Las notas son notas de estudio compiladas por mí. Si hay algún error, indíquelo ~
Enlace a la columna de aprendizaje profundo:
http://t.csdnimg.cn/dscW7
pytorch - caja de herramientas de redes neuronales nn
Introducción
PyTorch Neural Network Toolbox nn es un módulo central para crear modelos de aprendizaje profundo. Proporciona un conjunto simple y flexible de API para definir, entrenar y evaluar fácilmente varios tipos de redes neuronales.
El módulo nn contiene muchos módulos y métodos predefinidos, como capas lineales, capas convolucionales, redes neuronales recurrentes, funciones de pérdida, etc. Estos módulos se pueden llamar directamente para construir modelos de aprendizaje profundo. Las siguientes son las funciones principales del módulo nn:
-
Definir modelos de redes neuronales: se pueden definir varios tipos de redes neuronales utilizando el módulo nn. Al heredar la clase nn.Module, puede crear su propia clase de red neuronal y definir la estructura y los parámetros de cada capa en ella.
-
Capas fáciles de usar: el módulo nn proporciona varios tipos de capas, como capas lineales, capas convolucionales, capas de agrupación, capas de normalización, etc. Estas capas han implementado los procesos de propagación hacia adelante y hacia atrás de forma predeterminada y se pueden usar directamente.
-
Función de activación no lineal: el módulo nn proporciona funciones de activación comunes, como ReLU, Sigmoid, Tanh, etc., que pueden agregar transformaciones no lineales entre capas.
-
Derivación automática: el módulo nn se basa en el mecanismo de derivación automática de PyTorch, que puede calcular automáticamente gradientes y realizar retropropagación. Esto permite a los usuarios centrarse más en el diseño y la implementación del modelo sin tener que calcular los gradientes manualmente.
-
Entrenamiento y optimización: puede usar el optimizador en el módulo nn (como SGD, Adam, etc.) para entrenar el modelo y usar funciones de pérdida predefinidas (como entropía cruzada, error cuadrático medio, etc.) para evaluar el rendimiento. del modelo.
-
Serialización y guardado: puede utilizar la API en el módulo nn para serializar el modelo en un archivo y restaurarlo cuando sea necesario.
PyTorch Neural Network Toolbox nn proporciona un conjunto de API simples y flexibles para definir, entrenar y evaluar fácilmente varios tipos de redes neuronales. También admite modelos y capas definidos por el usuario, lo que permite a los usuarios crear modelos de aprendizaje profundo más complejos según sus propias necesidades y escenarios de aplicación.
nn.Módulo
nn.Module es la clase base para todos los modelos de redes neuronales en PyTorch. Todos los modelos de redes neuronales definidos por el usuario deben heredar de la clasenn.Module e implementar sus métodos.
nn.ModuleProporciona algunos atributos y métodos importantes, lo que permite a los usuarios definir fácilmente la estructura y los parámetros de la red neuronal y realizar cálculos de propagación hacia adelante y hacia atrás.
Las siguientes son algunas propiedades y métodos importantes denn.Module clase:
-
__init__(self): Constructor, utilizado para inicializar la estructura y los parámetros del modelo. En este método, el usuario puede definir varias capas en el modelo y especificar sus parámetros. -
forward(self, input): Método de propagación hacia adelante. En este método, el usuario define el proceso de propagación hacia adelante del modelo. Al llamar al método de propagación hacia adelante de cada capa y combinar y transformar sus salidas, finalmente se genera la salida del modelo. -
parameters(self): Devuelve todos los parámetros que se pueden aprender en el modelo. Este método devuelve un iterador que se puede utilizar para iterar sobre todos los parámetros del modelo y optimizarlos y actualizarlos. -
to(self, device): Mueva el modelo al dispositivo especificado, como CPU o GPU. Mediante este método, el modelo se puede cargar fácilmente en un dispositivo adecuado para su cálculo. -
state_dict(self)yload_state_dict(self, state_dict): estos dos métodos se utilizan para serializar y cargar el estado del modelo. El métodostate_dict()devuelve un diccionario que contiene todos los estados del modelo, que se puede guardar en un archivo. El métodoload_state_dict()carga el estado del modelo desde el diccionario dado. -
train()yeval(): estos dos métodos se utilizan para configurar el modo de entrenamiento y el modo de evaluación del modelo. En el modo de entrenamiento, el modelo conserva algunas operaciones específicas, como la eliminación de capas, y en el modo de evaluación estas operaciones están desactivadas.
Al heredarnn.Module la clase y anular sus métodos, los usuarios pueden definir fácilmente su propio modelo de red neuronal. Al mismo tiempo, nn.Module también proporciona algunos métodos y funciones prácticos, como gestión de parámetros, movimiento del dispositivo y guardado de estado, etc., lo que hace que la capacitación y la implementación del modelo sean más fáciles y eficientes.
nn.Module implementa la capa completamente conectada
Utilice nn.Module para implementar la capa completamente conectada. Capa completamente conectada, también conocida como capa afín, salida y \textbf{y} yImportación japonesa x \textbf{x} xpie completo y=Wx+b \textbf{y=Wx+b} y=Wx+b, W \textbf{W} Wsuma b \textbf{b} b es un parámetro que se puede aprender.
import torch as t
from torch import nn
class Linear(nn.Module): # 继承nn.Module
def __init__(self, in_features, out_features):
super(Linear, self).__init__() # 等价于nn.Module.__init__(self)
self.w = nn.Parameter(t.randn(in_features, out_features))
self.b = nn.Parameter(t.randn(out_features))
def forward(self, x):
x = x.mm(self.w) # x.@(self.w)
return x + self.b.expand_as(x)
layer = Linear(4,3)
input = t.randn(2,4)
output = layer(input)
print(output)
for name, parameter in layer.named_parameters():
print(name, parameter) # w and b
Explicación del código:
Este código define una capa lineal personalizadaLinear, que hereda denn.Module clase y se anula. los métodos __init__ y forward que contiene. La dimensión de entrada de esta capa es in_features y la dimensión de salida es out_features.
