現代の企業では、多くの場合、ビジネスの問題点を解決するためにデータ分析と機械学習を使用する必要があります。たとえば、製造業では、機器によって収集されたデータは予知保全と品質管理に使用され、小売業では、クライアントによって収集されたデータはチャネル コンバージョン率分析とパーソナライズされた推奨事項に使用されます。
| Amazon クラウド テクノロジー開発者コミュニティは、開発者にグローバルな開発テクノロジー リソースを提供します。技術ドキュメント、開発事例、技術コラム、トレーニングビデオ、アクティビティやコンテストなどがあります。中国の開発者が世界最先端のテクノロジー、アイデア、プロジェクトとつながることを支援し、優れた中国の開発者やテクノロジーを世界のクラウド コミュニティに推奨します。まだ注目/お気に入りをしていない場合は、これを見たときに慌てずにクリックして、ここを技術の宝庫にしてください。 |
通常、ビジネス部門は要件を技術チームに提出する必要があり、技術チームはビジネス要件を技術要件に変換し、データ エンジニア、データ サイエンティスト、機械学習エンジニアなどを動員してデータ処理、分析、モデリングを行います。プロセスは長く、比較的高額なチーム間のコミュニケーションコストが必要であり、企業の人材予備スキルの要件もあります。顧客のビジネス部門は一般に、機械学習を使用してビジネス上の問題を解決するためのしきい値と学習コストを削減し、ビジネス アナリストがデータ サイエンティストやデータ エンジニアの支援をあまり受けずに特定分野のビジネス データの洞察を迅速に解決できるようにすることを期待しています。
この記事では、自動車業界の障害分析を例として、Amazon クラウド テクノロジー上にコード不要のデータ分析プラットフォームを構築する方法を説明します。ビジネス担当者は、プログラミング能力、SQL、または機械学習の事前知識を必要とせず、すぐに実行できます。ビジネス シナリオに応じて使用し、特定のニーズに応じて分析用のデータをセルフサービスでアップロードおよびインポートすることで、ビジネス パーソンが最短時間で最も便利にデータを使用できるようにします。
シナリオと問題点
車両の異常故障率は通常、生産バッチの問題、耐用年数、ディーラーのメンテナンスなどの複数の要因の影響を受けます。
