Volcano Engine Edge Cloud es un servicio de computación en la nube basado en tecnología básica de computación en la nube y poder de computación heterogéneo de borde combinado con red, construido en infraestructura de borde a gran escala, formando una computación, red, almacenamiento, seguridad e inteligencia basados en el borde Una nueva generación de soluciones informáticas en la nube distribuidas con capacidades básicas.
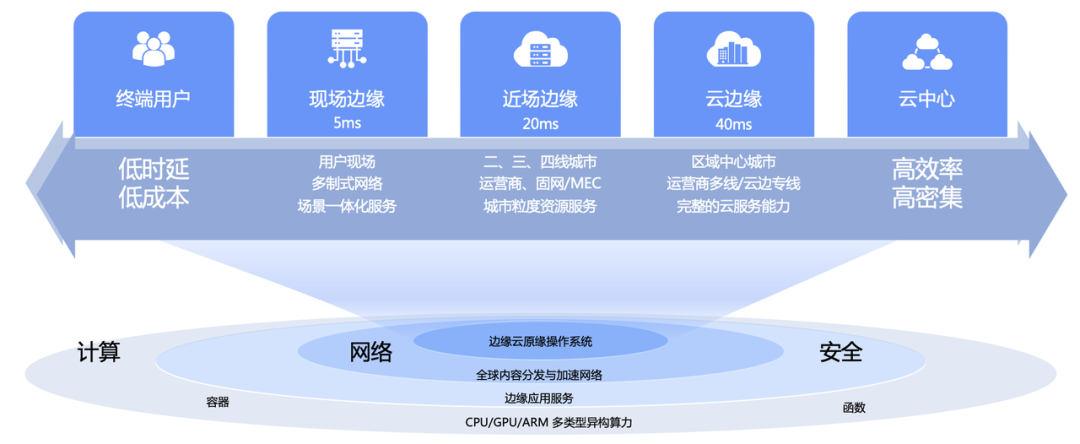
01- Desafíos de almacenamiento de escena perimetral
El almacenamiento perimetral es principalmente para escenarios comerciales típicos que se adaptan a la computación perimetral, como la representación perimetral. La representación perimetral del motor del volcán se basa en los recursos de potencia informática masivos subyacentes, que pueden ayudar a los usuarios a organizar fácilmente millones de colas de cuadros de representación, la programación de tareas de representación cercanas y la representación paralela de multitarea y multinodo. , lo que mejora en gran medida el renderizado. Presente brevemente el almacenamiento que se encuentra en la pregunta de renderizado perimetral:
- Es necesario unificar los metadatos del almacenamiento de objetos y el sistema de archivos, de modo que después de cargar los datos a través de la interfaz de almacenamiento de objetos, se pueda operar directamente a través de la interfaz POSIX;
- Satisfaga las necesidades de escenarios de alto rendimiento, especialmente al leer;
- Implementa completamente la interfaz S3 y la interfaz POSIX.
Para resolver los problemas de almacenamiento encontrados en la renderización de bordes, el equipo dedicó casi medio año a realizar pruebas de selección de almacenamiento. Inicialmente, el equipo eligió los componentes de almacenamiento interno de la empresa, que pueden satisfacer mejor nuestras necesidades en términos de sostenibilidad y rendimiento. Pero cuando se trata de escenas de borde, hay dos problemas específicos:
- En primer lugar, los componentes internos de la empresa están diseñados para la sala de cómputo central, y existen requisitos para la cantidad y los recursos físicos de la máquina, que son difíciles de cumplir en algunas salas de cómputo periféricas;
- En segundo lugar, los componentes de almacenamiento de toda la empresa se empaquetan juntos, incluidos: almacenamiento de objetos, almacenamiento de bloques, almacenamiento distribuido, almacenamiento de archivos, etc., mientras que el borde necesita principalmente almacenamiento de archivos y almacenamiento de objetos, que deben adaptarse y transformarse. y un establo en línea también requiere un proceso.
Después de que el equipo discutiera, se formó una solución factible: CephFS + puerta de enlace MinIO . MinIO proporciona un servicio de almacenamiento de objetos, el resultado final se escribe en CephFS y el motor de renderizado monta CephFS para realizar las operaciones de renderizado. Durante el proceso de prueba y verificación, cuando la cantidad de archivos llegó a decenas de millones, el rendimiento de CephFS comenzó a degradarse, ocasionalmente se congelaba, y los comentarios del lado comercial no cumplían con los requisitos.
