
01
atrásescenay el status quo
1. Características de los datos en el ámbito publicitario
Los datos en el campo de la publicidad se pueden dividir en: características de valor continuo A diferencia de los campos de imagen, video, voz y otros campos de IA , los datos originales en el campo se presentan principalmente en forma de ID, como ID de usuario, ID de publicidad, secuencia de ID de publicidad que interactúa con el usuario, etc., y la ID. La escala es grande y forma el campo publicitario. Las características distintivas de los datos dispersos de alta dimensión.
-
Existen características tanto estáticas (como la edad del usuario) como dinámicas basadas en el comportamiento del usuario (como la cantidad de veces que un usuario hace clic en un anuncio en una determinada industria). -
La ventaja es que tiene buena capacidad de generalización. La preferencia de un usuario por una industria se puede generalizar a otros usuarios que tengan las mismas características estadísticas de la industria. -
La desventaja es que la falta de capacidad de memoria da como resultado una baja discriminación. Por ejemplo, dos usuarios con las mismas características estadísticas pueden tener diferencias significativas de comportamiento. Además, las funciones de valor continuo también requieren mucha ingeniería de funciones manual.
-
Las características de valor discreto son características detalladas. Los hay enumerables (como el género del usuario, el ID de la industria) y los de alta dimensión (como el ID del usuario, el ID de la publicidad). -
La ventaja es que tiene una gran memoria y una gran distinción. Las características de valor discreto también se pueden combinar para aprender información cruzada y colaborativa. -
La desventaja es que la capacidad de generalización es relativamente débil.
-
Codificación one-hot -
Incrustación de funciones (Incrustación)
-
Conflicto de características: si el tamaño del vocabulario se establece demasiado grande, la eficiencia del entrenamiento disminuirá drásticamente y el entrenamiento fallará debido a la memoria OOM. Por lo tanto, incluso para funciones de valor discreto de ID de usuario de mil millones de niveles, solo configuraremos un espacio de ID Hash de 100.000 niveles. La tasa de conflicto de hash es alta, la información de la función está dañada y no hay ningún beneficio positivo de la evaluación fuera de línea. -
IO ineficiente: dado que características como la ID de usuario y la ID de publicidad son de alta dimensión y escasas, es decir, los parámetros actualizados durante el entrenamiento solo representan una pequeña parte del total. Bajo el mecanismo de incrustación estática original de TensorFlow, es necesario procesar el acceso al modelo. Todo el tensor denso generará una enorme sobrecarga de IO y no podrá soportar el entrenamiento de modelos grandes y dispersos.
02
Práctica escasa de modelos grandes
-
La API de TFRA es compatible con el ecosistema de Tensorflow (reutilizando el optimizador e inicializador original, la API tiene el mismo nombre y comportamiento consistente), lo que permite a TensorFlow admitir el entrenamiento y la inferencia de modelos grandes dispersos de tipo ID de una manera más nativa; El costo de aprendizaje y uso es bajo y no cambia los hábitos de modelado de los ingenieros de algoritmos. -
La expansión y contracción dinámica de la memoria ahorra recursos durante el entrenamiento; evita eficazmente los conflictos de Hash y garantiza que la información de las funciones no se pierda.
-
La incrustación estática se actualiza a incrustación dinámica: para la lógica Hash artificial de características de valores discretos, la incrustación dinámica TFRA se utiliza para almacenar, acceder y actualizar parámetros, garantizando así que la incrustación de todas las características de valores discretos esté libre de conflictos en el marco del algoritmo y asegurando que todos los valores discretos aprendan características sin pérdidas. -
Uso de funciones de ID dispersas de alta dimensión: como se mencionó anteriormente, cuando se utiliza la función de incrustación estática de TensorFlow, las funciones de ID de usuario y ID de publicidad no tienen ganancias en la evaluación fuera de línea debido a conflictos de Hash. Una vez actualizado el marco del algoritmo, se reintroducen las funciones de identificación de usuario y de publicidad, lo que genera beneficios positivos tanto en línea como fuera de línea. -
El uso de características de identificación combinadas dispersas de alta dimensión: presentamos las características combinadas de valor discreto de la identificación de usuario y la identificación de publicidad de grano grueso, como la combinación de la identificación de usuario con la identificación de la industria y el nombre del paquete de la aplicación, respectivamente. Al mismo tiempo, en combinación con la función de acceso a funciones, se introducen funciones discretas que utilizan una combinación de ID de usuario e ID de publicidad más dispersos.