従来、品質保証部門は、点在する顧客からの不具合報告やメンテナンス依頼を受動的に受け付けており、特定の車種やロットの不具合がある程度蓄積したり、発生したりした場合に、その車両の不具合箇所を特定し、メンテナンスを行うことが可能でした。一様に思い出した。突然の故障発生により、関連部門は事前にメンテナンス資金の予算を立てたり、予備部品を事前に準備したり、事前に制御措置を講じたりすることができなくなり、自動車所有者の経験にも影響を及ぼしました。
したがって、車両の品質保証データのデータ分析、故障発生の時系列分析またはクラスター分析、既存データに基づく故障傾向の予測は、事業部門が品質早期警告および品質改善目標を達成するのに役立ちます。全体的なメンテナンスコストを削減するために、事前に対応する措置を講じてください。
技術的な目標
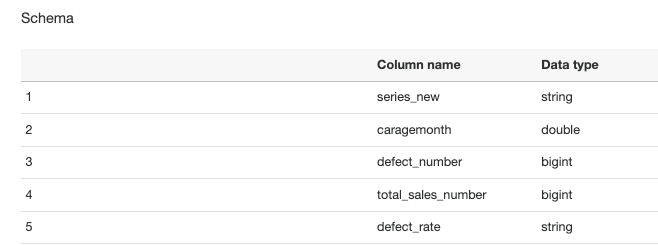
実販売車両データと車両メンテナンスデータ(以下の表に2つのスキーマを示します)を基に、モデルに基づいて故障状況を説明できる曲線を描き、その曲線を分類し、類似した故障曲線をまとめてスクリーニングします。異常故障の予測と早期警告の目的を達成するために、異常故障曲線を作成します。
- モデル故障曲線: 時間、走行距離、車両年数に基づく車両故障数の増加曲線など。この記事では車両の年式を例に挙げていますが、集計条件が異なる以外は同様です。
- 類似した形状を要約し、異常な断層曲線をスクリーニングします
- 既存のデータに基づいて傾向を予測する
サンプリングスキーマ
- 修復データ
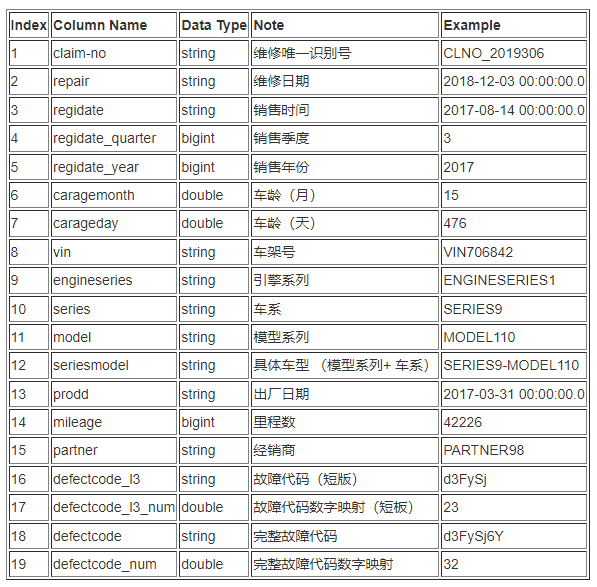
- 販売データ
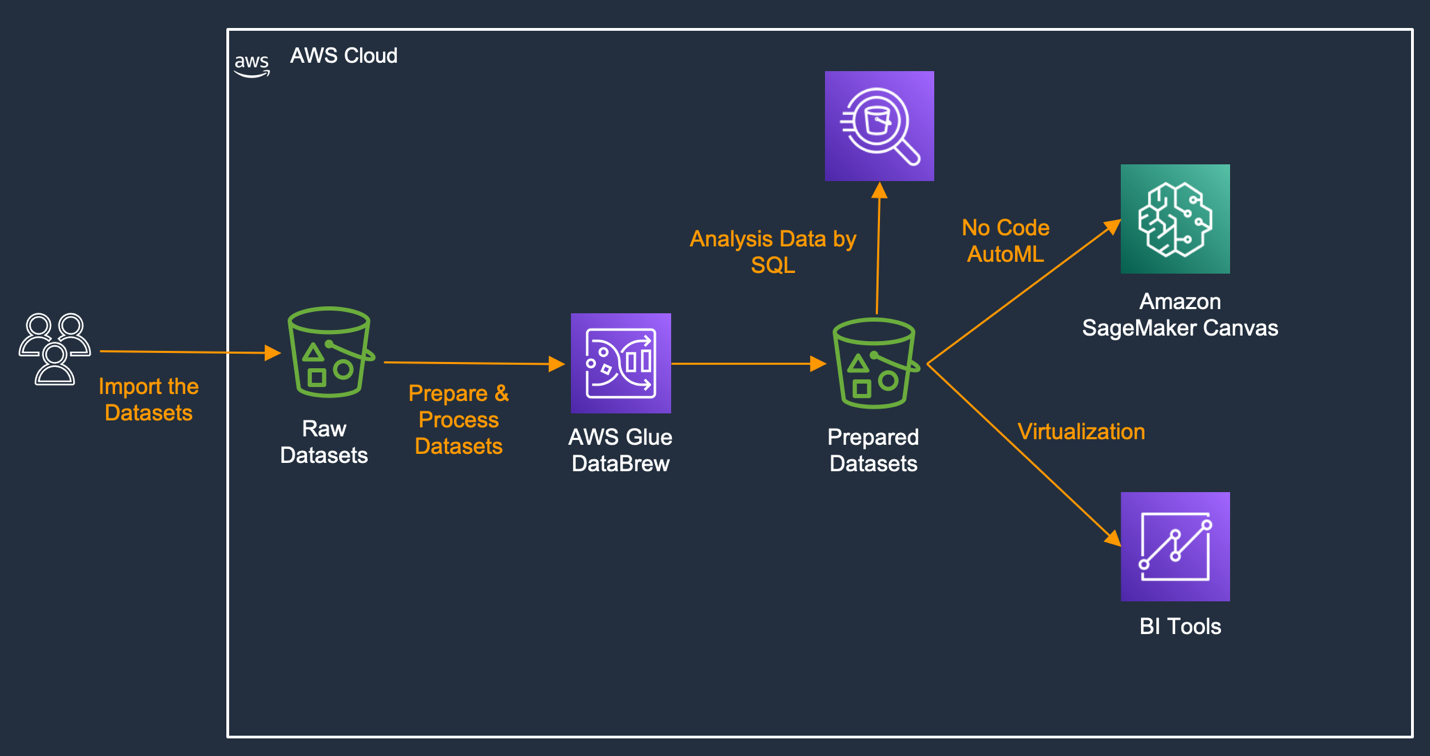
建築
- メインのデータ処理ツールとしてGlue Databrewを選択します 。Amazon Glue Databrew は、データアナリストやデータサイエンティストがデータをクリーンアップして変換するのに役立つビジュアルツールを提供し、その後の分析や機械学習シナリオへのデータの適用を容易にします。Glue Databrew は、コードを必要とせずに UI を通じて自動的に実行できる最大 250 の事前構築された変換で操作を提供します。たとえば、異常なデータのフィルタリング、データの標準形式への変換、無効な値の修正などを行います。
