著者 | zzbtie
ガイド
クラウドネイティブ環境での大規模なビジネスの反復によるコスト圧力が高まっています。サーバーレスの概念に導かれ、バイドゥ フィードのバックエンド サービスの弾力性、トラフィック、および容量の観点から多次元のパーソナライズされたサービス ポートレートを構築し、ポートレートに基づいてサービスを弾力的にスケーリングし、適応的に調整します。ビジネス運用コストを削減するために、この記事では、上記の関連する戦略と実際的なソリューションに焦点を当てます。
全文は 6542 ワードで、予想読了時間は 17 分です。
01 背景
Baidu の内部製品ラインでのクラウド ネイティブの推進により、マイクロサービスは各ビジネス ラインの標準構成になりました. 検索、レコメンデーション、広告などの戦略的コンピューティング ビジネス シナリオでは、通常、バックエンドは多くのマイクロサービスで構成されます. これらのマイクロサービス サービスは一般的に次の特徴があります。
-
複数のインスタンス: 各サービスは複数のインスタンスで構成され、マイクロサービスは rpc を介して通信し、サービスは通常、水平/垂直スケーリングをサポートします。
-
重い計算: マイクロサービスには比較的複雑なビジネス ロジックが含まれています. 通常, 一部のポリシー ディクショナリはサービスにローカルに読み込まれ、複雑なポリシー計算を実行します. サービス自体はより多くの CPU やその他のリソースを必要とします.
-
7*24h : サービスは通常、固定容量を使用して 7*24 時間のオンライン サービスを提供し、クラウド ネイティブ コンポーネントは、冗長容量の回復などの定期的な容量管理を実行します。
Baidu App Recommendation Service (略して Baidu Feed) は、典型的なレコメンデーション ビジネス シナリオです. バックエンドには、複雑な戦略と重い計算を伴う多くのマイクロサービスが含まれています. これらのバックエンド サービスは、通常、固定容量を使用して、数億のユーザーに 7*24 時間の情報フローを提供します.サービス。Baidu Feed のバックエンド サービスでは、ユーザー トラフィックに典型的なピークと谷があり、トラフィックの谷とピークの期間に同じ容量を使用することは、リソースの浪費であることは間違いありません。バックエンド サービスでの Baidu Feed のサーバーレス。サービス ポートレートに基づくエラスティック スケーリングの技術的ソリューションと実装について詳しく説明します。
02 アイデアと目標
業界におけるサーバーレスの大規模な実践は、FaaS 側にあり、通常、インスタンスは軽量で、コンテナーのライフサイクルは比較的短いです。私たちが扱っているのは、比較的「重い」バックエンド サービスです. このようなサービスのインスタンス拡張には、通常、次の段階が含まれます:
-
PaaS がコンテナーを初期化する: PaaS は、インスタンスのクォータ要件 (CPU、メモリ、ディスクなど) に従って、コンテナーを割り当てるのに適したマシンを見つけ、コンテナーを初期化します。
-
バイナリファイルと辞書ファイルの準備: サービスのバイナリファイルと辞書ファイルをリモートからローカルにダウンロードし、解凍します。
-
インスタンスの起動: インスタンスは起動スクリプトに従ってローカルでプロセスを起動し、インスタンス情報をサービスディスカバリに登録します。
