
Spark es un motor informático de big data rápido, versátil y escalable . Tiene las ventajas de alto rendimiento, facilidad de uso, tolerancia a fallas, integración perfecta con el ecosistema Hadoop y alta actividad comunitaria. En uso real, tiene una amplia gama de escenarios de aplicación:
· Limpieza y preprocesamiento de datos: en escenarios de análisis de big data, los datos generalmente necesitan operaciones de limpieza y preprocesamiento para garantizar la calidad y coherencia de los datos. Spark proporciona una API enriquecida que puede limpiar, filtrar, transformar y otras operaciones sobre los datos.
· Análisis de procesamiento por lotes: Spark es adecuado para tareas de procesamiento por lotes en diversos escenarios de aplicaciones, incluido el análisis estadístico, la extracción de datos, la extracción de características, etc. Los usuarios pueden utilizar la potente API de Spark y las bibliotecas integradas para realizar procesamiento y análisis de datos complejos para extraer datos. valor intrínseco en .
· Consulta interactiva: Spark proporciona el módulo Spark SQL que admite consultas SQL . Los usuarios pueden utilizar declaraciones SQL estándar para consultas interactivas y análisis de datos a gran escala.
El uso de Spark en Kangaroo Cloud
En la plataforma de desarrollo fuera de línea Kangaroo Cloud Stack , ofrecemos tres formas de utilizar Spark:
● Crear tareas de Spark SQL
Los usuarios pueden implementar su propia lógica empresarial directamente escribiendo SQL. Este método es actualmente la forma más utilizada de utilizar Spark en la plataforma fuera de línea de pila de datos, y también es el método más recomendado.
● Crear tarea Spark Jar
Los usuarios deben usar el lenguaje Scala o Java para implementar la lógica empresarial en IDEA, luego compilar y empaquetar el proyecto, cargar el paquete Jar resultante en la plataforma fuera de línea, luego hacer referencia a este paquete Jar al crear una tarea Spark Jar y finalmente enviar la tarea. ir a la ejecución programada.
Para requisitos que son difíciles de lograr o expresar usando SQL, o los usuarios tienen otros requisitos más profundos, las tareas de Spark Jar sin duda brindan a los usuarios una forma más flexible de usar Spark.
● Crear tareas de PySpark
Los usuarios pueden escribir directamente el código Python correspondiente . Entre nuestra base de clientes, hay bastantes clientes para quienes, además de SQL, Python puede ser su lenguaje principal. Especialmente para los usuarios con ciertos análisis de datos y bases de algoritmos, a menudo realizan análisis más profundos de los datos procesados. En este momento, las tareas de PySpark son naturalmente su mejor opción.
Spark juega un papel importante en la plataforma de desarrollo fuera de línea Kangaroo Cloud Data Stack . Por lo tanto, hemos realizado muchas optimizaciones internas en Spark para que sea más conveniente para los clientes enviar tareas usando Spark. También hemos creado algunas herramientas basadas en Spark para mejorar la funcionalidad de toda la plataforma de desarrollo fuera de línea de la pila de datos.
Además, Spark también juega un papel muy importante en el escenario del lago de datos. El módulo de almacén y lago integrado de Kangaroo Cloud ya admite dos lagos de datos principales, Iceberg y Hudi. Los usuarios pueden usar Spark para leer y escribir tablas de lago. La capa inferior de administración de tablas de lago también se implementa usando Spark para llamar a diferentes procedimientos almacenados.
A continuación se explicará la optimización realizada dentro de Kangaroo Cloud tanto desde el lado del motor como desde el propio Spark.
Optimización del lado del motor
Las funciones del motor interno de Kangaroo Cloud se utilizan principalmente para el envío de tareas, la adquisición del estado de las tareas, la adquisición del registro de tareas, la detención de tareas, la verificación de sintaxis, etc. Hemos optimizado cada punto de función en distintos grados. La siguiente es una breve introducción a través de dos ejemplos.
