1. Red de creencias profundas (DBN)
En 2006, el "padre de las redes neuronales" Geoffrey Hinton sacrificó la red de creencias profundas de artefactos, que resolvió el problema de entrenamiento de las redes neuronales profundas de una sola vez y promovió el rápido desarrollo del aprendizaje profundo.
Deep Belief Nets (Deep Belief Nets) es un modelo de generación de probabilidad que puede establecer una distribución de probabilidad conjunta de datos de entrada y categorías de salida.
La red de creencias profundas resuelve el problema de optimización de las redes neuronales profundas mediante la adopción del entrenamiento capa por capa. El entrenamiento capa por capa le da a toda la red un buen peso inicial, para que la red pueda lograr la solución óptima solo después de un ajuste fino.
Cada capa oculta de la red de creencias profundas desempeña un doble papel: sirve como la capa oculta de la neurona anterior y la capa visible de la neurona posterior.
En el entrenamiento capa por capa, el papel más importante es la
estructura de la "máquina de Boltzmann restringida" . La red de creencias profundas puede considerarse como 受限玻尔兹曼机un todo
Máquina de Boltzmann (BM)
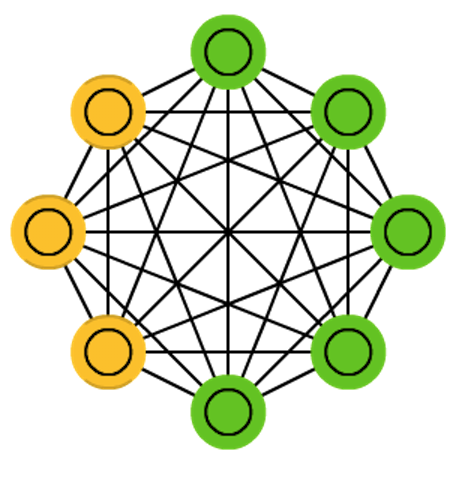
Boltzmann Machines (Boltzmann Machines, BM para abreviar), propuesta por Great God Hinton en 1986, es una red neuronal estocástica enraizada en la mecánica estadística. En este tipo de red, las neuronas tienen solo dos estados (inactivo, activado). Representado por binario 0 y 1, el valor del estado se determina de acuerdo con la ley de estadísticas de probabilidad.
Dado que la forma de expresión de esta ley estadística de probabilidad es similar a la distribución de Boltzmann propuesta por la famosa mecánica estadística LEBoltzmann, esta red se llama "máquina de Boltzmann".
En física, la distribución de Boltzmann es una descripción de la ley de distribución de energía de las moléculas de gas en un estado de equilibrio térmico cuando un gas ideal se somete a una fuerza externa conservadora.
En el aprendizaje estadístico, si consideramos que el modelo debe aprenderse como un objeto de alta temperatura, el proceso de aprendizaje se considera como un proceso de enfriamiento para alcanzar el equilibrio térmico. Después de que la energía converge al mínimo, el equilibrio térmico tiende a ser estable, es decir, cuando la energía es la menor, la red es la más estable y la red es óptima en este momento.
La máquina Boltzmann (BM) se puede utilizar en el aprendizaje supervisado y el aprendizaje no supervisado.
En el aprendizaje no supervisado, las variables ocultas pueden verse como representaciones de características internas de variables visibles, y pueden aprender reglas complejas en los datos. El precio de la máquina Boltzmann es que el tiempo de entrenamiento es muy largo, muy largo y muy largo.
