El estado actual de Apache Spark en iQiyi
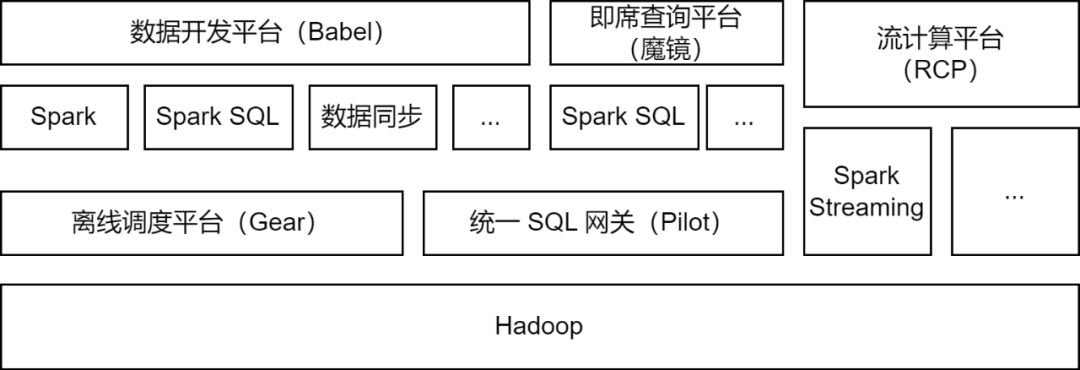
Apache Spark es el marco informático fuera de línea utilizado principalmente por la plataforma de big data iQiyi y admite algunas tareas informáticas de flujo para procesamiento de datos, sincronización de datos, análisis de consultas de datos y otros escenarios:
-
Procesamiento de datos : la plataforma de desarrollo de datos permite a los desarrolladores enviar tareas del paquete Spark Jar o tareas Spark SQL para el procesamiento de datos ETL.
-
Sincronización de datos
: la herramienta de sincronización de datos BabelX de desarrollo propio de iQIYI se basa en el marco informático Spark. Admite el intercambio de datos entre 15 fuentes de datos como Hive, MySQL y MongoDB. Admite la sincronización de datos entre múltiples clústeres y múltiples nubes. configurado Tareas de sincronización de datos totalmente administradas.
-
Análisis de datos : los analistas de datos y los estudiantes de operaciones envían SQL o configuran consultas de indicadores de datos en la plataforma de consultas ad hoc Magic Mirror y llaman al servicio Spark SQL a través de la puerta de enlace SQL unificada Pilot para el análisis de consultas.
Actualmente, el servicio iQiyi Spark ejecuta más de 200.000 tareas Spark todos los días, ocupando más de la mitad de los recursos informáticos generales de big data.
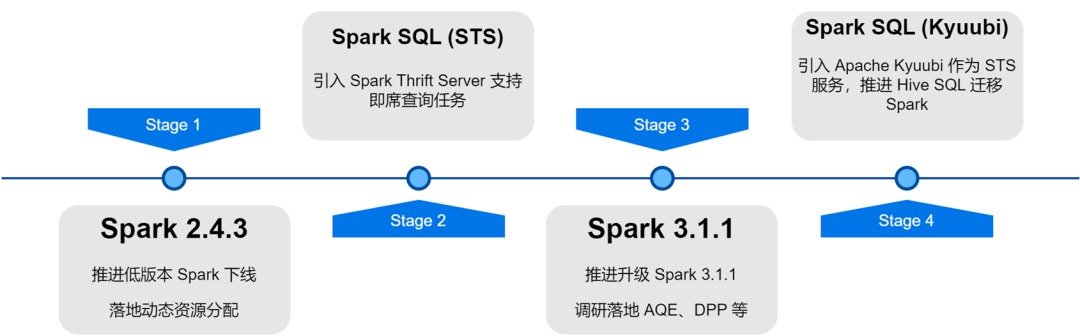
En el proceso de actualización y optimización de la arquitectura de la plataforma de big data de iQiyi, el servicio Spark ha pasado por iteraciones de versiones, optimización de servicios, SQLización de tareas y gestión de costos de recursos, etc., lo que ha mejorado enormemente la eficiencia informática y el ahorro de recursos de las tareas fuera de línea.
Optimización de la aplicación del marco informático Spark
Con la actualización iterativa de la versión interna de Spark, investigamos e implementamos algunas características excelentes de la nueva versión de Spark: asignación dinámica de recursos, optimización adaptativa de consultas, poda dinámica de particiones, etc.
-
Asignación dinámica de recursos (DRA)
: existe ceguera en la aplicación de recursos por parte del usuario y los requisitos de recursos de cada etapa de las tareas de Spark también son diferentes. La asignación de recursos irrazonable conduce a un desperdicio de recursos de tareas o una ejecución lenta. Lanzamos el servicio externo aleatorio en Spark 2.4.3 y habilitamos la asignación dinámica de recursos (DRA). Después de habilitarse, Spark iniciará o liberará dinámicamente el Ejecutor según los requisitos de recursos de la etapa de ejecución actual. Después de que DRA se puso en línea, el consumo de recursos de las tareas de Spark se redujo en un 20 %.
-
Optimización adaptativa de consultas (AQE)
: la optimización adaptativa de consultas (AQE) es una característica excelente introducida en Spark 3.0. Según los indicadores estadísticos durante el tiempo de ejecución de la etapa previa, optimiza dinámicamente el plan de ejecución de las etapas posteriores y selecciona automáticamente el. Estrategia de unión adecuada Optimice la unión sesgada, fusione particiones pequeñas, divida particiones grandes, etc. Después de actualizar Spark 3.1.1, AQE se activó de forma predeterminada, lo que resolvió eficazmente problemas como archivos pequeños y datos sesgados, y mejoró enormemente el rendimiento informático de Spark. El rendimiento general aumentó en aproximadamente un 10%.