De igual forma existe otra solución basada en Ceph, que es utilizar Ceph RGW + S3FS. Esta solución básicamente puede cumplir con los requisitos, pero el rendimiento de escribir y modificar archivos no cumple con los requisitos de la escena.
Después de más de tres meses de pruebas, hemos aclarado varios requisitos básicos para el almacenamiento en la renderización de bordes:
- La operación y el mantenimiento no deben ser demasiado complicados : el personal de I+D de almacenamiento puede comenzar con los documentos de operación y mantenimiento; el trabajo de operación y mantenimiento de la expansión posterior y el manejo de fallas en línea deben ser lo suficientemente simples.
- Confiabilidad de los datos : debido a que el servicio de almacenamiento se proporciona directamente al usuario, no se permite que los datos escritos con éxito se pierdan o sean inconsistentes con los datos escritos.
- Use un conjunto de metadatos y admita tanto el almacenamiento de objetos como el almacenamiento de archivos : de esta manera, cuando el lado comercial lo usa, no necesita cargar y descargar archivos varias veces, lo que reduce la complejidad del uso del lado comercial.
- Mejor desempeño en lectura : El equipo necesita resolver el escenario de más lectura y menos escritura, por lo que esperan tener un mejor desempeño en lectura.
- Actividad de la comunidad : una comunidad activa puede responder más rápido al resolver problemas existentes y promover activamente la iteración de nuevas funciones.
Después de aclarar los requisitos básicos, descubrimos que las tres soluciones anteriores no satisfacían del todo las necesidades.
02- Beneficios de usar JuiceFS
El equipo de almacenamiento perimetral de Volcano Engine se enteró de JuiceFS en septiembre de 2021 y tuvo algunos intercambios con el equipo de Juicedata. Después de la comunicación, decidimos probarlo en el escenario de la nube perimetral. La documentación oficial de JuiceFS es muy rica y fácil de leer. Puede conocer más detalles leyendo la documentación.
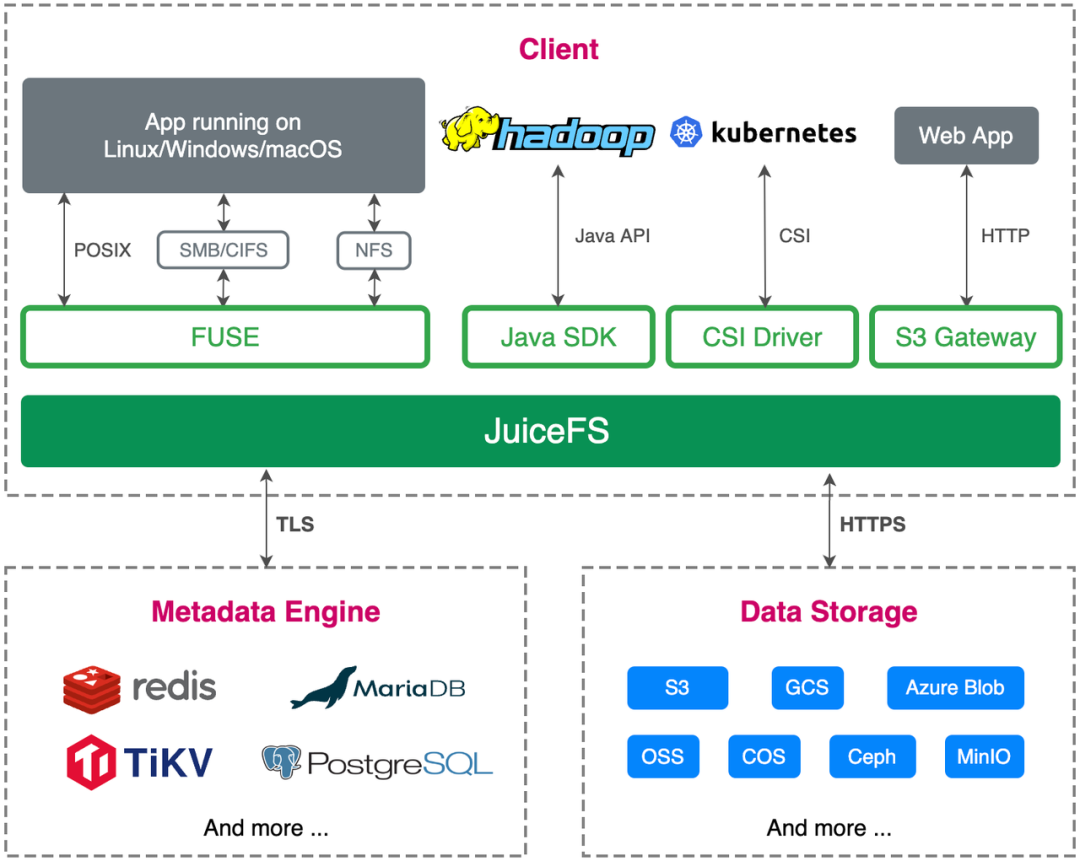
Por lo tanto, comenzamos a realizar pruebas PoC en el entorno de prueba, enfocándonos en la verificación de factibilidad, la complejidad de O&M y la implementación, y la adaptación al negocio upstream, y si cumple con las necesidades del negocio upstream.