Se mejoró la velocidad de envío de Spark on Yarn
Con el desarrollo y la mejora continuos de nuevas funciones en el complemento Spark del lado del motor, el tiempo necesario para que el lado del motor envíe tareas Spark también aumenta en consecuencia. Por lo tanto, el código relacionado con el envío de tareas Spark debe optimizarse. acortar el tiempo de envío de tareas de Spark. Mejorar la experiencia del usuario.
Con este fin, hemos realizado el siguiente trabajo para algunos archivos de configuración comunes, como core-site.xml, Yarn-site.xml, archivo keytab, spark-sql-application.jar, etc., resulta que cada uno. Cada vez que envía una tarea, debe descargarla desde El servidor descarga y envía estos archivos de configuración. Ahora, después de la optimización, el archivo anterior solo debe descargarse una vez cuando se inicializa el cliente SparkYarnClient y luego cargarse en la ruta HDFS especificada. El envío posterior de tareas Spark solo debe especificarse en la ruta HDFS correspondiente a través de parámetros. De esta forma, el tiempo de envío de cada tarea de Spark se reduce considerablemente.
En la nueva versión de la pila de datos, para consultas temporales , también juzgaremos la complejidad del SQL que se ejecutará en función de reglas personalizadas y enviaremos el SQL menos complejo al SparkSQLEngine iniciado en el lado del motor para acelerar la operación. Este SparkSQLEngine interno solo se usaba para la verificación de sintaxis en el pasado, pero ahora también asume parte de la función de ejecución de SQL, y SparkSQLEngine también puede expandir y contraer recursos dinámicamente de acuerdo con la situación general de ejecución para lograr una utilización efectiva de los recursos.
Chequeo de gramática
En versiones anteriores de la pila de datos, para la verificación de la sintaxis de SQL, el motor primero enviará el SQL al servidor Spark Thrift. Este Spark Thrift Server se implementa en modo local y no solo se usa para la verificación de sintaxis. Todos los metadatos en otras plataformas se obtienen enviando SQL a este Spark Thrift Server para su ejecución. Este método tiene grandes desventajas, por lo que hemos realizado algunas optimizaciones. Una tarea de Spark se inicia en modo local en el lado del motor . Cuando se realiza la verificación de sintaxis, el SQL ya no se envía al servidor Spark Thrift. En cambio, se mantiene una SparkSession internamente para realizar la verificación de sintaxis directamente en el SQL.
Aunque este método no requiere una conexión sólida con el servidor Spark Thrift externo, ejercerá cierta presión sobre el componente de programación y la complejidad general de Engine-Plugins también aumentará mucho durante el proceso de implementación.
Para optimizar los problemas anteriores, hemos realizado una optimización adicional. Cuando se inicia el componente de programación, envía una tarea Spark SparkSQLEngine a Yarn. Puede entenderse como un servidor Spark Thrift remoto que se ejecuta en Yarn. El lado del motor monitorea el estado de salud de SparkSQLEngine en todo momento . De esta manera, cada vez que se realiza la verificación de sintaxis, el motor envía SQL a SparkSQLEngine a través de JDBC para la verificación de sintaxis.
A través de la optimización anterior, la plataforma de desarrollo fuera de línea se desacopla del servidor Spark Thrift. EasyManager no necesita implementar un servidor Spark Thrift adicional, lo que hace que la implementación sea más liviana. No es necesario mantener un proceso residente de Spark en modo local en el lado de la programación. También allana el camino para la mejora de las consultas interactivas de las tareas de Spark SQL en la plataforma de desarrollo fuera de línea.
Desacoplar la plataforma de desarrollo fuera de línea del servidor Spark Thrift implementado por EasyManager tendrá los siguientes beneficios:
· Capaz de realizar verdaderamente la coexistencia de múltiples clústeres de Spark y múltiples versiones
· La implementación estándar de EasyManager puede eliminar Spark Thrift Server y reducir la carga de operación y mantenimiento de primera línea
· La verificación de sintaxis de Spark SQL se vuelve más liviana, no es necesario almacenar en caché SparkContext, lo que reduce el uso de recursos del motor.