通常、バックエンド サービス インスタンスの展開時間は分単位であり、辞書ファイルのダウンロードと解凍は、展開時間全体の 70% 以上を占めます.大きな辞書を持つインスタンスでは、より多くの時間がかかります.安定した容量を確保するために非常に短い時間 (数秒など) でスケーリングすることはできません。ただし、これらのバックエンド サービスのトラフィックは通常、定期的に変動し、明らかな潮汐特性を持っています.サービスのトラフィックをより正確に予測できれば、事前に容量を適切に拡張して、増加に直面した容量を確保できます。一定量の容量削減を実行してトラフィック フローを削減し、リソース コストを節約し、リソースのオンデマンド使用を実現できます。
全体として、クラウドネイティブなコンポーネントに基づいて、弾力性、容量、トラフィック次元など、サービスごとに多次元のパーソナライズされたサービス ポートレートを作成し、サービスの安定性を確保する前提の下で、トラフィック量に応じて変動するサービス容量を実現します。調整。実装効果を下図に示します. 左の図では、通常モードのサービスによって消費されるリソースの量は固定されており、トラフィックの変動によって変化しません (リソースの量は、ピークトラフィックで必要な容量を満たす必要があります)右の図は、サーバーレス モードでサービスが消費するリソースの量です。リソースの量は、トラフィックの変動に合わせて動的に調整されます。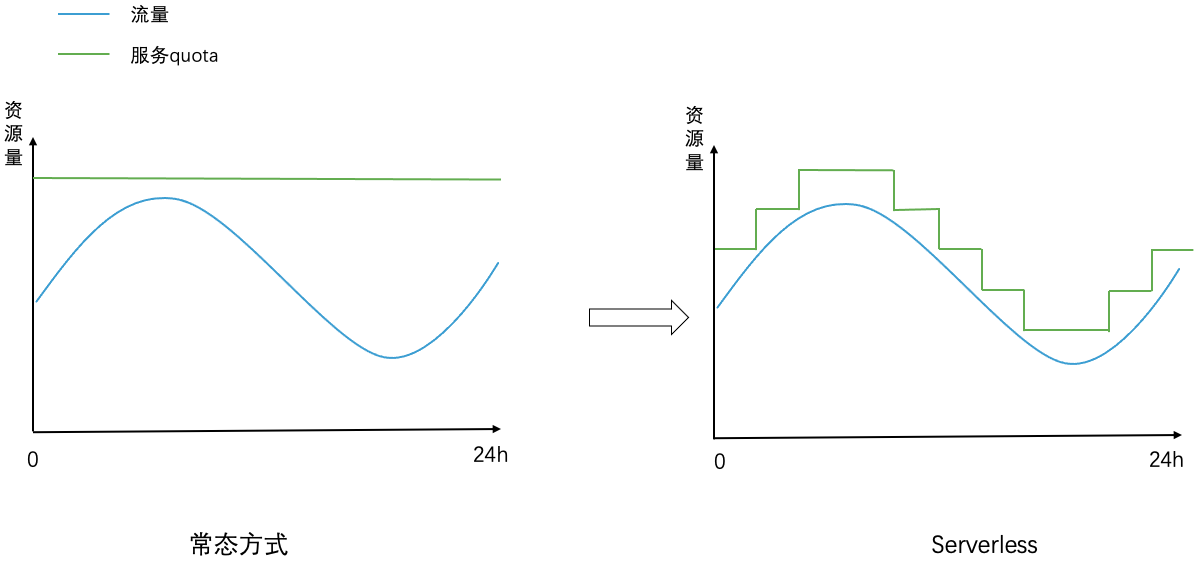
03 全体構成
全体的なエラスティック スケーリング アーキテクチャは次のとおりです。
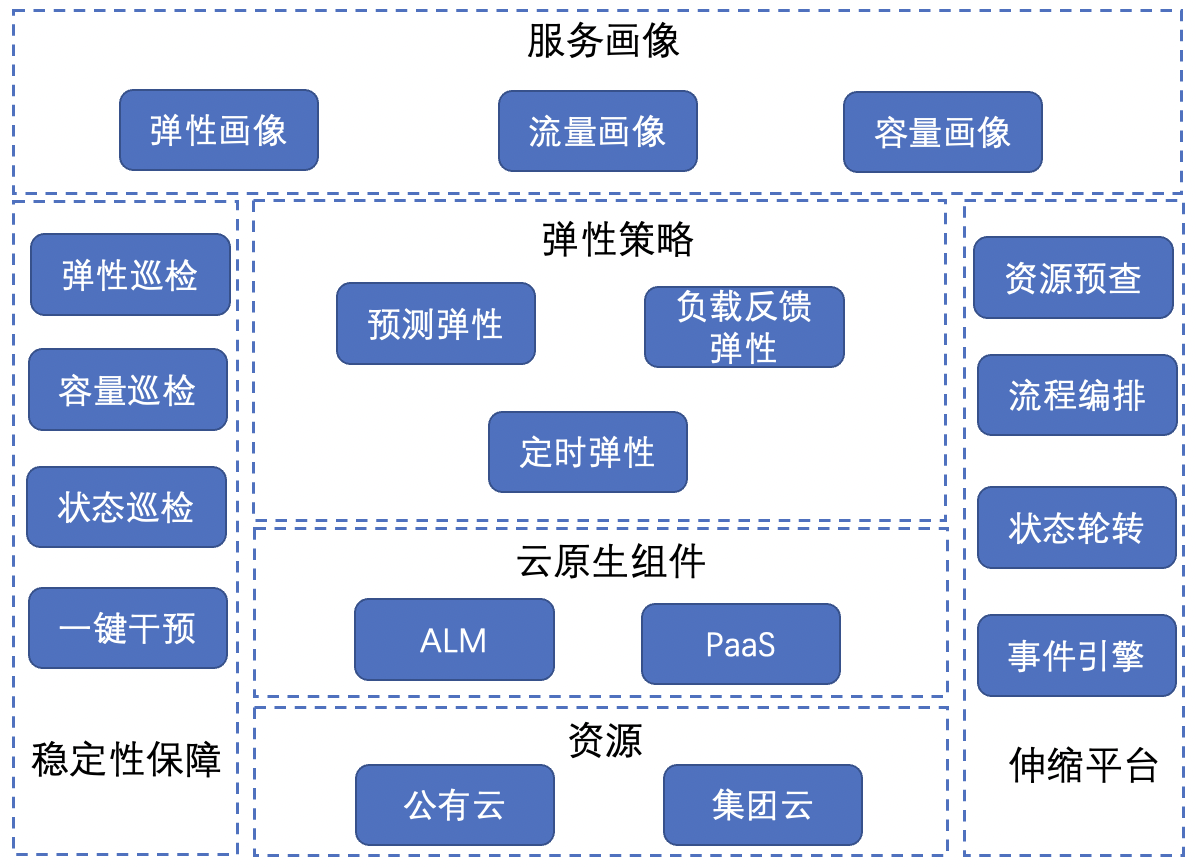
-
サービス ポートレート: エラスティック ポートレート、トラフィック ポートレート、キャパシティ ポートレートを含み、複数の次元でサービスのパーソナライズされた特性を表します。
-
弾力性戦略: 予測弾力性、負荷フィードバックの弾力性、タイミングの弾力性など、さまざまなシナリオのスケーリング戦略は、サーバーレスを実装するための基本的なコア戦略です。
-
クラウドネイティブ コンポーネント: PaaS と ALM (アプリ ライフサイクル マネージャー) を含みます。PaaS はサービスのスケーリング アクションの実行を担当し、ALM はサービスに関連するすべてのデータとポリシーの管理を担当します。
-
リソース: グループ クラウドとパブリック クラウドの 2 種類のエラスティック リソースを含み、サーバーレスは 2 種類のクラウド リソースに関連するサービス スケーリングをサポートします。
-
安定性保証: エラスティック検査、容量検査、ステータス検査、ワンクリック介入など、エラスティック スケーリングの安定性を確保するためのさまざまなメカニズム。
-
スケーラブルなプラットフォーム: リソースの事前チェック、プロセス オーケストレーション、ステータス ローテーション、イベント エンジンなどの基本的なメカニズムを含む、全体的な戦略を実装するためのサポート プラットフォーム。
次に、サービス ポートレート、柔軟な戦略、安定性の保証など、コア戦略とプラクティスを紹介します。
04 サービスポートレート
Baidu フィードのバックエンドには多くのサービスが含まれています.各サービスの辞書ファイルのサイズは異なります.一部のサービスは CPU 計算が多く、他のサービスは IO が多くなっています.サービスごとにスケーラビリティ、トラフィックの変動、および負荷容量に違いがあります. したがって、サービスのオンライン操作データを中心に、弾力性、トラフィック、および負荷の次元からパーソナライズされた弾力性のあるポートレート、トラフィックのポートレート、および容量のポートレートを構築し、各サービスのパーソナライズされた特性を多次元で記述します。
