Prólogo: En escenarios comerciales, el equipo de seguridad de una empresa generalmente usa códigos de verificación como un método para reducir el riesgo de daño comercial, a fin de reducir la posibilidad de eventos de riesgo como acreditación, registro falso, deslizamiento fraudulento, robo de información y lana.
Hoy exploraremos la importancia de los códigos de verificación en el control de riesgos comerciales a través de la aplicación práctica de los códigos de verificación en el evento especial del décimo aniversario de GeeExpert.
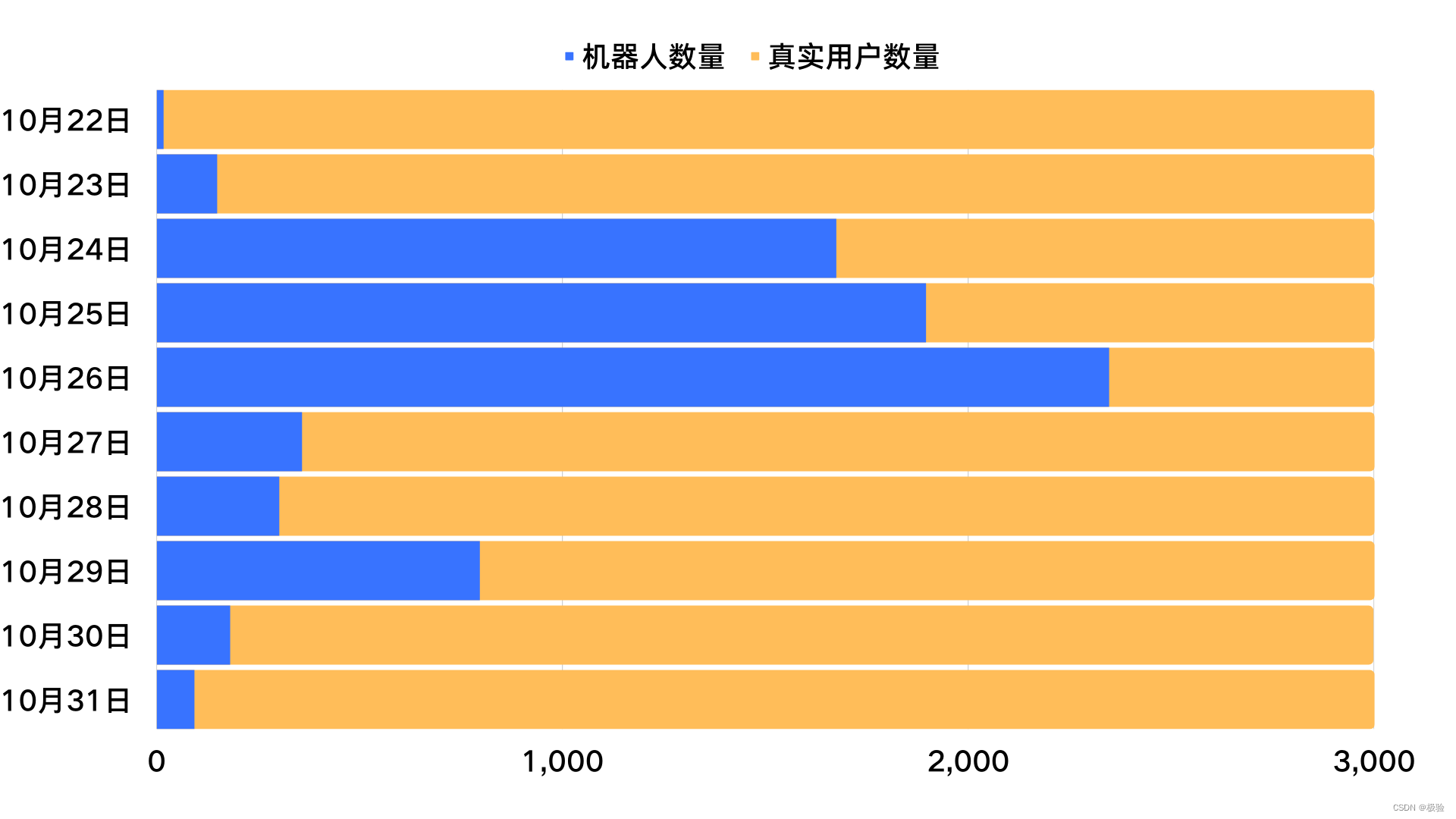
En el evento del décimo aniversario de octubre, simulamos actividades de marketing de comercio electrónico para crear un evento real de un escenario empresarial atacado por una máquina. En este evento, el robot participó en un total de 1.183.900 sorteos de cartas y recibió un total de 7.811 membresías mensuales de iQiyi a través de trampas automáticas. Si esta inversión se convierte en actividades operativas a gran escala, el negocio de la empresa puede causar una pérdida de 234.300 yuanes.