class Linear(nn.Module):
def __init__(self, in_features, out_features):
super(Linear, self).__init__()
self.w = nn.Parameter(t.randn(in_features, out_features))
self.b = nn.Parameter(t.randn(out_features))
def forward(self, x):
x = x.mm(self.w)
return x + self.b.expand_as(x)
En el método__init__, primero se llama al constructor de la clase principal para inicializar el modelo y luego se definen dos parámetros: self.w y < /span>< a i=3>, que corresponden a la matriz de peso y al vector de sesgo de esta capa respectivamente, y los marcan como parámetros que se pueden aprender. self.b
En el métodoforward, el tensor de entradax se multiplica primero por la matriz de pesoself.w y luego por Bias. vectorself.b, y finalmente obtener la salida de esta capa.
A continuación, el código crea un Linear objetolayer y pasa las dimensiones de la entrada 4 y la salida. Dimensiones3. Luego se define un tensor de entrada aleatorio input con forma (2, 4).
layer = Linear(4,3)
input = t.randn(2,4)
Finalmente, pase el tensor de entrada al método del layer objeto para obtener el tensor de salida . forwardoutput
output = layer(input)
Puede ver los resultados del cálculo del modelo para una entrada determinada imprimiendo el valor del tensor a través de la instrucción print(output). output
print(output)
Además, el código utiliza el método named_parameters para iterar sobre todos los parámetros en el objeto layer e imprime sus nombres y valores. Se pueden obtener dos parámetros, w y b.
for name, parameter in layer.named_parameters():
print(name, parameter)
nn.Module implementa un perceptrón multicapa

import torch as t
from torch import nn
class Linear(nn.Module): # 继承nn.Module
def __init__(self, in_features, out_features):
super(Linear, self).__init__() # 等价于nn.Module.__init__(self)
self.w = nn.Parameter(t.randn(in_features, out_features))
self.b = nn.Parameter(t.randn(out_features))
def forward(self, x):
x = x.mm(self.w) # x.@(self.w)
return x + self.b.expand_as(x)
class Perceptron(nn.Module):
def __init__(self, in_features, hidden_features, out_features):
nn.Module.__init__(self)
self.layer1 = Linear(in_features, hidden_features) # 此处的Linear是自定义的全连接层
self.layer2 = Linear(hidden_features, out_features)
def forward(self,x):
x = self.layer1(x)
x = t.sigmoid(x)
return self.layer2(x)
perceptron = Perceptron(3,4,1)
for name, param in perceptron.named_parameters():
print(name, param.size())
Explicación del código:
Primero, se define una clase llamada Linear, que hereda de nn.Module. Esta clase representa una capa lineal que contiene parámetros de pesow y parámetros de sesgob.
class Linear(nn.Module):
def __init__(self, in_features, out_features):
super(Linear, self).__init__()
self.w = nn.Parameter(t.randn(in_features, out_features))
self.b = nn.Parameter(t.randn(out_features))
def forward(self, x):
x = x.mm(self.w)
return x + self.b.expand_as(x)
Luego, se define una clase llamada Perceptron, que también hereda de nn.Module. Esta clase representa un modelo de perceptrón multicapa, que consta de dos capas lineales.
class Perceptron(nn.Module):
def __init__(self, in_features, hidden_features, out_features):
nn.Module.__init__(self)
self.layer1 = Linear(in_features, hidden_features)
self.layer2 = Linear(hidden_features, out_features)
def forward(self, x):
x = self.layer1(x)
x = t.sigmoid(x)
return self.layer2(x)
En el método de inicialización, se crean dos Linear objetos self.layer1 y self.layer2 como las dos capas del perceptrón. En el método de propagación directa, los datos de entrada se calculan primero mediante self.layer1, luego pasan por la función de activación sigmoidea y finalmente la salida se obtiene mediante self.layer2.
Finalmente, se crea un Perceptronobjetoperceptron y se imprimen los nombres y tamaños de los parámetros.
perceptron = Perceptron(3, 4, 1)
for name, param in perceptron.named_parameters():
print(name, param.size())
Este código muestra cómo construir un modelo de perceptrón multicapa utilizando capas lineales personalizadas e imprimir la información de los parámetros. A través de este ejemplo, podemos comprender cómo usar PyTorch para construir un modelo de red neuronal, depurarlo y optimizarlo.
Convención de nomenclatura para parámetros en el módulo:
- Para algo como
self.param_name = nn.Parameter(t.randn(3, 4)), asígnale un nombreparam_name - Para el parámetro en el submódulo, el nombre del módulo actual se agregará antes de su nombre. Por ejemplo, para
self.sub_module = SubModel(), hay un parámetro llamado param_name en SubModel, luego el nombre del parámetro formado al unir los dos essub_module.param_name.
Capas de redes neuronales de uso común
En las redes neuronales, existen muchas capas de uso común que se utilizan para construir varios tipos diferentes de modelos. A continuación se muestran algunas capas de redes neuronales comunes y sus usos:
-
Capa completamente conectada: la capa completamente conectada es una de las capas más básicas, también llamada capa lineal o capa densa. Multiplica cada elemento de la entrada con un peso y obtiene el resultado agregando un término de sesgo. Las capas completamente conectadas se utilizan a menudo para extraer características y realizar clasificación.
