最適化自体の観点から、ディープラーニングトレーニングのBatchSizeと学習率(および学習率削減戦略の影響)
は、モデルのパフォーマンスの収束に影響を与える最も重要なパラメーターです。
学習率はモデルの収束状態に直接影響し、batchsizeはモデルの汎化パフォーマンスに影響します。これら2つは分子と分母に直接関連しており、互いに影響することもあります。
記事ディレクトリ
- 1 Batchsizeがトレーニング結果に与える影響(同じ数のエポックラウンド)
- 結果の比較
- 1. Alexnet 2080s train_batchsize = 32、val_batchsize =64。lr= 0.01 GHIMyousan
- 2. Alexnet 2080 train_batchsize = 64、val_batchsize = 64、lr = 0.01 GHIM-me 14k itera
- 3. Alexnet 2080s train_batchsize = 64、val_batchsize = 64、lr = 0.02 GHIM-yousan
- 4 Squeezenet 2080s train_bs = 64 val-bs = 64 lr 0.01 GH
- 4-再現性実験Squeezenet 2080s train_bs = 64 val-bs = 64 lr 0.01 GHIM-me、結果はまだ87%accをオーバーフィットしています
- 5 == mobilenetv1 2080s t-bs:64、v-bs:64 lr:0.01、GHIM-me == overfitting
- 5 == mobilenetv2 2080s t-bs:64、v-bs:64 lr:0.01、GHIM-me ==オーバーフィッティング