- Glue を使用してデータ形式 (スキーマ) をクロールし、Athena をコネクタとして使用し、最後に QuickSight をダッシュボード表示用の BI 表示ツールとして使用します。
- Databrew で処理されたデータをモデルの入力として使用し、Sagemaker Canvas を使用して予測モデルを生成します。Amazon SageMaker Canvas は、ビジネスアナリストに視覚的なポイントアンドクリックインターフェイスを提供することで機械学習 (ML) へのアクセスを拡張し、AutoML テクノロジーを活用して、機械学習の経験やコードの記述を必要とせずに、独自のユースケースに基づいて ML モデルを自動的に作成します。 。同時に、SageMaker Canvas は Amazon SageMaker Studio と統合されているため、ビジネスアナリストがモデルやデータセットをデータサイエンティストと共有し、ML モデルを検証してさらに最適化できるようになります。
前提条件
- Glue Databrew はすでにほとんどの地域 (北京と寧夏を含む) でサポートされており、コンソールで対象の地域に切り替えることができます。SageMaker Canvas は現在、一部の地域で利用可能です。特定の地域については、このFAQ ドキュメントを参照してください 。この記事では、例としてオハイオ州 (us-east-2) を使用します。
- まず、サンプル データをターゲット リージョンの S3 バケットに保存します。アップロード方法がわからない場合は、この S3 ドキュメントを参照してください。
プロトコルのステップ
1. データ変換用の Glue Databrew
この章では次の機能を完了します
- 無効なデータのクリーニング
- 車両メンテナンス データを販売データに合わせて変換する
- 車両整備データと販売データを一元化
- 車両モデルと車両年齢ごとにデータを集計
- 故障率を計算する
詳細な手順
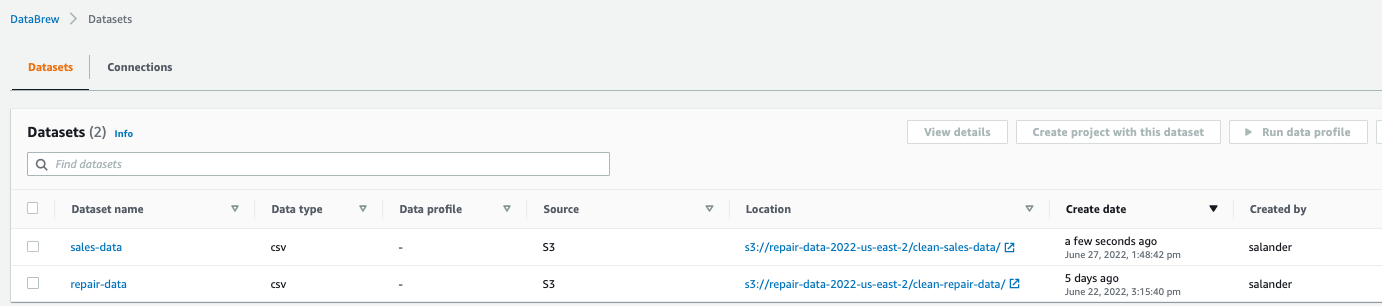
1. Databrew コンソールを開き、左側の列の [データセット] をクリックし、[新しいデータセットを接続] をクリックしてデータ ソースを作成します