Optimización de la función Spark
A medida que se desarrolla el negocio, descubrimos que Spark de código abierto no tiene implementaciones funcionales correspondientes en algunos escenarios. Por lo tanto, hemos desarrollado más complementos nuevos basados en Spark de código abierto para admitir aplicaciones más funcionales de la pila de datos.
Diagnóstico de misión
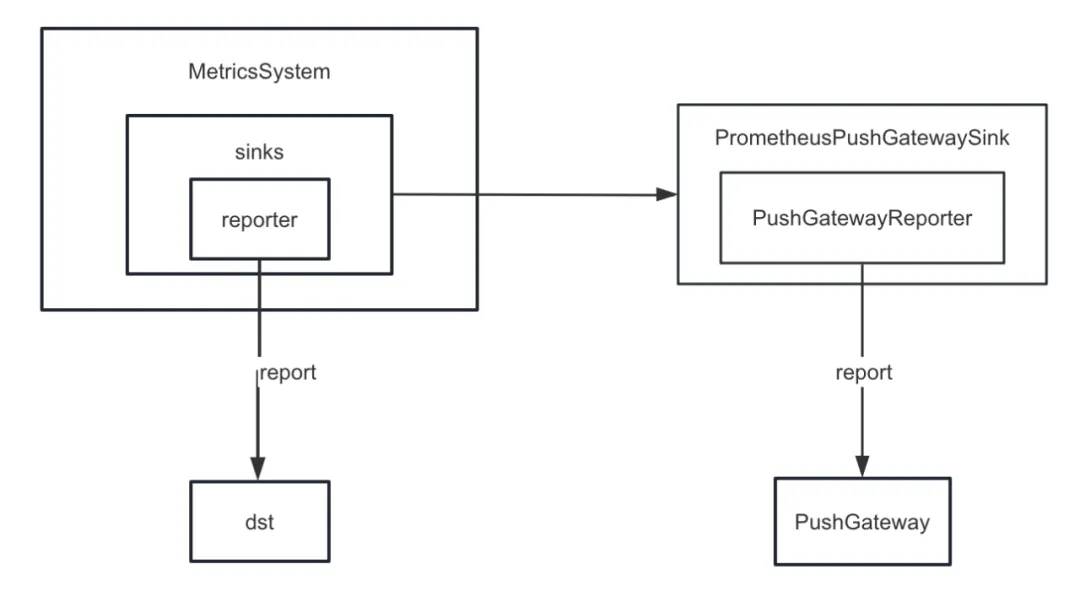
Primero, mejoramos el sumidero métrico de Spark. Spark proporciona varios receptores internamente además de ConsoleSink, también hay CSVSink, JmxSink, MetricsServlet, GraphiteSink, Slf4jSink, StatsdSink, etc. PrometheusServlet también se agregó después de Spark3.0, pero no puede satisfacer nuestras necesidades.
Al desarrollar la función de diagnóstico de tareas , necesitamos enviar los indicadores internos de Spark a PushGateway de manera unificada, y el servidor Prometheus extrae periódicamente los indicadores de PushGateway. Finalmente, llamando a la interfaz de consulta proporcionada por Prometheus, podemos consultar el interno. Indicadores de Spark en índice casi en tiempo real.

Pero Spark no implementa indicadores internos de hundimiento en PushGateway. Por lo tanto, agregamos el complemento spark-prometheus-sink y personalizamos PrometheusPushGatewaySink para enviar los indicadores internos de Spark a PushGateway.
Además, también personalizamos un nuevo indicador para describir el progreso de ejecución de la tarea de visualización de consultas temporales de Spark SQL. Los pasos específicos son los siguientes:
· Agregue un indicador para describir el progreso de las tareas fuera de línea personalizando JobProgressSource y registre el indicador en el sistema de gestión de indicadores en el sistema de gestión interno de Spark.