-
Capa convolucional: la capa convolucional es una capa especialmente utilizada para procesar imágenes y datos espaciales. Utiliza operaciones de convolución para filtrar datos de entrada y extraer características espaciales locales. Las capas convolucionales se utilizan comúnmente para tareas como el reconocimiento de imágenes, la detección de objetos y el procesamiento del habla.
-
Capa de agrupación: la capa de agrupación se utiliza principalmente para reducir el tamaño espacial del mapa de características y conservar las características más importantes. Las operaciones de agrupación comunes incluyen la agrupación máxima y la agrupación promedio, que seleccionan el valor máximo o promedio en cada región como salida respectivamente.
-
Capa recurrente: la capa recursiva se utiliza para procesar datos de secuencia, como el procesamiento del lenguaje natural y el pronóstico de series de tiempo. Tienen mecanismos de memoria que transfieren información en cada paso de tiempo. Las capas recurrentes comunes incluyen redes neuronales recurrentes (RNN) y redes de memoria a corto plazo (LSTM).
-
Capa de incrustación: la capa de incrustación se utiliza para codificar datos simbólicos o categóricos discretos en una representación vectorial continua de baja dimensión. Se utiliza ampliamente en el procesamiento del lenguaje natural para asignar palabras o caracteres en un espacio vectorial continuo.
-
Capa de normalización: la capa de normalización se utiliza para estandarizar los datos de entrada en la red neuronal para mejorar la estabilidad y la velocidad de convergencia del modelo. Las operaciones de normalización comunes incluyen la normalización por lotes y la normalización de capas.
-
Capa de función de activación: la capa de función de activación aplica una transformación no lineal a la salida de la red neuronal para introducir capacidades no lineales. Las funciones de activación comunes incluyen ReLU (Unidad lineal rectificada), Sigmoide y Tanh, etc.
Esta es solo una pequeña cantidad de capas de redes neuronales de uso común. Hay muchos otros tipos de capas en aplicaciones prácticas, como capas de atención, conexiones residuales, etc. Dependiendo de la tarea y el problema, elegir la combinación correcta de capas puede construir de manera efectiva un modelo de red neuronal poderoso.
Capa relacionada con la imagen
Las capas relacionadas con imágenes incluyen principalmente capas de convolución (Conv), capas de agrupación (Pool), etc. En el uso real, estas capas se pueden dividir en unidimensionales (1D), bidimensionales (2D) y tridimensionales (3D). ) El método de agrupación también se divide en agrupación promedio (AvgPool), agrupación máxima (MaxPool), agrupación adaptativa (AdaptiveAvgPool), etc. Además de la convolución directa comúnmente utilizada, la capa convolucional también tiene convolución inversa (TransposeConv).
La capa de convolución (Conv) implementa un filtro de nitidez
# 导入所需的库
from PIL import Image
from torchvision.transforms import ToTensor, ToPILImage
import torch as t
import torch.nn as nn
# 创建将图像转换为张量的转换器
to_tensor = ToTensor()
# 创建将张量转换为图像的转换器
to_pil = ToPILImage()
# 打开图像文件
lena = Image.open('C:/图片路径/1.png')
# 将彩色图像转换为灰度图像,并将其通道数从3变为1。并将图像转换为张量,并添加一维作为batch_size
input = to_tensor(lena.convert('L')).unsqueeze(0)
# 定义锐化卷积核
kernel = t.ones(3, 3)/-9.
kernel[1][1] = 1
conv = nn.Conv2d(1, 1, (3, 3), 1, bias=False)
conv.weight.data = kernel.view(1, 1, 3, 3)
# 对输入进行卷积操作
out = conv(input)
# 将输出张量转换为图像,并显示出来
to_pil(out.data.squeeze(0))


La función de este código es implementar un filtro de nitidez para enfocar la imagen de entrada. Los pasos específicos son los siguientes:
-
Cree un convertidor que convierta una imagen en un tensor
to_tensor = ToTensor()y un convertidor que convierta un tensor en una imagento_pil = ToPILImage(). -
Abrir archivo de imagen
lena = Image.open('图片路径'). -
input = to_tensor(lena.convert('L')).unsqueeze(0), convierte la imagen en color a escala de grises y cambia su número de canales de 3 a 1. Y convierta la imagen a tensor y agregue una dimensión como tamaño_lote, es decir, conviértala a entrada del modelo con tamaño de entrada(1, channels, height, width). -
kernel = t.ones(3, 3)/-9.; kernel[1][1] = 1
Defina el núcleo de convolución de nitidez: este núcleo de convolución es una matriz de 3x3, el punto central es 1 y otras posiciones son -1/9, es decir, el desplazamiento es -1/9. -
conv = nn.Conv2d(1, 1, (3, 3), 1, bias=False), cree una capa convolucional conv. El número de canales de entrada de la capa convolucional es 1, el número de canales de salida es 1, el tamaño del núcleo de convolución es (3, 3), el tamaño del paso es 1 y el sesgo es Falso. -
conv.weight.data = kernel.view(1, 1, 3, 3), convierta el núcleo de convolución creado previamente en un tensor de la misma forma y asígnelo al peso de la capa convolucional. -
out = conv(input): realice una operación de convolución en la entrada, utilice el núcleo de convolución creado para realizar una operación de convolución en la entrada y obtenga un tensor con un tamaño de salida de(1, 1, height, width). -
to_pil(out.data.squeeze(0)), convierte el tensor de salida en una imagen y muéstralo. Dado que se agrega un tamaño de lote unidimensional durante la entrada, esta dimensión debe eliminarse primero mediantesqueeze().