Máquina de Boltzmann restringida (RBM)

Las máquinas de Boltzmann restringidas (RBM)
eliminan las conexiones intracapa de la "máquina de Boltzmann" (BM) y restringen las conexiones para convertirse en "máquinas de Boltzmann restringidas" (RBM)
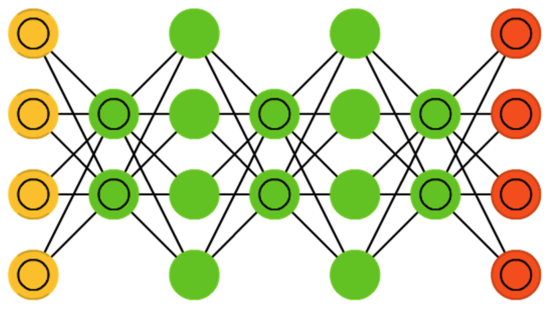
Una red neuronal de dos capas, una capa visible y una capa oculta.
La capa visible recibe los datos, la capa oculta procesa los datos, las dos capas están conectadas de manera totalmente conectada y no están conectadas antes de la misma capa.
La máquina de Boltzmann restringida necesita retroalimentar los resultados de salida a la capa visible, y al reconstruir el error de reconstrucción entre la capa visible y la capa oculta cíclicamente para reconstruir un conjunto de coeficientes de peso que minimiza el error.
El método tradicional de propagación inversa aplicado a estructuras profundas es factible en principio, pero no puede resolver el problema de la dispersión de gradiente en la operación práctica.
Dispersión de gradiente (desvanecimiento de gradiente), cuando el error se propaga, cuanto más lejos esté la distancia de propagación, menor será el valor del gradiente y más lenta será la actualización del parámetro.
Esto hará que los parámetros de la capa oculta converjan cerca de la capa de salida; y cerca de la capa de entrada, los parámetros de la capa oculta apenas han cambiado o son valores iniciales seleccionados al azar.
2. Red neuronal convolucional (CNN)
Red neuronal convolucional se refiere a una red neuronal que usa convolución en lugar de multiplicación de matriz en al menos una derivada.
¿Qué es la convolución?
La convolución es una operación matemática realizada en dos funciones: llamamos a \ ((f * g) (n) \) la convolución de f y g.
- Definición continua
\ ((f * g) (n) = \ int _ {- \ infty} ^ {\ infty} f (τ) g (n-τ) dτ \) - Definición discreta
\ ((f * g) (n) = \ sum_ {τ = - \ infty} ^ {\ infty} f (τ) g (n-τ) \)
Hacemos \ (x = τ \) , \ (y = n-τ \) , luego \ (x + y = n \) es equivalente a la línea recta debajo
Si atraviesa estas líneas rectas, como una toalla enrollada, como su nombre lo indica, "convolución"

En las redes convolucionales, la esencia de la convolución es el proceso de suma ponderada 核函数gcomo factor de ponderación 输入函数f.
De hecho, la función binaria \ (U (x, y) = f (x) g (y) \) se enrolla en una función unaria \ (V (t) \) , comúnmente conocida como ataque de reducción de dimensionalidad
\ (V (t) = \ int_ {x + y = t} U (x, y) d_x \) , las funciones f y g deberían tener el mismo estado, o las variables x e y deberían tener el mismo estado, una forma deseable es avanzar a lo largo de una línea recta x + y = t ;
Dados

Encuentre la probabilidad de que los dos dados sumen 4, este es el escenario de aplicación de convolución.
- La probabilidad del primer dado es f (1), f (2), ... f (6)
- La probabilidad del segundo octavo dado es g (1), g (2), ... g (m)
La probabilidad de que los dos dados sumen 4 es: \ (f (1) g (3) + f (2) g (2) + f (3) g (1) \) La
forma estándar es: \ ((f * g) (4) = \ sum_ {m = 1} ^ 3f (4-m) g (m) \)
Hacer bollos

La máquina produce continuamente bollos al vapor, suponiendo que la velocidad de producción del bollo al vapor es f (t),
luego la cantidad total de bollos al vapor producidos en un día es
\ (\ int_ {0} ^ {24} f (t) dt \)
y se corromperá gradualmente después de producirse. La función de corrupción es g (t). Por ejemplo, 10 bollos al vapor se corromperán en 24 horas.
