

Dirección del artículo : https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
Dirección Github : https://github.com/facebookresearch/llama
Introducción a LLaMA 2
Meta se lanzó antes del modelo grande de código semiabierto LLaMA. Desde el lanzamiento de LLaMA, los modelos extendidos basados en él han surgido uno tras otro, especialmente la serie alpaca. Estoy resumiendo estos modelos grandes recientemente. Los lectores interesados pueden leer: Resumen de LLaMA y sus modelos extendidos (1 )
Hoy la compañía Meta lanzó la versión LLaMA 2, que es una versión de código abierto y disponible comercialmente, y ha sido muy actualizada en modelos y efectos. Esta vez, LLaMA 2 anunció un total de tres tamaños de parámetros de 7B , 13B y 70B. Además, también entrenó 34 mil millones de variantes de parámetros, pero no se publicó y solo se mencionó en el informe técnico. En comparación con LLaMA, LLaMA 2 tiene un 40 % más de datos de entrenamiento y la longitud del contexto también se actualizó de 2048 a 4096. Puede comprender y generar texto más largo y adopta un mecanismo de atención de consultas grupales. Específicamente, el modelo de preentrenamiento de LLaMA 2 se entrena en 2 billones de tokens, y el modelo de LLaMA 2-Chat se ajusta en 1 millón de datos etiquetados por humanos.

LLaMA 2 supera a otros modelos de lenguaje de código abierto en muchos puntos de referencia externos, incluidas las pruebas de inferencia, codificación, competencia y conocimiento, como se muestra en la siguiente tabla:

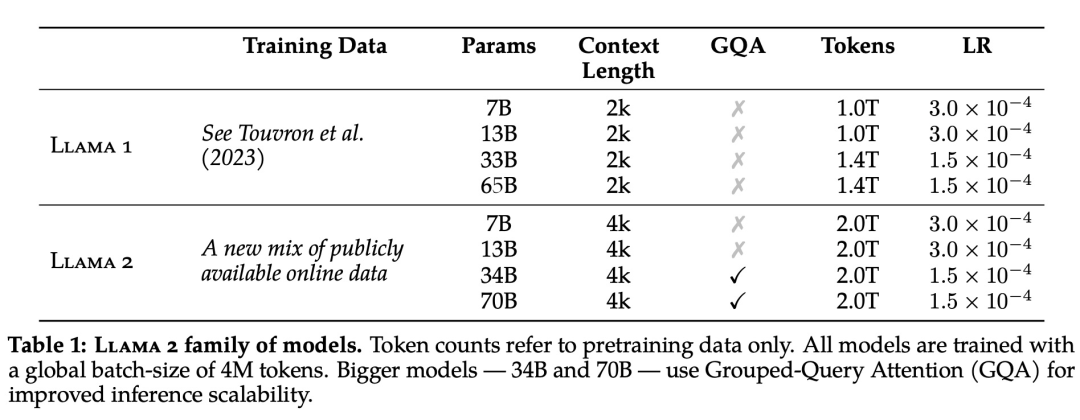
Pre-entrenamiento LLaMA 2
El corpus de capacitación para LLaMA 2 contiene datos mixtos de fuentes disponibles públicamente y no incluye datos relacionados con Meta productos o servicios. LLaMA 2 adopta la mayoría de las configuraciones previas al entrenamiento y la arquitectura del modelo en LLaMA, incluida la arquitectura de transformador estándar, la prenormalización mediante RMSNorm, la función de activación de SwiGLU y la incrustación de posición rotada.
En cuanto a los hiperparámetros, Meta se entrena con el optimizador AdamW, donde β_1 = 0,9, β_2 = 0,95, eps = 10^−5. Al mismo tiempo, se utilizó un programa de tasa de aprendizaje de coseno (2000 pasos de calentamiento), y la tasa de aprendizaje final se redujo al 10 % de la tasa de aprendizaje máxima.