4.1 エラスティック ポートレート
目標: スケーラビリティの観点から、サービスのスケーラビリティについて説明します。クラウド ネイティブの指標、サービス インスタンスの仕様、インスタンスの展開と移行の時間、リソースの依存性、およびサービスの弾力性を表すその他の側面に基づいて、ビジネスのサービスは次の 3 つのカテゴリに分類されます。
高弾性: 完全にステートレスなサービスで、損失なく自由にスケーリングでき、スケーリング速度が速い。
中程度の弾力性: ある程度のスケーラビリティがありますが、サービス状態の復元に時間がかかり、スケーリング速度は平均的です。
弾力性が低い: スケーラビリティがほとんどなく、サービスの状態を復元するために多額のコストが必要であり、スケーリングの速度が遅い。
伸縮性のあるポートレート構造:
各サービスについて、PaaS から複数の最近のインスタンス拡張レコードを取得してインスタンス拡張時間を取得し、中央値をサービスのインスタンス展開時間として取り、サービスのインスタンス クォータ (CPU、メモリ、ディスク) を組み合わせます。状態、存在するかどうか、外部依存関係、単純なルールを使用してすべてのサービスを高、中、低の弾力性のある機能に分類すると同時に、サービスの弾力性を向上させるために、標準化されたコンテナー変換とストレージとコンピューティングの分離を行うようサービスを促進します。
回復力の向上:
-
標準化されたコンテナーの変換: Baidu フィード ビジネスのサービス インスタンスのほとんどは、以前は標準化されていないコンテナーであり、ポートの分離とリソースの混合に欠陥があり、ストレージとコンピューティングの分離をサポートできず、全体的な展開と移行の効率に影響を与えていました。サービスの標準化されたコンテナー変換を促進することにより、各サービスは既にリソース プール間およびクラウド間スケジューリング展開をサポートしており、各リソース プールの断片化されたリソースを最大限に活用し、リソース配信効率と混合展開機能を改善し、効果的に実行できます。サービスの柔軟なスケーラビリティを向上させる
-
ストレージとコンピューティングの分離: 大規模な辞書ファイルを使用するバックエンド サービスでは、時間のかかるサービス拡張は辞書ファイルのダウンロードと解凍に集中します.この種のサービスをクラウド ディスク共有ボリュームに接続し、辞書コンテンツをサービス インスタンスが展開されたときにリモートで読み取ることができます. メモリに読み込まれるため、時間のかかる辞書ファイルのダウンロードと解凍が削減され、サービスの展開とインスタンスの移行時間が大幅に改善され、サービスの弾力的なスケーラビリティが効果的に向上します
4.2 トラフィック プロファイル
目標:
サービスのトラフィックの変化傾向を説明し、将来のある時点でのトラフィックを予測し、トラフィックに応じて対応する容量を構成します。
トラフィック プロファイルの構築:
-
CPU 使用率: トラフィック プロファイルは過去のトラフィック データに基づいて将来のトラフィック データを予測しますが、qps データを直接収集するのではなく、qps の代わりに CPU 使用率を使用します。主な理由は、通常、バックエンド サービスには複数の rpc/http インターフェイスがあり、異なるサービスのインターフェイスの数が異なり、サービス内の異なるインターフェイスの qps とパフォーマンスが異なり、単一のインターフェイスの qps インデックスが反映できないためです。