-
Poda de partición dinámica (DPP)
: en los motores informáticos SQL, la inserción de predicados generalmente se usa para reducir la cantidad de datos leídos de la fuente de datos, mejorando así la eficiencia informática. Se introduce un nuevo método de inserción en Spark3: poda de partición dinámica y filtro de tiempo de ejecución. Al calcular primero la tabla pequeña de Join, la tabla grande de Join se filtra en función de los resultados del cálculo, lo que reduce la cantidad de datos leídos por los grandes. mesa. Realizamos investigaciones y pruebas sobre estas dos funciones y activamos DPP de forma predeterminada. En algunos escenarios comerciales, el rendimiento aumentó 33 veces. Sin embargo, descubrimos que en Spark 3.1.1, activar DPP hará que el análisis de SQL con muchas subconsultas sea particularmente lento. Por lo tanto, implementamos una regla de optimización: calcule el número de subconsultas y, cuando supere 5
, desactive
la optimización DPP.
En el proceso de uso de Spark, también encontramos algunos problemas. Al seguir el último progreso de la comunidad, descubrimos e implementamos algunos parches para resolverlos. Además, también hemos realizado algunas mejoras en Spark para hacerlo adecuado para diversos escenarios de aplicaciones y mejorar la estabilidad del marco informático.
-
Admite escritura simultánea
Dado que Spark 3.1.1 convierte las tablas de formato Hive Parquet en el Parquet Writer integrado de Spark de forma predeterminada, utilice el operador InsertIntoHadoopFsRelationCommand para escribir datos (spark.sql.hive.convertMetastoreParquet=true). Al escribir una partición estática, el directorio temporal se creará directamente debajo de la ruta de la tabla. Cuando varias tareas de escritura de particiones estáticas escriben en diferentes particiones de la misma tabla al mismo tiempo, existe el riesgo de que la tarea falle o se pierdan datos (cuando se confirma una tarea, se limpiará todo el directorio temporal, lo que provocará la pérdida de datos). para otras tareas).
Agregamos un parámetro forceUseStagingDir al operador InsertIntoHadoopFsRelationCommand y usamos el directorio Staging específico de la tarea como directorio temporal. De esta forma, diferentes tareas utilizan diferentes directorios temporales, resolviendo así el problema de la escritura concurrente. Hemos enviado el problema relevante [SPARK-37210] a la comunidad.
-
Soporte para consultar subdirectorios
Después de actualizar Hive a 3.x, el motor Tez se utiliza de forma predeterminada. Cuando se ejecuta la declaración Union, se generará el subdirectorio HIVE_UNION_SUBDIR. Debido a que Spark ignora los datos en los subdirectorios, no se pueden leer datos.
Este problema se puede resolver recurriendo a Parquet/Orc Reader a Hive Reader, agregando los siguientes parámetros:

Sin embargo, el uso del Parquet Reader integrado de Spark tendrá un mejor rendimiento, por lo que abandonamos el plan de recurrir a Hive Reader y, en su lugar, transformamos Spark. Dado que Spark ya admite la lectura de subdirectorios de tablas no particionadas a través del parámetro recursiveFileLookup, lo hemos ampliado para admitir la lectura de subdirectorios de tablas particionadas. Para obtener más detalles, consulte: [SPARK-40600].
-
Mejoras en la fuente de datos JDBC
Hay una gran cantidad de tareas de fuente de datos JDBC en aplicaciones de sincronización de datos. Para mejorar la eficiencia operativa y adaptarnos a varios escenarios de aplicaciones, hemos realizado las siguientes modificaciones en la fuente de datos JDBC integrada de Spark:
Empuje hacia abajo de las condiciones de fragmentación
:
después de que Spark fragmenta la fuente de datos JDBC, inserta condiciones de fragmentación a través de subconsultas. Descubrimos que en MySQL 5.x, las condiciones de la subconsulta no se pueden presionar hacia abajo, por lo que agregamos un marcador de posición que representa la posición de la condición. Y al insertar la condición de fragmentación en Spark, se empuja hacia el interior de la subconsulta, logrando así la capacidad de presionar hacia abajo la condición de fragmentación.
Múltiples modos de escritura
:
hemos implementado múltiples modos de escritura para fuentes de datos JDBC en Spark.
-
Normal: modo normal, use el valor predeterminado INSERT INTO para escribir
-
Upsert: se actualiza cuando existe la clave principal, escrita en el modo INSERTAR EN... EN ACTUALIZACIÓN DE CLAVE DUPLICADA
-
Ignorar: ignorar cuando existe la clave principal, escribir en modo INSERT IGNORE INTO
Modo silencioso:
cuando se produce una excepción durante la escritura JDBC, solo se imprime el registro de excepciones y la tarea no finaliza.
Tipo de mapa compatible
: utilizamos la fuente de datos JDBC para leer y escribir datos de ClickHouse. El tipo de mapa en ClickHouse no es compatible con la fuente de datos JDBC, por lo que agregamos soporte para el tipo de mapa.
-
Límite de tamaño de escritura en disco local
Operaciones como Shuffle, Cache y Spill en Spark generarán algunos archivos locales. Cuando se escriben demasiados archivos locales, el disco del nodo informático puede llenarse, lo que afecta la estabilidad del clúster.