Máquina vs Usuarios Humanos Aceptando Premios
Tomando el 27 de octubre como la línea divisoria para implementar el código de verificación en la escena de recepción de recompensas, dividimos toda la actividad en la primera etapa y la segunda etapa. En la primera etapa sin el código de verificación, el robot se llevó con éxito 6081 recompensas; pero En la segunda etapa, el código de verificación desempeñó el papel de interceptar cuentas anormales, identificó con éxito las cuentas de riesgo e implementó estrategias de control de riesgos. Según las estadísticas, existen 3.464 cuentas anormales identificadas a través de códigos de verificación en esta actividad. Entonces, en este escenario comercial, ¿cómo identifica el código de verificación las cuentas riesgosas?
El código de verificación utilizado en esta actividad es el código de verificación de comportamiento extremadamente experimental. Este código de verificación se basa en características de comportamiento biológico y utiliza aprendizaje profundo de inteligencia artificial para realizar análisis de alta dimensión en los datos de comportamiento generados durante el proceso de verificación, y encuentra que Los patrones de comportamiento de los usuarios humanos y las máquinas son consistentes con Las diferencias en las características de comportamiento pueden distinguir con precisión entre humanos y máquinas en esta escena.
0 1
Análisis e identificación de ideas de hacking
A través del análisis de seguimiento de la plataforma de craqueo y la investigación inversa de productos de seguridad relacionados, el laboratorio de seguridad interactivo de Jiexperi descubrió que el craqueo de códigos de verificación se basa principalmente en el craqueo de simuladores y el craqueo de interfaces.
Simulador de craqueo: a través de varias herramientas de prueba automatizadas, como Selenium para operar el núcleo de cromo para realizar operaciones automáticas de arrastrar, hacer clic y otras;