· Personaliza JobProgressListener y registra JobProgressListener en ListenerBus en el sistema de gestión interna de Spark. Entre ellos, la lógica del método onJobStart de JobProgressListener es calcular el número de todas las Tareas bajo el Trabajo actual; la lógica del método onTaskEnd es calcular y actualizar el progreso de la tarea actual fuera de línea después de que se completa cada Tarea ; El método onJobEnd consiste en calcular y actualizar el progreso actual de la tarea sin conexión después de que se completa cada trabajo. Actualizar el progreso actual de la tarea sin conexión.
Conexión a la versión comercial del clúster Hadoop
A medida que aumenta el número de clientes de Kangaroo Cloud, sus entornos también varían. Algunos clientes utilizan la versión de código abierto de los clústeres de Hadoop y un número considerable de clientes utilizan HDP, CDH, CDP, TDH, etc. Cuando nos conectamos a los clústeres de estos clientes, el lado de desarrollo a menudo necesita hacer nuevas adaptaciones, y el lado de operación y mantenimiento también necesita configurar parámetros adicionales o realizar otras operaciones adicionales cada vez que se implementa y actualiza.
Tomando HDP como ejemplo, cuando nos conectamos a HDP, el Spark que usamos es Spark2.3 que viene con HDP, y también necesitamos agregar algunos parámetros en el lado de operación y mantenimiento y mover todos los paquetes Jar de Spark que viene con HDP. para Especificar directorio. En realidad, estas operaciones traerán cierta confusión y problemas a la operación y el mantenimiento. Los diferentes tipos de clústeres necesitan mantener diferentes documentos de operación y mantenimiento, y el proceso de implementación también es más propenso a errores. Y de hecho, hemos realizado mejoras funcionales y correcciones de errores en el código fuente de Spark. Si usa Spark que viene con HDP, no podrá disfrutar de todos los beneficios de nuestro Spark mantenido internamente.
Para resolver los problemas anteriores, nuestro Spark interno se ha adaptado a los editores existentes y comunes en el mercado existente. En otras palabras, nuestro Spark interno puede ejecutarse en todos los clústeres de Hadoop diferentes. De esta manera, no importa qué tipo de clúster Hadoop esté conectado, la operación y el mantenimiento solo necesitan implementar el mismo Spark, lo que reduce en gran medida la presión de la implementación de operación y mantenimiento. Más importante aún, los clientes pueden usar directamente nuestra versión estable interna de Spark para disfrutar de más funciones nuevas y mayores mejoras de rendimiento.
Nuevas funciones de Spark3.2: AQE
En versiones anteriores de Data Stack, la versión predeterminada de Spark es 2.1.3. Posteriormente actualizamos la versión de Spark a 2.4.8. A partir de Data Stack 6.0, también se puede utilizar Spark 3.2. Aquí nos centramos en AQE , que también es la característica nueva más importante de Spark3.x.
Descripción general de AQE
Antes de Spark3.2, AQE estaba desactivado de forma predeterminada. Debe configurar spark.sql.adaptive.enabled en verdadero para habilitar AQE. Después de Spark3.2, AQE está habilitado de forma predeterminada. Siempre que la tarea cumpla con las condiciones de activación de AQE durante la operación, puede disfrutar de la optimización que brinda AQE.
Cabe señalar que la optimización de AQE solo ocurrirá en la fase de reproducción aleatoria. Si la operación de reproducción aleatoria no está involucrada en el proceso de ejecución de SQL, AQE no desempeñará ningún papel incluso si el valor de spark.sql.adaptive.enabled es. verdadero. Más precisamente, AQE entrará en vigor sólo si el plan de ejecución física contiene un nodo de intercambio o una subconsulta.
Durante la operación, AQE recopila la información de los archivos intermedios generados en la etapa del mapa aleatorio, recopila estadísticas sobre esta información y ajusta dinámicamente el Plan Lógico Optimizado y el Plan Spark que aún no se han ejecutado en función de las reglas existentes, modificando así el original. Declaración SQL. Optimización del tiempo de ejecución.