サービスの全体的なリソース消費. これにより、qps データのリソース消費と複数のインターフェイスを使用するサービスとの間のマッピングを確立することが困難になります。バックエンド サービスの主なリソース オーバーヘッドは CPU であり、サービスの CPU 使用率は各サービスの単一の一般的な指標であり、複数のインターフェイス リクエストを処理するときのサービスの全体的なリソース オーバーヘッドを直接反映するため、この指標はより正確になる可能性があります。 qps サービスのキャパシティ要件を直接特徴付けます。
-
タイム スライス: 通常、バックエンド サービスのトラフィックは 24 時間で定期的に変動します。1 日 24 時間を複数のタイム スライスに分割します。サービスごとに履歴データをカウントします (たとえば、過去 N 日間の各タイム スライスの対応するトラフィック履歴データに基づいて、将来の特定のタイム スライスの交通状況を予測します。たとえば、24 時間を 24 のタイム スライスに分割し、各タイム スライスが 1 時間に対応する場合、あるサービスの午後 2 時から午後 3 時までの対応するタイム スライスにおける交通状況を予測し、過去 7 日間 (N=7 ) サービスは、午後 2:00 から午後 3:00 までのトラフィック データを予測します。このうち、タイム スライスのサイズは設定可能で、タイム スライスの設定が小さいほど、対応する時間範囲は狭くなります.単位時間あたりのトラフィックの変化が大きいサービスの場合は、より小さなタイム スライスを設定でき、トラフィックの少ないサービスの場合は、より小さなタイム スライスを設定できます.変動に応じて、より小さなタイム スライスを構成できます。
-
収集の監視: 各サービスについて、すべてのインスタンスの負荷データ (CPU 使用率などを含む) を定期的に収集し、それらをサービス データに集約して、対応する時間枠 (ウィンドウ サイズは構成可能) でデータを平滑化します。たとえば、インスタンスの CPU 使用率を 10 秒ごとに収集してサービスの CPU 使用率に集計し、1 分間の時間枠内のサービスの CPU 使用率の平均値を、時間に対応するデータとして使用します。時間窓。収集とデータ処理を監視するプロセスでは、絶対中央値差アルゴリズムを使用して、あらゆる種類の異常な異常データ ポイントを排除します。
-
ポートレート構築: サービスごとに、過去 N 日間の各タイム スライスの各タイム ウィンドウに対応する CPU 使用率を計算します.タイム スライスの場合、スライディング ウィンドウを使用して、最大の K ウィンドウ データの平均値をタイム スライスとして取得します.これにより、過去 N 日間の各タイム スライスにおける各サービスの CPU 使用率データを取得できます。同時に、隣接する 2 つのタイム スライスのトラフィック増加率が計算されます。つまり、(次のタイム スライス トラフィック -現在のタイム スライス トラフィック)/現在のタイム スライス トラフィック。追従予測弾力性では、タイムスライスのトラフィックとトラフィックの伸び率から、将来のあるタイムスライスのトラフィックを予測します。
4.3 容量のポートレート
目標:
サービスの容量要件を特徴付けるために、通常はサービスのピーク CPU 使用率に置き換えられます。たとえば、サービスが安定しているときに 60% のピーク CPU 使用率がある場合、サービスの安定性を確保するために少なくとも 40% の CPU バッファーがサービス用に予約されていることを意味します。
容量ポートレートの構築:
-