Descifrado de interfaz: use el programa de interfaz para descifrar los parámetros clave correctos, a fin de descifrar el código de verificación. Dado que el craqueo de la interfaz requiere la restauración inversa del JS frontal y la lógica de generación de parámetros debe aclararse por completo, el umbral técnico y el costo de implementación del craqueo con simuladores son más altos.
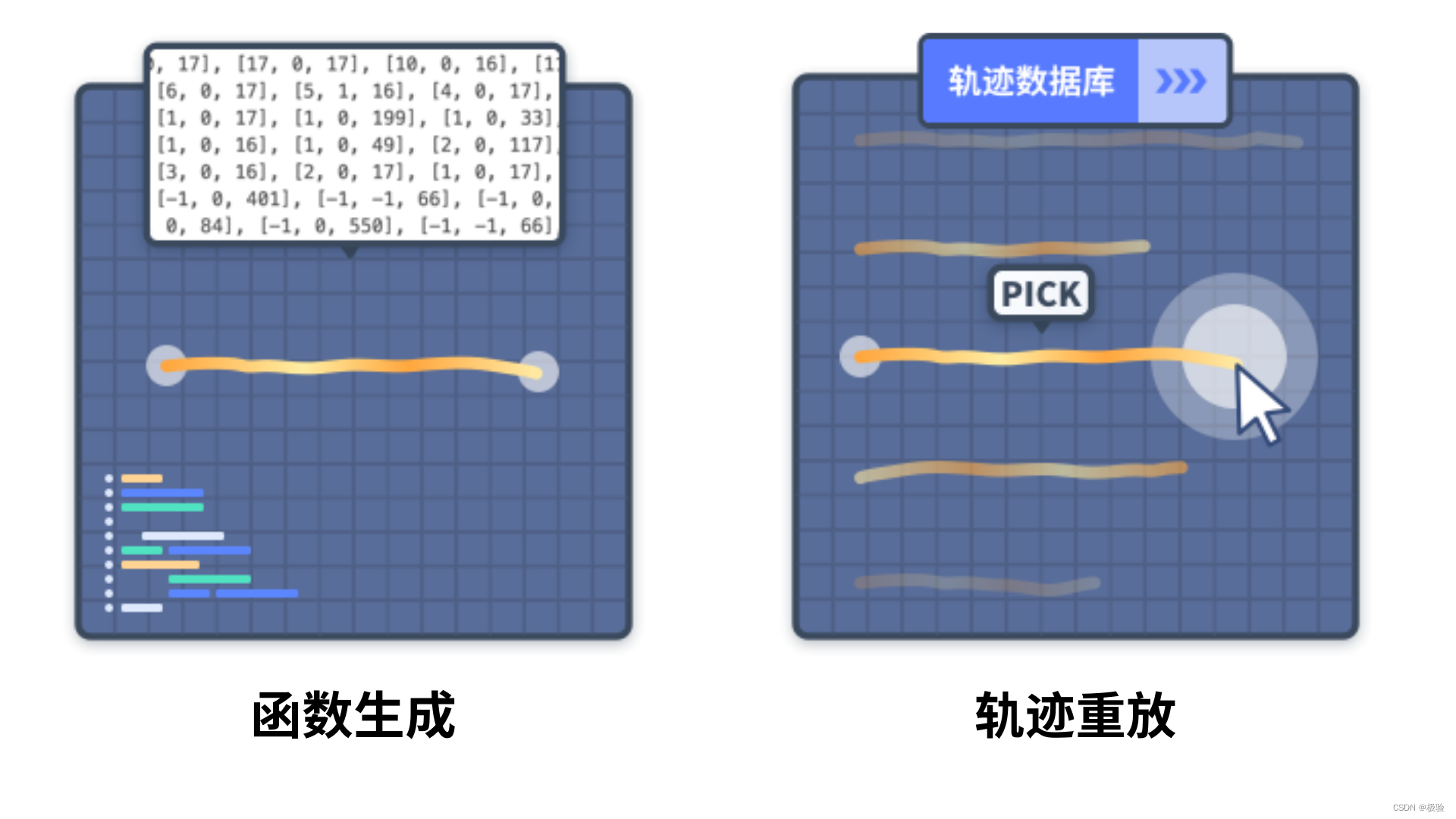
El craqueo del simulador y el craqueo de la interfaz son dos caminos técnicos para automatizar el proceso de craqueo, pero no importa cuál se use, las respuestas de verificación deben obtenerse a través de imágenes exhaustivas manuales, reconocimiento de IA, etc., y luego generar una trayectoria de comportamiento lo más realista posible. . La generación automática de trayectorias incluye:
Generación de funciones: al escribir funciones, se generan automáticamente datos de trayectoria con patrones de comportamiento específicos y las características de la máquina son relativamente obvias.
Reproducción de trayectoria: a través de varios canales, se acumulan muestras de trayectoria real de diferentes tipos y longitudes, y los datos de trayectoria se entregan repetidamente de acuerdo con la adaptación de la respuesta.
 Con base en estos, el captcha puede identificar excepciones a través de los siguientes tres modelos:
Con base en estos, el captcha puede identificar excepciones a través de los siguientes tres modelos:
Modelo CNN: el nombre completo es el modelo de red neuronal convolucional, que aprende automáticamente las características de las trayectorias de las máquinas a partir de bases de datos masivas, distingue las trayectorias de las personas y las máquinas en tiempo real y bloquea las trayectorias de riesgo anormales.