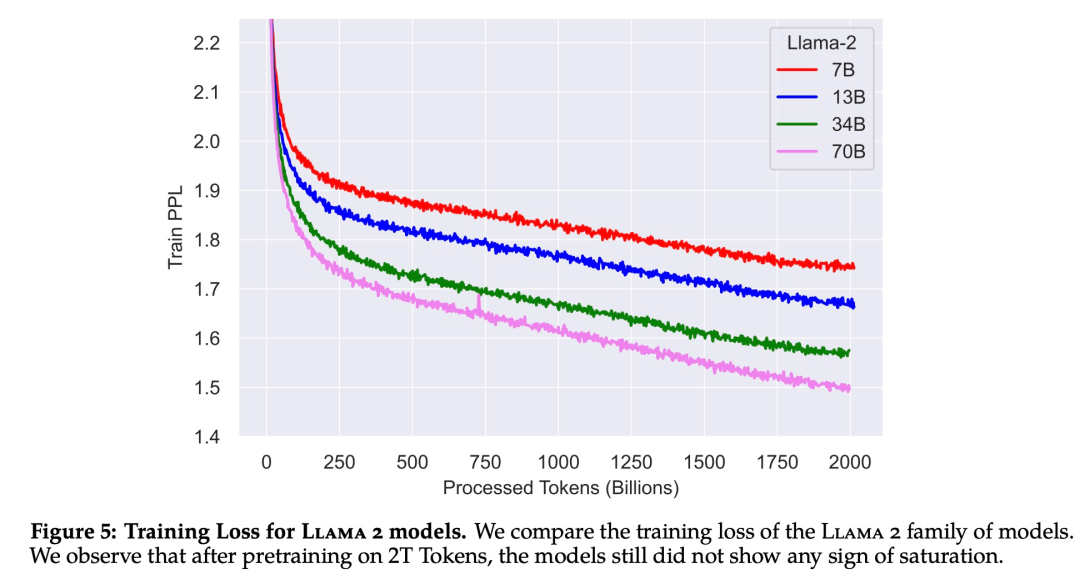
La Figura 5 a continuación muestra la curva de pérdida de entrenamiento para LLaMA 2 para estas configuraciones de hiperparámetros.
En términos de hardware de entrenamiento, Meta entrenó previamente el modelo en su Research Super Cluster (RSC), así como en su clúster de producción interno. Ambos clústeres usaban NVIDIA A100.
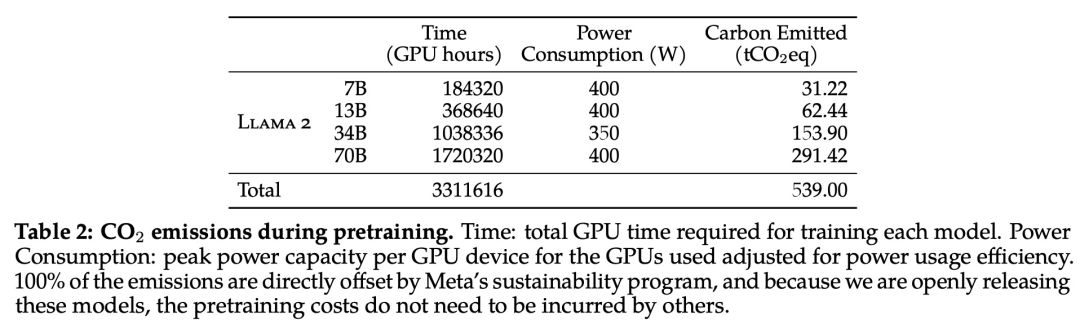
En cuanto a la huella de carbono del preentrenamiento, Meta calculó las emisiones de carbono generadas por el preentrenamiento del modelo LLaMA 2 utilizando la estimación del consumo de energía y la eficiencia de carbono de los dispositivos GPU según métodos de investigación anteriores.
Evaluación del modelo preentrenado LLaMA 2


LLaMA-Chat
El ajuste fino de LLaMA-Chat se basa en LLaMA 2 en 100 datos etiquetados por humanos. El diagrama de flujo general del ajuste fino de LLaMA-Chat es el siguiente:
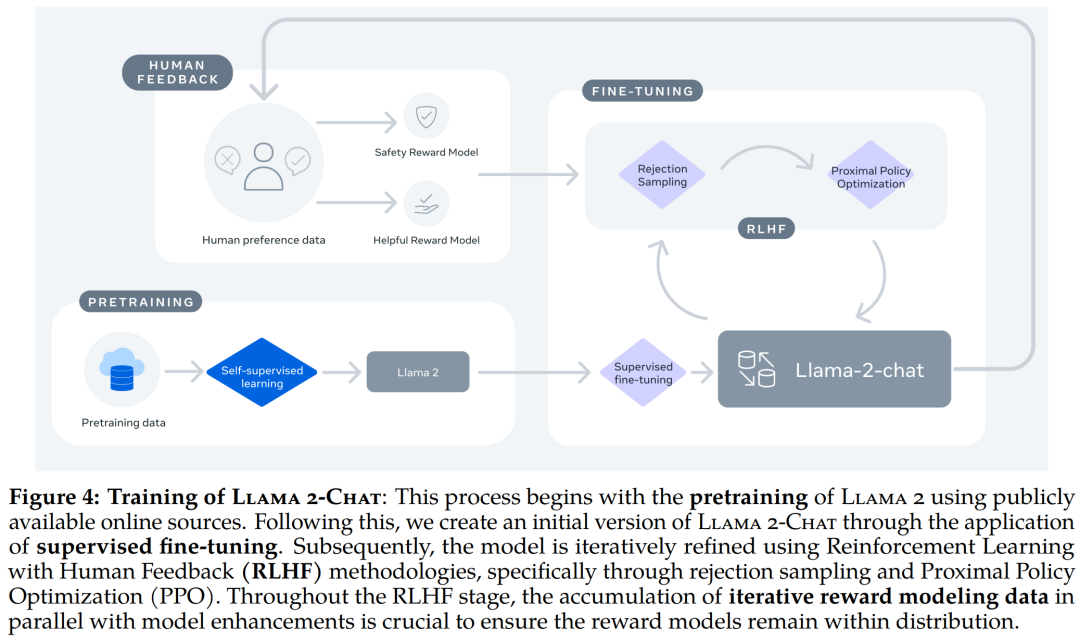
Los siguientes son los detalles de SFT y RLHF respectivamente:
Ajuste fino supervisado (SFT)
En la etapa SFT, se recopilan miles de ejemplos de datos SFT de alta calidad, como se muestra en la Tabla 5 a continuación:

Durante el ajuste fino, cada muestra consta de un aviso y una respuesta. Para garantizar que la longitud de la secuencia del modelo se rellene correctamente, Meta concatena todas las indicaciones y respuestas en el conjunto de entrenamiento. Utilizan un token especial para separar los fragmentos de solicitud y respuesta, y utilizan un objetivo autorregresivo para poner a cero la pérdida de token de las solicitudes del usuario, por lo que se propagan hacia atrás solo en tokens de respuesta. Finalmente, el modelo fue afinado dos veces.
Comentarios basados en humanos ( RLHF)
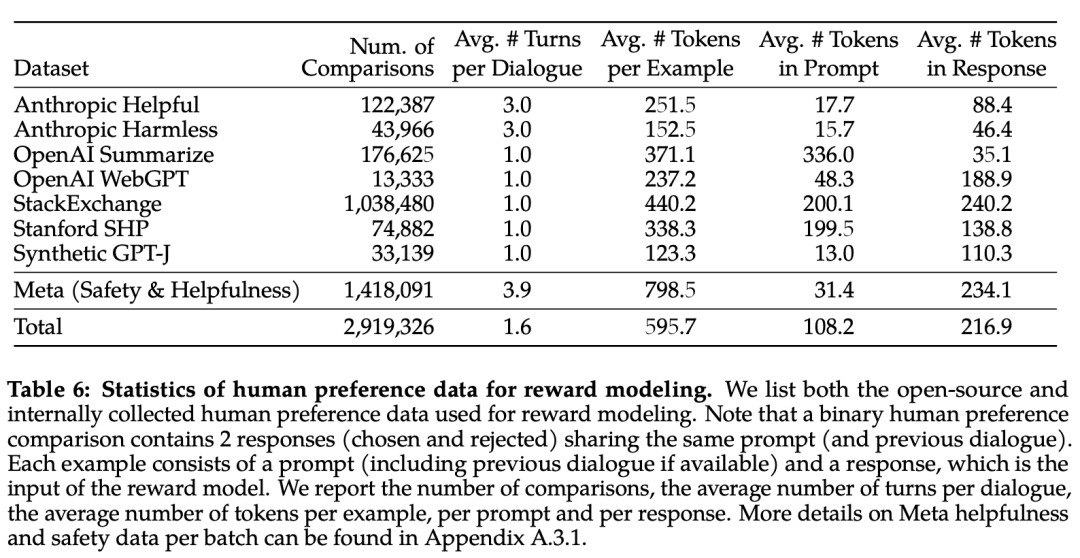
RLHF tiene como objetivo alinear el comportamiento del modelo con las preferencias humanas y el seguimiento de instrucciones. La Tabla 6 a continuación informa estadísticas sobre los datos de modelado de recompensas recopilados por Meta a lo largo del tiempo y comparados con varios conjuntos de datos de preferencia de fuente abierta. Recopilaron un gran conjunto de datos de más de 1 millón de comparaciones binarias basadas en criterios específicos aplicados por humanos, es decir, datos de modelos de metarrecompensas.
El modelo de recompensa de RM toma como entrada las respuestas del modelo y sus señales correspondientes (incluido el contexto de rondas anteriores) y genera una puntuación escalar que representa la calidad de la generación del modelo (p. ej., utilidad y seguridad). Usando este puntaje de respuesta como recompensa, Meta optimiza LLaMA 2-Chat durante RLHF para alinearse mejor con las preferencias humanas y mejorar la utilidad y la seguridad.