容量と遅延: サービスのスループットとトラフィックが一定であると仮定すると、サービスの遅延は多くの場合、残りの CPU バッファーに反比例します。つまり、残りの CPU バッファーが少ないほど、遅延は増加します。バイドゥ フィードのビジネス ラインでは、非コア リンクのサービスの遅延がわずかに増加したとしても、システムの送信遅延に直接影響を与えることはないため、コア リンクと比較して、非コア リンクのサービスは-core リンクを予約できます CPU バッファーが少なくなります。
-
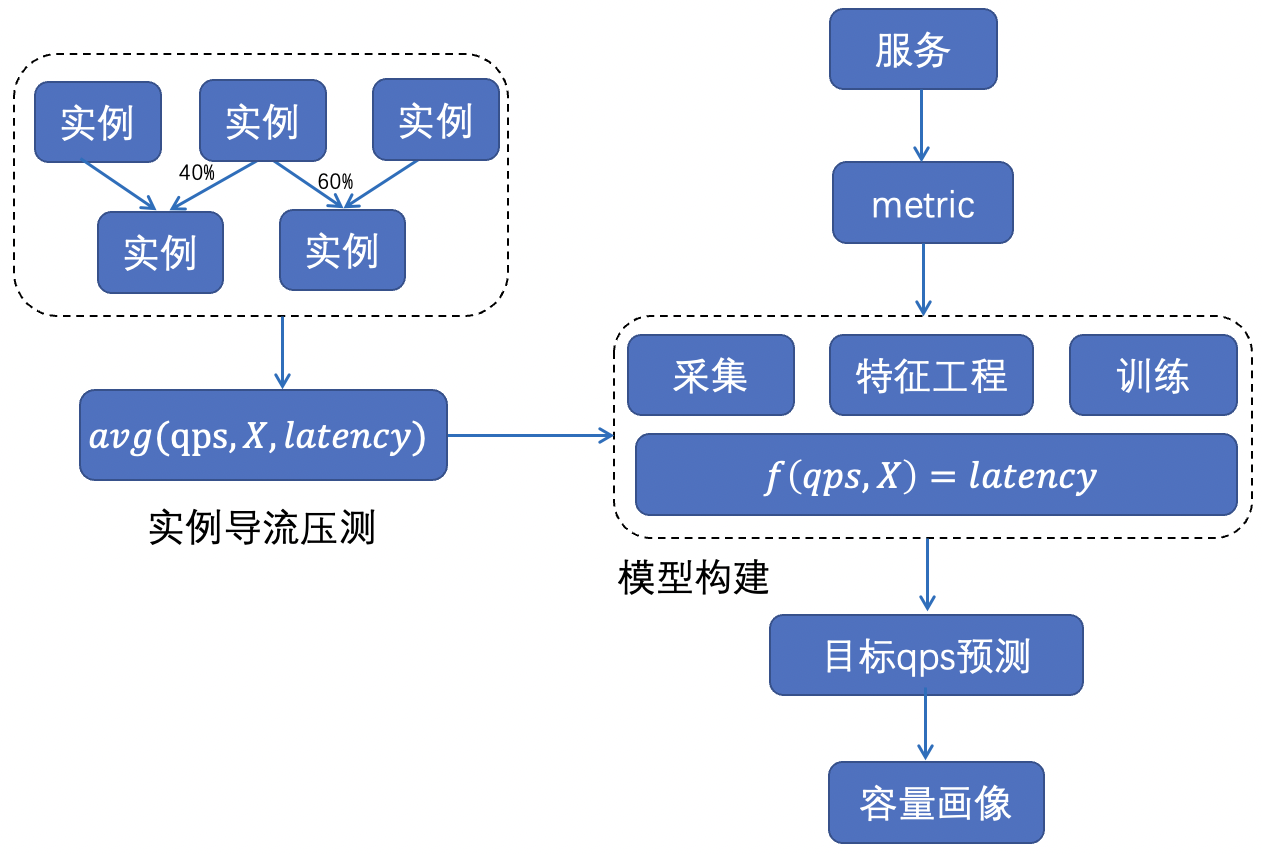
全体的な方法: さまざまなサービスの限界スループットと対応するピーク CPU 使用率は異なります. 全体として, 機械学習方法を使用して各サービスのパフォーマンス曲線を作成し、各サービスの CPU バッファの適切な量を記述します. 全体的な方法は次のとおりです.下の図に示されています。
-
特徴の取得: インスタンスの監視と収集 + インスタンスの迂回圧力の測定を通じて、さまざまな負荷の下でのサービスの遅延データを取得します。
-
モデルの構築: 一連のコンテナーとマシンの監視指標と、サービスの qps、CPU 使用率、マシンの負荷などのサービスの遅延との関係をモデル化します: f(qps, X)=latency。
-
プロファイルの計算: 遅延モデルに基づいて、遅延の許容範囲内で各サービスの最終的なスループットと対応する CPU 使用率を評価します (コア サービスの遅延の増加は許可されず、非コア サービスの遅延の増加は許可されます)。特定のしきい値によって)。
05 柔軟な戦略
さまざまなビジネス スケーリング シナリオに対処するために、次の 3 種類のエラスティック ポリシーを構築して、ビジネスのエラスティック スケーリングをサポートします。
予測弾力性: 弾力性の低いサービスについて、各タイム スライスのトラフィック変動に応じて、将来のトラフィックを予測し、事前にサービス キャパシティを計画および調整します。
負荷フィードバックの弾力性: 弾力性の高いサービスの場合、ほぼリアルタイムのサービス負荷の変化に応じて、サービスの安定性を確保するためにサービス容量が時間内にスケーリングされます。
タイミングの柔軟性: 一部のサービスは、トラフィックのピーク時に大きく変化しますが、オフピーク時にはあまり変化しません. ピーク時には、安定性を確保するために最大容量を提供する必要があります. オフピーク時には、容量を頻繁に調整する必要はありません.タイミングの柔軟性はピーク期間中にもたらされます.ピーク期間の前にスケールアップし、ピーク期間の後にスケールダウンし、ピーク期間とオフピーク期間に同じ容量を維持します.
5.1 予測弾力性
目標:
サービスによって構成されたタイム スライスに従って、将来のタイム スライスのトラフィックが現在のタイム スライス内で予測され、さまざまなトラフィックの変化に対処するために、予測されたトラフィックに従ってサービスが事前に拡張され、容量が遅延されます。
トラフィック予測:
-
現在の時間については、トラフィック プロファイルの前のタイム スライス トラフィック、現在のタイム スライス トラフィック、および次のタイム スライス トラフィックを組み合わせて計算されます。ここで、前のタイム スライス トラフィック、現在のタイム スライス トラフィック、および次回スライス トラフィックはすべて、過去 N 日間に対応しています タイム スライスの最大トラフィックで、それぞれ prev、cur、next として記録されます。
-
prev、cur、next の関係により、フローの傾向は下図のように 4 つのケースに分けられます。