En este sentido, agregamos un indicador de volumen de escritura en disco en Spark, lanzamos una excepción cuando el volumen de escritura en disco alcanza el umbral, juzgamos la excepción de falla de la tarea en TaskScheduler y llamamos a DagScheduler cuando se captura la excepción del límite de escritura en disco. El método detiene las tareas con un uso excesivo del disco.
Al mismo tiempo, también agregamos el indicador de uso del disco de Executor en ExecutorMetric para exponer el uso actual del disco de Spark Executor, lo que facilita la observación de tendencias y el análisis de datos.
El servicio Spark consume muchos recursos informáticos. Desarrollamos una plataforma de gestión de excepciones para auditar y gestionar recursos informáticos para tareas de procesamiento por lotes de Spark y tareas informáticas de flujo, respectivamente.
En la operación y el mantenimiento diarios, descubrimos que una gran cantidad de tareas de Spark tienen problemas como desperdicio de memoria y baja utilización de la CPU. Para encontrar tareas con estos problemas, entregamos indicadores de recursos cuando las tareas de Spark se ejecutan a Prometheus para analizar la utilización de los recursos de las tareas y obtener detalles de cálculo y configuración de recursos mediante el análisis de Spark EventLog.
Al optimizar los parámetros de recursos de las tareas y permitir la asignación dinámica de recursos, la utilización de recursos informáticos de las tareas de Spark mejora efectivamente. La actualización de la versión Spark también genera muchos ahorros de recursos.
La optimización de los parámetros de recursos se divide en optimización de memoria y CPU. La plataforma de administración de excepciones recomienda configuraciones de parámetros de recursos razonables basadas en el uso máximo de recursos de la tarea en los últimos siete días, mejorando así la utilización de recursos de las tareas Spark.
Tomando la optimización de la memoria como ejemplo, los usuarios a menudo resuelven el problema del desbordamiento de memoria (OOM) aumentando la memoria, pero ignoran la investigación en profundidad de las causas de OOM. Esto hace que los parámetros de memoria de una gran cantidad de tareas de Spark se establezcan demasiado altos y que la proporción entre la memoria de recursos de la cola y la CPU esté desequilibrada. Obtenemos indicadores de memoria de Spark Executor y enviamos órdenes de trabajo de excepción para notificar a los usuarios y guiarlos para configurar correctamente los parámetros de memoria y la cantidad de particiones.
Después de casi un año de gestión de auditoría de recursos, la plataforma de gestión de excepciones ha emitido más de 1600 órdenes de trabajo, ahorrando un total de aproximadamente el 27 % de los recursos informáticos.
Implementación y optimización del servicio Spark SQL.
El servicio iQiyi Spark SQL ha pasado por varias etapas, desde el servicio Thrift Server nativo de Spark hasta la versión Kyuubi 0.7 y Apache Kyuubi 1.4, lo que ha aportado grandes mejoras a la arquitectura y la estabilidad del servicio.
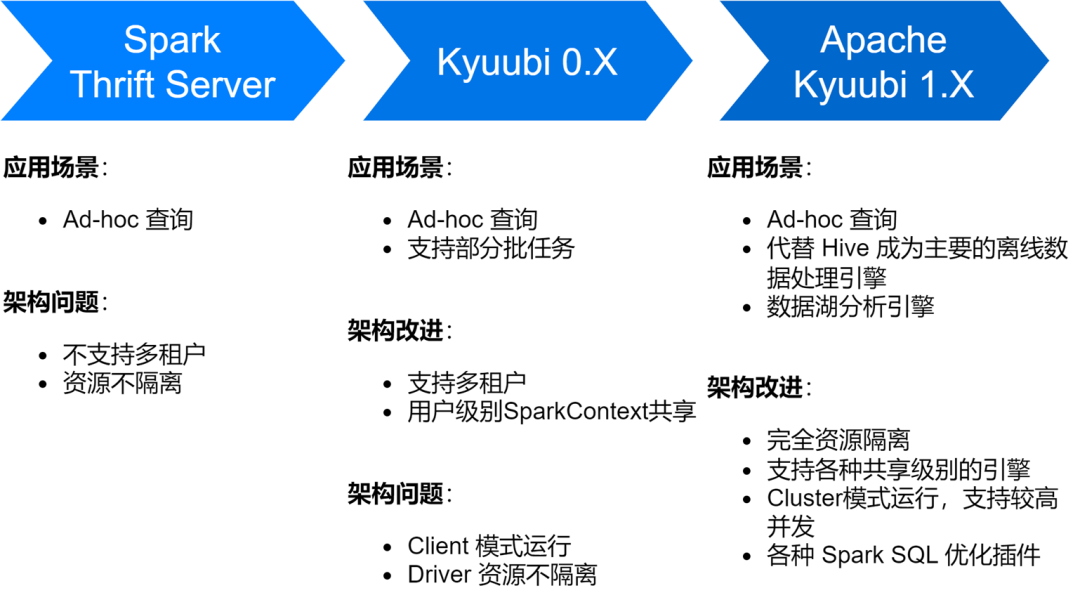
En la actualidad, el servicio Spark SQL ha reemplazado a Hive como el principal motor de procesamiento de datos fuera de línea de iQiyi, ejecutando un promedio de aproximadamente 150.000 tareas SQL por día.
-
Optimice el almacenamiento y la eficiencia informática
También encontramos algunos problemas durante la exploración del servicio Spark SQL, que incluyen principalmente la generación de una gran cantidad de archivos pequeños, mayor almacenamiento y cálculos más lentos. Por esta razón, también hemos llevado a cabo una serie de optimizaciones de eficiencia informática y de almacenamiento.