En cada lote de anotaciones de preferencias humanas para el modelado de recompensas, Meta toma 1000 muestras como conjunto de prueba para evaluar el modelo y llama a la recopilación de todas las señales para el conjunto de prueba correspondiente "meta-utilidad" y "meta-seguridad", respectivamente.
Los resultados de precisión se informan en la Tabla 7 a continuación. Como era de esperar, el propio modelo de recompensas de Meta se desempeñó mejor en el conjunto de pruebas interno recopilado en base a LLaMA 2-Chat, con el modelo de recompensas de "Utilidad" que se desempeñó mejor en el conjunto de pruebas de "Metautilidad" y, de manera similar, el modelo de recompensas de "Seguridad" se desempeñó mejor en el conjunto de pruebas de "Metaseguridad".
En general, el modelo de recompensa de Meta supera todas las líneas de base, incluido GPT-4. Curiosamente, GPT-4 supera a otros modelos que no son de meta-recompensa a pesar de que no se entrenó directamente ni se dirigió específicamente a esta tarea de modelado de recompensa.
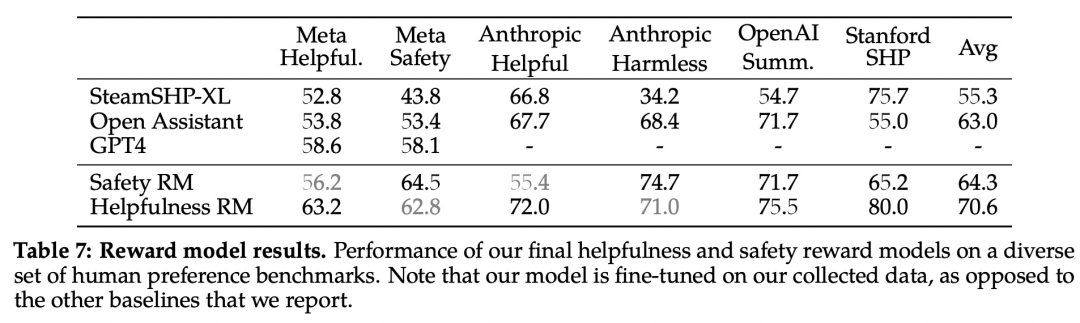
Meta estudia las tendencias de escalado de los modelos de recompensa en términos de datos y tamaño del modelo, ajustando diferentes tamaños de modelos con cantidades crecientes de datos de modelos de recompensa recopilados cada semana. Estas tendencias se informan en la Figura 6 a continuación, que muestra los resultados esperados de un mayor rendimiento para modelos más grandes con cantidades similares de datos.
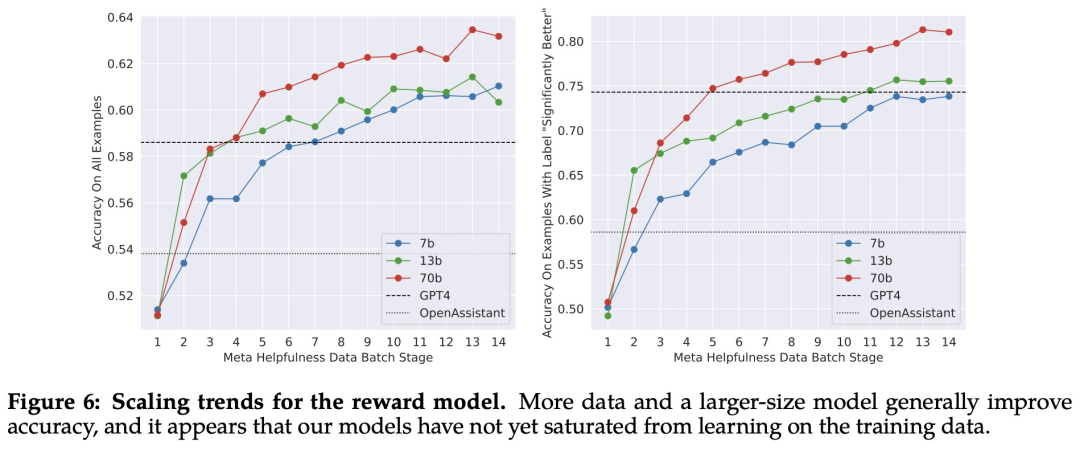
A medida que se reciben más lotes de anotaciones de datos de preferencias humanas, se pueden entrenar mejores modelos de recompensa y recopilar más pistas. Por lo tanto, Meta entrenó versiones sucesivas del modelo RLHF, denominado aquí como RLHF-V1, ..., RLHF-V5.
RLHF se ajusta aquí utilizando dos algoritmos principales:
-
Optimización de políticas proximales (PPO);
-
Ajuste fino del muestreo de rechazo.