-
case-1: prev < cur < next 全体のトラフィックは上昇傾向にあるが、現時点では次のタイムスライスのトラフィック増加に備えて事前にキャパシティを拡張する必要がある
-
case-2: prev > cur < next トラフィック全体が減少傾向から増加傾向に転じた; 現時点では、次のタイム スライスのトラフィック増加に備えて、事前に拡張を実行する必要があります
-
ケース 3: prev < cur > next、全体的なトラフィックが上昇トレンドから下降トレンドに反転し、現在のタイム スライスがピーク トラフィック状態にあり、アクションが実行されない
-
ケース 4: 前 > 現在 > 次、全体的なトラフィックは減少傾向にあり、スケーリング アクションが実行されます
拡張/縮小戦略:
-
スケーリングが必要なシナリオ (上記のケース 1、ケース 2、ケース 4 など) では、ターゲット トラフィックを計算します。ここで、ターゲット トラフィック = 最大 (ターゲット トラフィック 1、ターゲット トラフィック 2) です。
-
目標容量 1 は、上記の 4 種類のケースのトラフィックに基づいて計算されます。
-
case-1 と case-2 の場合、対象トラフィック 1 は次と同じです (事前に展開することに相当)。
-
ケース 4 の場合、ターゲット トラフィック 1 は cur に等しくなります (これは、次のタイム スライスのトラフィックに従ってスケール ダウンするためのものではありません。そうしないと、現在のタイム スライスをサポートできない可能性があります。ここでは、以下に従ってのみスケール ダウンします)。現在のタイム スライス トラフィック。これは、遅延の縮小と同等です)。
-
ターゲット トラフィック 2 = 現在のトラフィック * (過去 N 日間の現在のタイム スライスと次のタイム スライスとの間の最大増加率)。ここで、現在のトラフィックは、最新の K 時間ウィンドウに対応する CPU 使用率を収集します。
-
ターゲット トラフィックとサービスのキャパシティ プロファイル (つまり、サービスが予約する必要がある CPU バッファーの量) に基づいてターゲット キャパシティを計算し、ターゲット キャパシティに基づいてサービスのインスタンスのターゲット数を計算し、PaaS をリンクします。サービスを水平方向にスケーリングします。
5.2 負荷フィードバックの弾力性
目標:
サービスのほぼリアルタイムの負荷状況に応じて、トラフィックの急激な変化に対応できるようにサービス容量が調整されます。
拡張/縮小戦略:
-
データ収集:
-
一般的な監視: CPU 使用率、CPU 使用率など、サービスの一般的な負荷をほぼリアルタイムで収集します。
-
カスタム監視: Prometheus メトリック モードで、サービス遅延インジケーター、スループット インジケーターなどのカスタム ビジネス監視インジケーターをサポートします。
-
収集期間は設定可能で、通常はスライディング ウィンドウ方式を使用して監視指標を集計および判断します。
-
拡張/縮小の決定: サービスの一般的な負荷データとカスタム負荷データに従って、サービスのキャパシティ ポートレートと組み合わせて、サービスに必要なインスタンスの目標数を計算し、水平方向の拡張と縮小操作を実行します。
5.3 タイミングの柔軟性
目標:
一部のサービスのトラフィックは、オフピーク期間中の変動が少なくなります. 頻繁な容量調整は必要なく、固定されていますが、ピーク期間とオフピーク期間では異なる容量が予想されます.