Implementamos dos conjuntos de entornos, uno basado en Redis + Ceph de un solo nodo y el otro basado en MySQL + Ceph de una sola instancia .
En términos de la construcción del entorno general, Redis, MySQL y Ceph (implementados a través de Rook) son relativamente maduros y los materiales de referencia para implementar el plan de operación y mantenimiento son relativamente completos. Al mismo tiempo, el cliente de JuiceFS también puede conectar estos bases de datos y Ceph de forma sencilla y cómoda.El proceso de implementación es muy sencillo.
En términos de adaptación comercial, la nube perimetral se desarrolla e implementa en base a la nube nativa. JuiceFS es compatible con la API S3, es totalmente compatible con el protocolo POSIX y admite el montaje CSI, lo que satisface completamente nuestras necesidades comerciales.
Después de pruebas exhaustivas, descubrimos que JuiceFS satisface completamente las necesidades del lado comercial y se puede implementar y ejecutar en producción para satisfacer las necesidades en línea del lado comercial.
Beneficio 1: Optimización de procesos comerciales
Antes de usar JuiceFS, la renderización perimetral utilizaba principalmente el servicio de almacenamiento de objetos interno (TOS) de ByteDance. Los usuarios subían datos a TOS, y el motor de renderización descargaba los archivos subidos por los usuarios desde TOS al local, y el motor de renderización leía los archivos locales. generar el resultado de la representación y, a continuación, volver a cargar el resultado de la representación en TOS y, finalmente, el usuario descarga el resultado de la representación de TOS. Hay varios enlaces en el proceso de interacción general, y en el medio hay una gran cantidad de copias de red y de datos, por lo que habrá fluctuaciones en la red o una gran demora en este proceso, lo que afectará la experiencia del usuario.
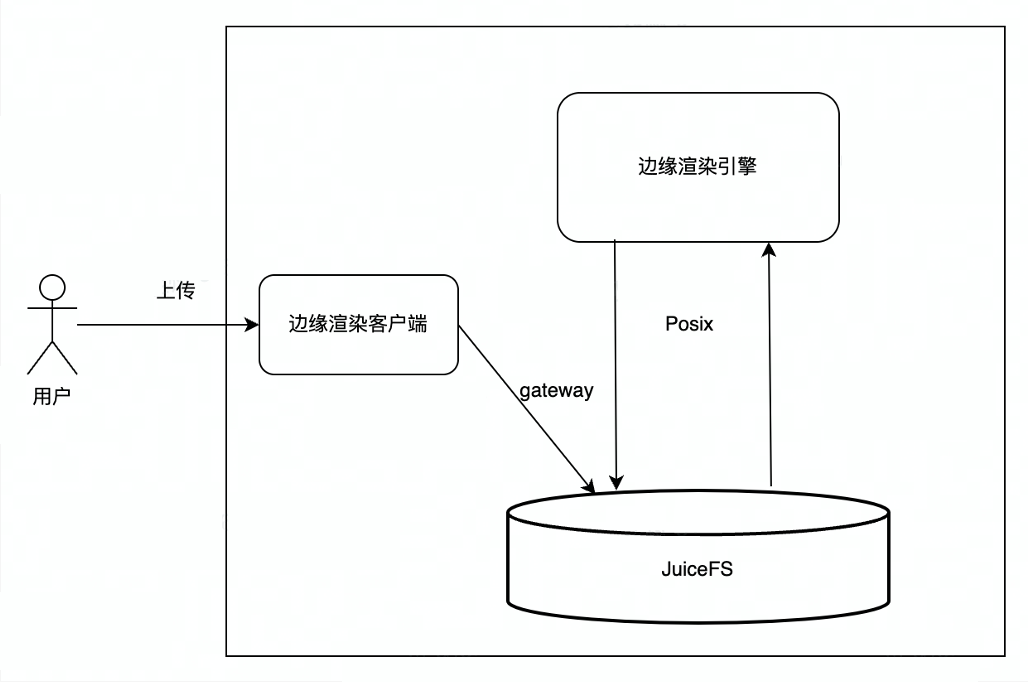
Después de usar JuiceFS, el proceso se convierte en que el usuario carga a través de la puerta de enlace JuiceFS S3. Dado que JuiceFS realiza la unificación del almacenamiento de objetos y los metadatos del sistema de archivos, JuiceFS se puede montar directamente en el motor de renderizado, y el motor de renderizado utiliza la interfaz POSIX. para procesar archivos Leer y escribir, el usuario final descarga directamente el resultado de la representación de la puerta de enlace JuiceFS S3, el proceso general es más conciso, eficiente y más estable.