2. データセットに名前を付け(「repair-data」など)、S3 の保存場所を選択した後、データ形式は csv、デフォルトの区切り文字は「,」で、「データセットの作成」をクリックします。同様に、デフォルトの区切り文字「,」を使用して、 sales-data という名前のデータ セットを csv 形式で作成してデータ セットを作成します。
3. 新しく作成したデータセット修復データを選択し、「データセットでプロジェクトを作成」を選択し、プロジェクト名とレシピ名を入力し、既存の IAM ロールを選択するか、新しい IAM ロールを作成して、この IAM ロールが選択したデータセットに接続する権限を持っていることを確認します。データ。「プロジェクトの作成」をクリックします 。DataBrew インターフェイスがロードされるまで待ちます。
4. 最初のステップは、無効なデータをクリーンアップすることです。
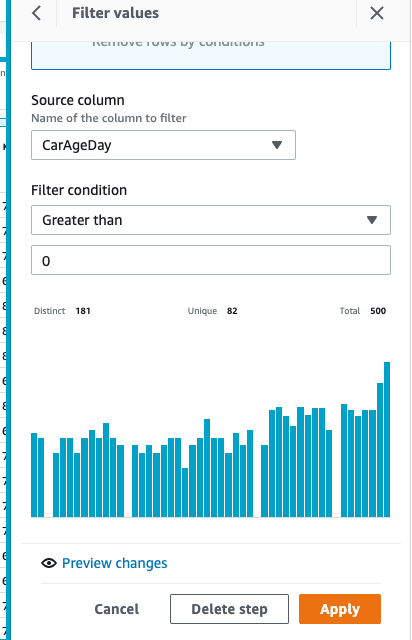
(1) CarAgeDay 列 (日ごとに計算された車の年齢を表します) を選択し、フィルターをクリックして、0 より大きいデータのみを保持することを選択します (または、要件に応じてこの値をカスタマイズします)。図に示すように、「0 より大きい」の条件を編集した後、「レシピに追加」をクリックすると、右側にブラウザが生成されます。「適用」をクリックして有効にします。
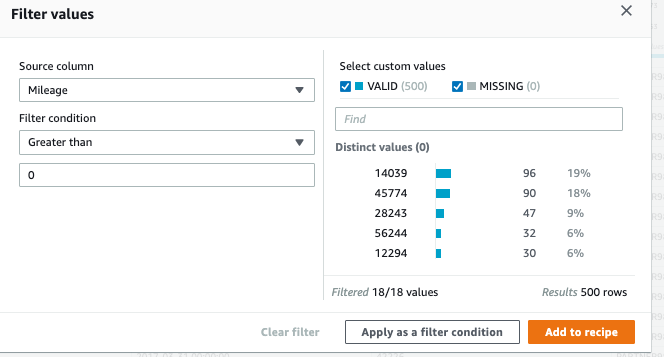
(2) 走行距離をフィルタリングし、0 より大きい有効なデータのみを保持します。また、「レシピに追加」をクリックし、「適用」をクリックして有効にします。
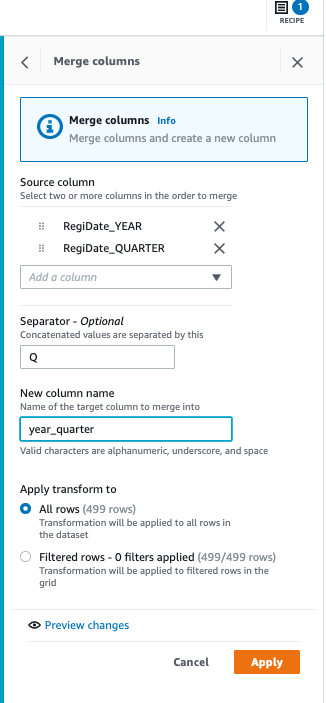
5. 2 番目のステップでは、車両メンテナンス データの販売年と販売四半期を 1 つのフィールドにマージして、販売データを調整します。右側のレシピをクリックし、ステップを追加し、マージ操作 (列の連結) を選択して RegiDate_ Year をマージします。および RegiDate_Quarter、コネクタとして「 Q 」、ターゲット列名「 year_quarter 」
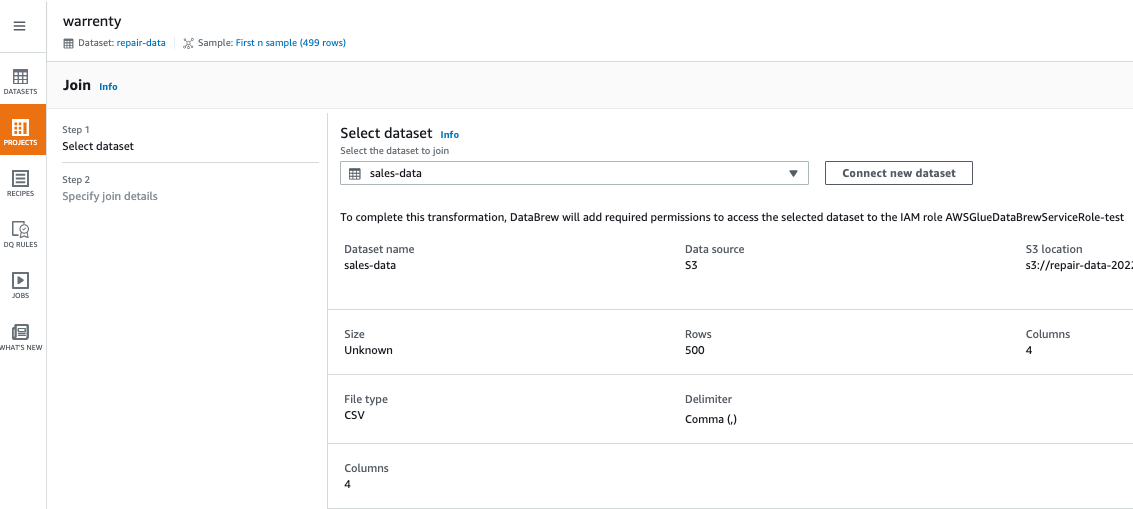