\ (10 * g (t) \)
Los bollos al vapor producidos en un día es
\ (\ int_ {0} ^ {24} f (t) g ( 24-t) dt \)
Hacer pescado

La convolución se considera cocción, la función de entrada es la materia prima y la función de núcleo es la receta, para la misma función de entrada carpa
- El peso de la salsa de soja en la función del núcleo es mayor, y el pescado estofado sale
- El peso del azúcar y el vinagre en la función del núcleo es mayor, y la producción de pescado de vinagre Xihu
- La función de pimienta en el grano tiene un peso mayor y produce pescado picante coreano
Procesamiento de imagen
Suponiendo que una imagen tiene ruido, para suavizarla, puede convertir la imagen en una matriz
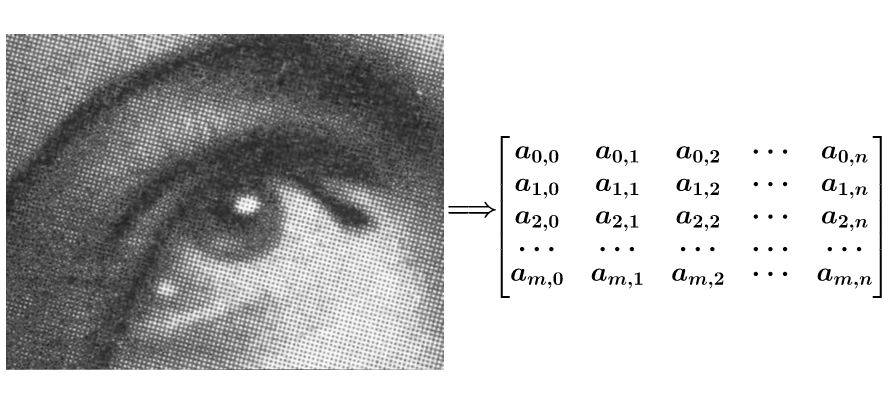
Si desea suavizar el punto \ (a_ {1,1} \) , puede realizar una operación de convolución en la matriz de composición \ (f \) y \ (g \) cerca del punto \ (a_ {1,1} \) , y luego Rellenar de nuevo

\ (F \) y \ (G \) se calcula como sigue, de hecho, ser calculada en la dirección opuesta, lo mismo que toalla en rollo

de computación \ (c_ {1,1} \) escrito fórmula \ ((f * g) ( 1,1) = \ sum_ {k = 0} ^ 2 \ sum_ {h = 0} ^ 2f (h, k) g (1-h, 1-k) \)
Referencia especifica:
Funciones de red neuronal convolucional
Las características de la operación de convolución determinan que la red neuronal es adecuada para procesar datos con una estructura similar a la red.
Los datos de red típicos son una imagen digital, ya sea en escala de grises o en color, es un conjunto de títulos o vectores definidos en una red de píxeles bidimensional.
Las redes neuronales convolucionales se usan ampliamente en el reconocimiento de imágenes y textos, y se expanden gradualmente a otros campos, como el procesamiento del lenguaje natural.
- Percepción dispersa
El tamaño de la función del núcleo de la capa convolucional suele ser mucho menor que el tamaño de la imagen.
La imagen puede tener miles de píxeles en ambas dimensiones, pero la función del núcleo no excederá decenas de píxeles como máximo.
Elegir una función de kernel más pequeña ayuda a descubrir los detalles locales sutiles en la imagen y mejorar la eficiencia de almacenamiento y la eficiencia de operación del algoritmo. - Uso compartido de parámetros Los
mismos parámetros se utilizan en un modelo. En cada ronda de entrenamiento, se utiliza una sola función del núcleo para convolucionar con todos los bloques de la imagen. - Invarianza de traducción
Cuando la entrada de la convolución está equilibrada, su salida es igual a la misma cantidad de traducción que la salida original, lo que indica que la operación de traducción y la función de la función del núcleo pueden intercambiarse.