- 6 mobilenetv1 2080 t-bs:64 v-bs:64 lr:0.01 GHIM-me適合
- 6 mobilenetv2 2080 t-bs:64 v-bs:64 lr:0.01 GHIM-me搭載
- 前任者10人がバッチサイズについて語る
- 1 **特定の範囲内で、一般的に言えば、Batch_Sizeが大きいほど、下向きの方向が正確になり、トレーニング振動が小さくなります。**
- 2 ==バッチ時間が長くならないため、バッチサイズのパフォーマンスが低下します。これは本質的にバッチサイズの問題ではありません。同じエポックでのパラメータの更新が減少するため、より多くの反復が必要になります。==
- 3 ==大きなバッチサイズはシャープな最小値に収束し、小さいバッチサイズはフラットな最小値に収束します。==
- 4バッチサイズが増加し、他の人と一緒に学習率が増加するはずです
- 5 Batchsizeのサイズを増やすことは、学習率の減衰を追加することと同じです。
- おわりに
- 1学習率を上げると、バッチサイズも増えるため、収束がより安定します。
- 2多くの研究がより大きな学習率は汎化能力の改善につながることを示しているので、大きな学習率を使用するようにしてください。本当に減衰させたい場合は、バッチサイズを増やすなど、他の方法を試すことができます。学習率はモデルの収束に大きな影響を与え、慎重に調整します。
- 3 bnを使用することの欠点は、小さすぎるバッチサイズを使用できないことです。そうしないと、平均と分散にバイアスがかかります。したがって、現在はビデオメモリが配置できる量と同じです。さらに、実際にモデルを使用する場合は、データを分散して前処理することが非常に重要であり、データが適切でない場合は、これ以上トリックを実行しても意味がありません。