Beneficio 2: Aceleración de lectura de archivos y escritura secuencial de archivos grandes
Gracias al mecanismo de almacenamiento en caché del lado del cliente de JuiceFS, podemos almacenar en caché los archivos que se leen con frecuencia localmente en el motor de renderizado, lo que acelera enormemente la lectura de archivos. Hicimos una prueba comparativa sobre si abrir el caché y descubrimos que el rendimiento se puede aumentar entre 3 y 5 veces después de usar el caché .
Del mismo modo, debido a que el modelo de escritura de JuiceFS es escribir en la memoria primero, cuando un fragmento (predeterminado 64M) está lleno, o cuando la aplicación llama a la interfaz de escritura forzada (interfaz close y fsync), los datos se cargarán en el almacenamiento de objetos, y la carga de datos es exitosa Después de eso, actualice el motor de metadatos. Por lo tanto, al escribir archivos grandes, escriba primero en la memoria y luego en el disco, lo que puede mejorar en gran medida la velocidad de escritura de los archivos grandes.
En la actualidad, los escenarios de uso de Edge son principalmente de representación, el sistema de archivos lee más y escribe menos, y la escritura de archivos también es principalmente para archivos grandes. Los requisitos de estos escenarios comerciales son muy consistentes con los escenarios aplicables de JuiceFS Después de que el lado comercial reemplazó el almacenamiento con JuiceFS, la evaluación general también es muy alta.
03- Cómo usar JuiceFS en escenas de borde
JuiceFS se implementa principalmente en Kubernetes. Cada nodo tiene un contenedor DaemonSet responsable de montar el sistema de archivos de JuiceFS y luego lo monta en el pod del motor de renderizado en forma de HostPath. Si el punto de montaje falla, DaemonSet se encargará de restaurar automáticamente el punto de montaje.
En términos de control de autoridad, el almacenamiento perimetral utiliza el servicio LDAP para autenticar la identidad de los nodos del clúster de JuiceFS, y cada nodo del clúster de JuiceFS es autenticado por el cliente LDAP y el servicio LDAP.
