数の同時リクエストがサーバーの同時実行しきい値を超えないようにする: ブラウザーが同じドメイン名に対して同時実行制限を設定していない場合、サーバーは通常、悪意のある攻撃を回避するために同じクライアント ソースに対して同時実行しきい値を設定します。サーバーの同時実行しきい値を超過する可能性があります。
クライアントの良心メカニズム: 2 つのアプリケーションがリソースを占有するのを防ぐために、より強い側が制限なくリソースを取得し、弱い側が永久にブロックされます。
2. サーバー側のマルチプロセス + マルチコルーチンの同時実行:
複数のプロセスで開発する場合、複数のプロセスが同じイベントを待機する「雷の群れ問題」が発生することがあります。イベントが発生すると、すべてのプロセスがカーネルによって起動されますが、起動後は 1 つのプロセスだけがイベントを取得して処理し、他のプロセスは時間の取得が失敗したことを検出して待機状態に入ります。同じイベントをリッスンする場合、プロセスの数が増えるほど、CPU の競合が深刻になり、コンテキスト コストが深刻になります。
したがって、この状況に対応して、uwsgi サービスは共有ロック メカニズムを設計および実装し、同時に 1 つのプロセスだけがイベントを監視するようにして、雷の群れの問題を解決しました。
ただし、それでもプロセス数を無制限に拡張できるわけではなく、一般的には CPU コア数の 2 倍が推奨されます。
では、プロセス数は限られているので、スループットを向上させるにはどうすればよいでしょうか?通常の状況では、データベースまたはファイルを読み取るとき、現在のプロセスまたはスレッドは、IO 操作が結果を返すまで待機してから、後続のコードの実行を続けます。マルチスレッドによってスループットを向上させ、IO ブロックが発生すると、スレッドがスタックし、他の同時リクエストがスレッドによって処理されなくなります。非同期 IO は、IO の代わりにコルーチンを通じて実装されます。つまり、スレッドごとに実装されます。 IO 結果を待つ場合、最初に新しいリクエストを処理し、IO が完了するまで待機してから、IO を待つ必要があるコードに戻ります。このようにして、プログラム内のすべてのスレッドを最大限に活用し、常に何かを行うことができます。この方法により、個々の時間に影響を与えることなく、全体のスループットが向上し、全体の時間が削減されます。
2.2.2 システム保証
アラートを購読する:
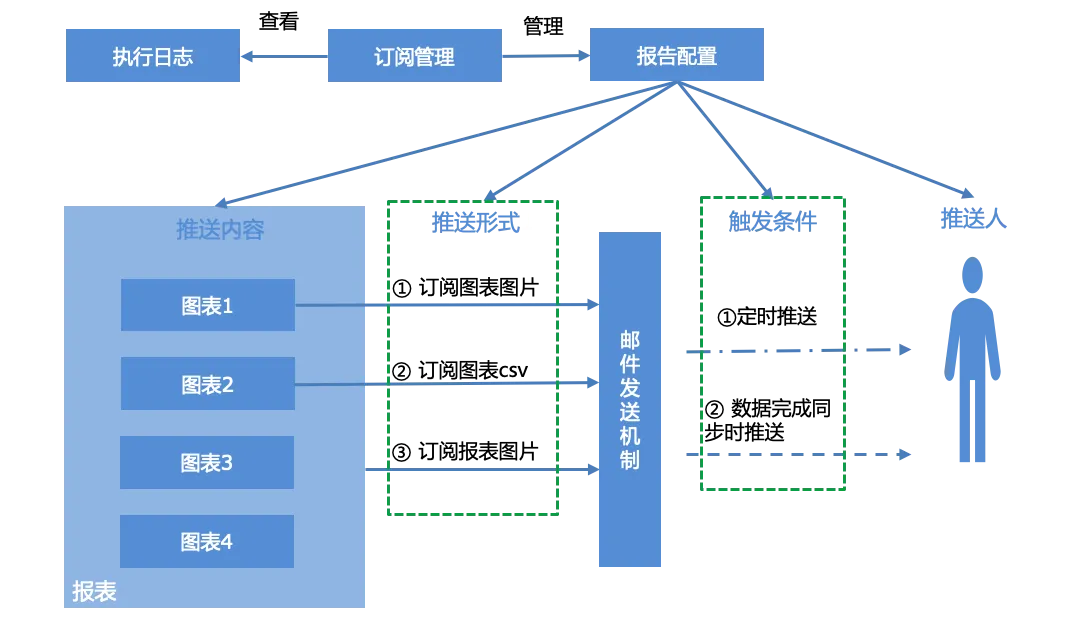
ユーザーは、レポートのレポートを構成し、サブスクリプション管理インターフェイスに従って生成されたサブスクリプション レポートを管理し、システムの実行ログ、つまりレポートのプッシュ ステータスを表示できます。
レポート構成には主に、プッシュ コンテンツ、プッシュ フォーム、トリガー条件、プッシャーの 4 つの部分が含まれます。
プッシュコンテンツ: 単一のグラフ、レポート全体
プッシュフォーム:3つのプッシュフォーム
チャートのスクリーンショット
チャートCSVデータの電子メール添付ファイル
レポートのスクリーンショット
発動条件:
スケジュールされたプッシュ、cron 式に基づくスケジュールされたプッシュ。
データ同期が完了するとプッシュされます。レポートのすべてのチャートに関連付けられたデータ セットがデータ同期を完了すると、プッシュ条件がトリガーされ、電子メール通知が完了します。