Evaluación de resultados de RLHF
La Figura 11 a continuación informa el progreso de diferentes versiones de SFT y RLHF en términos de seguridad y utilidad, según lo evaluado por el modelo de recompensa de seguridad y utilidad dentro de Meta.
Como se muestra en la Figura 12 a continuación, el modelo LLaMA 2-Chat supera significativamente al modelo de código abierto tanto en las indicaciones de una sola ronda como en las de varias rondas. En particular, LLaMA 2-Chat 7B supera a MPT-7B-chat en el 60 % de las sugerencias, y LLaMA 2-Chat 34B exhibe una tasa de ganancias general de más del 75 % en relación con Vicuna-33B y Falcon 40B del mismo tamaño.
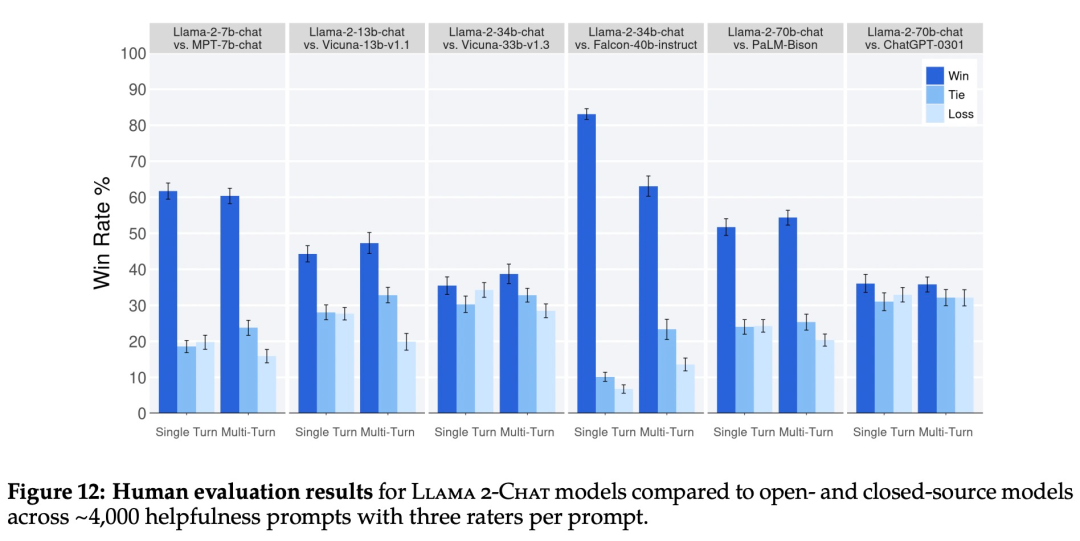
Si bien los resultados muestran que LLaMA 2-Chat está a la par con ChatGPT en términos de evaluación humana, se debe tener en cuenta que la evaluación humana tiene algunas limitaciones.
-
Según los estándares académicos y de investigación, este artículo tiene un gran conjunto de sugerencias de 4k. Sin embargo, esto no incluye el uso real de estos modelos, que podría ser mucho más numeroso.
-
La diversidad de indicaciones puede ser otro factor que afecte los resultados; por ejemplo, la indicación establecida en este documento no incluye ninguna indicación relacionada con la codificación o el razonamiento.
-
Este artículo solo evalúa la generación final de diálogos de múltiples turnos. Un enfoque más interesante para la evaluación podría ser pedirle al modelo que complete una tarea y califique la experiencia general del modelo en múltiples conversaciones.
-
La evaluación humana de los modelos generativos es inherentemente subjetiva y ruidosa. Por lo tanto, la evaluación con un conjunto diferente de pistas o una instrucción diferente puede arrojar resultados diferentes.
LLaMA Seguridad
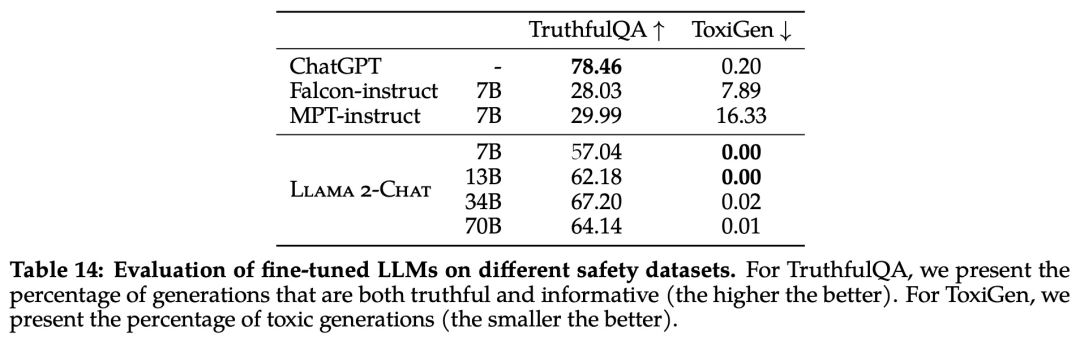
El estudio evaluó la seguridad de LLaMA 2 utilizando tres puntos de referencia de uso común, centrándose en tres dimensiones clave:
-
Autenticidad, se refiere a si el modelo de lenguaje generará información de error, usando el benchmark TruthfulQA;
-
Toxicidad, se refiere a si el modelo de lenguaje producirá contenido "tóxico", grosero y dañino, utilizando el punto de referencia ToxiGen;
-
Sesgo, se refiere a si el modelo de lenguaje producirá contenido sesgado, utilizando el punto de referencia BOLD.