1 Batchsizeがトレーニング結果に与える影響(同じ数のエポックラウンド)
ここでは、GHIM-20を使用します。20のカテゴリの各タイプの画像20枚、合計10000(train9000)(val1000)、および
合計100エポック(9000画像を100回トラバースするのと同じですが、acc(トラバースは反復ごとに10回印刷されます)合計1000 val_list)

ここで使用されるAlexnet(それぞれtrain_batchsize = 32およびtrain_batchsize = 64)
結果の比較
1. Alexnet 2080s train_batchsize = 32、val_batchsize =64。lr= 0.01 GHIMyousan
- 2080sトレーニングs 4.68h、ほぼ28kの反復== 100epoch x 9000/32、各トレインバッチは濃い青の損失を記録します
- val-batchは、val-loss水色を記録します
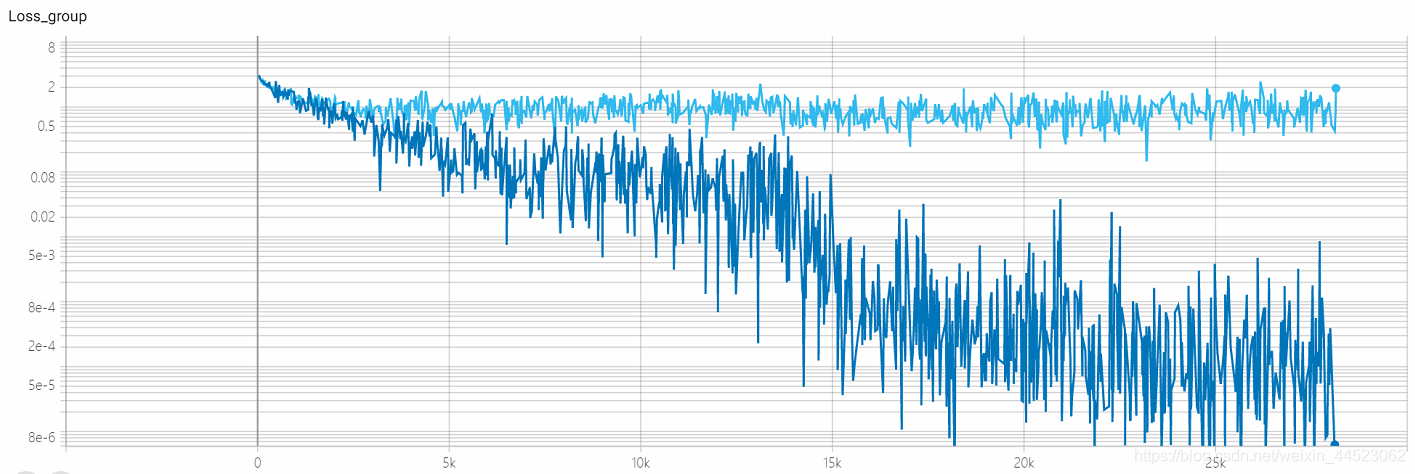
質問:損失は収束していますか?
acc-lossは、train-lossよりも常に大きいため、過剰適合の問題であることがわかります。
いくつかの回答を確認しました
。1. 理論的には収束しません。つまり、設計したネットワークに問題があります。これは、考慮すべき最初の要素でもあります。勾配が存在するかどうか、つまり、逆伝播が壊れているかどうか;
2. 理論的には収束している:-
学習率の設定は不合理です(ほとんどの場合)。学習率の設定が大きすぎると、非収束が発生します。小さすぎると、収束率が非常に遅くなります。