Funciones de activación comunes
| función | imagen |
|---|---|
| sigmoideo | 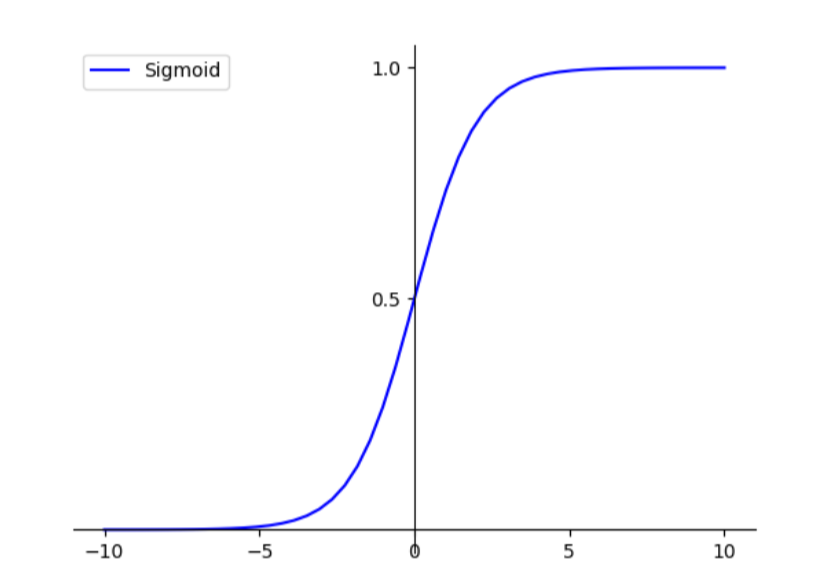 |
| sospechoso | 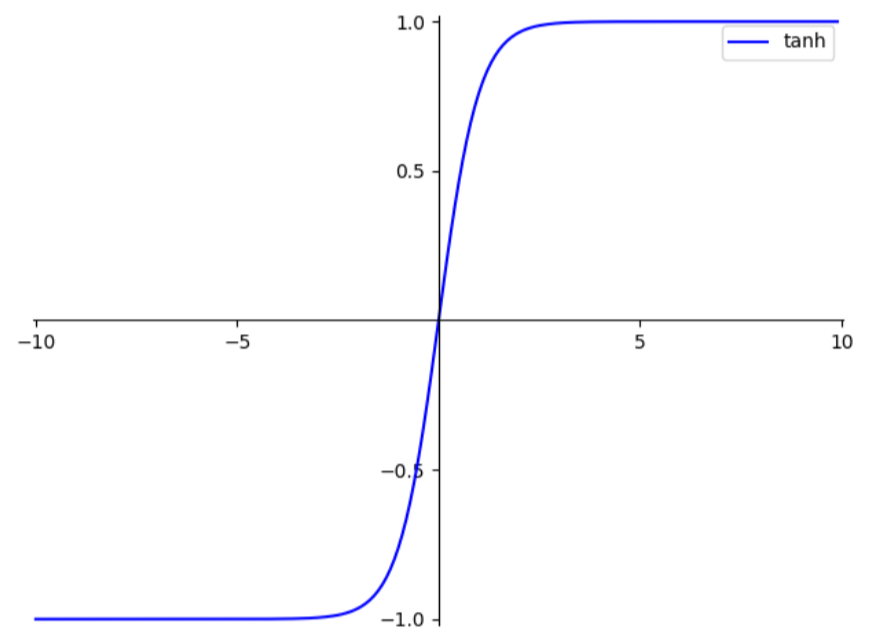 |
| reanudar |  |
| Fugas de ReLU |  |
A continuación se muestra un ejemplo de PyTorch implementando una función de activación común:
import torch
import torch.nn as nn
# 定义输入张量x
x = torch.randn(1, 10)
# Sigmoid激活函数
sigmoid = nn.Sigmoid()
activated_x = sigmoid(x)
print("Sigmoid激活后的输出:", activated_x)
# Tanh(双曲正切)激活函数
tanh = nn.Tanh()
activated_x = tanh(x)
print("Tanh激活后的输出:", activated_x)
# ReLU激活函数
relu = nn.ReLU()
activated_x = relu(x)
print("ReLU激活后的输出:", activated_x)
# LeakyReLU激活函数
leaky_relu = nn.LeakyReLU(negative_slope=0.01)
activated_x = leaky_relu(x)
print("LeakyReLU激活后的输出:", activated_x)
# Softmax激活函数
softmax = nn.Softmax(dim=1)
activated_x = softmax(x)
print("Softmax激活后的输出:", activated_x)
En este ejemplo, primero definimos un tensor de entrada de tamaño y luego usamos las funciones de activación ReLU, Sigmoid, Tanh, LeakyReLU y Softmax. procesarlo y generar los resultados procesados. (1, 10)x
Tenga en cuenta que cada función de activación se implementa creando un modelo PyTorch correspondiente. Por ejemplo, la función de activación de ReLU se implementa creando una instancia de nn.ReLU. Al usarlo, solo necesitamos pasar el tensor de entrada al modelo.