拡張/縮小戦略:
-
トラフィック プロファイルのピーク期間と非ピーク期間の対応するタイム スライスの最大フローを計算します。
-
最大トラフィックとキャパシティ プロファイルに基づいて、サービスのピーク時とオフピーク時に対応するターゲット キャパシティを計算します。
-
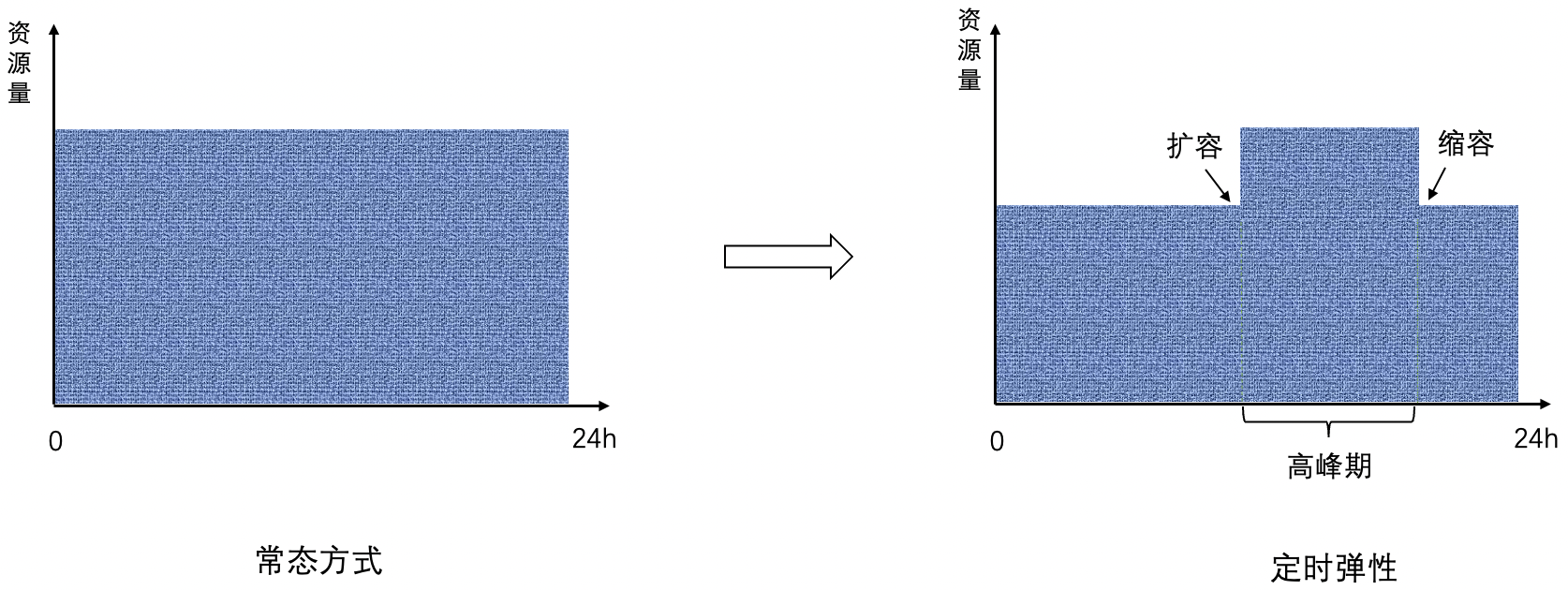
目標容量に応じて、ピーク時前に定期的に拡張動作(横展開)を行い、ピーク時以降に定期的にスケーリング動作(横スケーリング)を行い、全体の効果を下図に示します。
5.4 回復力の実践
-
上記の 3 種類のエラスティック ポリシーは、構成に応じて個別に使用することも、必要に応じて組み合わせて使用することもできます。
-
弾力性の高い関数型コンピューティングでは、負荷フィードバックの弾力性を使用して FaaS 効果を実現できます。
-
3 種類の戦略を組み合わせて使用すると、すべてサービス インスタンスの数を調整して同時に有効になるため、3 種類の戦略のうち、タイミングの弾力性 > 予測の弾力性 > 負荷フィードバックの弾力性が優先されます。
-
ロード フィードバックの弾力性を予測の弾力性またはタイミングの弾力性と組み合わせて使用する場合、ロード フィードバックの弾力性は拡張アクションのみを実行でき、容量を縮小することはできず、容量のスケーリングは予測の弾力性またはタイミングの弾力性によって実行されます。サービスの CPU 負荷が比較的低い場合、次のタイム スライスのトラフィックを事前に準備するための予測弾力性の拡張が原因である可能性があるため、このとき、負荷に応じて容量を縮小することはできません。フィードバックの弾力性と同じことがタイミングの弾力性にも当てはまります。
-
再試行メカニズム:
-
予測の弾力性とタイミングの弾力性の実行頻度は低く、いくつかのポリシー計算と PaaS を呼び出してサービス インスタンスの数を変更する必要があります.全体的な操作はアトミックではなく、再試行メカニズムが必要です。
-
負荷フィードバックは高頻度で弾力的に実行され、サービス要件に従ってオンデマンドで再試行できます。
-
ターゲット容量の検証: サービス ターゲット インスタンスの数を変更するには、上記の各エラスティック ポリシーを検証する必要があります。
-
妥当な範囲内でターゲット インスタンスの数を制限します。インスタンスのターゲット数を、各サービス キャパシティ プロファイルで構成されたインスタンスの上限および下限と比較し、それを超える場合は、上限および下限のしきい値まで平滑化します。
-