Seguridad preentrenada
En primer lugar, los datos previos al entrenamiento son muy importantes para el modelo. Meta realiza experimentos para evaluar la seguridad de los datos previos al entrenamiento.
El estudio utilizó el clasificador HateBERT ajustado en el conjunto de datos ToxiGen para medir la "toxicidad" de los datos en inglés del corpus previo al entrenamiento. Los resultados específicos se muestran en la Figura 13 a continuación:

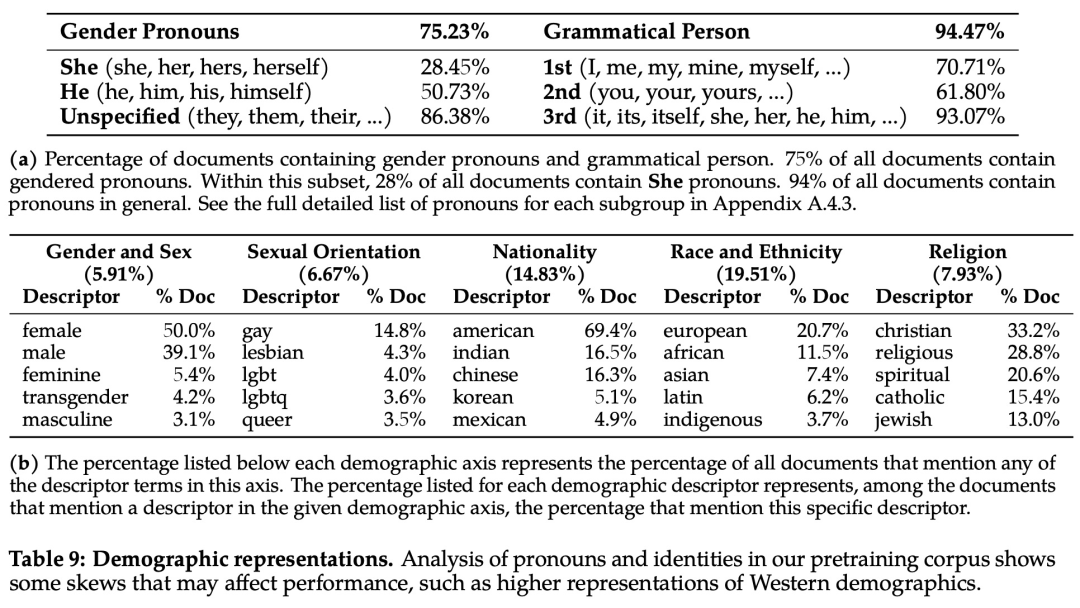
Para analizar el problema del sesgo, el estudio analizó estadísticamente los pronombres y términos relacionados con la identidad y sus proporciones en el corpus previo al entrenamiento, como se muestra en la Tabla 9 a continuación:
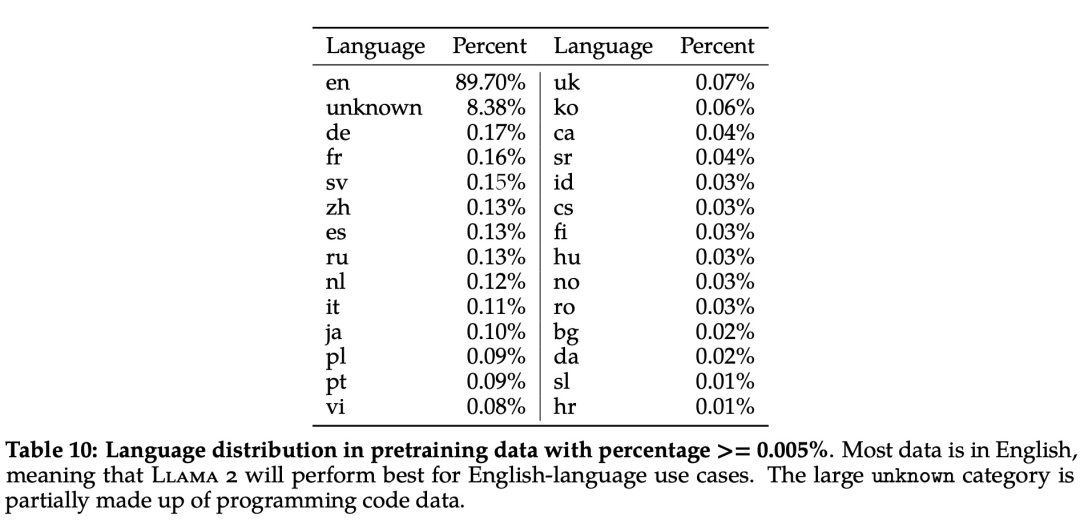
Además, en términos de distribución lingüística, las lenguas cubiertas por el corpus LLaMA 2 y sus proporciones se muestran en la Tabla 10 a continuación:
puesta a punto de seguridad
Específicamente, Meta utiliza las siguientes técnicas en el ajuste fino seguro: 1. Ajuste fino seguro supervisado, 2. RLHF seguro, 3. Destilación de contexto seguro.