-
バッチサイズが大きすぎると、ローカル最適になり、グローバル最適に到達できないため、収束し続けることができません。
-
ネットワーク容量、複雑なタスクを完了するための浅いネットワークの損失が減少しないことは確かです。ネットワーク設計は単純すぎます。一般に、ネットワーク内のレイヤーの数とノードの数が多いほど、フィッティング能力が強くなります。レイヤーとノードの数が十分でない場合、複雑な状況に対応できないため、収束も発生しません。
学習率ステップの減少のベースは大きすぎず、batchsize = 32は大きくないため、収束していますか??(結局のところ、損失= 0.0008は大きすぎません。)
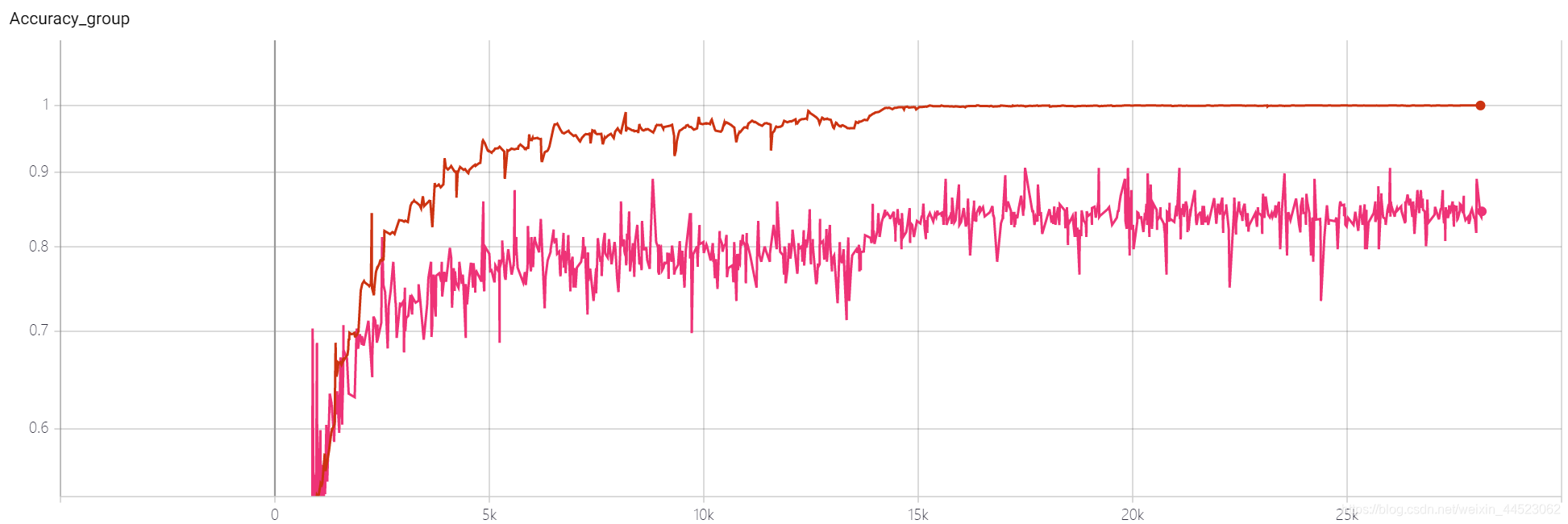
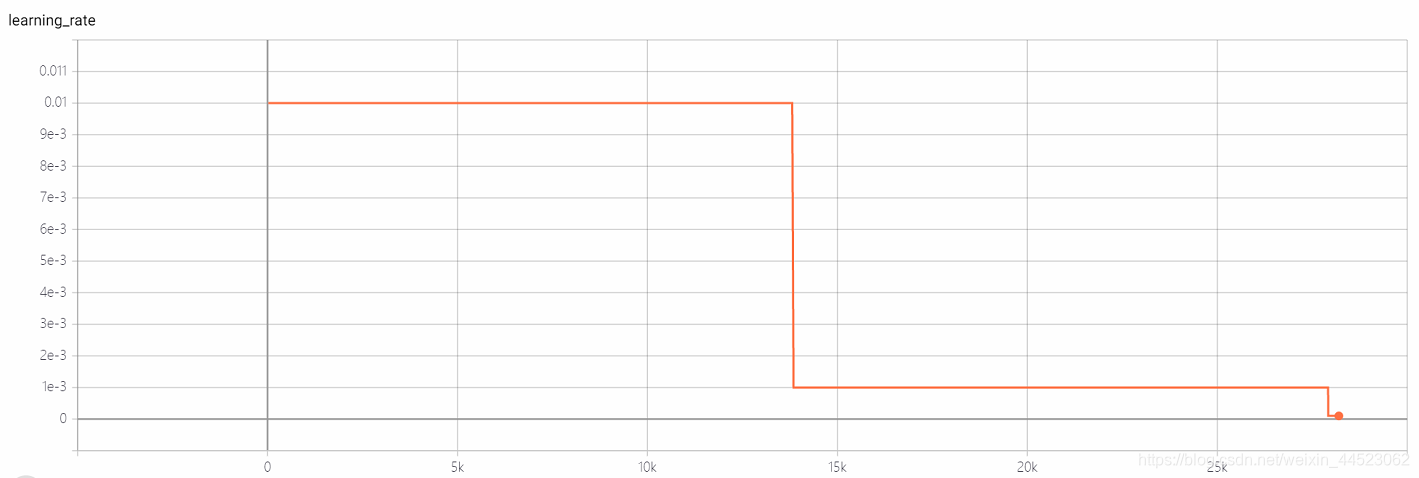
acc曲線は次のとおりです:基本的に、15,000回の反復(つまり、エポック= 15000 * 32/9000 = 53ラウンド)の後で画像を見てフィットします。興味深いのは、学習に対応していることです。レートが0.01から0.001に減少
質問:値のacc84%が上昇しないのはなぜですか
トレーニングセットのパフォーマンスは良好で、テストセットの違いは過剰適合であり、学習された機能がまだ十分に一般化されていないことを示してい
ます。
過剰適合ソリューション
1.理由:- 過剰適合の理由は、トレーニングセットの大きさがモデルの複雑さと一致しないためです。
- トレーニングセットの規模は、モデルの複雑さよりも小さくなります。
- トレーニングセットとテストセットの機能の分布に一貫性がない。
- サンプルのノイズデータ...
2.ソリューション