Habilite la compresión ZStandard para mejorar la relación de compresión
Zstd es el algoritmo de compresión de código abierto de Meta. En comparación con otros formatos de compresión, tiene una mayor tasa de compresión y eficiencia de descompresión. Nuestros resultados de medición reales muestran que la tasa de compresión de Zstd es equivalente a Gzip y la velocidad de descompresión es mejor que Snappy. Por lo tanto, utilizamos el formato de compresión Zstd como formato de compresión de datos predeterminado durante el proceso de actualización de Spark y también configuramos Shuffle data en compresión Zstd, lo que generó grandes ahorros en el almacenamiento del clúster. Cuando se aplica en escenarios de datos publicitarios, la tasa de compresión mejoró 3,3 veces. , ahorrando un 76% de los costos de almacenamiento.
Agregue la fase de Reequilibrio para evitar generar archivos pequeños
El problema de los archivos pequeños es un tema importante en Spark SQL: demasiados archivos pequeños ejercerán una gran presión sobre Hadoop NameNode y afectarán la estabilidad del clúster. El marco informático nativo de Spark no tiene una buena solución automatizada para resolver el problema de los archivos pequeños. En este sentido, también investigamos algunas soluciones de la industria y finalmente utilizamos la solución de optimización de archivos pequeños que viene con el servicio Kyuubi.
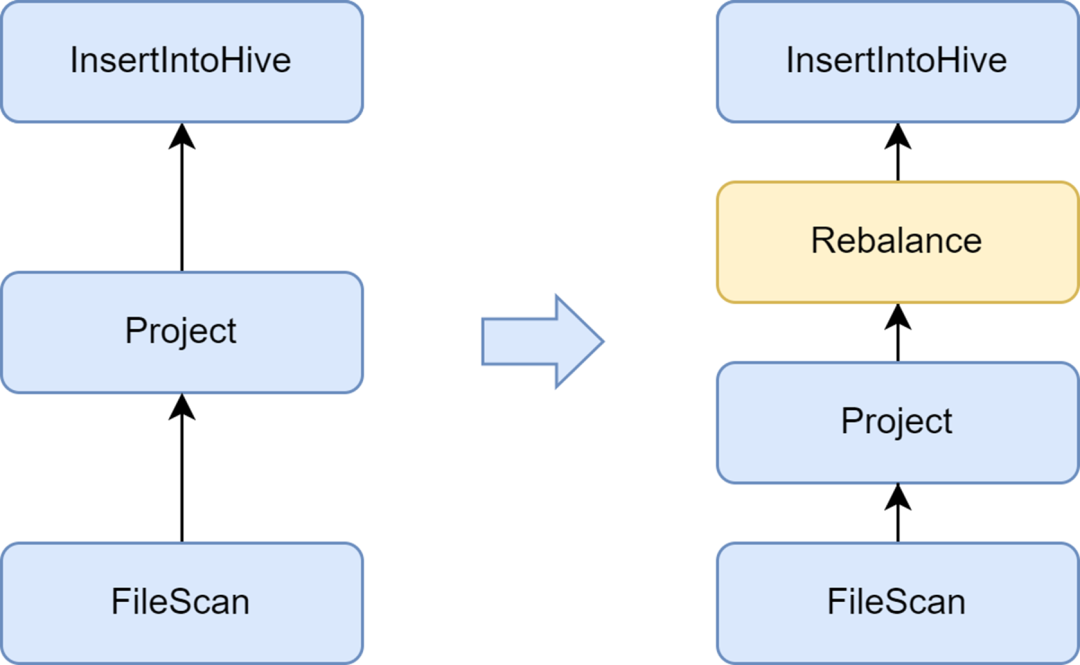
El optimizador insertRepartitionBeforeWrite proporcionado por Kyuubi puede insertar el operador Reequilibrio antes del operador Insertar. Combinado con la lógica de AQE para fusionar automáticamente particiones pequeñas y dividir particiones grandes, logra el control del tamaño del archivo de salida y resuelve efectivamente el problema de los archivos pequeños.
Después de habilitarlo, el tamaño promedio del archivo de salida de Spark SQL se optimiza de 10 MB a 262 MB, evitando la generación de una gran cantidad de archivos pequeños.
Habilite la inferencia de clasificación de reparto para mejorar aún más la tasa de compresión
Después de activar la optimización de archivos pequeños, descubrimos que el almacenamiento de datos de algunas tareas se volvió mucho mayor. Esto se debe a que la operación de reequilibrio insertada en la optimización de archivos pequeños utiliza campos de partición o particiones aleatorias para la partición, y los datos se dispersan aleatoriamente, lo que resulta en una reducción en la eficiencia de codificación del archivo en formato Parquet, lo que a su vez conduce a una reducción. en la tasa de compresión de archivos.