1 回の拡張と縮小のステップ サイズを制限する: インスタンスの目標数を現在のインスタンス数と比較し、各拡張と縮小の比率を制限し、1 回の拡張が多すぎてリソースが不足するのを防ぎ、縮小しすぎてリソースが不足するのを防ぎます。急増する単一インスタンスのトラフィック メモリ不足が発生します。
06 安定保証
大規模なサービス容量を頻繁かつ動的に調整しながら、サービスの安定性を確保する方法は非常に重要です.私たちは、検査と介入ストップロスの観点から対応する安定性機能を構築し、検査によって問題が発生する前に防止し、ワンストップで迅速に停止します.クリック介入ダメージ。
弾力性検査: サービス インスタンスの移行を定期的にトリガーし、サービスの弾力性をテストし、辞書ファイルの依存関係の例外によって引き起こされるスケーリングの失敗を事前に明らかにします。
キャパシティ検査: さまざまなサービスのアラーム ポリシーを構成し、各サービスのリソース キャパシティを定期的に検査し、キャパシティが不十分な場合にアラームまたはワンクリック プランをトリガーします。
状態検査:サービスの異常状態を未然に防ぐため、各サービスの状態が正常に巡回しているかどうかを確認します.例えば、ピーク時とオフピーク時ではサービスのキャパシティ状態が異なります.
ワンクリック介入: サーバーレス プランからのワンクリック終了、ワンクリックでのオープン/クローズ インスタンスのソフトおよびハード リミット プランなどを含む、迅速なストップ ロス機能、容量の低下を防ぐための定期的なオンライン ドリルを提供します。
07 まとめ
全体的な作業はサーバーレスを中心に行われます. 各サービスのパーソナライズされた特性は、弾力性、トラフィック、および容量のサービス ポートレートを通じて記述されます. ポートレートに基づいて、さまざまなサービス拡張シナリオに対応し、効果的に実現するために、複数のタイプの弾力的なポリシーが構築されます.サービス リソースのオンデマンド使用。現在、サーバーレスは 100,000 サービス インスタンスの規模で Baidu フィード ビジネス ラインに上陸し、ビジネス運営コストを効果的に削減しています。
次に、サーバーレスは 2 つの方向性に焦点を当てます: ホット イベントのキャパシティ保証とトラフィック プロファイル予測の精度を向上させるための機械学習の適用、およびビジネスに価値を生み出すための大規模サービスへの継続的なアクセスです!
- 終わり -
推奨読書:
パフォーマンス プラットフォーム データ アクセラレーション ロード
Baidu エンジニアがモジュール フェデレーションを理解する
コード記述を簡素化するための Golang ジェネリックの巧妙な使用