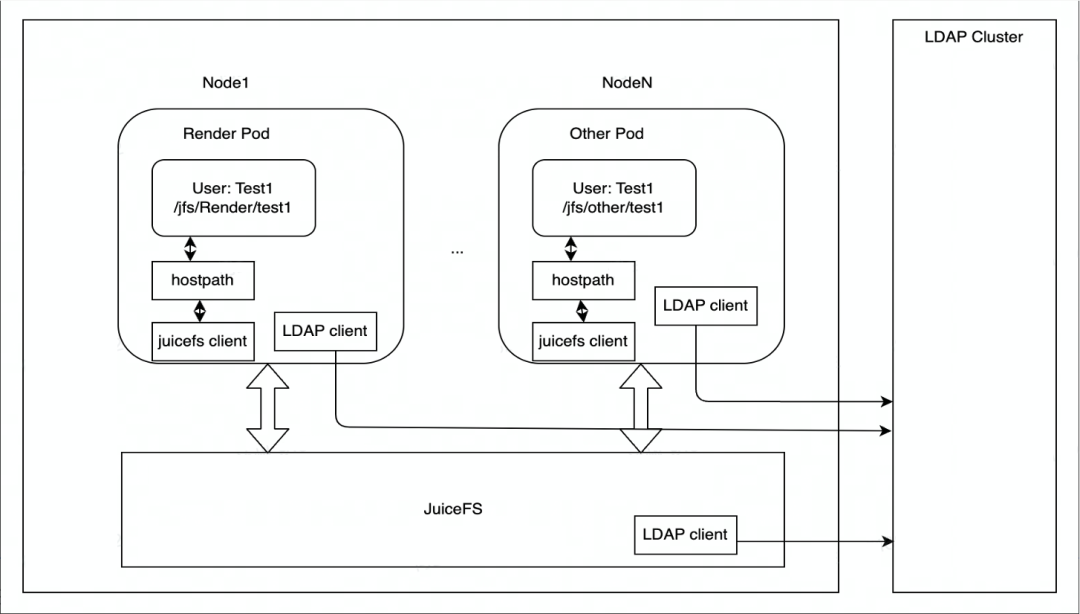
Nuestros escenarios de aplicación actuales se basan principalmente en la representación y se expandirán a más escenarios comerciales en el futuro. En términos de acceso a datos, actualmente se accede al almacenamiento perimetral principalmente a través de HostPath. Si existe la necesidad de una expansión elástica en el futuro, se considerará la implementación del controlador CSI de JuiceFS.

04- Experiencia práctica en ambiente de producción
motor de metadatos
JuiceFS es compatible con una gran cantidad de motores de metadatos (como MySQL, Redis) y el entorno de producción de almacenamiento perimetral del motor del volcán utiliza MySQL . Después de evaluar la escala del volumen de datos y la cantidad de archivos (la cantidad de archivos es de decenas de millones, probablemente decenas de millones, el escenario de más lecturas y menos escrituras), así como el rendimiento de escritura y lectura, encontramos que MySQL está en operación y mantenimiento, confiabilidad de datos, y el lado comercial lo ha hecho mejor.
MySQL actualmente adopta dos esquemas de implementación: instancia única y instancia múltiple (una maestra y dos esclavas), que se pueden seleccionar de manera flexible para diferentes escenarios en el perímetro. En un entorno con pocos recursos, se puede usar una sola instancia para la implementación y el rendimiento de MySQL es relativamente estable dentro de un rango determinado. Ambos esquemas de implementación utilizan discos en la nube de alto rendimiento (proporcionados por clústeres de Ceph) como discos de datos de MySQL, lo que puede garantizar que los datos de MySQL no se perderán incluso en implementaciones de una sola instancia.
En escenarios con abundantes recursos, se pueden usar varias instancias para la implementación. La sincronización maestro-esclavo de múltiples instancias se realiza a través del componente orquestador proporcionado por MySQL Operator ( https://github.com/bitpoke/mysql-operator) Se considera correcto solo si dos instancias esclavas se sincronizan con éxito, pero se agota el tiempo de espera También se establece el período Si la sincronización no se completa después de que expire el tiempo de espera, devolverá el éxito y se emitirá una alarma. Una vez que se completa el plan de recuperación de desastres posterior, el disco local puede usarse como el disco de datos de MySQL para mejorar aún más el rendimiento de lectura y escritura, reducir la latencia y aumentar el rendimiento.
Recursos del contenedor de configuración de instancia única de MySQL :
- UPC: 8C
- Memoria: 24G
- Disco: 100 G (basado en Ceph RBD, los metadatos ocupan alrededor de 30 G de espacio en disco en el escenario de almacenamiento de decenas de millones de archivos)
- Imagen del contenedor: mysql:5.7
my.cnfConfiguración MySQL :
ignore-db-dir=lost+found # 如果使用 MySQL 8.0 及以上版本,需要删除这个配置
max-connections=4000
innodb-buffer-pool-size=12884901888 # 12G
almacenamiento de objetos
El almacenamiento de objetos utiliza un clúster de Ceph autoconstruido , que se implementa a través de Rook. El entorno de producción actual utiliza la versión Octopus. Con Rook, los clústeres de Ceph se pueden operar y mantener de manera nativa en la nube, y los componentes de Ceph se pueden administrar y controlar a través de Kubernetes, lo que reduce en gran medida la complejidad de la implementación y administración del clúster de Ceph.