(より単純なモデル構造、データ拡張、正則化、ドロップアウト、早期停止、アンサンブル、データの再クリーニング)
-
2. Alexnet 2080 train_batchsize = 64、val_batchsize = 64、lr = 0.01 GHIM-me 14k itera
2080 train_batchsize = 64、4.5kの反復は基本的に適合され(4500 * 64/9000 = 32ラウンド)、trainとvalの両方が優れています。そして、フィッティングは良いです
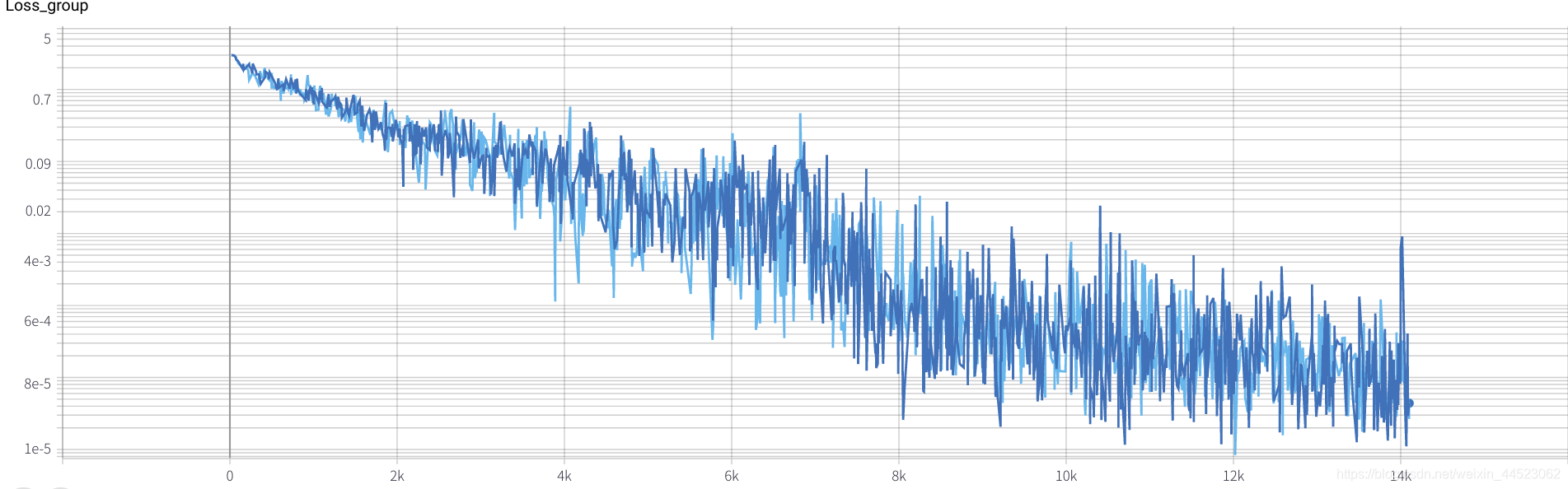
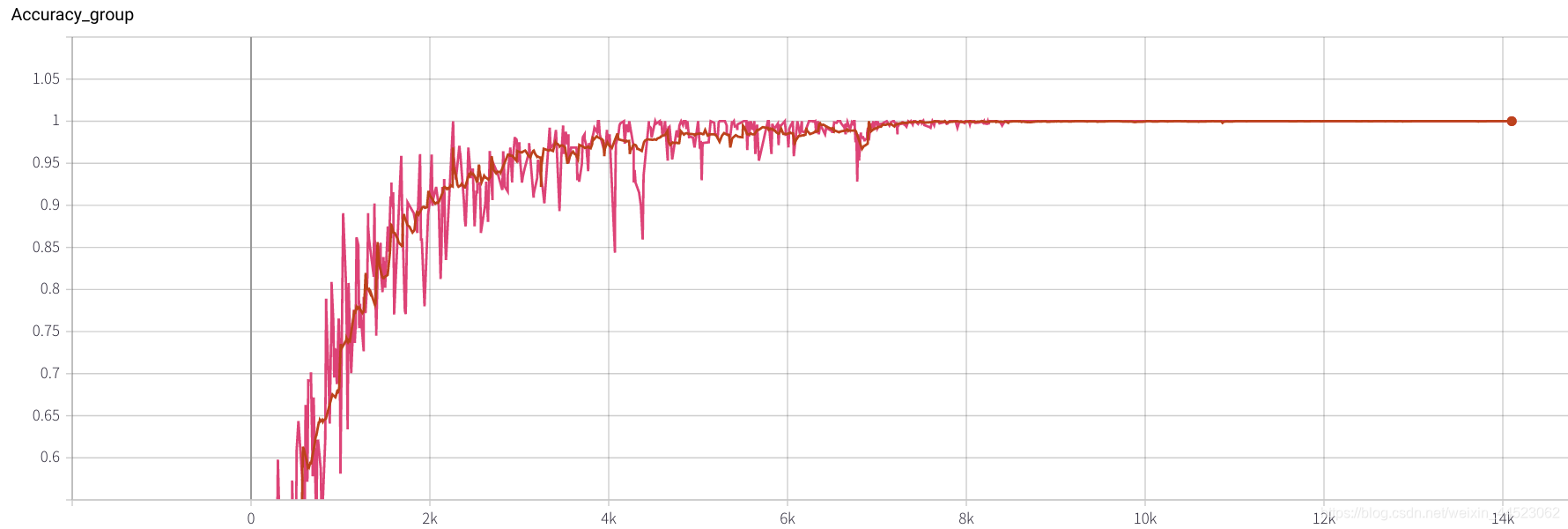
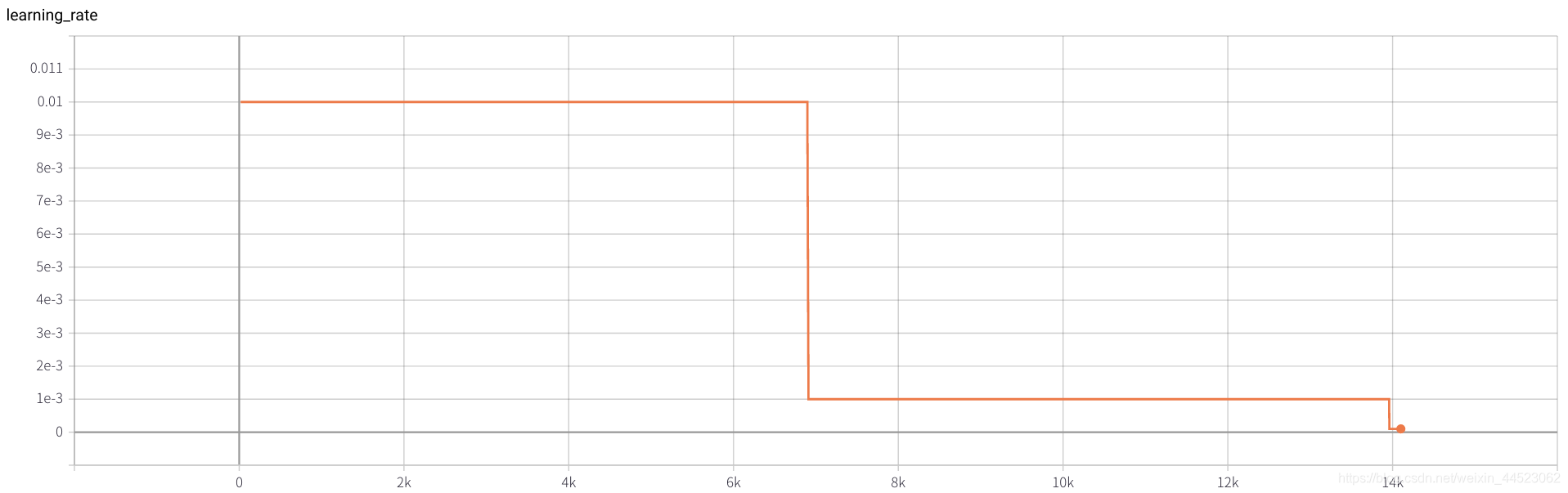
3. Alexnet 2080s train_batchsize = 64、val_batchsize = 64、lr = 0.02 GHIM-yousan
2080年代、収束や過適合はありませんか???
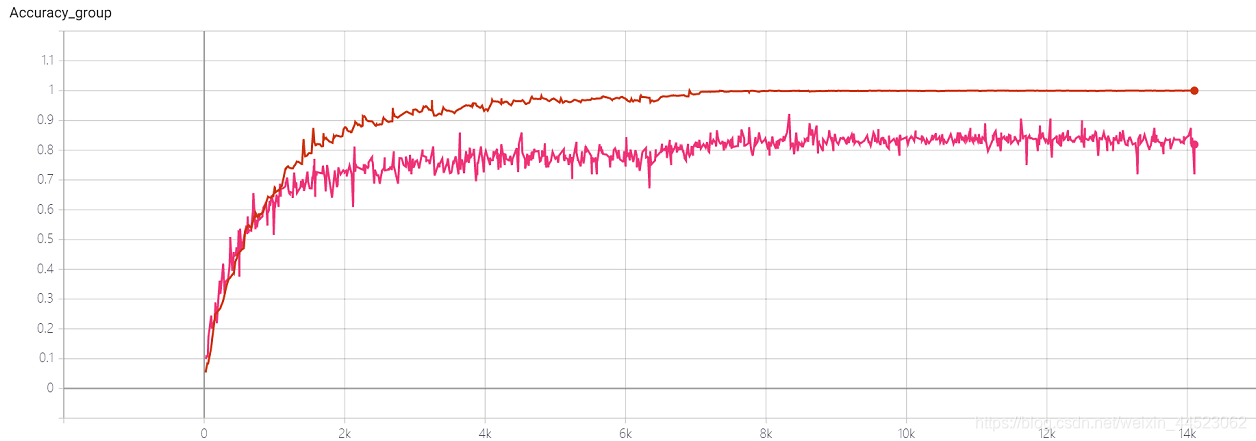
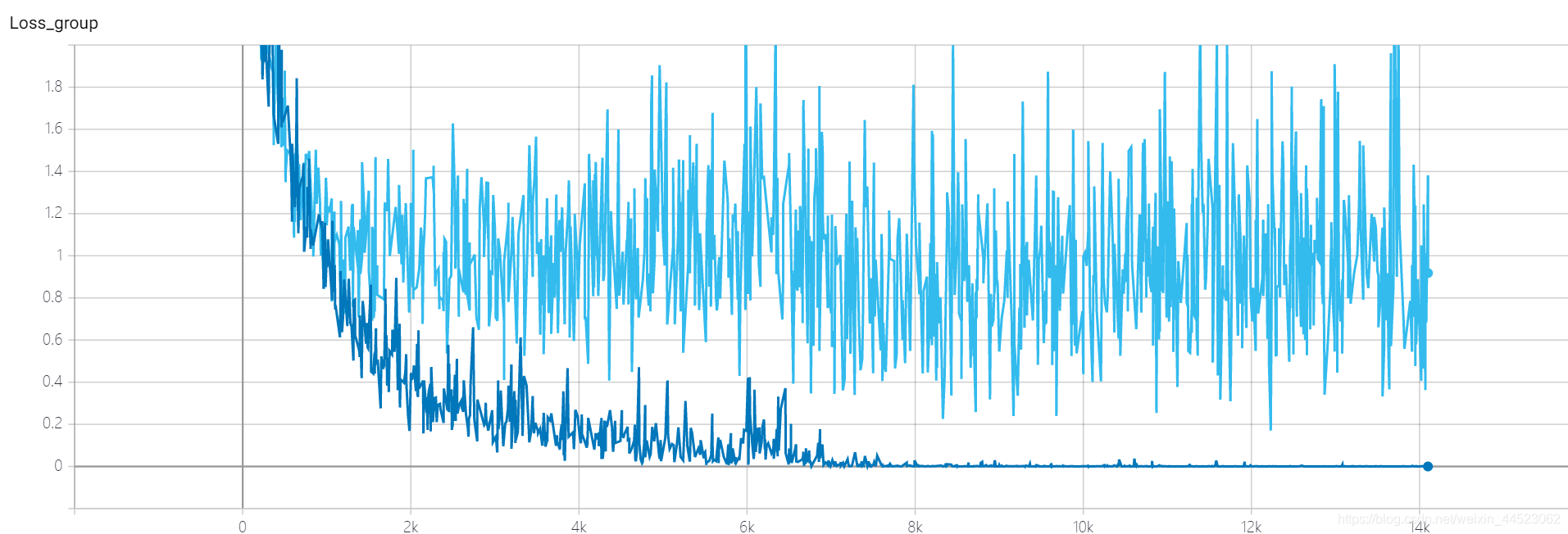
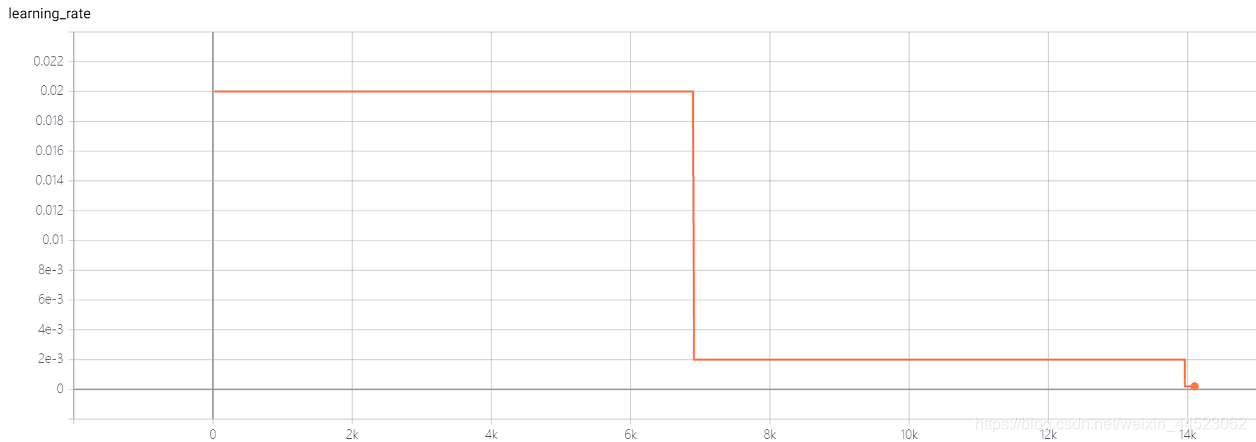
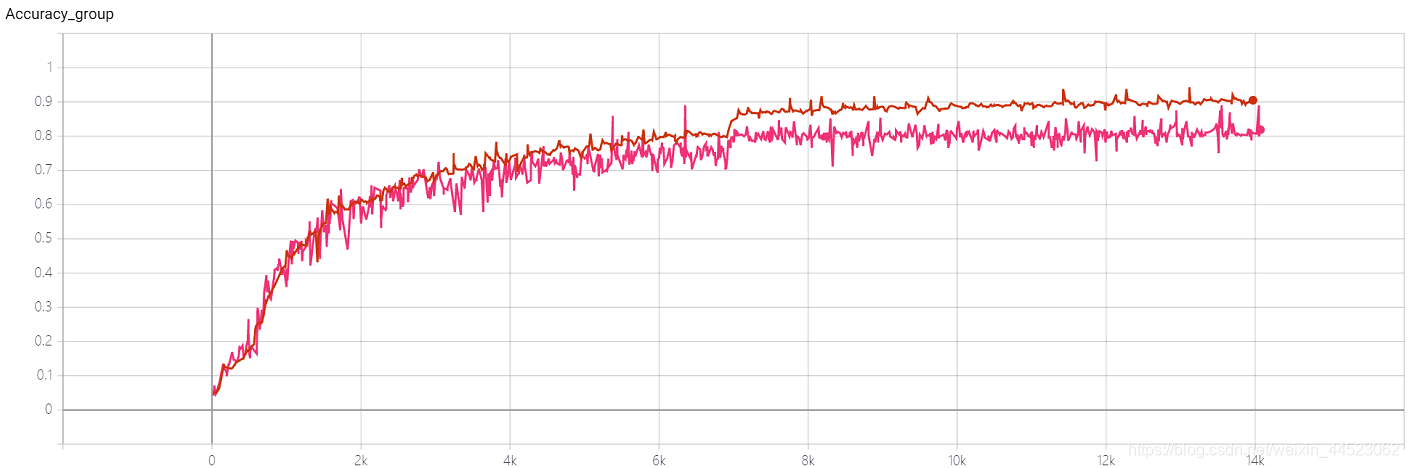
4 Squeezenet 2080s train_bs = 64 val-bs = 64 lr 0.01 GH

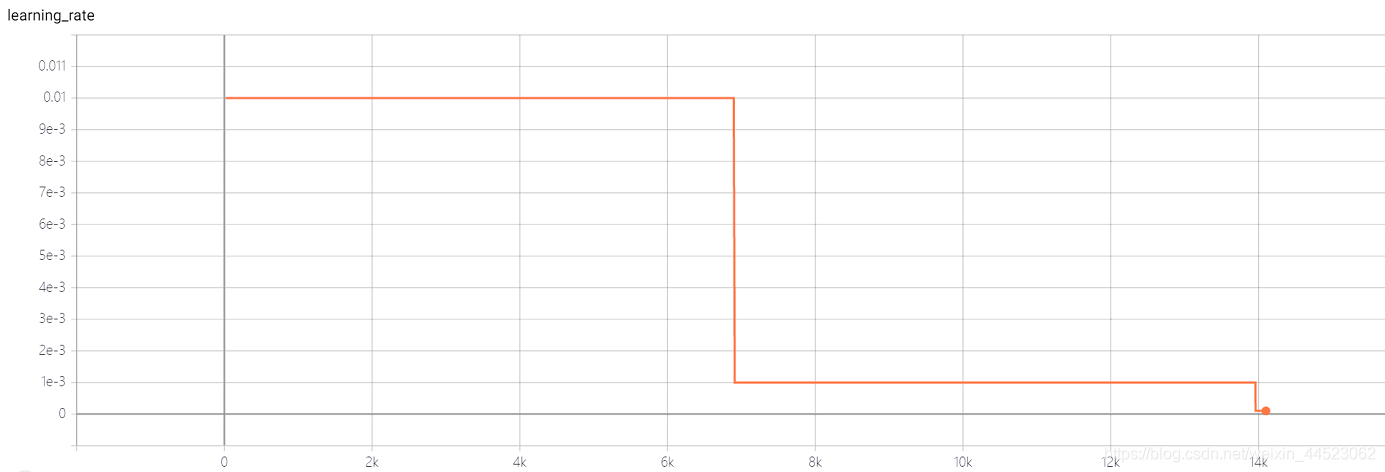
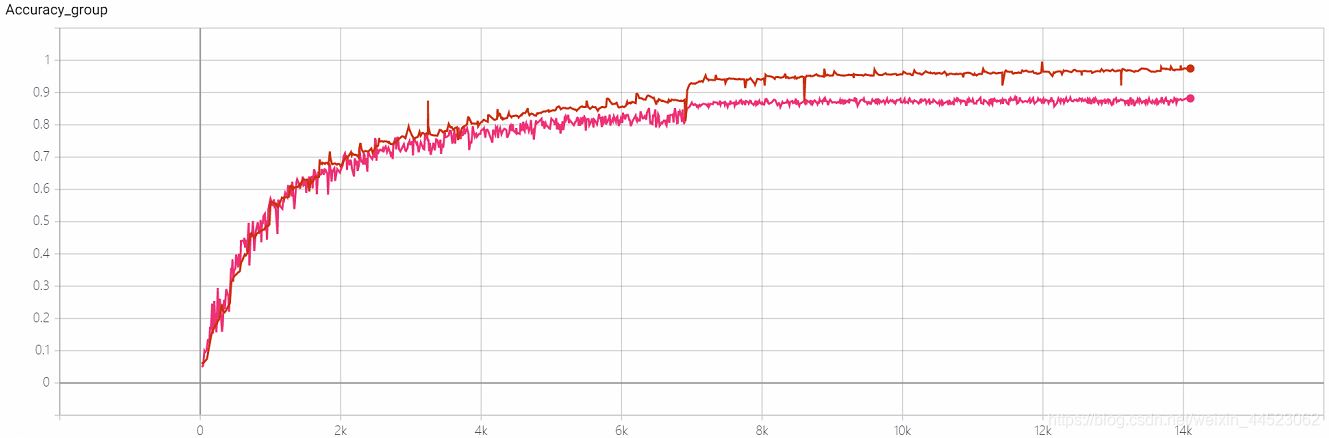