6. 3 番目のステップは、車両メンテナンス データと販売データを結合することです。[JOIN 操作] をクリックし、結合するデータ セットとして sales-data を選択し、LEFT JOIN を選択して、結合キーとして year_quarter と Sales_Quarter を使用し、参照後に [終了] をクリックします。
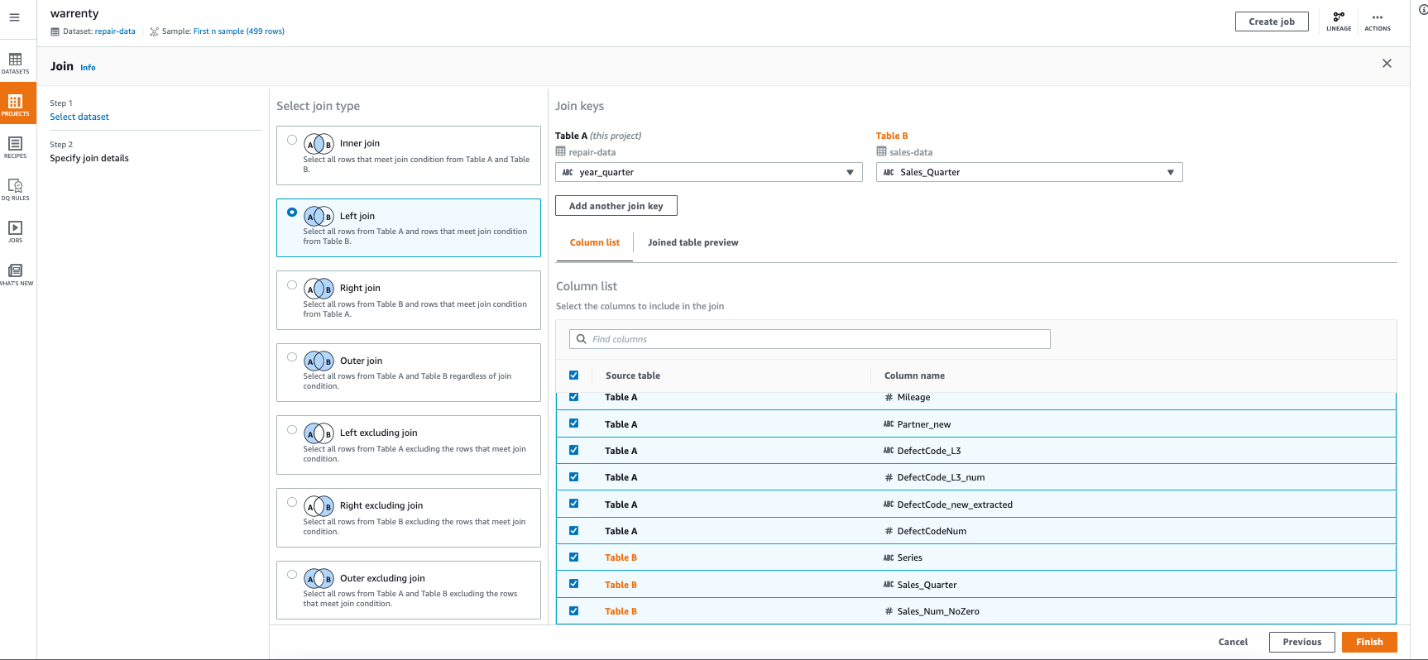
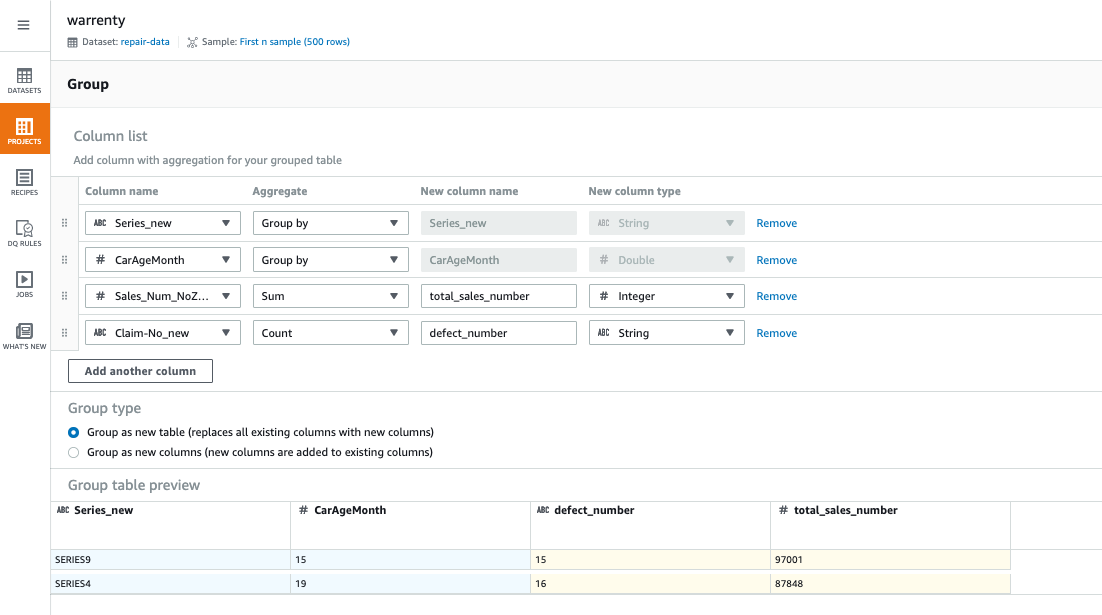
7. 4 番目のステップは、モデルと車両の年式に従ってデータを集計することです。次の図に示すように、Series_new と CarAgeMonth に従って Group by を集計して、故障数と販売数を生成します。
8. 5 番目のステップは故障率を計算することです
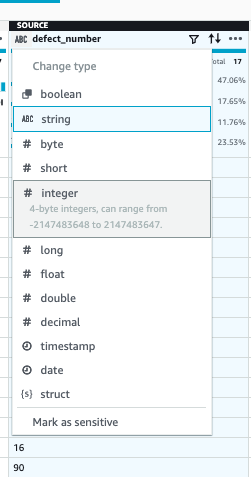
(1) 除算を行うには、まず欠陥番号を INT データ型に変更します。
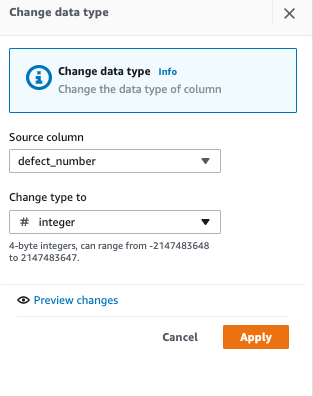
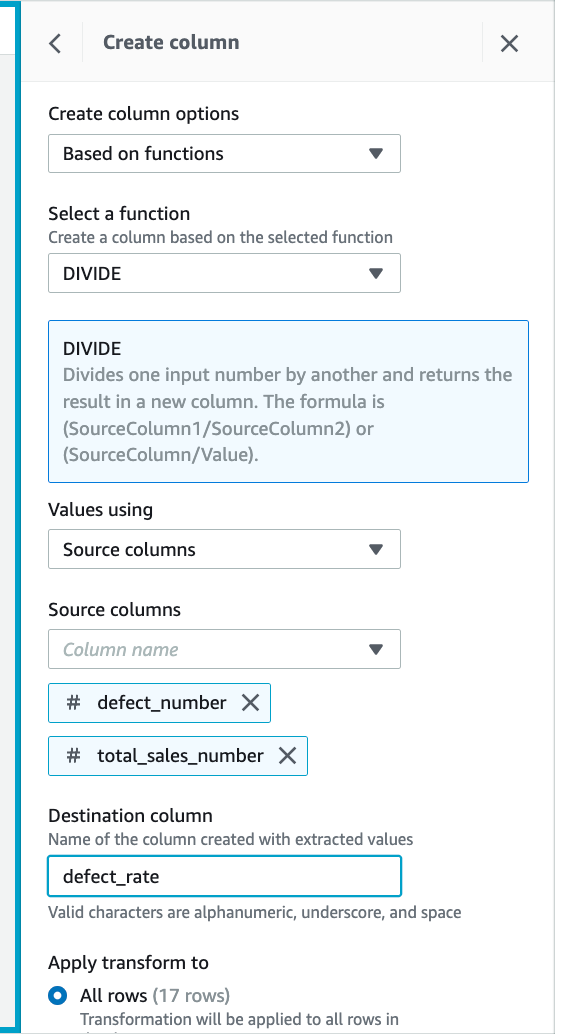
(2) 故障率を計算するために、DIVIDE メソッドを選択し、最初の列で欠陥番号を選択し、二番目の列で total_sales_number を選択し、ターゲット列の名前を欠陥率とします。
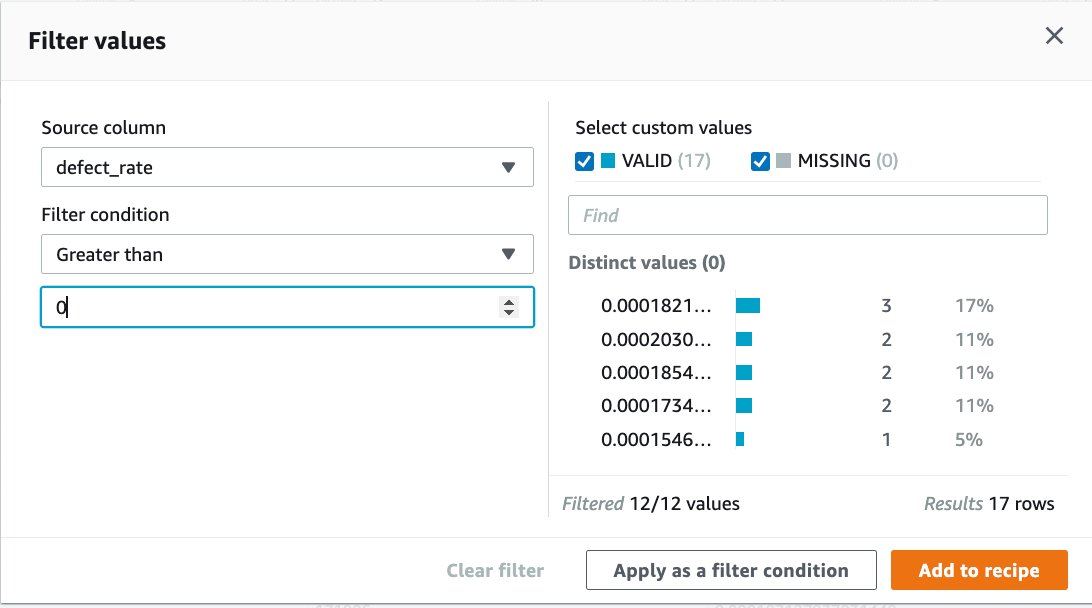
9. 5 番目のステップは、故障率を計算することです。defect_rate をフィルタリングして、0 未満の無効な値を削除します。
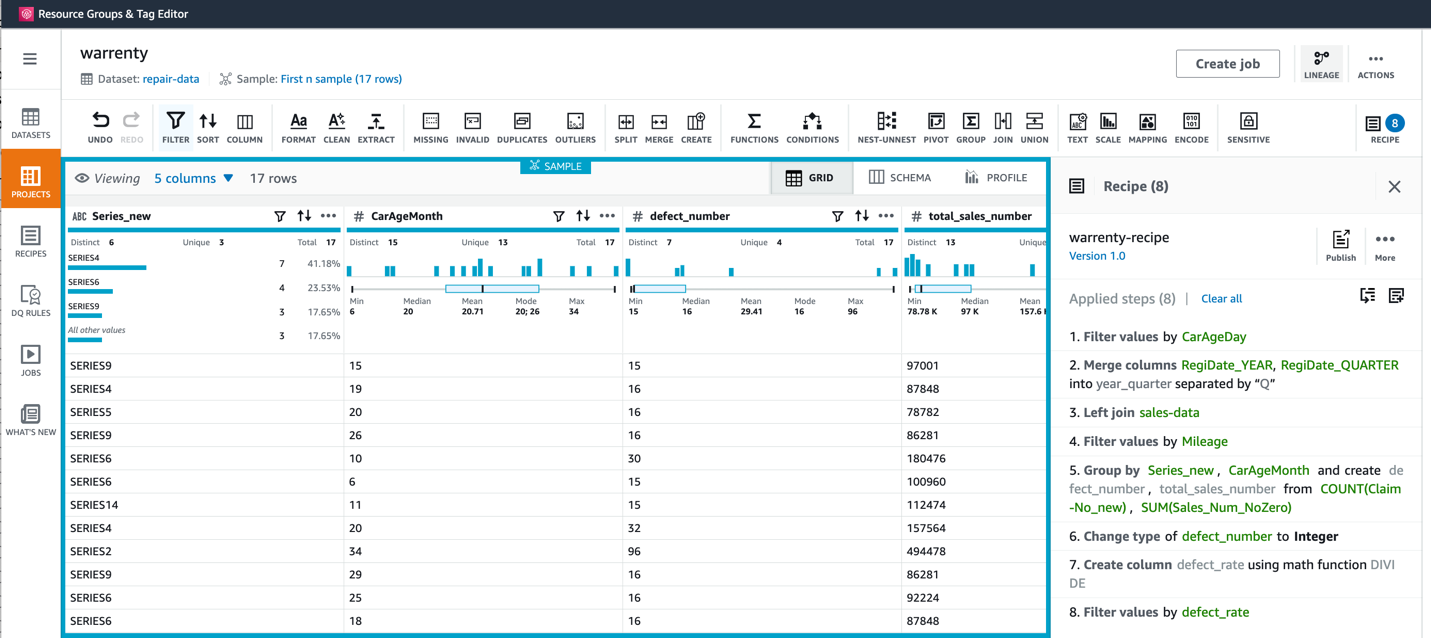
10. 最終的なデータと計算式は図に示されており、各モデルの集計に基づいて、さまざまな年齢の故障率を追跡できます。もちろん、ニーズに応じてデータに対してさらに処理や変換を行うこともできます。
11. 右上の [ジョブの作成] をクリックして、データセット全体にこのレシピを使用します。ジョブ名、ファイル出力アドレス (S3 の場所) を定義し、IAM ロール (このロールには S3 の対応する場所への読み取りおよび書き込み権限が必要です) を選択し、下部にある [ジョブの作成と実行] をクリックし、データ処理約2分で完了します。