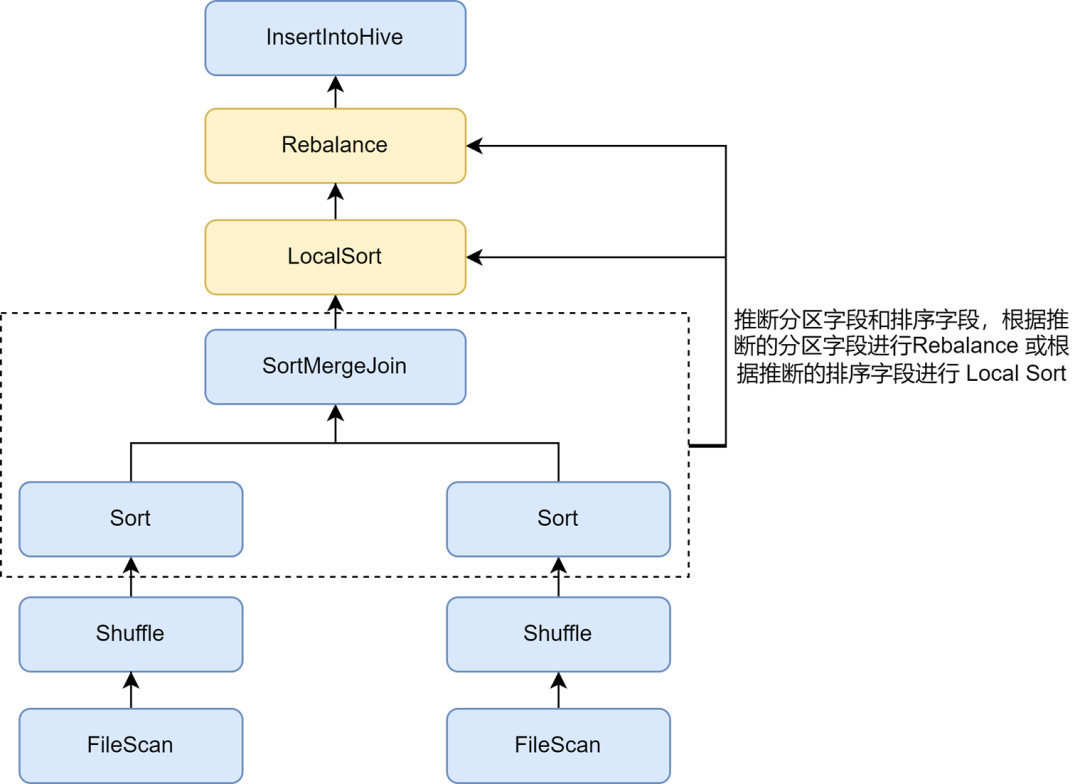
En las reglas de optimización de archivos pequeños de Kyuubi, la inferencia automática de particiones y campos de clasificación se puede habilitar a través del parámetro spark.sql.optimizer.inferRebalanceAndSortOrders.enabled. Para la escritura de particiones no dinámicas, operadores como Join, Aggregate y Sort en el. Se utilizan los campos de partición y clasificación del plan de ejecución previa a partir de las claves, y los campos de partición inferidos se utilizan para el reequilibrio, o los campos de clasificación inferidos se utilizan para la clasificación local antes del reequilibrio, de modo que la distribución de datos finalmente insertada. El operador de reequilibrio es lo más consistente posible con el plan previo y evita escribir Los datos entrantes se dispersan aleatoriamente, lo que mejora efectivamente la tasa de compresión.
Habilite la optimización de Zorder para mejorar la tasa de compresión y la eficiencia de las consultas.
La clasificación Zorder es un algoritmo de clasificación multidimensional. Para formatos de almacenamiento en columnas como Parquet, los algoritmos de clasificación eficaces pueden hacer que los datos sean más compactos, mejorando así la tasa de compresión de datos. Además, dado que se recopilan datos similares en la misma unidad de almacenamiento, por ejemplo, el rango estadístico de mínimo/máximo es menor, se puede aumentar la cantidad de datos que se omiten durante el proceso de consulta, lo que mejora efectivamente la eficiencia de la consulta.
La optimización de la clasificación en clústeres de Zorder se implementa en Kyuubi. Los campos de Zorder se pueden configurar para las tablas y la clasificación de Zorder se agregará automáticamente al escribir. Para tareas existentes, el comando Optimizar también se admite para la optimización Zorder de datos existentes. Hemos agregado optimización Zorder internamente a algunas empresas clave, reduciendo el espacio de almacenamiento de datos en un 13 % y mejorando el rendimiento de las consultas de datos en un 15 %.
Introducir una configuración AQE independiente en la etapa final para aumentar el paralelismo informático.
Durante el proceso de migración de algunas tareas de Hive a Spark, descubrimos que la velocidad de ejecución de algunas tareas en realidad se ralentizó. El análisis encontró que debido a que el operador Rebalance se insertó antes de escribir y se combinó con Spark AQE para controlar archivos pequeños, cambiamos la chispa de AQE. sql.La configuración adaptive.advisoryPartitionSizeInBytes está establecida en 1024M, lo que hace que el paralelismo de la fase Shuffle intermedia se vuelva más pequeño, lo que a su vez hace que la ejecución de la tarea sea más lenta.