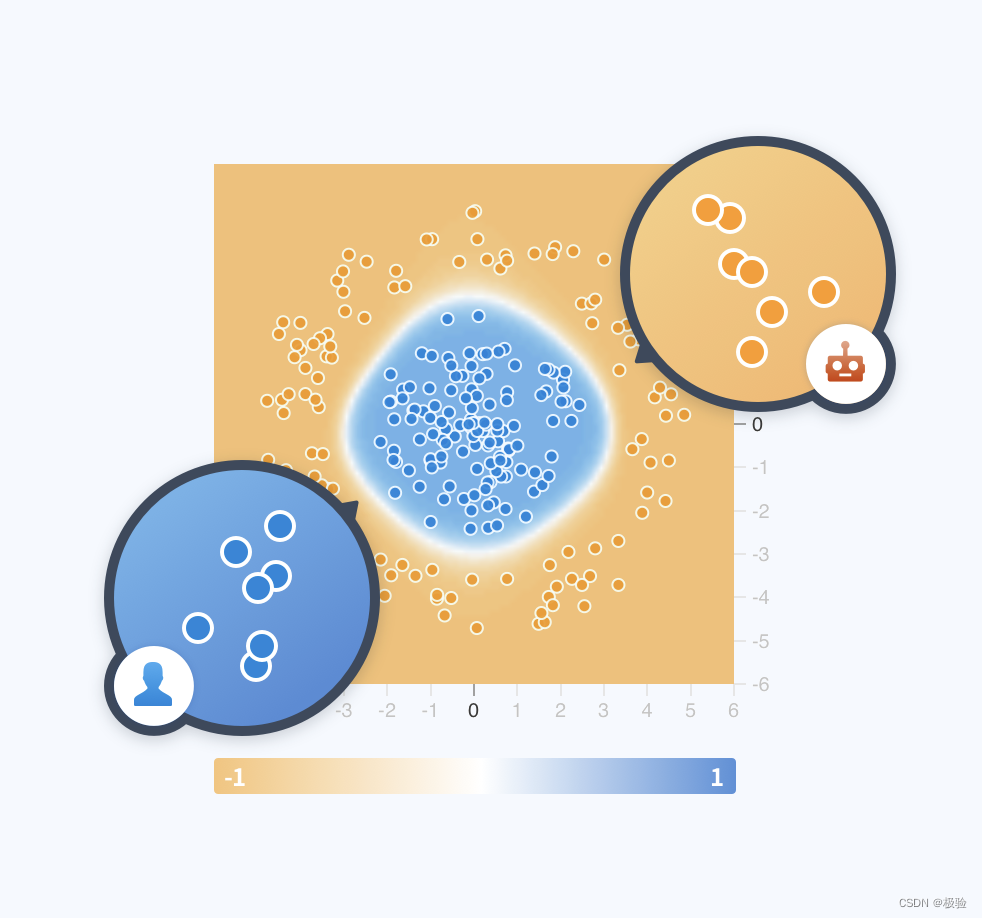
Modelo de clúster: la trayectoria generada por la función es muy fácil de generar patrones de agregación en el espacio de características, y el modelo de agrupamiento dinámico descubre automáticamente nuevas variantes de datos de la máquina a través de la agregación de este patrón de comportamiento. El modelo de agrupamiento calcula la distribución de probabilidad de los datos en el espacio de baja dimensión en el período de tiempo actual realizando un mapeo de baja dimensión de los datos en el espacio de característica de alta dimensión en tiempo real.Si la probabilidad de un área determinada es más alto que el umbral, se prohibirá la nueva caída. Los datos de trayectoria en esta área.
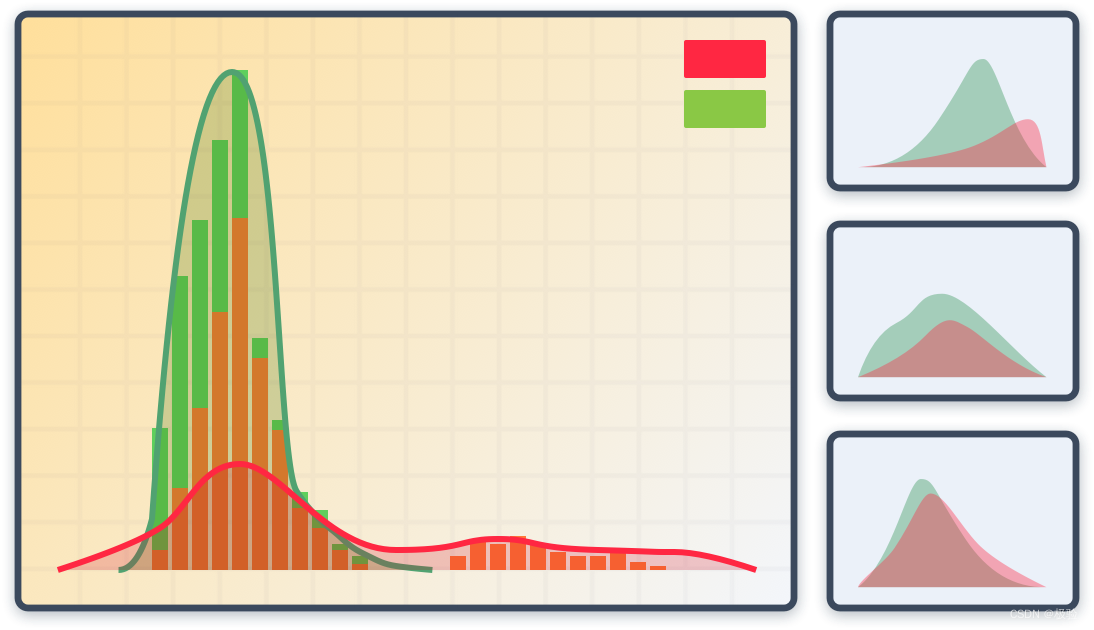
Modelo hash: el modelo hash codifica los datos en un espacio de características de alta dimensión, y cada trayectoria real tiene su correspondiente código hash único. Cuando los piratas informáticos intentan descifrar la verificación reproduciendo la trayectoria o generando una biblioteca de trayectoria aleatoria, la trayectoria generará una colisión hash, exponiendo así las características de la máquina.
0 2
Máquina de contraintercepción dinámica en tiempo real