El resultado es el siguiente:
Sigmoid激活后的输出: tensor([[0.6914, 0.3946, 0.2316, 0.3845, 0.6496, 0.7061, 0.3284, 0.4206, 0.8200, 0.6755]])
Tanh激活后的输出: tensor([[ 0.6678, -0.4035, -0.8334, -0.4386, 0.5492, 0.7046, -0.6141, -0.3099, 0.9080, 0.6250]])
ReLU激活后的输出: tensor([[0.8068, 0.0000, 0.0000, 0.0000, 0.6172, 0.8765, 0.0000, 0.0000, 1.5163, 0.7332]])
LeakyReLU激活后的输出: tensor([[ 0.8068, -0.0043, -0.0120, -0.0047, 0.6172, 0.8765, -0.0072, -0.0032, 1.5163, 0.7332]])
Softmax激活后的输出: tensor([[0.1407, 0.0409, 0.0189, 0.0392, 0.1164, 0.1508, 0.0307, 0.0456, 0.2860, 0.1307]])
La función ReLU tiene un parámetro in situ. Si se establece en True, sobrescribirá la salida directamente en la entrada, lo que puede ahorrar memoria/memoria de video. La razón por la que se puede cubrir es que al calcular la retropropagación de ReLU, el gradiente de la retropropagación solo se puede calcular en función de la salida. Sin embargo, solo unas pocas operaciones de autograduación admiten operaciones in situ (como tensor.sigmoid_()). A menos que sepa claramente lo que está haciendo, generalmente no utilice operaciones in situ.
# ReLU激活函数
relu = nn.ReLU(inplace=True)
activated_x = relu(x)
print("ReLU激活后的输出:", activated_x)
Lista de módulos y secuencial
ModuleList y Sequential son dos clases importantes que se utilizan para crear modelos de redes neuronales en PyTorch.
ModuleList es una clase contenedora que puede contener múltiples submódulos (como capas, funciones de activación, etc.) y procesarlos como un todo. Al utilizar ModuleList, se pueden administrar y organizar fácilmente múltiples submódulos.
Aquí hay un ejemplo de usoModuleList para construir un modelo:
import torch
import torch.nn as nn
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.layers = nn.ModuleList([
nn.Linear(10, 20),
nn.ReLU(),
nn.Linear(20, 30),
nn.Tanh()
])
def forward(self, x):
for layer in self.layers:
x = layer(x)
return x
En este ejemplo, la claseMyModel define un modelo que contiene cuatro submódulos. En el constructor del modelo, se crea un objeto ModuleList y se le agregan cuatro submódulos. En el método forward del modelo, la salida final se obtiene atravesando los submódulos en ModuleList y pasándoles la entrada capa por capa.
En comparación con el uso directo de listas o tuplas para almacenar submódulos, una ventaja de usar ModuleList es que registrará automáticamente el submódulo para que se puedan modelar los parámetros del submódulo. Otras partes son identificados y actualizados.
Sequential es otra clase para construir modelos que proporciona una forma más concisa de definir una secuencia continua de capas. UsandoSequential, se pueden conectar múltiples capas (como capas lineales, funciones de activación, etc.) en serie para formar un modelo de red neuronal completo.
Aquí hay un ejemplo de usoSequential para construir un modelo:
import torch
import torch.nn as nn
model = nn.Sequential(
nn.Linear(10, 20),
nn.ReLU(),
nn.Linear(20, 30),
nn.Tanh()
)
En este ejemplo, la clase Sequential se usa directamente para construir el modelo, pasando cada capa como parámetro al constructor Sequential. De esta forma, cada capa se agregará al modelo en orden.
Una ventaja de usarSequential es que proporciona una forma más concisa e intuitiva de definir la estructura del modelo. Sin embargo, dado queSequential solo es aplicable a modelos de conexión secuencial, no puede manejar de manera flexible algunas estructuras de red complejas, como conexiones de salto o conexiones multidireccionales.
ModuleListTanto como Sequential son herramientas importantes para crear modelos de redes neuronales. ModuleList es adecuado para gestionar y organizar múltiples submódulos, mientras que Sequential es adecuado para definir de forma concisa modelos conectados secuencialmente. La elección de qué clase utilizar depende de sus necesidades específicas y de la estructura del modelo.
Capa de red neuronal recurrente (RNN)
La capa de red neuronal recurrente (RNN) es una capa de red neuronal que se utiliza para procesar datos de secuencia. A diferencia de las redes neuronales tradicionales, RNN toma cada elemento de una secuencia como entrada y transfiere información a través de estados de memoria, logrando así una transferencia continua de información en la secuencia.
En RNN, la salida en el momento actual depende no solo de la entrada en el momento actual, sino también del estado de la entrada y la memoria de todos los momentos anteriores. Específicamente, el cálculo de RNN se puede expresar como:
h t = f ( W ∗ x t + U ∗ h t − 1 ) h_t = f(W * x_t + U * h_{t-1})ht=f(W∗Xt+EN∗ht−1)
Entre ellos, h_t representa el estado de la memoria en el momento actual, x_t representa la entrada en el momento actual y W y U son matrices de peso.
La estructura básica de RNN es la siguiente:

La ventaja de RNN es que puede procesar datos de secuencia de cualquier longitud, tiene una gran capacidad de memoria y puede aprender dependencias a largo plazo. en la secuencia relación. Sin embargo, debido a que RNN necesita reutilizar la misma matriz de peso muchas veces durante el proceso de cálculo, provoca el problema de la desaparición o explosión del gradiente, lo que afecta su efecto de entrenamiento. Para resolver este problema, posteriormente aparecieron algunas estructuras RNN mejoradas, como LSTM y GRU.