Meta observó al principio del desarrollo de LLaMA 2-Chat que podía aprender de las demostraciones de seguridad durante el ajuste fino supervisado. El modelo aprendió rápidamente a escribir respuestas de seguridad detalladas, abordar problemas de seguridad, explicar por qué los temas pueden ser confidenciales y proporcionar información más útil. En particular, cuando los modelos generan respuestas de seguridad, tienden a escribirlas con más detalle que los anotadores normales. Entonces, después de recopilar solo unos pocos miles de demostraciones supervisadas, Meta cambió por completo a RLHF para enseñarle al modelo cómo escribir respuestas más matizadas. Otro beneficio de usar RLHF para la sintonización completa es que hace que el modelo sea más resistente a los intentos de fuga.

Primero, Meta lleva a cabo RLHF mediante la recopilación de datos sobre las preferencias humanas por la seguridad, donde los anotadores escriben avisos que creen que provocan un comportamiento inseguro, luego comparan múltiples respuestas modelo a los avisos y seleccionan la respuesta más segura según un conjunto de pautas. Luego, los datos de preferencia humana se utilizan para entrenar un modelo de recompensa seguro, y se reutiliza un indicador adversario en la etapa RLHF para tomar muestras del modelo.
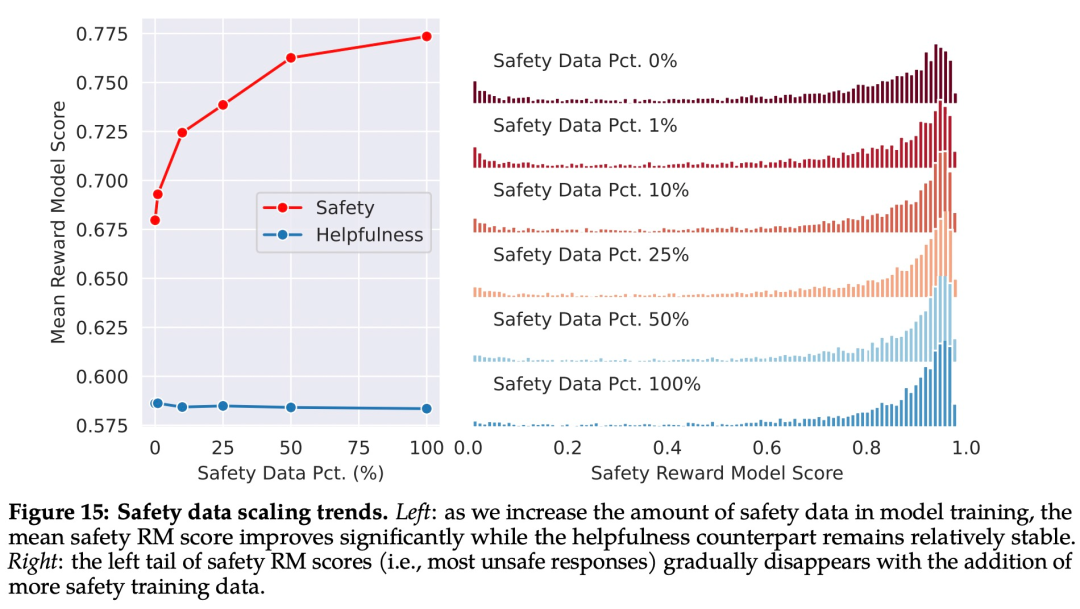
Como se muestra en la Figura 15 a continuación, Meta usa el puntaje promedio del modelo de recompensa como resultado del desempeño del modelo en términos de seguridad y utilidad. Meta observó que cuando aumentaron la proporción de datos seguros, el rendimiento del modelo que maneja indicaciones riesgosas y contradictorias mejoró significativamente.