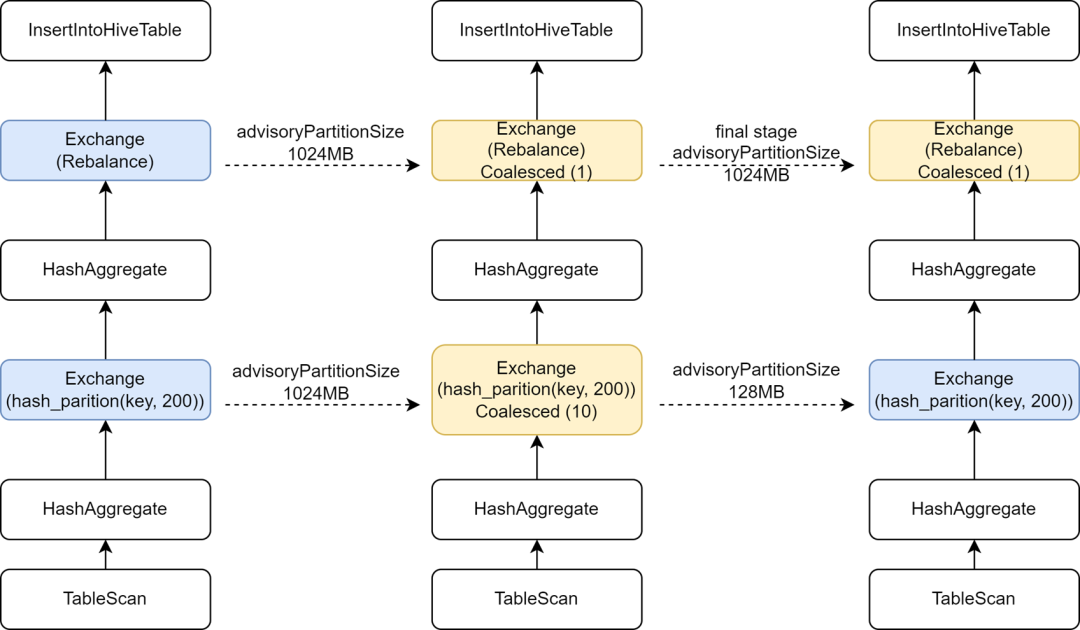
Kyuubi proporciona optimización de la configuración de la etapa final, lo que permite agregar algunas configuraciones por separado para la etapa final, de modo que podamos agregar un AdvisoryPartitionSizeInBytes más grande para la etapa final de control de archivos pequeños, y usar un AdvisoryPartitionSizeInBytes más pequeño para las etapas anteriores para aumentar el paralelismo. de cálculos y reduce el desbordamiento del disco durante la etapa Shuffle, lo que mejora efectivamente la eficiencia informática. Después de agregar esta configuración, el tiempo de ejecución general de las tareas de Spark SQL se reduce en un 25% y los recursos se ahorran en aproximadamente un 9%.
Inferir escritura dinámica de tareas de una sola partición para evitar particiones aleatorias excesivamente grandes
Para la escritura de particiones dinámicas, la optimización de archivos pequeños de Kyuubi utilizará el campo de partición dinámica para reequilibrar. Para las tareas que utilizan particiones dinámicas para escribir en una única partición, todos los datos de Shuffle se escribirán en la misma partición Shuffle. iQIYI utiliza internamente Apache Uniffle como servicio de reproducción aleatoria remota. Las particiones grandes causarán un único punto de presión en el servidor aleatorio, e incluso activarán la limitación de corriente y provocarán una reducción de la velocidad de escritura. Para este propósito, desarrollamos una regla de optimización para capturar las condiciones del filtro de partición escrita e inferir si los datos de una sola partición se escriben en forma de partición dinámica para tales tareas; ya no usamos campos de partición dinámica para reequilibrar, sino que utilizamos campos aleatorios; Reequilibrar, esto evita generar una partición Shuffle más grande. Para más detalles, consulte: [KYUUBI-5079].
-
Detección e interceptación de SQL anormal
Cuando hay problemas con la calidad de los datos o los usuarios no están familiarizados con la distribución de datos, es fácil enviar algún SQL anormal, lo que puede provocar un grave desperdicio de recursos y una baja eficiencia informática. Agregamos algunos indicadores de monitoreo al servicio Spark SQL y detectamos e interceptamos algunos escenarios informáticos anormales.
Limitar consultas grandes
En iQiyi, los analistas de datos envían SQL para el análisis de consultas ad-hoc a través de la plataforma de consultas ad-hoc Magic Mirror, que proporciona a los usuarios capacidades de consulta de segundo nivel. Usamos el motor compartido de Kyuubi como motor de procesamiento back-end para evitar iniciar un nuevo motor para cada consulta, lo que desperdicia tiempo de inicio y recursos informáticos. La presencia permanente del motor compartido en segundo plano puede brindar a los usuarios una experiencia interactiva más rápida.
Para el motor compartido, varias solicitudes se apropiarán de recursos entre sí. Incluso si habilitamos la asignación dinámica de recursos, todavía hay situaciones en las que los recursos están ocupados por algunas consultas grandes, lo que provoca que otras consultas se bloqueen. En este sentido, hemos implementado la función de interceptar consultas grandes en el complemento Spark de Kyuubi. Al analizar operaciones como Table Scan en el plan de ejecución de SQL, podemos contar la cantidad de particiones consultadas y la cantidad de datos escaneados. excede el umbral especificado, se determinará para consultas grandes y ejecución de intercepción.
Según los resultados de la determinación, la plataforma Magic Mirror cambia las consultas grandes a un motor independiente para su ejecución. Además, Magic Mirror define un tiempo de espera de nivel de minutos. Las tareas que utilizan el motor compartido para ejecutar horas extras se cancelarán y se convertirán automáticamente a ejecución de motor independiente. Todo el proceso no tiene en cuenta a los usuarios, lo que evita de manera efectiva que se bloqueen las consultas ordinarias y permite que las consultas grandes continúen ejecutándose utilizando recursos independientes.
Supervisar el exceso de datos
Algunas operaciones como Explosionar, Unir y Count Distinct en Spark SQL provocarán una expansión de datos. Si la expansión de datos es muy grande, puede provocar un desbordamiento del disco, GC completo o incluso OOM, y también empeorar la eficiencia del cálculo. Podemos ver fácilmente si se ha producido una expansión de datos según el número de indicadores de filas de salida de los nodos anteriores y siguientes en el diagrama del plan de ejecución de SQL de la página de la pestaña SQL de la interfaz de usuario de Spark.