A continuación se muestra un ejemplo de implementación de un modelo RNN simple usando PyTorch:
import torch
import torch.nn as nn
class MyRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(MyRNN, self).__init__()
self.hidden_size = hidden_size
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
h0 = torch.zeros(1, x.size(0), self.hidden_size) # 初始化记忆状态
out, hn = self.rnn(x, h0)
out = self.fc(out[:, -1, :]) # 取最后一个时刻的输出作为模型输出
return out
En este ejemplo, creamos una clase de modelo RNN llamada MyRNN y usamos la clase nn.RNN para definir la capa RNN. En el método directo del modelo, primero inicializamos el estado de la memoria a través de la función torch.zeros y pasamos el tensor de entrada y el estado de la memoria a la capa RNN para su cálculo. Luego obtenemos el resultado final del modelo tomando el resultado en el último momento y usando una capa completamente conectada para mapearlo en el espacio de salida.
optimizador
En PyTorch, puede utilizar el módulotorch.optim para implementar el uso básico del optimizador, establecer diferentes tasas de aprendizaje para diferentes partes del modelo y ajustar la tasa de aprendizaje. A continuación presentamos estos contenidos respectivamente.
- Uso básico del optimizador.
Primero, debe crear un objeto optimizador para optimizar los parámetros del modelo. Suponiendo que hemos definido un objeto modelomodel, podemos crear un objeto optimizador de la siguiente manera:
import torch.optim as optim
optimizer = optim.Adam(model.parameters(), lr=0.01)
En este ejemplo, utilizamos el algoritmo de optimización de Adam para actualizar los parámetros del modelo. Pasamos todos los parámetros entrenables (es decir, pesos y sesgos) del objeto modelomodel al constructor del optimizador y establecemos la tasa de aprendizaje inicial0.01.
A continuación, durante el ciclo de entrenamiento, las actualizaciones de parámetros se pueden realizar de la siguiente manera:
optimizer.zero_grad() # 清零梯度
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新参数
En este ejemplo, primero llamamos a la función zero_grad() para borrar los gradientes de todos los parámetros y luego llamamos a la función backward() para calcular el gradiente de la función de pérdida con respecto a los parámetros del modelo. , y finalmente llamar a la funciónstep() para actualizar los parámetros.
- Establecer diferentes tasas de aprendizaje para diferentes partes del modelo.
Establezca diferentes tasas de aprendizaje para diferentes partes del modelo para ajustar mejor los parámetros del modelo. En PyTorch, esto se puede lograr mediante:
optimizer = optim.Adam([
{
'params': model.conv1.parameters()},
{
'params': model.conv2.parameters(), 'lr': 0.01},
{
'params': model.fc.parameters(), 'lr': 0.001}
], lr=0.0001)
En este ejemplo, las tres partes del modelo (conv1, conv2 y fc) se colocan en diferentes diccionarios y se establecen diferentes tasas de aprendizaje para cada diccionario. Finalmente, pasamos todos los diccionarios al constructor del optimizador y establecemos la tasa de aprendizaje inicial0.0001.
- Ajustar la tasa de aprendizaje
A veces, es necesario ajustar la tasa de aprendizaje durante el entrenamiento para optimizar mejor los parámetros del modelo. En PyTorch, la tasa de aprendizaje se puede ajustar de la siguiente manera:
# 减小学习率到原来的1/10
for param_group in optimizer.param_groups:
param_group['lr'] /= 10.0
En este ejemplo, primero iteramos a través de todos los grupos de parámetros y luego dividimos la tasa de aprendizaje de cada grupo de parámetros por 10,0, reduciendo así la tasa de aprendizaje a 1/10 del original. Tenga en cuenta que optimizer.param_groups es una lista, donde cada elemento es un diccionario que contiene toda la información relacionada con el grupo de parámetros, como la tasa de aprendizaje, el coeficiente de disminución de peso, etc.
nn.funcional VS nn.Módulo
nn.function y nn.Module son módulos muy importantes en la biblioteca de aprendizaje profundo de PyTorch. Ambos ayudan a definir modelos de redes neuronales, pero se utilizan de formas ligeramente diferentes y para diferentes propósitos.
- nn.funcional
nn.function es un módulo en PyTorch que contiene varias funciones no lineales, funciones de agrupación, funciones de convolución, etc. Estas funciones se implementan como funciones puras, es decir, su salida depende sólo de la entrada y no depende de ningún estado externo. Por lo tanto, a menudo se utilizan para crear capas simples sin parámetros ni funciones de pérdida personalizadas complejas.
A continuación se muestra una capa simple completamente conectada implementada usando nn.funcional:
import torch.nn as nn
import torch.nn.functional as F
class MyNet(nn.Module):
def __init__(self):
super(MyNet, self).__init__()
self.fc1 = nn.Linear(784, 256)
self.fc2 = nn.Linear(256, 10)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
En este ejemplo, nn.Linear se usa para crear dos capas completamente conectadas y luego la función F.relu se usa como función de activación en el método directo.
- nn.Módulo
nn.Module es una clase base en PyTorch y todos los modelos de redes neuronales deberían heredarla. nn.Module proporciona algunos métodos útiles, como parameters(), named_parameters() y modules(), etc., que pueden acceder cómodamente a los parámetros. en el modelo y submódulos. Después de heredar la clase nn.Module, necesitamos implementar los métodos __init__ y forward para definir la estructura del modelo y el proceso de propagación hacia adelante.
A continuación se muestra una capa simple completamente conectada implementada usando nn.Module:
import torch.nn as nn
class MyNet(nn.Module):
def __init__(self):
super(MyNet, self).__init__()
self.fc1 = nn.Linear(784, 256)
self.fc2 = nn.Linear(256, 10)
def forward(self, x):
x = nn.functional.relu(self.fc1(x))
x = self.fc2(x)
return x
En este ejemplo, nn.Linear se utiliza para crear dos capas completamente conectadas y se definen como atributos del modelo en el método __init__. Luego, la función nn.functional.relu se utiliza como función de activación en el método de avance.