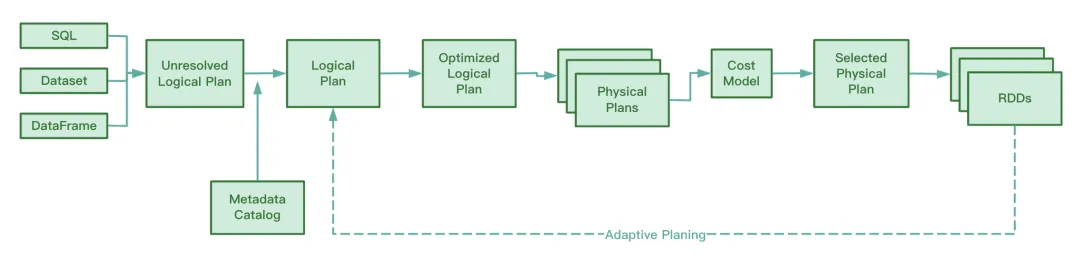
A juzgar por el código fuente de Spark, AQE implica las siguientes cuatro reglas de optimización:

Sabemos que RBO optimiza SQL en función de una serie de reglas, que incluyen la eliminación de predicados, la poda de columnas, el reemplazo constante, etc. Estas reglas estáticas se han integrado en Spark. Cuando Spark ejecuta SQL, estas reglas se aplicarán a SQL una por una.
Ventajas del AQE
Esta característica de CBO solo está disponible después de Spark2.2. En comparación con RBO, CBO combinará la información estadística de la tabla y seleccionará un plan de ejecución más optimizado en función de esta información estadística y el modelo de costos.
Sin embargo, CBO solo admite tablas registradas en Hive Metastore. CBO no admite archivos como parquet y orc almacenados en sistemas de archivos distribuidos. Además, si la tabla de Hive carece de información de metadatos, CBO no podrá recopilar estadísticas al recopilar estadísticas, lo que puede provocar que CBO falle.
Otra desventaja de CBO es que CBO necesita ejecutar ANALIZAR ESTADÍSTICAS DE COMPUTACIÓN DE TABLA para recopilar información estadística antes de la optimización. Si esta declaración encuentra una tabla grande durante la ejecución, llevará más tiempo y la eficiencia de recopilación será baja.
Ya sea CBO o RBO, son optimizaciones estáticas. Después de enviar el plan de ejecución física, si el volumen y la distribución de datos cambian mientras se ejecuta la tarea, CBO no optimizará el plan de ejecución física existente.
A diferencia de CBO y RBO, durante el proceso de ejecución, AQE analizará los archivos intermedios generados durante el proceso de mapa aleatorio y ajustará y optimizará dinámicamente el plan de ejecución lógico y el plan de ejecución física que aún no han comenzado a ejecutarse. En comparación con RBO, el procesamiento AQE puede obtener un plan de ejecución física más optimizado .
AQE tres características principales
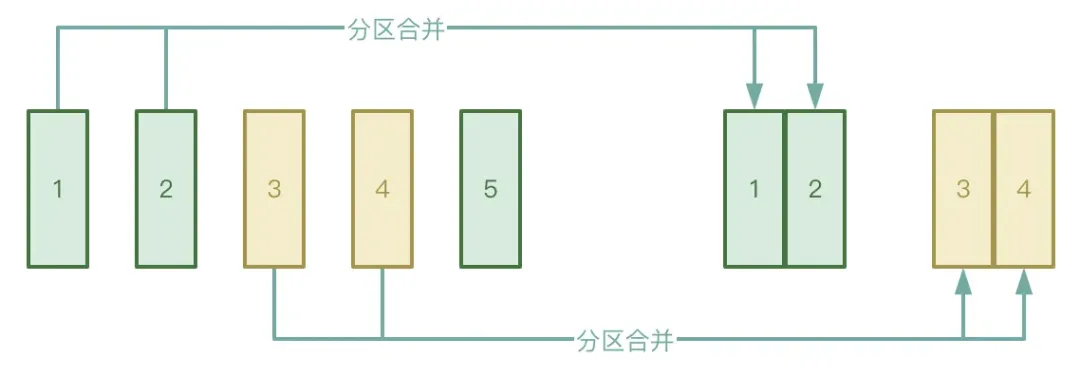
● Fusión automática de particiones
El proceso Shuffle se divide en dos etapas: etapa Map y etapa Reducir. La etapa Reducir extraerá los archivos temporales intermedios generados en la etapa Map al Ejecutor correspondiente. Si los datos procesados por la etapa Map se distribuyen de manera muy desigual, hay muchos. claves. De hecho, solo hay unas pocas claves de datos, los datos pueden formar una gran cantidad de archivos pequeños después del procesamiento.