Pusher : メールアカウント。複数ある場合は「,」で区切ります。
権限:

データ権限の階層的な管理と制御: データセットとダッシュボードの二層認証コアに基づいて、ルールの粒度に従って承認を申請するための行と列の権限をサポートし、ユーザー権限を柔軟に制御します。
効率的なコラボレーション:MPS(統合権限管理システム)統合権限サービスを開放し、権限承認、有効期限回復、退職凍結などの機能を実現し、スムーズなオフィスを開設し、権限承認の高速循環を加速します。
03 まとめと計画
3.1 概要
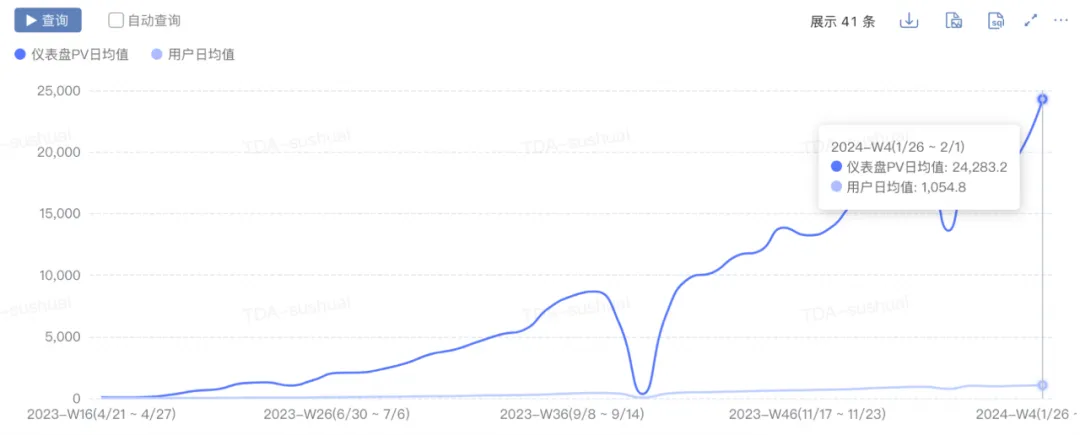
継続的な反復の結果、TDA は基本的にワンストップのセルフサービス分析機能を開発し、次の指標を達成しました。
- スケールの成長: pv は 0 から 2w+ に増加し、uv は 0 から 1000+ に増加し、毎日の新しいチャートは 0 から 300+ に増加しました。
-
パフォーマンスの向上: ダッシュボードの最初の画面の 90 パーセンタイルに到達するまでの時間が 10 秒以上から 5 秒に短縮されました。
-
ビジネス効率の向上: コア ビジネスの 80% 以上のセルフサービス率を促進し、変動分析の効率を 20 倍に高め、単一指標の変動のエンドツーエンドの属性分析を 2 時間から 5 分に短縮します。
3.2 計画
さまざまな分野での AI ネイティブ テクノロジーの浸透に伴い、TDA は将来的に AI テクノロジーを組み合わせて、プラットフォームのインテリジェントな分析エクスペリエンスを強化します。主なポイントは次のとおりです。
-
セルフサービス データ アクセス: データ アクセスが自由化され、データ ソースの種類が拡張されます。
-
AI+BI: アトリビューション分析、埋め込み分析、分析レポートなどの BI 機能を大規模モデル AI と組み合わせて、インテリジェントな分析製品を向上させます。
-
管理コックピット (探索): OKR 目標ダッシュボード。
- - - 終わり - - -
推奨読書
この記事では、Go 言語の IO 基本ライブラリを完全に理解します。
Baidu データ ウェアハウス フュージョン コンピューティング エンジンの秘密を明らかにする
JetBrains 2024 (2024.1) の最初のメジャー バージョン アップデートは オープンソースです。Microsoft も費用を支払う予定です。なぜオープンソースが依然として批判されているのでしょうか? [復旧] Tencent Cloud バックエンドがクラッシュ: コンソールにログイン後、大量のサービス エラーとデータなし ドイツも 「独立して制御可能」にする必要がある 州政府は 30,000 台の PC を Windows から Linux deepin-IDE に移行し、最終的に達成ブートストラッピング! Visual Studio Code 1.88 がリリースされました. 良い人です、Tencent は Switch を本当に「思考する学習マシン」に変えました. RustDesk リモート デスクトップが起動し、Web クライアントを再構築します. SQLite に基づく WeChat のオープン ソース ターミナル データベースである WCDB がメジャー アップグレードされました.