Capa de red neuronal convolucional
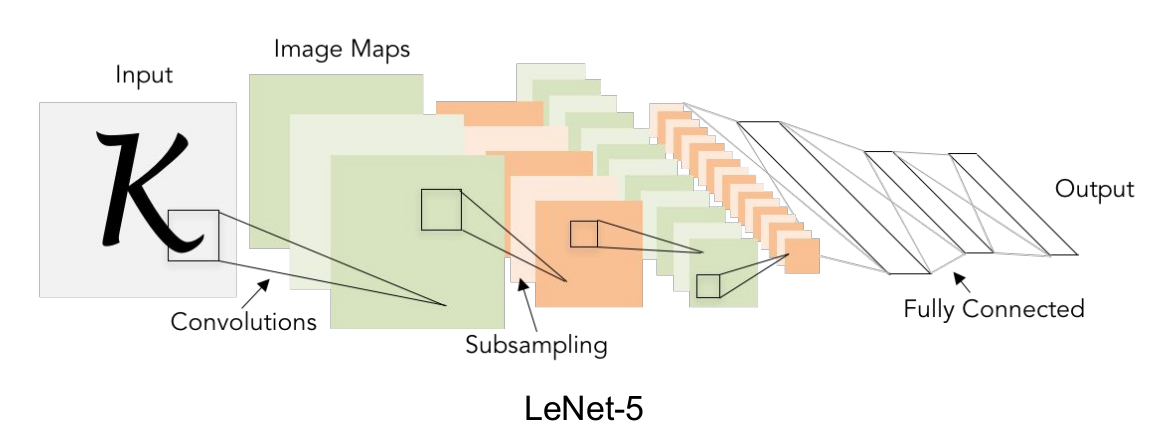
Después de que la imagen de entrada se envíe a la red neuronal convolucional, debe recorrer la capa convolucional, la capa de activación y la capa de agrupación, y finalmente generar los resultados de clasificación de la capa completamente conectada.
- Capa de
entrada Los datos de entrada, generalmente realizan algún procesamiento de datos, como promedios, normalización, PCA / blanqueamiento, etc. - Capa
convolucional La capa convolucional es la parte central de la red neuronal convolucional. Los parámetros son una o más funciones del núcleo inicializadas aleatoriamente. La función del núcleo escanea la imagen de entrada fila por columna, como una lámpara. Todos los resultados de convolución calculados después del escaneo pueden formar una matriz. Las características obtenidas por la capa de convolución generalmente se envían a la capa de excitación para su procesamiento. - La
función principal de la capa de excitación es hacer un mapeo no lineal de los resultados de la capa de convolución. Las funciones comunes de la capa de excitación son sigmoide, tanh, Relu, Leaky Relu, ELU, Maxout - Capa de agrupamiento
En el medio de la capa base de volumen continuo y la capa de excitación, se utiliza para comprimir la cantidad de datos y parámetros para reducir el sobreajuste.
En resumen, si la entrada es una imagen, la función principal de la capa de agrupación es comprimir la imagen.
Un método común de agrupamiento máximo es dividir el mapa de entidades en varias regiones rectangulares y seleccionar el valor máximo en cada región. - Capa completamente conectada
Todas las neuronas entre las dos capas tienen derecho a reconectarse, por lo general, la capa completamente conectada se encuentra en la cola de la red neuronal convolucional y genera el resultado de la clasificación.
En el entrenamiento de redes neuronales convolucionales, el parámetro a entrenar es un núcleo de convolución.
Kernel de convolución: es decir, la función del kernel utilizada para la convolución.