Para evitar la situación anterior, puede habilitar la función de fusión automática de particiones de AQE para evitar iniciar demasiadas tareas de reducción para extraer los archivos pequeños generados en la etapa de Mapa.
● Procesamiento automático de sesgo de datos
El escenario de la aplicación es principalmente en uniones de datos. Cuando se produce una desviación de datos, AQE puede detectar automáticamente la partición sesgada y dividirla de acuerdo con ciertas reglas. Actualmente, en Spark3.2, el procesamiento automático de sesgo de datos es compatible tanto para SortMergeJoin como para ShuffleHashJoin.
● Unirse al ajuste de la estrategia
AQE degradará dinámicamente Hash Join y Sort Merge Join a Broadcast Join.
Sabemos que una vez que una tarea de Spark comienza a ejecutarse, se determina el grado de paralelismo. Por ejemplo, en la etapa de mapa aleatorio , el paralelismo es el número de particiones; en la etapa de reducción aleatoria, el paralelismo es el valor de spark.sql.shuffle.partitions, que por defecto es 200. Si la cantidad de datos se reduce durante la ejecución de la tarea Spark, lo que hace que el tamaño de la mayoría de las particiones se reduzca, se producirá un desperdicio de recursos si todavía se inician tantos subprocesos para procesar el pequeño conjunto de datos.
Durante el proceso de ejecución, AQE fusionará automáticamente particiones en función de los resultados temporales intermedios generados después de la reproducción aleatoria y, bajo ciertas condiciones, aplicando reglas de CoalesceShufflePartitions y combinando los parámetros proporcionados por el usuario, que en realidad está ajustando el número de reductores. Originalmente, un subproceso de reducción solo extraería los datos de una partición procesada. Ahora, un subproceso de reducción extraerá los datos de más particiones según la situación real, lo que puede reducir el desperdicio de recursos y mejorar la eficiencia de la ejecución de tareas. Dirección de descarga del "Libro técnico del sistema de indicadores industriales": https://www.dtstack.com/resources/1057?src=szsm
Dirección de descarga del "Informe técnico del producto Dutstack": https://www.dtstack.com/resources/1004?src=szsm
Dirección de descarga del "Libro técnico sobre prácticas de la industria de gobernanza de datos": https://www.dtstack.com/resources/1001?src=szsm
Para aquellos que quieran saber o consultar más sobre productos de big data, soluciones industriales y casos de clientes, visite el sitio web oficial de Kangaroo Cloud: https://www.dtstack.com/?src=szkyzg
Decidí renunciar al código abierto Hongmeng Wang Chenglu, el padre del código abierto Hongmeng: El código abierto Hongmeng es el único evento de software industrial de innovación arquitectónica en el campo del software básico en China: se lanza OGG 1.0, Huawei contribuye con todo el código fuente. Google Reader es asesinado por la "montaña de mierda de códigos" Fedora Linux 40 se lanza oficialmente Ex desarrollador de Microsoft: el rendimiento de Windows 11 es "ridículamente malo" Ma Huateng y Zhou Hongyi se dan la mano para "eliminar rencores" Compañías de juegos reconocidas han emitido nuevas regulaciones : los regalos de boda de los empleados no deben exceder los 100.000 yuanes Ubuntu 24.04 LTS lanzado oficialmente Pinduoduo fue sentenciado por competencia desleal Compensación de 5 millones de yuanes