Los indicadores en el gráfico del plan de ejecución de Spark SQL se informan al controlador a través de eventos de ejecución de tareas y eventos de latido del ejecutor, y se agregan en el controlador.
Para recopilar indicadores de tiempo de ejecución de manera más oportuna, ampliamos SQLOperationListener en Kyuubi, escuchamos el evento SparkListenerSQLExecutionStart para mantener sparkPlanInfo y, al mismo tiempo, escuchamos el evento SparkListenerExecutorMetricsUpdate y capturamos los cambios en los indicadores estadísticos SQL del nodo en ejecución. y comparó el número de indicadores de filas de salida del nodo en ejecución actual y el número de indicadores de filas de salida de los nodos secundarios anteriores, calculó la tasa de expansión de datos para determinar si se produjo una expansión de datos grave y recopiló eventos anormales o interceptó tareas anormales cuando. se produce la expansión de datos.
Tecla de inclinación de unión de posición
El problema de sesgo de datos es un problema común en Spark SQL y afecta el rendimiento. Aunque existen algunas reglas para optimizar automáticamente el sesgo de datos en Spark AQE, no siempre son efectivas. Además, es probable que el problema de sesgo de datos sea causado por el usuario. malentendido de los datos La lógica de análisis incorrecta se escribe porque la comprensión no es lo suficientemente profunda o los datos en sí tienen problemas de calidad, por lo que es necesario que analicemos la tarea de sesgo de datos y ubiquemos el valor clave sesgado.

Podemos determinar fácilmente si se ha producido un sesgo de datos en la tarea a través de las estadísticas de Stage Tasks en la interfaz de usuario de Spark. Como se muestra en la figura anterior, el valor máximo de Duración de la tarea y Lectura aleatoria excede el valor del percentil 75, por lo que es obvio que los datos. se ha producido un sesgo.
Sin embargo, para calcular los valores de clave que causan sesgo en la tarea de sesgo, generalmente es necesario dividir manualmente el SQL y luego calcular la distribución de claves en cada etapa usando Count Group By Keys para determinar el valor de clave sesgado. suele ser una tarea que requiere relativamente tiempo.
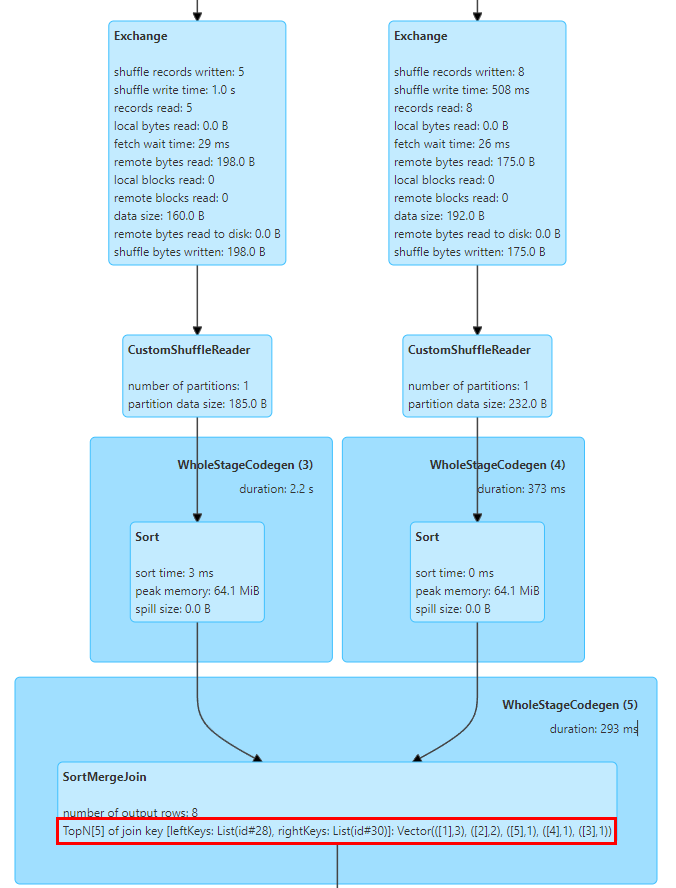
En este sentido, implementamos estadísticas de TopN Keys en SortMergeJoinExec.
La implementación de SortMergeJoin es ordenar la clave primero y luego realizar la operación de unión, de modo que podamos contar fácilmente los valores TopN de la clave mediante acumulación.
Implementamos un acumulador TopNAccumulator, que mantiene internamente un objeto de tipo Map[String, Long] Utiliza el valor de la clave de unión como clave del mapa y mantiene el valor de conteo de la clave en el valor del mapa en SortMergeJoinExec, para cada fila de datos. Para el cálculo acumulativo, dado que los datos están en orden, solo necesitamos acumular las claves insertadas y, al insertar nuevas claves, determinar si se alcanza el valor N y eliminar la clave más pequeña.
Además, Spark solo admite la visualización de indicadores estadísticos de tipo Long. También modificamos la lógica de visualización de los indicadores estadísticos de SQL para adaptarlos a los valores de tipo Map.
La figura anterior muestra los 5 valores principales de la clave de unión de las dos tablas para unirse, donde la clave es el campo de identificación y hay 3 filas con id = 1.