Ante la intrusión de la máquina, el código de verificación puede desempeñar un papel de defensa en tiempo real, es decir, la máquina debe responder la respuesta correcta en la escena correspondiente antes de continuar con el siguiente paso. En este caso, se recolectan recompensas por pasar la verificación, para que la máquina pueda ser interceptada en tiempo real, reduzca los usuarios de máquinas anormales en sitios web, software o applets, y reduzca el riesgo de daños comerciales.
Además, si los piratas informáticos actualizan sus métodos de intrusión a través del aprendizaje automático durante el proceso de ataque, el código de verificación también se puede defender de manera científica y efectiva a través de cambios dinámicos, como ofuscación y transformación regulares de JS front-end, cambios regulares de front-end dinámico. parámetros, la biblioteca de riesgos de toda la red se actualizará regularmente y el algoritmo de cifrado de parámetros se cambiará de manera flexible. Sin embargo, entre los códigos de verificación existentes, solo GeeExperiment 4.0 puede hacer esto.
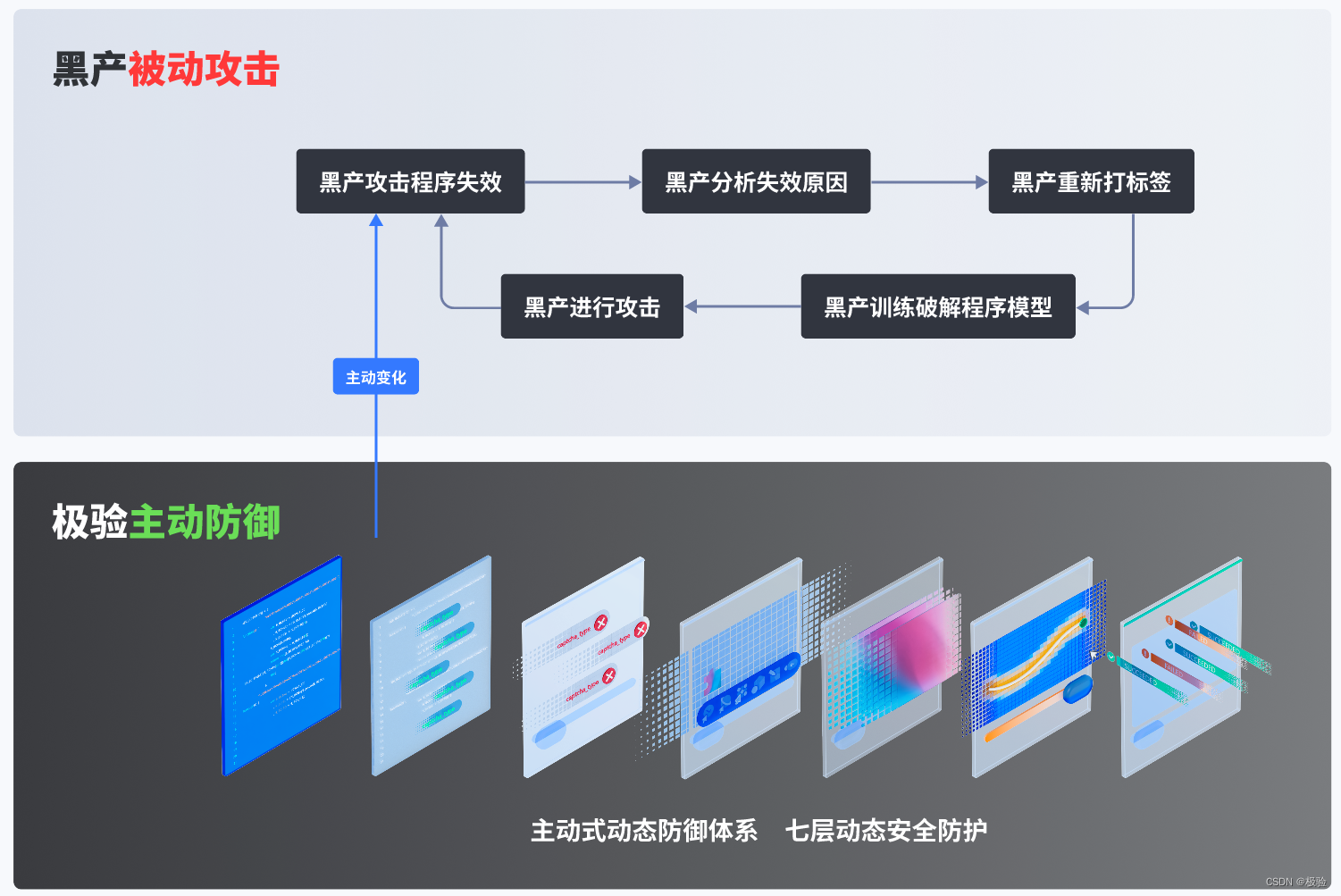
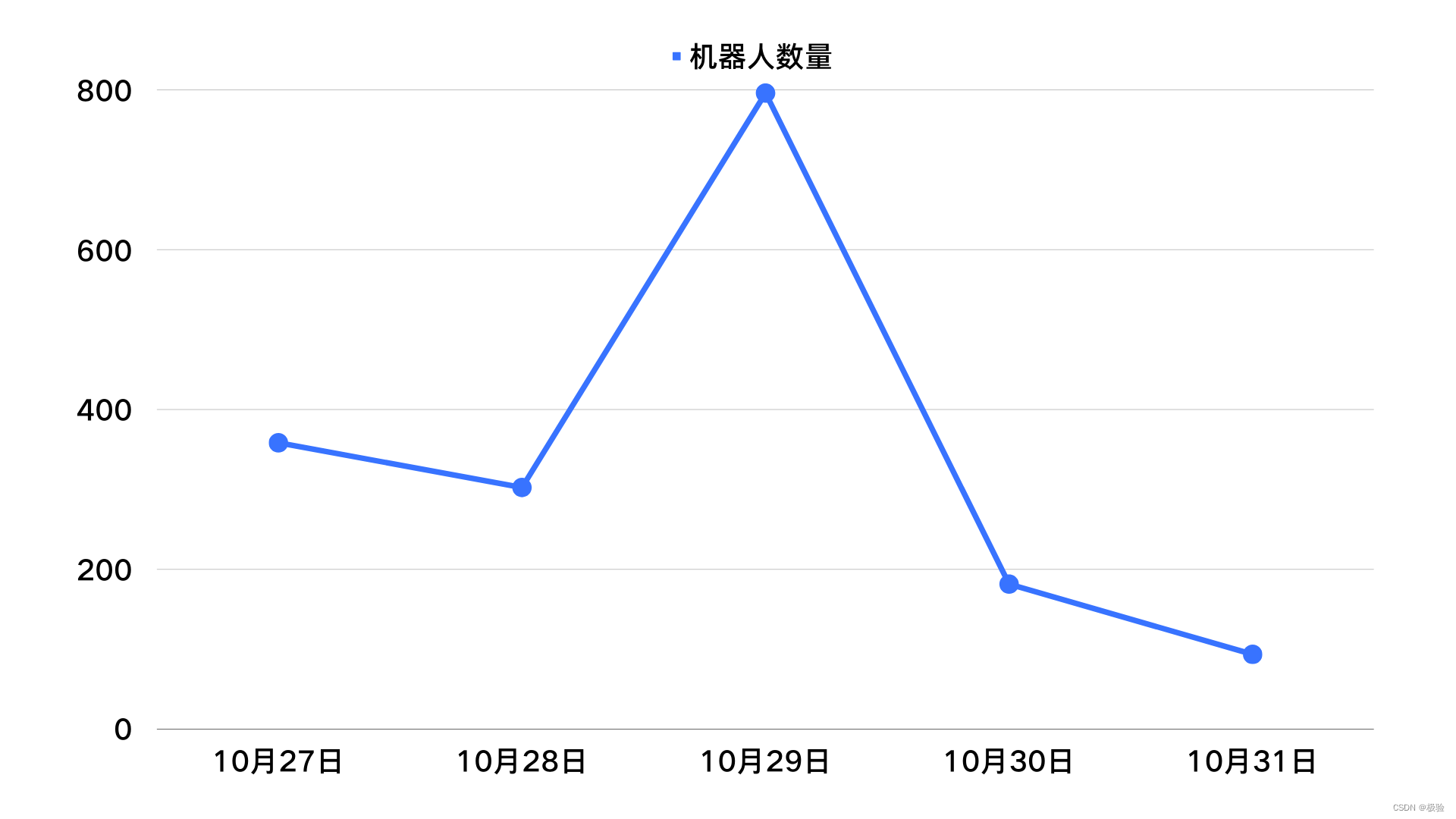
Por ejemplo, bajo la protección del código de verificación, la cantidad de premios recibidos los días 27 y 28 del evento disminuyó significativamente en comparación con el día 26 cuando no se configuró ningún código de verificación, pero la