4-再現性実験Squeezenet 2080s train_bs = 64 val-bs = 64 lr 0.01 GHIM-me、結果はまだ87%accをオーバーフィットしています
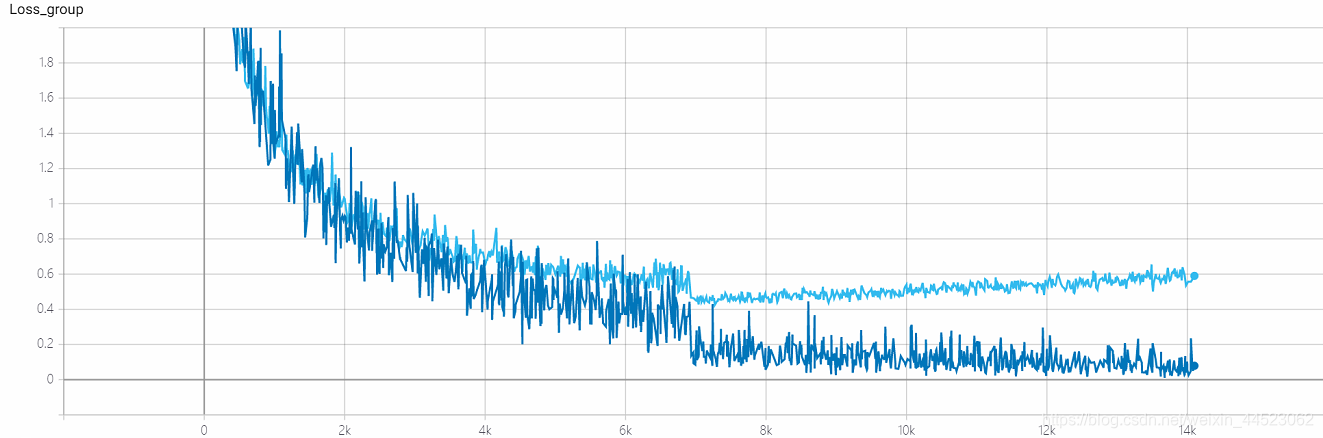
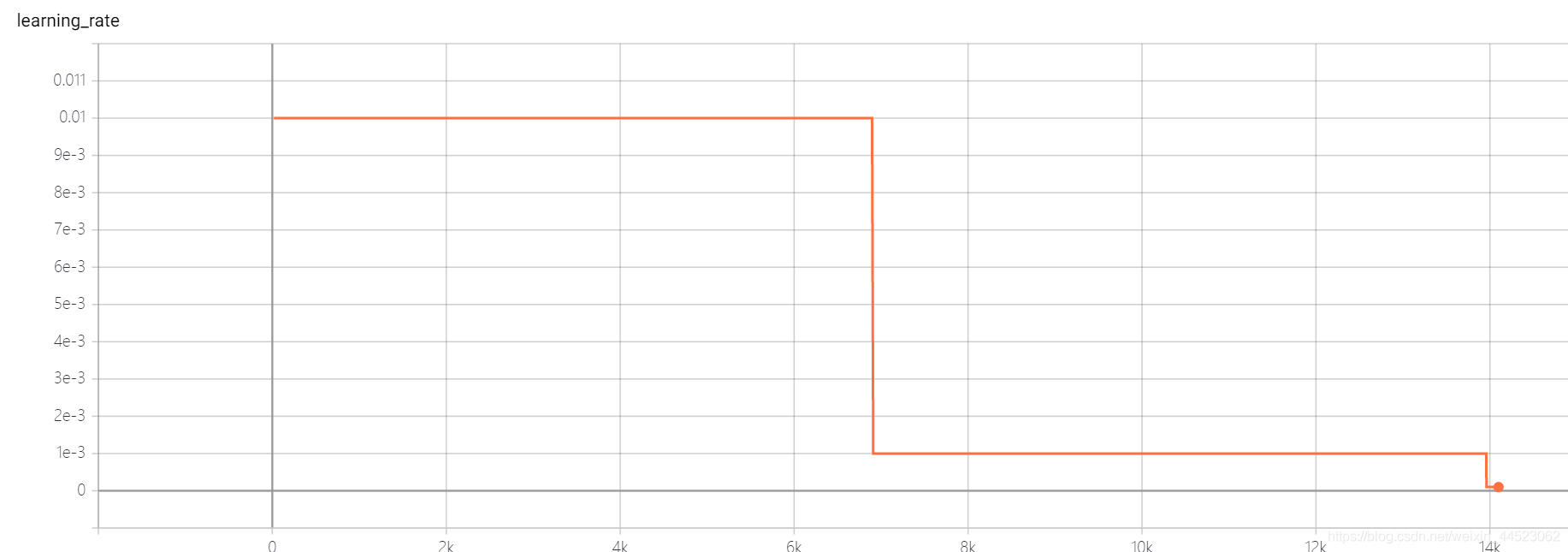
5 mobilenetv1 2080s t-bs:64、v-bs:64 lr:0.01、GHIM-me過剰適合
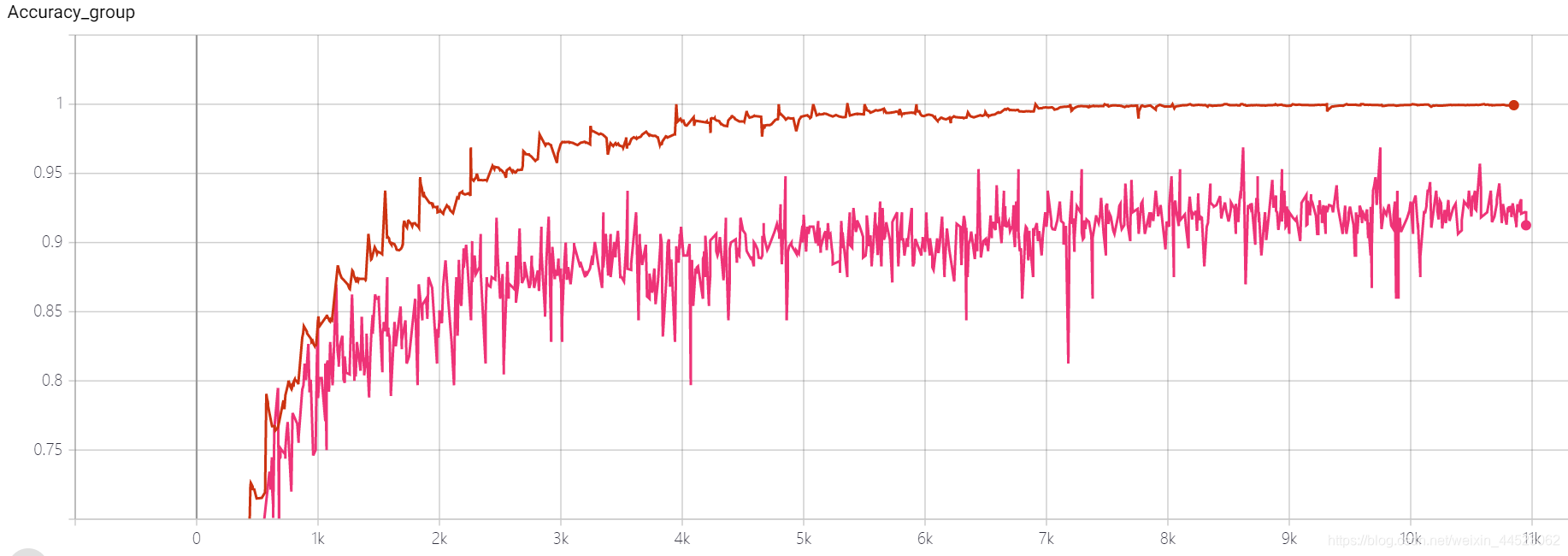
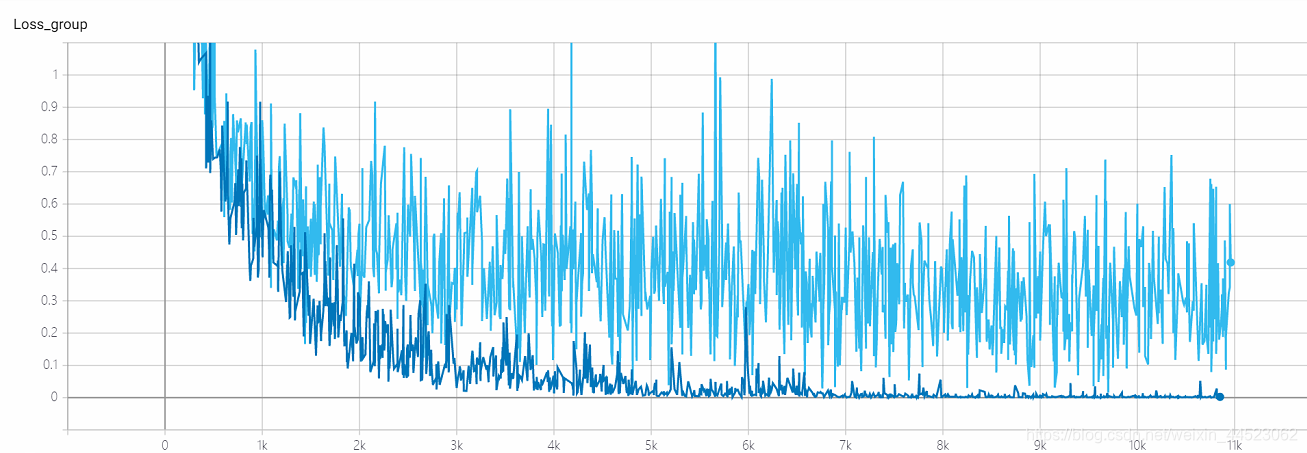
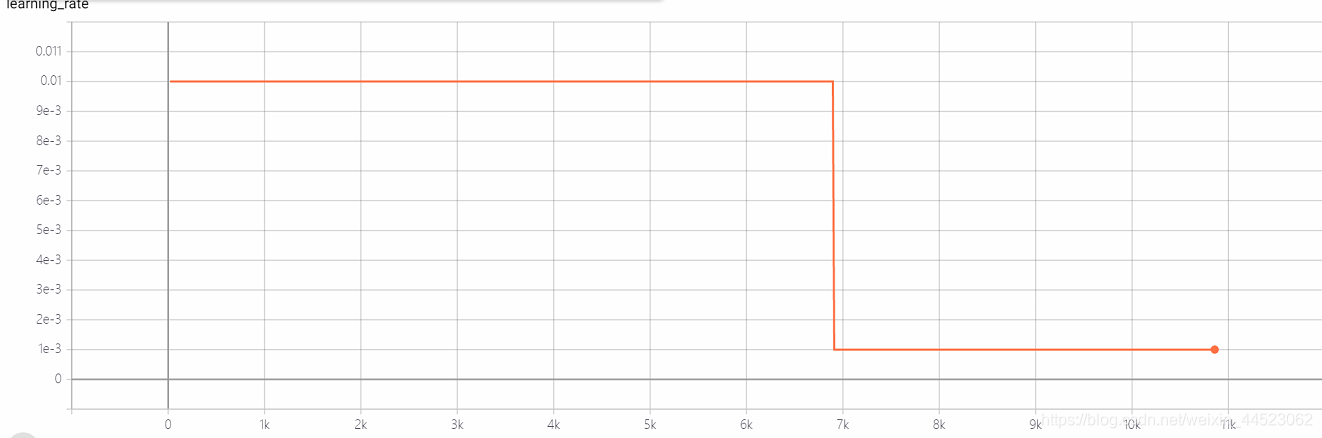
5 mobilenetv2 2080s t-bs:64、v-bs:64 lr:0.01、GHIM-me過剰適合
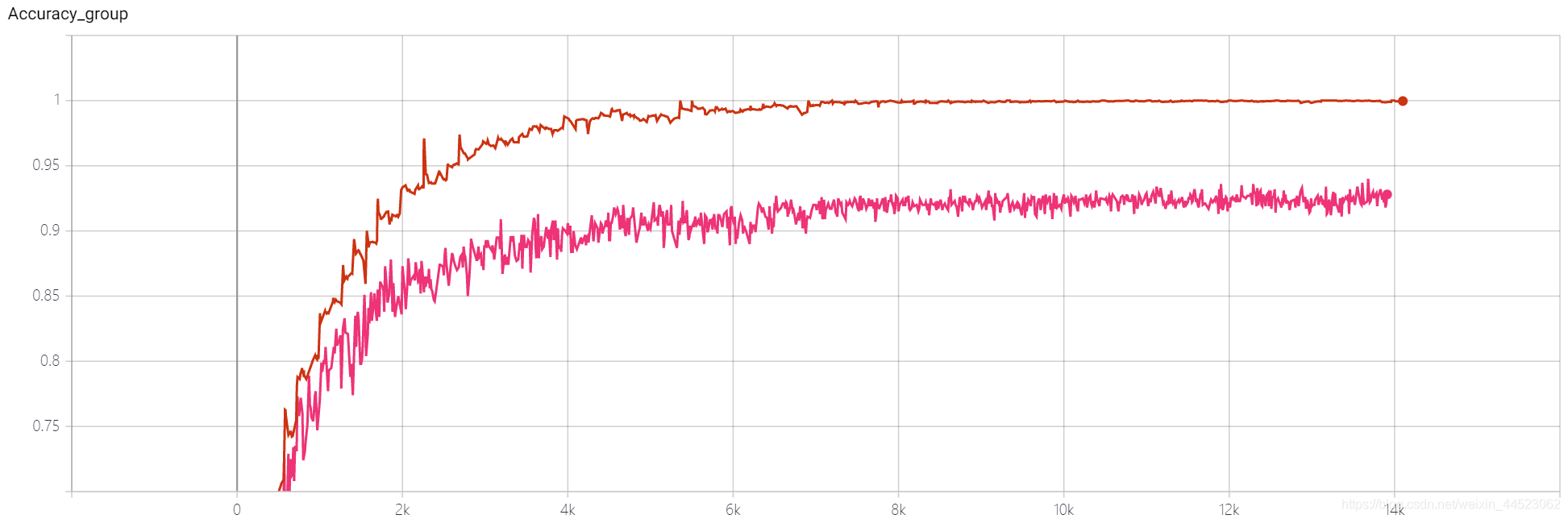
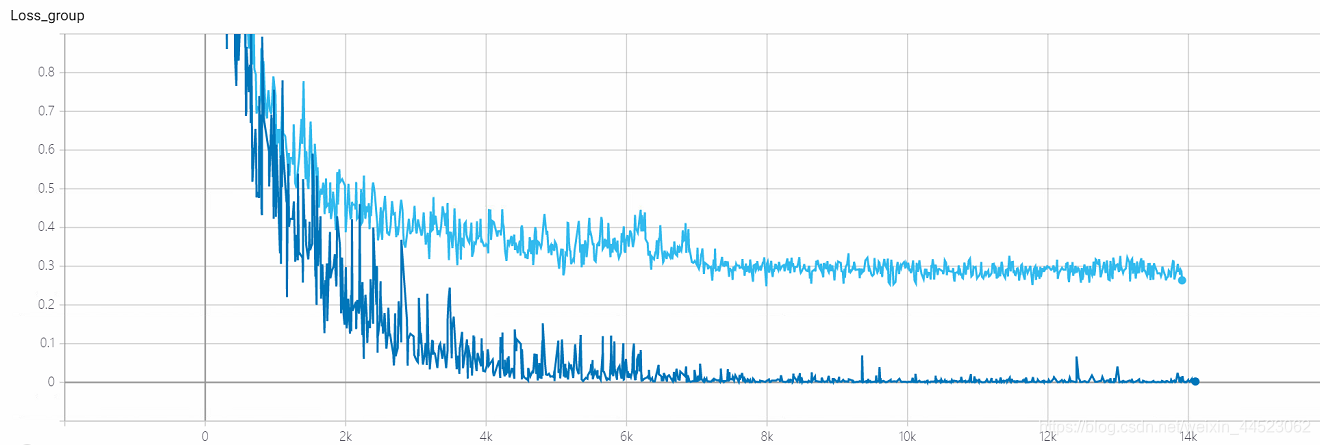
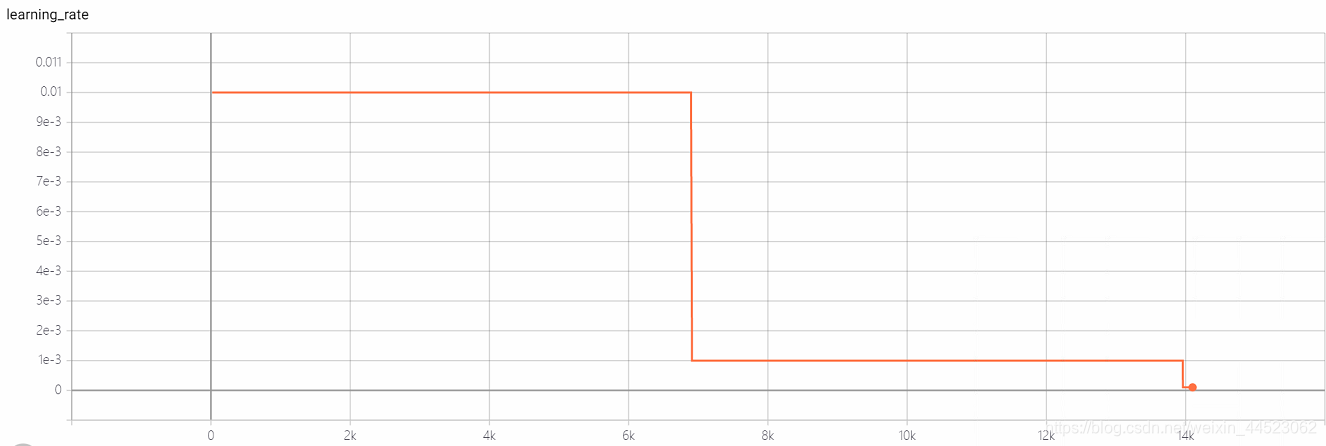
6 mobilenetv1 2080 t-bs:64 v-bs:64 lr:0.01 GHIM-me適合
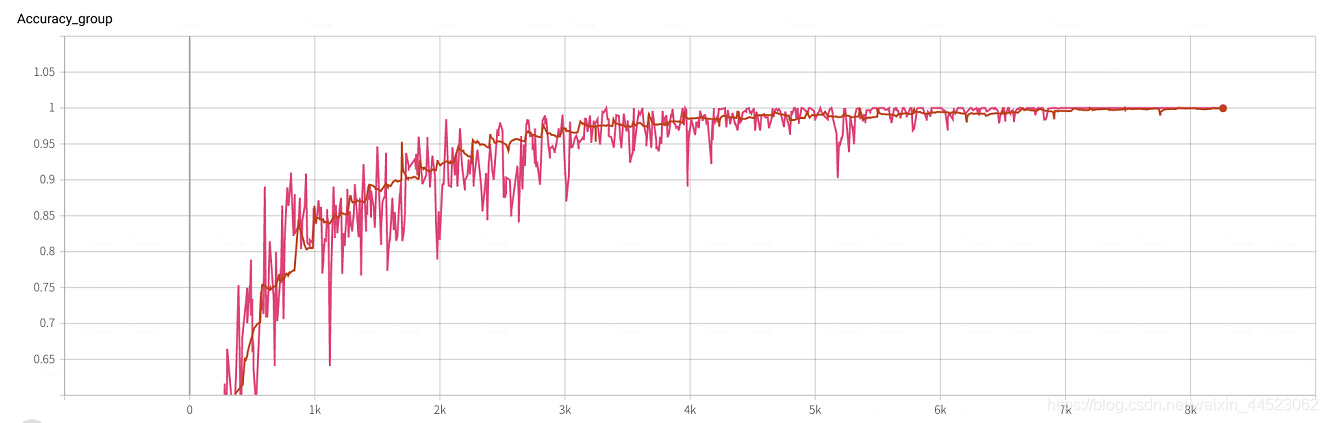

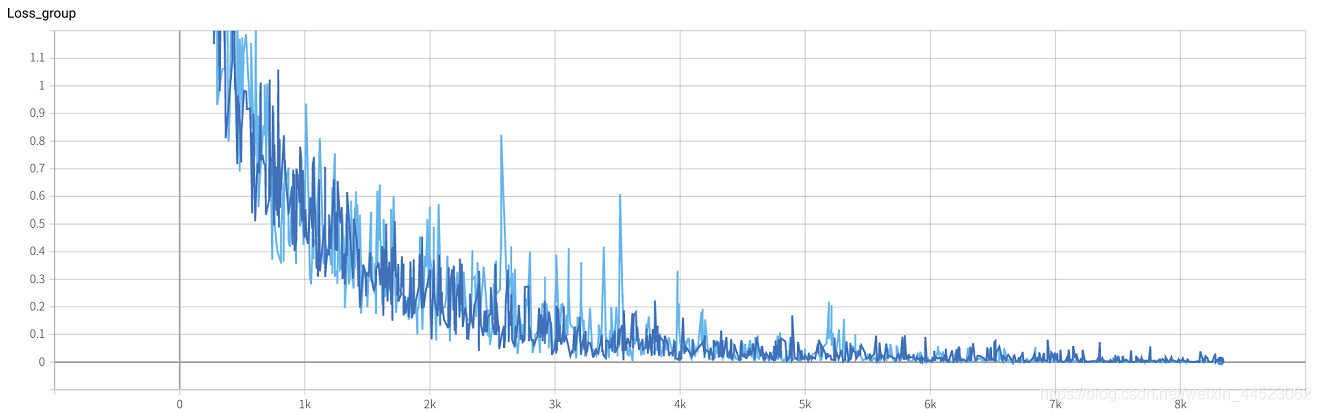
6 mobilenetv2 2080 t-bs:64 v-bs:64 lr:0.01 GHIM-me搭載
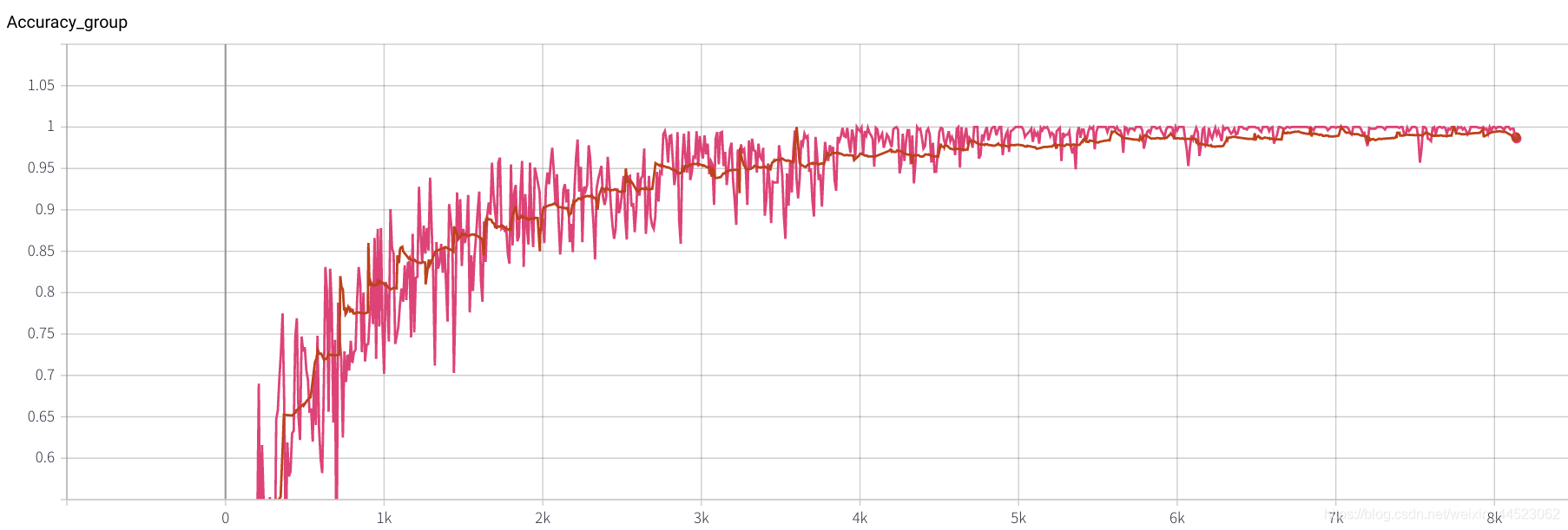