12. 最終的に、レシピを公開してレシピを保存することを選択できます。このレシピを直接使用して、次回他のサンプル セットに適用できます。
2. データ表示に QuickSight を使用する
この章では次の機能を完了します
- Glue は、Databrew によって出力されたスキーマをデータ ディレクトリとしてクロールします。
- Athena をコネクタとして使用して BI ツール QuickSight に接続します
- QuickSight のウィジェットとダッシュボードをカスタマイズする
詳細な手順
1. Glue Crawler (クローラー) に移動し、クローラーの追加 (クローラーの追加) をクリックして、S3 データの場所 (先ほどの Databrew の出力場所) を定義します。定義が完了したら、必ず「クローラーの実行」をクリックして、この実行中のタスクを開始してください。ジョブが完了したら、左側の表の列でデータ スキーマを確認してください。
2. Athena は Glue のデータ ディレクトリを使用するため、Athena をクリックすると、先ほどクロールした欠陥率テーブルが表示されます。この記事では、以下に示すように、Glue を使用して他の 2 つの元のテーブルもクロールします。
3. コンソールを QuickSight に追加し、データセット (データセット) を追加し、データ ソースとして Athena を選択します。プロンプトに従って、ターゲット テーブルを選択し、データを QuickSight にロードします。

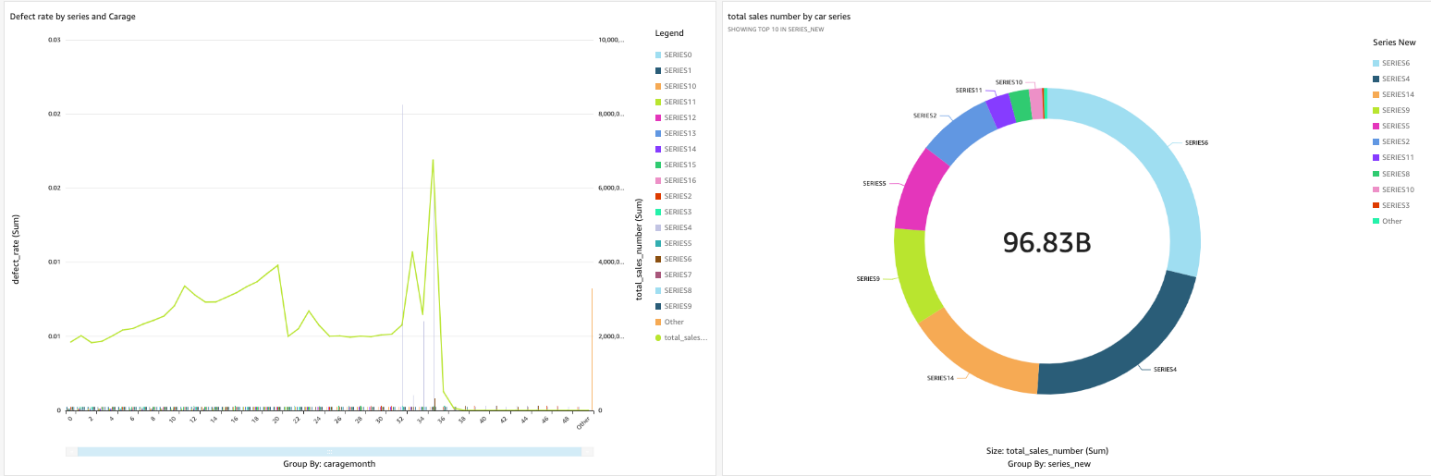
4. インポートが成功したら、 [新しい分析]を追加します 。ここでは、データのさまざまなディメンションとさまざまなグラフ フォームを使用して、カスタマイズされたデータの調査と表示を実行できます。この記事では、各モデルの不良率と販売台数を例に挙げています。SERIES4 は比較的人気のあるモデルであることがわかります。この車の故障率は比較的高く、基本的に故障率は車が 3 程度のときに発生します。この規定に基づき、事前のお客様対応と車検を行っていただきます。したがって、この記事の焦点は Quicksight の使用ではないため、展開されません。QuickSight の使用に慣れていない場合は、このチュートリアル をクリックして参照してください。