La función de la red neuronal convolucional es extraer las características del objeto de entrada capa por capa. La capacitación también utiliza el método de propagación inversa. La actualización continua de los parámetros puede mejorar la precisión de la extracción de características de la imagen
3. Generando una red adversarial (GAN)
GAN (Generative Adversarial Network) es un modelo generativo diseñado por Goodfellow y otros en 2014. Inspirado por el juego de suma cero en la teoría de juegos, el problema generativo se considera como la confrontación y el juego entre las dos redes, el generador y el discriminador.
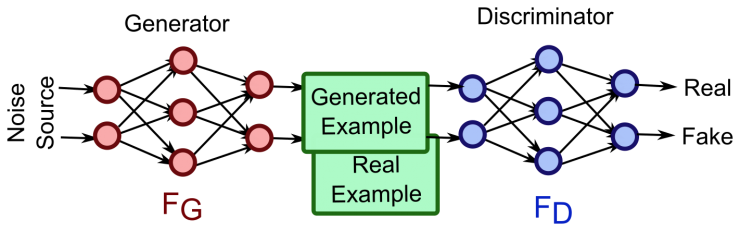
Este método fue propuesto por Goodfellow et al. En 2014. La red de confrontación generativa consiste en un generador y un discriminador. El
generador genera muestras aleatorias del espacio latente como entrada, y su salida debe imitar las muestras reales en el conjunto de entrenamiento tanto como sea posible.
La entrada del discriminador es la muestra real o la salida del generador, y su propósito es distinguir la salida del generador de la muestra real tanto como sea posible.
La principal ventaja de GAN es que supera la clasificación tradicional de la red neuronal y las funciones de extracción de características, y puede generar nuevos datos de acuerdo con las características de los datos reales.
Las dos redes avanzan en la confrontación. Después del progreso, la confrontación continúa, y los datos obtenidos por la red generativa se vuelven cada vez más perfectos, acercándose a los datos reales, para que se puedan generar los datos deseados (imágenes, secuencias, videos, etc.).
Generador (generador)
El generador genera datos sintéticos a partir del ruido dado (generalmente conocido como distribución uniforme o distribución normal). Intenta producir datos más cercanos a la realidad.
El generador es como un hueso blanco, tratando de simular la distribución potencial de muestras de datos reales a partir de ruido aleatorio para generar muestras de datos falsos y reales.

Discriminador
El discriminador distingue la salida del generador de los datos reales. Intente distinguir entre datos reales y datos generados más perfectamente.
El discriminador es Wu Wukong, y usa ojos de fuego para juzgar si se trata de datos reales que son inofensivos para humanos y animales o un pretendiente disfrazado por el generador.

Generar una red de adversarios * puede verse como un avance en el aprendizaje profundo
Tanto el generador como el discriminador pueden implementarse con una red neuronal profunda para establecer un modelo de generación de datos para que el generador sea lo más preciso posible. Usted tiene la distribución de muestras de datos. El aprendizaje adversario es un aprendizaje no supervisado del método de aprendizaje.
La capacitación en red puede ser equivalente al problema mínimo-máximo de la función de catálogo
- Máximo: maximice la precisión del discriminador para distinguir datos reales de datos falsos
- Mínimo: minimice la probabilidad de que el discriminador descubra los datos generados por el generador
El modelo generativo tradicional define la distribución del modelo y luego resuelve los parámetros. Por ejemplo, bajo la premisa de que los datos conocidos satisfacen la distribución normal, el modelo generativo resolverá la media y la varianza normales de acuerdo con la muestra a través de métodos como la estimación de máxima verosimilitud.
Las redes adversas generativas eliminan la dependencia de la distribución del modelo y no limitan las dimensiones de generación, lo que amplía enormemente el rango de muestras de datos generados, y también pueden integrar diferentes funciones de pérdida, aumentando la libertad de diseño.