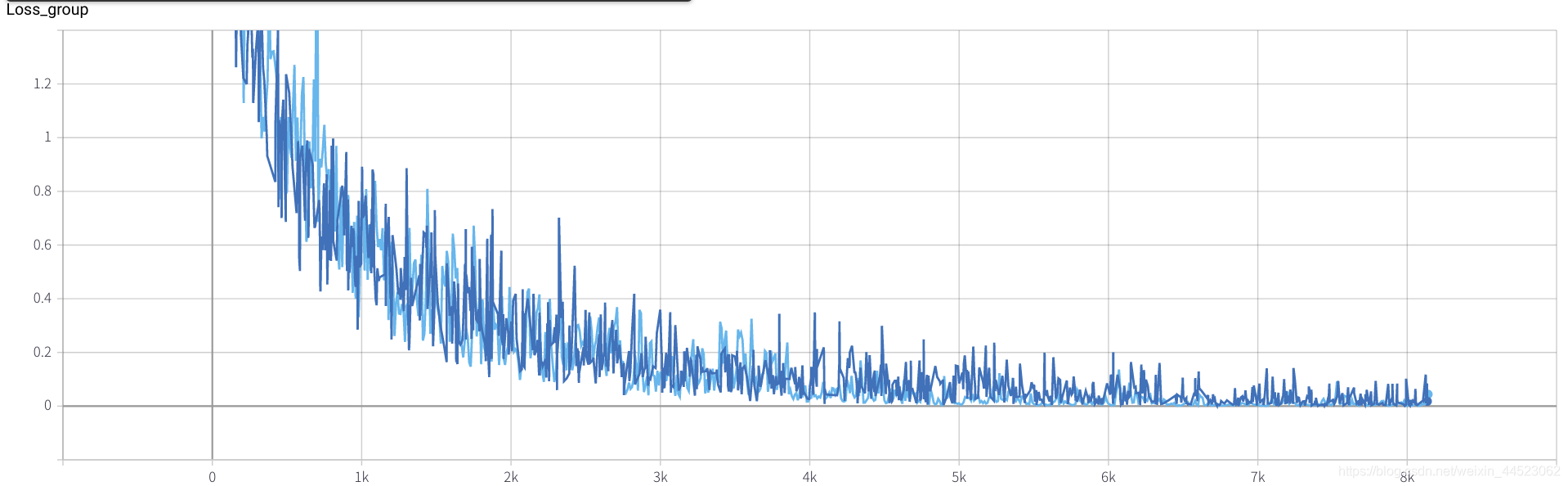
lr = 0.01
前任者10人がバッチサイズについて語る
1 一般的に言えば、特定の範囲内では、Batch_Sizeが大きいほど、下方向が正確に決定され、トレーニングショックが少なくなります。
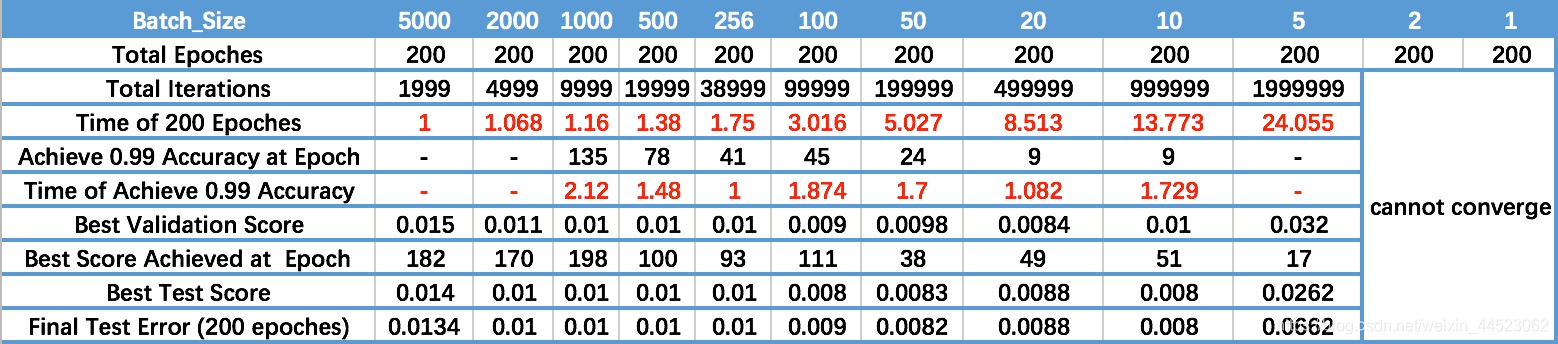
- Batch_Sizeが増加すると、同じ精度を達成するために必要なエポックの数が増加します。最後から2番目の行
- Batch_Sizeが増加すると、同じ量のデータの処理が速くなります。
- 上記の2つの要素の矛盾により、Batch_Sizeは特定のポイントまで増加し、最適な時間に達します。
- 最終的な収束精度はさまざまなローカルの極値に分類されるため、Batch_Sizeは、最適な最終的な収束精度に到達するために数倍に増加します。
2 バッチサイズのパフォーマンスが大幅に低下するのは、トレーニング時間が十分に長くないためです。これは、本質的にバッチサイズの問題ではありません。同じエポックでのパラメータの更新は少なくなるため、より多くの反復が必要になります。
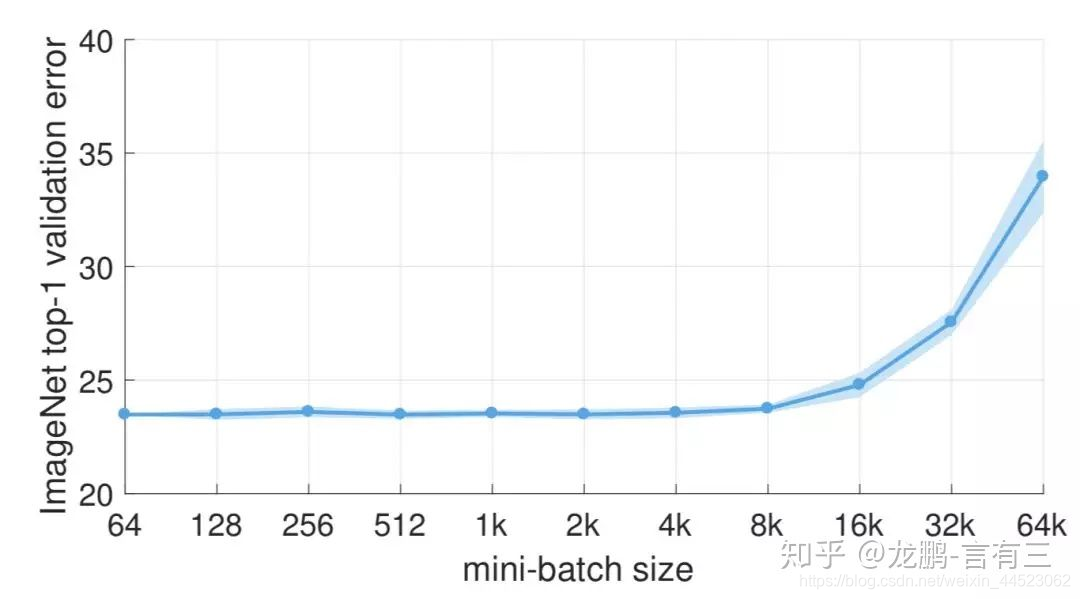
バッチサイズ= 8kの後でエラー率が上昇する
3 大きいバッチサイズはシャープな最小値に収束し、小さいバッチサイズはフラットな最小値に収束します。これにより、汎化能力が向上します。
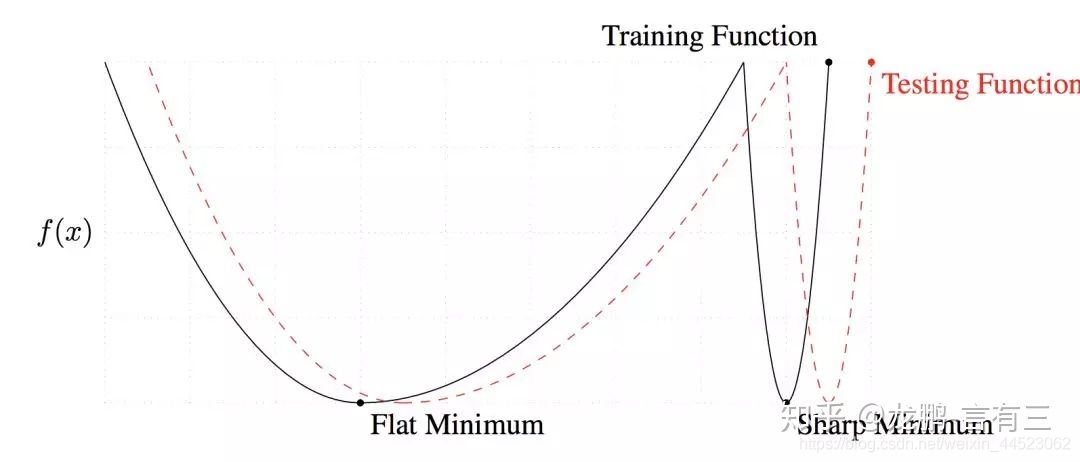
2つの違いは、上に示すように、1つは速く、もう1つはゆっくりと変化する傾向にあります。この現象の主な理由は、小さいバッチサイズによって引き起こされるノイズが鋭い最小値を回避するのに役立つためです。