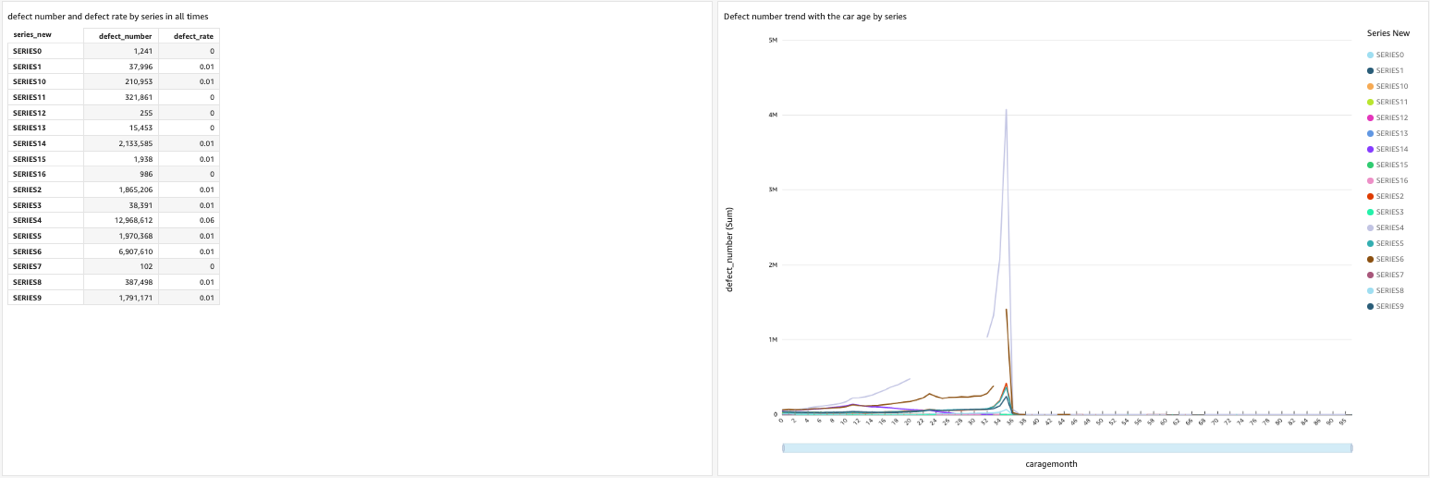
12. すべてのデータが統合されたら、 右上の共有をクリックし てダッシュボードとして公開します
3. Sagemaker Canvas を機械学習ツールとして使用する
この章では次の機能を完了します
- データの追加処理
- データの複数のコピーを結合する
- Sagemaker Canvas を使用してモデルを構築する
- 予測を生成する
詳細な手順
1. 既存データを活用して車両の販売予測やメンテナンス予測などを行うことができます。この記事では故障率を予測の対象とする例を取り上げます。まず、Databrew で他の冗長な列を削除し、series、caragemonth、defect_rate の 3 つの列だけを残します。目標は、シリーズとカラゲに基づいて、さまざまなモデル シリーズの故障率を推測することです。(次回の CSV ダウンロードが完了した後、これら 2 つの列を手動で削除することもできます)
2. 現在、Sagemaker Canvas はモデル データセットとして 1 つのファイルのみをサポートしているため、最初に Athena を使用して複数の Databrew 出力ファイルを 1 つの CSV にマージします。Athena を開いて select * を実行し、スクリーンショットの右下隅に示すように結果をダウンロードして、単一の CSV ファイルを取得します。
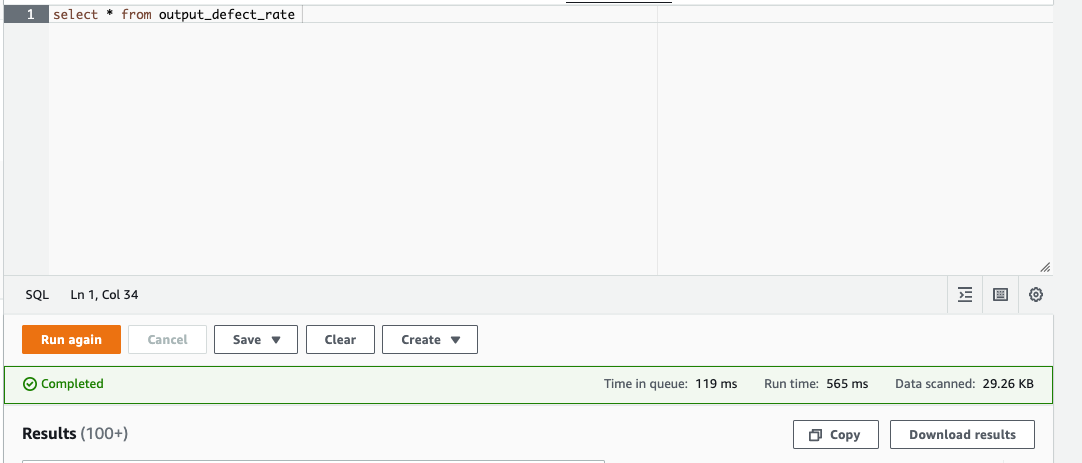
3. 必要なカラムの取り外しを実行します (最初のステップで説明したとおり)。
4. Sagemaker Canvas データセットにデータをアップロードする
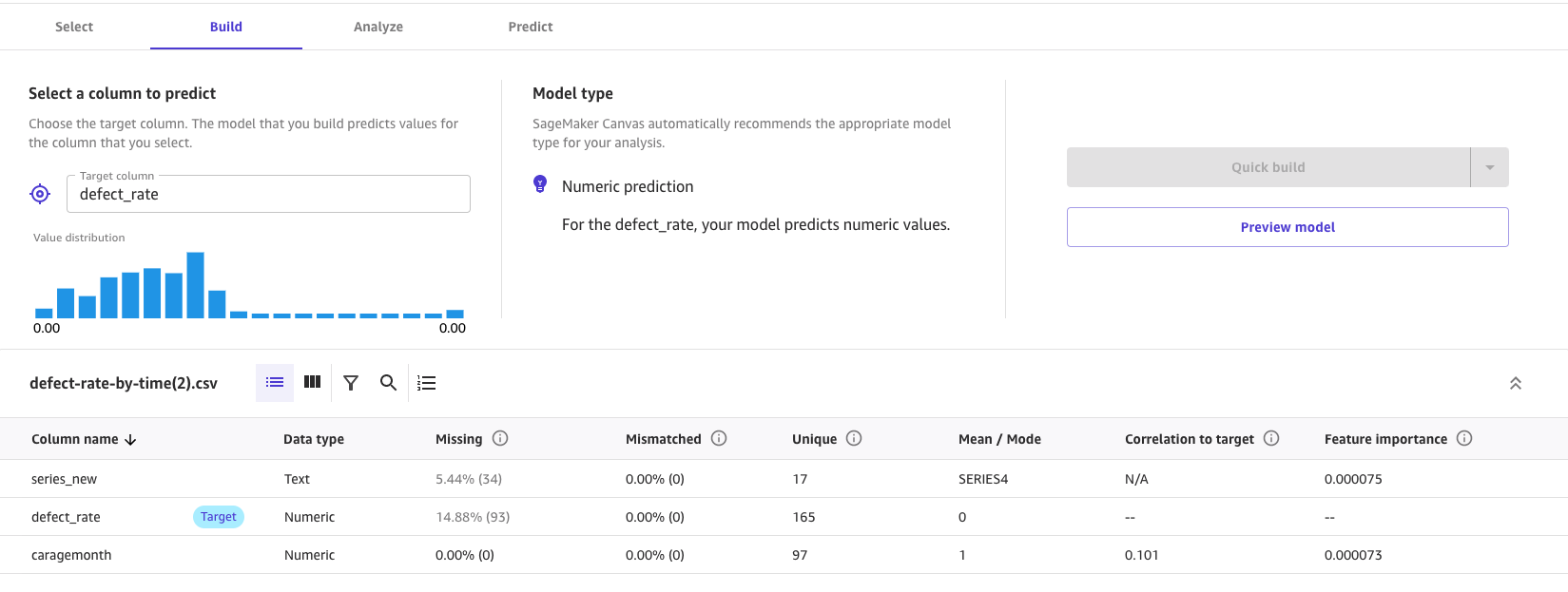
5.モデルを作成し、このデータセットを選択し、ターゲットを欠陥率として選択します。モデルをすばやく生成したい場合は、クイック ビルドを選択してモデルを構築します (2 ~ 15 分)。より高い精度が必要な場合は、標準ビルド (2 ~ 4 時間) を選択します。この記事ではクイック ビルドを選択します。