En general, nn.Module se usa para construir modelos de redes neuronales más complejos con parámetros, mientras que nn.functional se usa para construir capas simples sin parámetros ni funciones de pérdida personalizadas. Al construir redes neuronales, a menudo se prefiere el módulo nn.Module porque proporciona más flexibilidad y escalabilidad.
nn.init implementa la inicialización de parámetros
nn.init es un módulo de la biblioteca de aprendizaje profundo de PyTorch que se utiliza para inicializar los pesos de las redes neuronales. Al entrenar una red neuronal, generalmente es necesario inicializar los pesos para mejorar la velocidad de convergencia y la capacidad de generalización del modelo.
nn.init proporciona una variedad de métodos de inicialización, incluida la inicialización de distribución normal común, la inicialización de distribución uniforme y la inicialización de Xavier. A continuación se utiliza la inicialización de Xavier como ejemplo para explicar.
- Inicialización de Xavier
La inicialización de Xavier es un método de inicialización de peso comúnmente utilizado que tiene como objetivo ecualizar las variaciones de las señales de entrada y salida. Esto puede ayudar a acelerar la convergencia del modelo y mejorar el rendimiento del modelo. La fórmula específica para la inicialización de Xavier es la siguiente:
W ∼ U [ − 6 norte yo norte + norte o u t , 6 norte yo norte + norte o u t ] W \sim U[-\frac{\sqrt{6}}{\sqrt{n_{in}+n_{out}}}, \frac{\ sqrt{6}}{\sqrt{n_{entrada}+n_{salida}}}]EN∼U[-norteen+norteout6,norteen+norteout6]
En eso, U [ a , b ] U[a, b] U[a,b]Área de visualización [ a , b ] [a, b] [a,Muestreo aleatorio de la distribución uniforme de b], n i n n_{in} norteen和 n o u t n_{out} norteoutrepresentan las dimensiones de entrada y salida de los pesos respectivamente.
- Inicialización de Xavier usando nn.init
Usar nn.init para inicializar Xavier es muy simple: solo necesita pasar los parámetros que deben inicializarse a la función de inicialización correspondiente. Por ejemplo, el siguiente código demuestra cómo utilizar nn.init para la inicialización de Xavier:
import torch.nn as nn
import torch.nn.init as init
class MyNet(nn.Module):
def __init__(self):
super(MyNet, self).__init__()
self.fc1 = nn.Linear(784, 256)
self.fc2 = nn.Linear(256, 10)
# 对权重进行Xavier初始化
init.xavier_uniform_(self.fc1.weight)
init.xavier_uniform_(self.fc2.weight)
def forward(self, x):
x = nn.functional.relu(self.fc1(x))
x = self.fc2(x)
return x
En este ejemplo, se crean dos capas completamente conectadas usando nn.Linear y se definen como atributos del modelo en el método __init__. Luego use la función init.xavier_uniform_ para realizar la inicialización de Xavier de los pesos.
En general, usar nn.init para la inicialización del peso puede ayudar a que el modelo converja más rápido y mejorar el rendimiento del modelo. Sin embargo, cabe señalar que la inicialización del peso no es omnipotente y, a veces, es necesario ajustar hiperparámetros como la tasa de aprendizaje y la regularización para optimizar el modelo.
nn.Análisis en profundidad del módulo
Constructor de la clase base nn.Module
def __init__(self):
self._parameters = OrderedDict()
self._modules = OrderedDict()
self._buffers = OrderedDict()
self._backward_hooks = OrderedDict()
self._forward_hooks = OrderedDict()
self.training = True
Constructor de la clase base nn.Module__init__ es uno de los componentes básicos de todos los modelos de redes neuronales de PyTorch. Su función principal es inicializar varios atributos del modelo y crear un diccionario ordenado vacío para almacenar los parámetros, submódulos, cachés, enlaces de propagación hacia adelante/hacia atrás, etc.
A continuación se explica cada atributo definido en__init__ función:
-
self._parameters: un diccionario ordenado que se utiliza para almacenar los parámetros que se pueden aprender del modelo (como pesos y sesgos). Las variables de tipo
nn.Parameterdefinidas en el modelo se agregan automáticamente al diccionario. -
self._modules: un diccionario ordenado utilizado para almacenar submódulos del modelo. Las variables de tipo
nn.Moduledefinidas en el modelo se agregan automáticamente al diccionario. -
self._buffers: un diccionario ordenado que se utiliza para almacenar el caché del modelo. Por ejemplo, aquí se pueden guardar algunos resultados intermedios, promedios móviles, etc.
-
self._backward_hooks: un diccionario ordenado que se utiliza para almacenar los ganchos de retropropagación del modelo, es decir, las funciones ejecutadas durante el proceso de retropropagación.
-
self._forward_hooks: un diccionario ordenado que se utiliza para almacenar los ganchos de propagación hacia adelante del modelo, es decir, las funciones ejecutadas durante el proceso de propagación hacia adelante.
-
self.training: Variable booleana utilizada para indicar el estado de entrenamiento del modelo. Durante el entrenamiento, esta variable es Verdadera y durante la prueba, esta variable es Falsa.
En general,nn.ModuleEl constructor de la clase base inicializa cada atributo en el modelo de red neuronal y crea un diccionario ordenado para almacenar los parámetros, submódulos, almacenamiento en caché, enlaces de propagación hacia adelante/hacia atrás, etc. Estas propiedades y diccionarios ordenados proporcionan un mecanismo conveniente para acceder y administrar los componentes del modelo y permiten una fácil serialización y deserialización.