2. Actualización del modelo
-
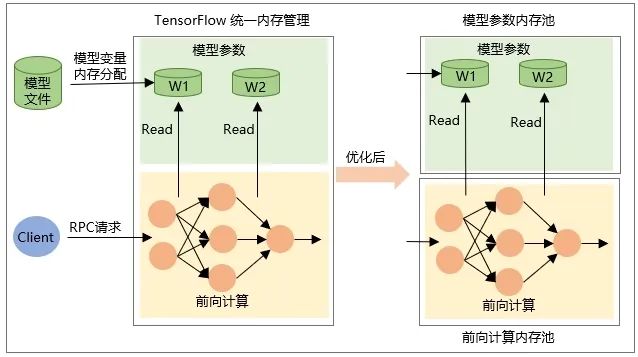
La asignación de la variable en sí Tensor cuando se restaura el modelo, es decir, la memoria se asigna cuando se carga el modelo y la memoria se libera cuando se descarga el modelo. -
La memoria del tensor de salida intermedia se asigna durante el cálculo directo de la red durante la solicitud RPC y se libera una vez que se completa el procesamiento de la solicitud.
03
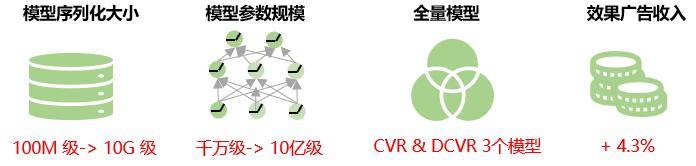
beneficio general
04
perspectiva del futuro
Actualmente, todos los valores de características de la misma característica en el modelo disperso de publicidad grande reciben la misma dimensión de incrustación. En los negocios reales, la distribución de datos de características de alta dimensión es extremadamente desigual, un número muy pequeño de características de alta frecuencia representa una proporción muy alta y el fenómeno de cola larga es grave cuando se utilizan dimensiones de incrustación fijas para todos los valores de características ; Reducirá la capacidad de incrustar el aprendizaje de representación. Es decir, para características de baja frecuencia, la dimensión de incrustación es demasiado grande y el modelo corre el riesgo de sobreajustarse para características de alta frecuencia, porque hay una gran cantidad de información que debe representarse y aprenderse, la incrustación; La dimensión es demasiado pequeña y el modelo corre el riesgo de no ajustarse lo suficiente. Por lo tanto, en el futuro, exploraremos formas de aprender de forma adaptativa la dimensión de incrustación de características para mejorar aún más la precisión de la predicción del modelo.
Al mismo tiempo, exploraremos la solución de exportación incremental del modelo, es decir, cargar solo los parámetros que cambian durante el entrenamiento incremental en TensorFlow Serving, reduciendo así la transmisión de red y el tiempo de carga durante la actualización del modelo, logrando actualizaciones a nivel de minutos. de modelos grandes y dispersos y mejorando la naturaleza en tiempo real del modelo.

Proceso de optimización de ofertas duales de publicidad de rendimiento iQIYI
Aplicación de lago de datos de publicidad y práctica de iQIYI Data Lake
Este artículo se comparte desde la cuenta pública de WeChat: Equipo de productos de tecnología iQIYI (iQIYI-TP).
Si hay alguna infracción, comuníquese con [email protected] para eliminarla.
Este artículo participa en el " Plan de creación de fuentes OSC ". Los que están leyendo pueden unirse y compartir juntos.
{{o.nombre}}
{{m.nombre}}