Después de una serie de investigaciones y pruebas, descubrimos que Spark SQL ha mejorado significativamente el rendimiento y el uso de recursos en comparación con Hive. Sin embargo, también encontramos muchos problemas durante la migración de Hive SQL a Spark. Al realizar algunas modificaciones y adaptaciones de compatibilidad al servicio Spark SQL, migramos con éxito la mayoría de las tareas de Hive SQL a Spark.
El soporte de Spark SQL para Hive UDF tiene algunos problemas en el uso real. Por ejemplo, las empresas suelen utilizar la función de reflexión para llamar a métodos estáticos de Java para procesar datos. Cuando se produce una excepción en la llamada de reflexión, Hive devolverá un valor NULL y Spark SQL generará una excepción y provocará que la tarea falle. Con este fin, modificamos la función de reflexión de Spark para capturar excepciones de llamadas de reflexión y devolver valores NULL, de forma coherente con Hive.
Otro problema es que Spark SQL no admite el constructor privado de Hive UDAF, lo que provocará que UDAF de algunas empresas no se inicialice. Hemos transformado la lógica de registro de funciones de Spark para admitir constructores privados de Hive UDAF.
-
Compatibilidad de funciones integradas
Existen diferencias en la lógica de cálculo de la función GROUPING_ID incorporada entre Spark SQL y Hive versión 1.2, lo que genera inconsistencia de datos durante la fase de ejecución dual. En la versión Hive 3.1, la lógica de cálculo de esta función se cambió para que sea coherente con la lógica de Spark, por lo que animamos a los usuarios a actualizar la lógica SQL y adaptar la lógica de esta función en Spark para garantizar la corrección de la lógica de cálculo.
Además, la función hash de Spark SQL utiliza el algoritmo Murmur3 Hash, que es diferente de la lógica de implementación de Hive. Recomendamos que los usuarios registren manualmente la función hash incorporada de Hive para garantizar la coherencia de los datos antes y después de la migración.
-
Compatibilidad de conversión de tipos
Spark SQL ha introducido la especificación ANSI SQL desde la versión 3.0. En comparación con Hive SQL, tiene requisitos más estrictos en cuanto a coherencia de tipos. Por ejemplo, está prohibida la conversión automática entre tipos de cadenas y numéricos. Para evitar anomalías de conversión automática causadas por definiciones de tipos de datos no estándar en la empresa, recomendamos que los usuarios agreguen CAST a SQL para una conversión explícita. Para transformaciones a gran escala, la configuración spark.sql.storeAssignmentPolicy=LEGACY se puede agregar temporalmente. para reducir la verificación de tipos del nivel Spark SQL para evitar excepciones de migración.
La función str_to_map en Hive retendrá automáticamente el último valor para las claves repetidas, mientras que en Spark, se generará una excepción y la tarea fallará. En este sentido, recomendamos que los usuarios auditen la calidad de los datos ascendentes o agreguen la configuración spark.sql.mapKeyDedupPolicy=LAST_WIN para conservar el último valor duplicado, de acuerdo con Hive.
-
Otra compatibilidad de sintaxis
La sintaxis Hint de Spark SQL y Hive SQL es incompatible y los usuarios deben eliminar manualmente las configuraciones relevantes durante la migración. Los consejos comunes de Hive incluyen la transmisión de tablas pequeñas. Dado que la función Spark AQE es más inteligente para transmitir tablas pequeñas y optimizar la inclinación de tareas, generalmente el usuario no requiere configuración adicional.
También existen algunos problemas de compatibilidad entre Spark SQL y las declaraciones DDL de Hive. Generalmente recomendamos que los usuarios utilicen la plataforma para realizar operaciones DDL en tablas de Hive. Para algunos comandos de operación de partición, como: eliminar particiones no existentes [KYUUBI-1583], declaraciones de Alter Partition desiguales y otros problemas de compatibilidad, también hemos ampliado el complemento Spark para mayor compatibilidad.
Resumen y perspectivas
En la actualidad, hemos migrado la mayoría de las tareas de Hive en la empresa a Spark, por lo que Spark se ha convertido en el principal motor de procesamiento fuera de línea de iQiyi. Completamos el trabajo preliminar de auditoría de recursos y optimización del rendimiento en el motor Spark, lo que generó ahorros considerables para la empresa. En el futuro, continuaremos optimizando el rendimiento y la estabilidad de los servicios y marcos informáticos de Spark. También promoveremos aún más la migración de las pocas tareas restantes de Hive.
Con la implementación del lago de datos de la empresa, cada vez más empresas están migrando al lago de datos Iceberg. A medida que Iceberg continúa mejorando las funciones de Spark DataSourceV2, Spark 3.1 ya no puede satisfacer algunas necesidades nuevas de análisis del lago de datos, por lo que estamos a punto de actualizar a Spark 3.4. Al mismo tiempo, también investigamos algunas características nuevas, como el filtro de tiempo de ejecución, la unión particionada de almacenamiento, etc., con la esperanza de mejorar aún más el rendimiento del marco informático Spark en función de las necesidades comerciales.
Además, para promover el proceso de computación de big data nativo de la nube, presentamos Apache Uniffle, un servicio de reproducción aleatoria remota (RSS). Durante el uso, descubrimos que hay problemas de rendimiento cuando se combina con Spark AQE, como la optimización de sesgo de BroadcastHashJoin [SPARK-44065], el problema de partición grande mencionado anteriormente y cómo realizar mejor la planificación de partición AQE. Continuaremos trabajando en ello. en el futuro, lo que conducirá a una investigación y optimización más profundas.
Quizás tú también quieras ver