4バッチサイズが増加し、他の人と一緒に学習率が増加するはずです
通常、バッチサイズを元のN倍に増やす場合、同じサンプルの後に更新された重みが等しくなるようにするには、線形スケーリングルールに従って、学習率を元のN倍に増やす必要があります[5]。ただし、重みの分散を維持する場合は、学習率を元のsqrt(N)倍に増やす必要があります[7]現在、両方の方法が検討されており、前者が主に使用されています。
5 Batchsizeのサイズを増やすことは、学習率の減衰を追加することと同じです。
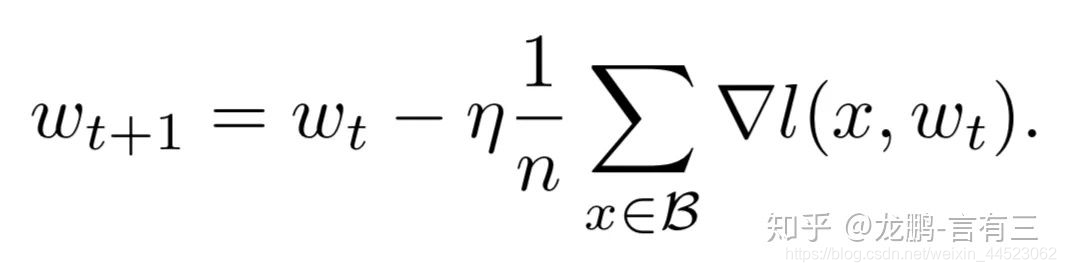
実際、SGDの重み更新式から、2つは実際に同等であることがわかります。これは、記事の十分な実験によって検証されています。
おわりに
1学習率を上げると、バッチサイズも増えるため、収束がより安定します。
2多くの研究がより大きな学習率は汎化能力の改善につながることを示しているので、大きな学習率を使用するようにしてください。本当に減衰させたい場合は、バッチサイズを増やすなど、他の方法を試すことができます。学習率はモデルの収束に大きな影響を与え、慎重に調整します。
3 bnを使用することの欠点は、小さすぎるバッチサイズを使用できないことです。そうしないと、平均と分散にバイアスがかかります。したがって、現在はビデオメモリが配置できる量と同じです。さらに、実際にモデルを使用する場合は、データを分散して前処理することが非常に重要であり、データが適切でない場合は、これ以上トリックを実行しても意味がありません。
参考資料
https://zhuanlan.zhihu.com/p/29247151
https://zhuanlan.zhihu.com/p/64864995