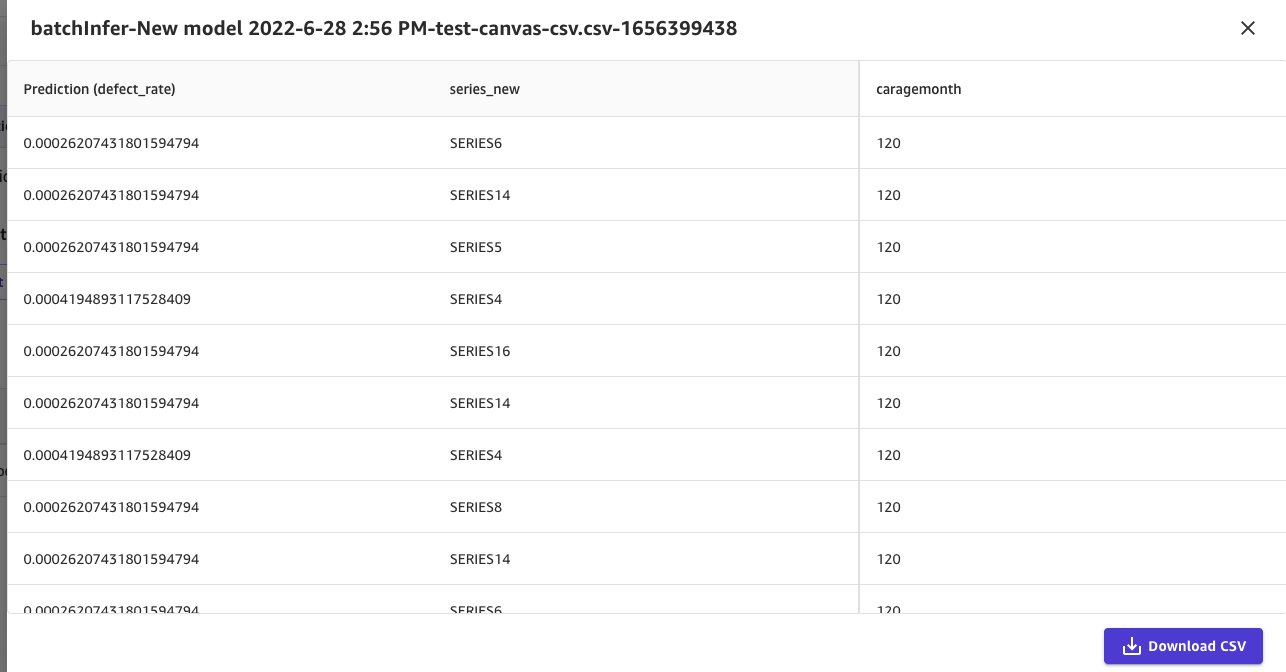
6. モデルが生成された後、台車に基づいて故障率を予測できます。バッチ予測の CSV ファイルをアップロードできます。また、単一の予測に対して単一の値を入力することもできます。この記事では前者を例に、予測したい系列とキャラジ(120か月)をアップロードし、最終的に以下の結果を取得します。
8. 標準ビルドを選択した場合、モデルの作成後、SageMaker Canvas はワンクリックでモデルを Amazon SageMaker Studio に共有することもできる ため、ビジネスアナリストはデータサイエンティストを招待して、モデル上の ML モデルをさらに検証して最適化することができます。および共有データセットを運用環境のレベルにまで拡張します。

結論は
この記事では、Glue Databrew や Sagemaker Canvas などのサービスを使用して、コード不要のデータ分析と機械学習のプラットフォームを構築する、グラフィック ベースのデータ処理と AutoML ソリューションについて説明します。一方で、顧客のビジネス アナリストがデータ処理と ML を削減するのに役立ちます。学習曲線、部門間のコミュニケーションコストの削減、AutoML 結果の解釈可能性の維持、モデルおよびデータセットレベルでのデータサイエンティストとの共有と継続的な最適化の促進。一方、このプラットフォームはサーバーレスに基づいており、顧客がサーバーを管理する必要がなく、従量課金制です。
この記事の著者

Li Tiange は、 Amazon ソリューション アーキテクトであり、Amazon ベースのクラウド コンピューティング ソリューション アーキテクチャのコンサルティングと設計を担当し、開発、サーバーレスなどの分野に優れ、顧客の実際的な問題を解決する豊富な経験を持っています。

Liang Rui Amazon ソリューションアーキテクトである Liang Rui は、主にエンタープライズレベルの顧客のクラウド作業を担当しており、自動車、伝統的な製造、金融、ホテル、航空、観光などの顧客にサービスを提供しており、DevOps が得意です。IT プロフェッショナル サービスで 11 年の経験があり、プログラム開発、ソフトウェア アーキテクト、ソリューション アーキテクトを歴任しました。