El Departamento de Ingeniería Electrónica de la Universidad de Tsinghua y el equipo Volcanic Voice de ByteDance se han unido para lanzar un nuevo modelo de lenguaje grande de código abierto, SALMONN.
Según los informes, SALMONN admite entrada de voz, audio y música, puede percibir y comprender diferentes tipos de entrada de contenido de audio y tiene funciones como reconocimiento y traducción de voz multilingüe y razonamiento del habla.
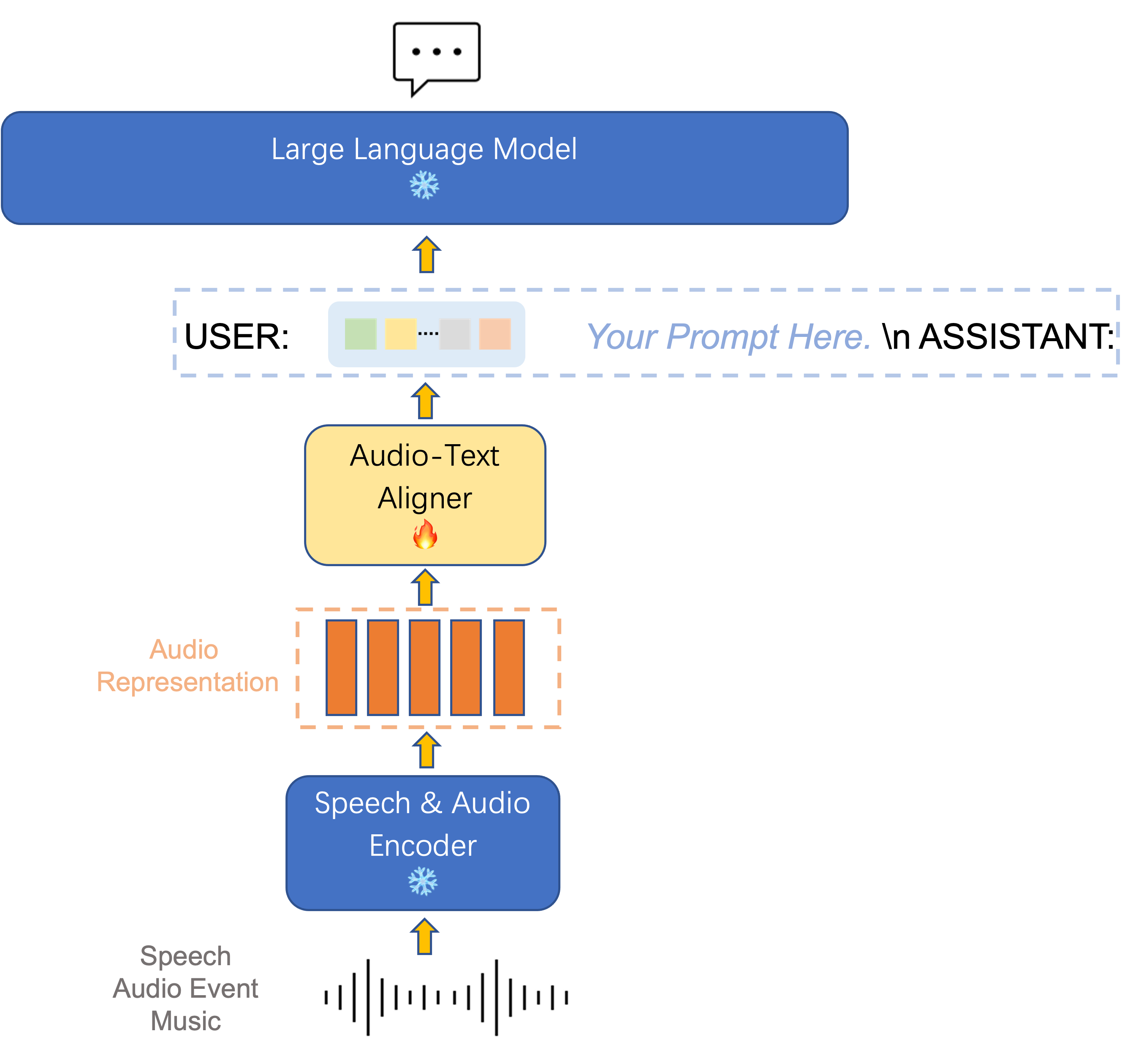
Se informa que SALMONN tiene mayor versatilidad que las tareas tradicionales de procesamiento de voz y audio, como el reconocimiento de voz y la generación de subtítulos de audio, y puede seguir con precisión las instrucciones del usuario.
- Repositorio de Github: https://github.com/bytedance/SALMONN/
- Enlace de demostración: https://bytedance.github.io/SALMONN/
En general, SALMONN actualmente es capaz de realizar reconocimiento de voz en inglés, traducción de voz de inglés a chino, reconocimiento de emociones, generación de subtítulos de audio, descripción de música y otras tareas importantes de voz y audio. Capacidades multilingües y multimodales, que cubren el reconocimiento de voz en idiomas distintos del inglés. , traducción de voz del inglés a otros idiomas (distintos del chino), resumen y extracción de palabras clave del contenido del habla, generación de historias basadas en audio, respuesta de preguntas en audio, tareas de razonamiento conjunto de voz y audio.