Finalmente, Meta refina la tubería RLHF con destilación de contexto. Esto implica generar respuestas de modelo más seguras anteponiendo al indicador un indicador previo seguro, como "Eres un asistente seguro y responsable", y luego ajustar el modelo en función de la respuesta más segura sin el indicador previo, que esencialmente extrae el indicador previo seguro (contexto) en el modelo.
Meta utiliza un enfoque específico que permite que el modelo de recompensa de seguridad elija si usar la destilación contextual para cada muestra.

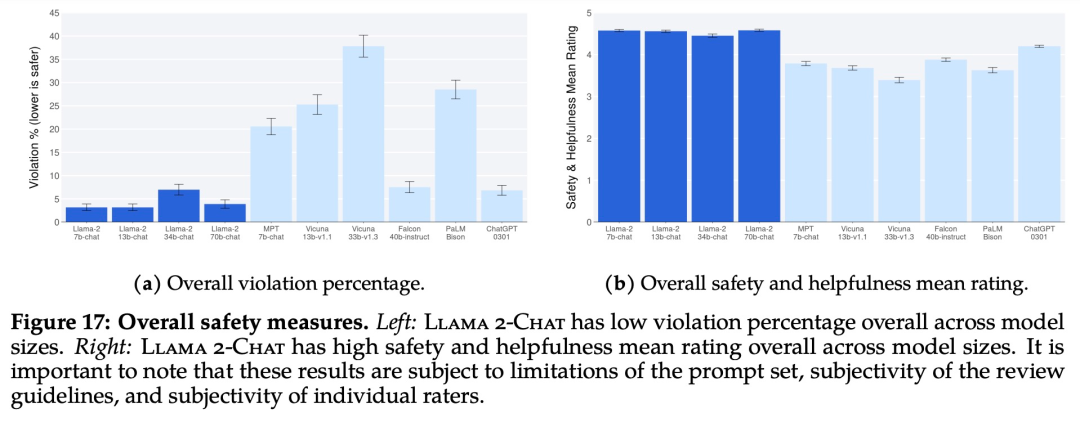
La Figura 17 a continuación muestra el porcentaje general de incumplimiento y la calificación de seguridad para varios LLM.
La Figura 18 a continuación muestra los porcentajes de infracción para conversaciones de uno o varios turnos. Una tendencia entre los modelos es que es más probable que múltiples rondas de diálogo provoquen respuestas inseguras. Dicho esto, LLaMA 2-Chat aún funciona bien en comparación con la línea de base, especialmente en conversaciones de varios turnos.

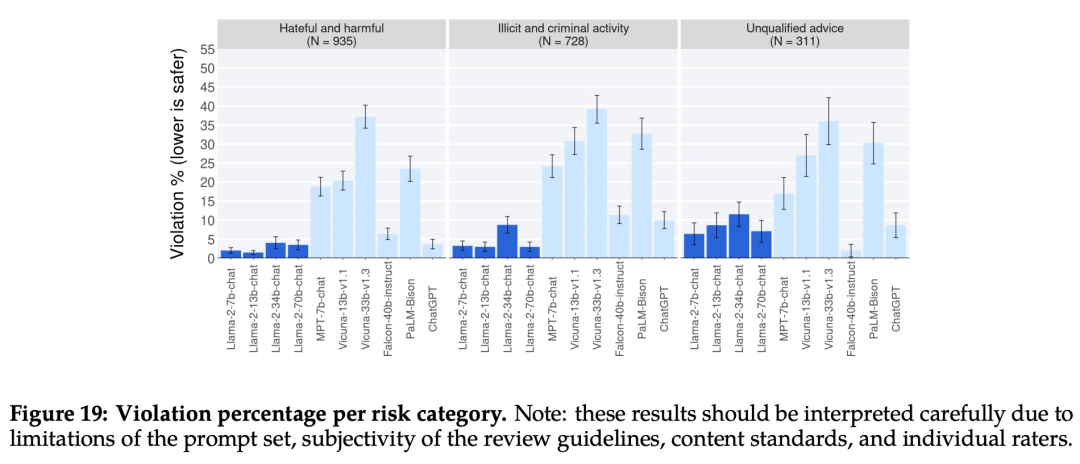
La Figura 19 a continuación muestra el porcentaje de brechas de seguridad en diferentes categorías para diferentes LLM.
referencias:
[1] https://ai.meta.com/llama/