Código de muestra:
import torch.nn as nn
class MyNet(nn.Module):
def __init__(self):
super(MyNet, self).__init__()
self.fc1 = nn.Linear(784, 256)
self.fc2 = nn.Linear(256, 10)
def forward(self, x):
x = nn.functional.relu(self.fc1(x))
x = self.fc2(x)
return x
# 创建模型实例
model = MyNet()
# 打印 Module 属性
print("Parameters:")
for name, param in model.named_parameters():
print(name, param.size())
print("\nModules:")
for name, module in model.named_modules():
print(name, module)
print("\nBuffers:")
for name, buffer in model.named_buffers():
print(name, buffer.size())
print("\nForward hooks:")
for hook in model._forward_hooks.values():
print(hook)
print("\nBackward hooks:")
for hook in model._backward_hooks.values():
print(hook)
En este ejemplo, creamos un modelo de red neuronal que hereda de la clase base nn.Module y define dos capas completamente conectadas en ella. Luego, imprimimos la Parameter, Module, Buffer y la dirección de avance del modelo accediendo a las propiedades del objeto de instancia y el diccionario ordenado. / Gancho de propagación hacia atrás y otras propiedades. El resultado es el siguiente:
Parameters:
fc1.weight torch.Size([256, 784])
fc1.bias torch.Size([256])
fc2.weight torch.Size([10, 256])
fc2.bias torch.Size([10])
Modules:
MyNet(
(fc1): Linear(in_features=784, out_features=256, bias=True)
(fc2): Linear(in_features=256, out_features=10, bias=True)
)
fc1 Linear(in_features=784, out_features=256, bias=True)
fc2 Linear(in_features=256, out_features=10, bias=True)
Buffers:
Forward hooks:
Backward hooks:
Como se puede ver en la salida:
ParametersLos atributos imprimen los parámetros que se pueden aprender del modelo, es decir, los pesos y sesgos de las dos capas completamente conectadas.ModulesEl atributo imprime los submódulos del modelo, incluido el modelo completo y sus dos capas completamente conectadas.BuffersLa propiedad está vacía porque no hay ningún caché definido en el modelo.Forward hooksLa propiedad está vacía porque no hay enlaces de propagación hacia adelante definidos en el modelo.Backward hooksLa propiedad está vacía porque no hay ganchos de retropropagación definidos en el modelo.
Acceder a submódulos en el modelo.
import torch
import torch.nn as nn
class SubNet(nn.Module):
def __init__(self):
super(SubNet, self).__init__()
self.conv = nn.Conv2d(3, 16, kernel_size=3, padding=1)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
def forward(self, x):
x = self.conv(x)
x = self.pool(x)
return x
class MyNet(nn.Module):
def __init__(self):
super(MyNet, self).__init__()
self.subnet1 = SubNet()
self.subnet2 = SubNet()
self.fc = nn.Linear(16 * 8 * 8, 10)
def forward(self, x):
x1 = self.subnet1(x)
x2 = self.subnet2(x)
x = torch.cat((x1, x2), dim=1)
x = x.view(-1, 16 * 8 * 8)
x = self.fc(x)
return x
# 创建模型实例
model = MyNet()
# 查看直接子模块
print("Children:")
for name, module in model.named_children():
print(name, module)
# 查看所有子模块(包括当前模块)
print("\nModules:")
for name, module in model.named_modules():
print(name, module)
# 查看命名直接子模块
print("\nNamed Children:")
for name, module in model.named_children():
print(name, module)
# 查看命名所有子模块(包括当前模块)
print("\nNamed Modules:")
for name, module in model.named_modules():
print(name, module)
En este ejemplo, definimos un SubNet submódulo y un MyNet modelo, que MyNet contiene dos. y SubNetsubmódulos y una capa completamente conectada. Analizamos los submódulos directos, todos los submódulos y sus versiones nombradas usando las funciones named_childrennamed_modules
El resultado es el siguiente:
Children:
subnet1 SubNet(
(conv): Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
subnet2 SubNet(
(conv): Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
Modules:
MyNet(
(subnet1): SubNet(
(conv): Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(subnet1.conv): Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(subnet1.pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(subnet2): SubNet(
(conv): Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(subnet2.conv): Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(subnet2.pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(fc): Linear(in_features=1024, out_features=10, bias=True)
)
subnet1 SubNet(
(conv): Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
subnet1.conv Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
subnet1.pool MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
subnet2 SubNet(
(conv): Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
subnet2.conv Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
subnet2.pool MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
fc Linear(in_features=1024, out_features=10, bias=True)
Named Children:
subnet1 SubNet(
(conv): Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
subnet2 SubNet(
(conv): Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
Named Modules:
MyNet MyNet(
(subnet1): SubNet(
(conv): Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(subnet1.conv): Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(subnet1.pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(subnet2): SubNet(
(conv): Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(subnet2.conv): Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(subnet2.pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(fc): Linear(in_features=1024, out_features=10, bias=True)
)
subnet1 SubNet(
(conv): Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
subnet1.conv Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
subnet1.pool MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
subnet2 SubNet(
(conv): Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
subnet2.conv Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
subnet2.pool MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
fc Linear(in_features=1024, out_features=10, bias=True)
Se puede ver en los resultados de salida:
- Utilice la función
named_childrenpara devolver un submódulo directo y acceder al nombre del submódulo a través del primer elemento de la tupla devuelta, y al submódulo mismo a través del segundo elemento. - Utilice
named_modulesla función para devolver todos los submódulos (incluido el módulo actual). También puede acceder al nombre del módulo a través del primer elemento de la tupla devuelta y al segundo elemento a través de módulo en sí. named_childrenLas funciones ynamed_modulestienen cada una una versión con nombre,named_childenynamed_modulesrespectivamente. El primer elemento de la tupla devuelta por estas dos funciones es el nombre del submódulo y el segundo elemento es el submódulo mismo.
Estas funciones proporcionan una manera conveniente de administrar, acceder y controlar submódulos en modelos complejos de redes neuronales.