cantidad de premios recibidos el día 29 aumentó ligeramente. Con diez años de rica experiencia, consideramos que la industria negra ha mejorado sus métodos de ataque a través del aprendizaje automático en este momento.
Inmediatamente, actualizamos la estrategia del modelo de verificación. Ante solicitudes riesgosas, el cerebro de IA de verificación fortalecerá automáticamente la estrategia de confrontación, como: cambiar dinámicamente el formulario de verificación, actualizar automáticamente el modelo visual, etc. El modelo de código de verificación que cambia dinámicamente ha traído grandes desafíos a la producción negra, aumentó el costo y el tiempo de craqueo y mejoró la capacidad de intercepción, por lo que podemos ver claramente que la cantidad de máquinas en los últimos dos días del evento está a la baja. tendencia de nuevo.
0 3
La importancia de los códigos de verificación en aplicaciones prácticas
Hoy en día, los piratas informáticos utilizan medios más diversificados de ataques automáticos. A través de los casos reales anteriores, podemos ver que los códigos de verificación tienen la siguiente importancia práctica en el control de riesgos:
1) Ayudar a las empresas a hacer juicios de riesgo: los datos de comportamiento recopilados por los códigos de verificación pueden enriquecer efectivamente la dimensión de recopilación de información del sistema de control de riesgos y proporcionar perspectivas y bases más diversas para el juicio final. Por ejemplo, la verificación de rompecabezas deslizante puede recopilar pistas de deslizamiento del usuario, y la verificación de reconocimiento de imágenes puede recopilar eventos de clic del mouse del usuario.
2) Mejorar la dificultad de los ataques de piratería: el código de verificación se implementa como un componente necesario en la entrada de negocios clave, como el inicio de sesión, la recuperación de contraseñas, la colocación de pedidos y la publicación de comentarios, lo que puede prevenir de manera efectiva ataques como la colisión de bases de datos y ataques brutos. adivinación forzada El despliegue de códigos de verificación Aumentó la dificultad de ataque de los productos negros.
3) Tratar con el tráfico malicioso: además del significado directo anterior, muchas empresas de Internet han estado o están trabajando en la construcción de sus propios sistemas de control de riesgos basados en las condiciones comerciales reales. Bajo la premisa del resultado del juicio del sistema de control de riesgos, se puede procesar en combinación con códigos de verificación de diferentes niveles de dificultad para mejorar la experiencia del usuario y reducir los errores de juicio.