Configuración del hardware del servidor Ceph:
- CPU nuclear 128
- RAM de 512 GB
- Disco del sistema: 2T * 1 NVMe SSD
- Disco de datos: 8T * 8 NVMe SSD
Configuración del software del servidor Ceph:
- Sistema operativo: Debian 9
- Núcleo: modificar /proc/sys/kernel/pid_max
- Versión cefalométrica: pulpo
- Backend de almacenamiento de Ceph: BlueStore
- Número de réplicas de Ceph: 3
- Apague la función de ajuste automático del grupo de colocación.
El enfoque principal de la representación perimetral es la baja latencia y el alto rendimiento, por lo que, en términos de selección de hardware del servidor, configuramos el clúster con discos SSD NVMe. Otras configuraciones se basan principalmente en la versión que mantiene el motor volcano, y el sistema operativo que elegimos es Debian 9. Para la redundancia de datos, se configuran tres copias para Ceph.En un entorno informático perimetral, EC puede ser inestable debido a limitaciones de recursos.
Cliente de JuiceFS
El cliente de JuiceFS admite la conexión directa a Ceph RADOS (mejor rendimiento que Ceph RGW), pero esta función no está habilitada de forma predeterminada en el binario oficial, por lo que es necesario volver a compilar el cliente de JuiceFS. Debe instalar librados antes de compilar. Se recomienda que la versión de librados corresponda a la versión de Ceph. Debian 9 no tiene un paquete librados-dev que coincida con la versión de Ceph Octopus (v15.2.*), por lo que debe descargar el paquete de instalación usted mismo.
Después de instalar librados-dev, puede comenzar a compilar el cliente JuiceFS. Usamos Go 1.19 para compilar aquí. En 1.19, se agrega la función de controlar la asignación máxima de memoria ( https://go.dev/doc/gc-guide#Memory_limit), que puede evitar que el cliente JuiceFS ocupe demasiado en casos extremos OOM ocurre debido a más memoria.
make juicefs.ceph
Después de compilar el cliente de JuiceFS, puede crear un sistema de archivos y montar el sistema de archivos de JuiceFS en el nodo informático. Para conocer los pasos detallados, consulte la documentación oficial de JuiceFS.
05- Futuro y perspectiva
JuiceFS es un producto de sistema de almacenamiento distribuido en el campo nativo de la nube. Proporciona un componente de controlador CSI que puede admitir muy bien los métodos de implementación nativos de la nube. Brinda a los usuarios opciones muy flexibles en términos de implementación de operación y mantenimiento. Los usuarios pueden elegir la nube También puede elegir la implementación privatizada, que es relativamente simple en términos de expansión de almacenamiento y operación y mantenimiento. Es totalmente compatible con el estándar POSIX y utiliza el mismo conjunto de metadatos que S3, lo que lo hace muy conveniente para llevar a cabo el proceso operativo de carga, procesamiento y descarga. Debido a que su almacenamiento de back-end es una función de almacenamiento de objetos, hay una gran demora en la lectura y escritura de archivos pequeños aleatorios, y el IOPS es relativamente bajo Para escenarios con más y menos escritura, JuiceFS tiene una ventaja relativamente grande, que es muy adecuado para las necesidades empresariales de los escenarios de renderizado perimetral .
Los planes futuros del equipo de nube perimetral de Volcano Engine relacionados con JuiceFS son los siguientes:
- Más nativo de la nube : JuiceFS se usa actualmente en forma de HostPath Más adelante, considerando algunos escenarios de escalado elástico, podemos cambiar a usar JuiceFS en forma de CSI Driver;
- Actualización del motor de metadatos : abstraiga el servicio gRPC de un motor de metadatos, que proporciona capacidades de almacenamiento en caché de varios niveles para adaptarse mejor a escenarios con más lecturas y menos escrituras. El almacenamiento de metadatos subyacente puede considerar migrar a TiKV para admitir una mayor cantidad de archivos.En comparación con MySQL, puede aumentar mejor el rendimiento del motor de metadatos a través de la expansión horizontal;
- Nuevas funciones y correcciones de errores : para el escenario comercial actual, se agregarán algunas funciones y se corregirán algunos errores, y esperamos contribuir con relaciones públicas a la comunidad y retribuir a la comunidad.
Si es de ayuda, preste atención a nuestro proyecto Juicedata/JuiceFS . (0ᴗ0✿)