4. Red neuronal recurrente (RNN)
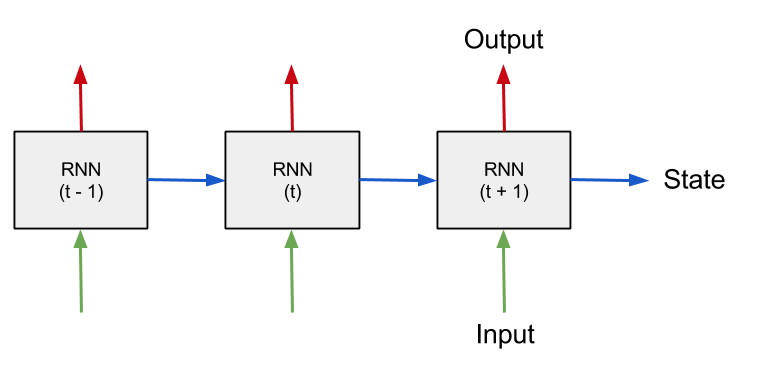
La red neuronal recurrente (red neuronal recurrente) también puede representar la red neuronal recurrente. Las redes neuronales recurrentes pueden considerarse como un caso especial de redes neuronales recurrentes, y las redes neuronales recurrentes pueden considerarse como la promoción de redes neuronales recurrentes.
La red neuronal convolucional tiene la característica de compartir parámetros en el espacio, lo que permite que la misma función del núcleo se aplique a diferentes regiones de la imagen.
Ajuste el uso compartido de parámetros a la dimensión de tiempo, deje que la red neuronal use el mismo coeficiente de peso para procesar los datos con el orden, y el resultado es la red neuronal recurrente.
-
La
red neuronal recurrente en el tiempo introduce la dimensión "tiempo", adecuada para procesar datos de series temporales.
La red neuronal recurrente consiste en dividir la entrada de longitud variable en pequeños bloques de igual longitud, y luego usar el mismo sistema de peso para el procesamiento, a fin de realizar el cálculo y el procesamiento de la entrada de longitud variable.
Por ejemplo, mi madre de repente te llamó a la cocina: "La comida está lista, date prisa ...", incluso si no escuchas claramente más tarde, puedes adivinar que diez o nueve son para que comas rápidamente. -
La salida de la red neuronal recurrente de memoria en el tiempo t depende de la entrada en el momento actual, y también depende de la salida de la red en el tiempo anterior t-1 o incluso antes.
En este sentido, la red neuronal recurrente introduce un mecanismo de retroalimentación y, por lo tanto, tiene una función de memoria. La función de memoria permite que la red neuronal recurrente extraiga la información de la secuencia misma.
La información interna de la secuencia de entrada se almacena en la capa oculta de la red neuronal y fluye a través de la capa oculta con el tiempo. Las características de memoria de la red recurrente se pueden expresar mediante la fórmula
\ (h_t = f (Wx_t + Uh_ {t-1}) \)
Explicación: El resultado ponderado de la entrada en el momento \ (x_t \) y el resultado ponderado del estado de la capa oculta en el momento \ (t-1 \) \ (h_ {t-1} \) se utilizan como
entrada de la función de transferencia , y el La salida de la capa oculta en el tiempo \ (t \) \ (h_t \) .
\ (W \) representa la matriz de peso de entrada a estado, \ (U \) representa la matriz de transición de estado a estado.
El entrenamiento de la red neuronal recurrente consiste en ajustar continuamente los parámetros \ (W \) y \ (U \) de acuerdo con el error entre el resultado de salida y el resultado real hasta alcanzar los requisitos preestablecidos. El método de entrenamiento también es un algoritmo de propagación inversa basado en gradiente .
La red neuronal de alimentación directa también tiene características de memoria en un determinado programa. Mientras los parámetros de la red neuronal estén optimizados, los parámetros optimizados contendrán rastros de datos pasados, pero la memoria optimizada se limita al conjunto de datos de entrenamiento. Cuando el vinagre de entrenamiento se aplica a Cuando se utiliza el nuevo conjunto de datos de prueba, sus parámetros no se ajustarán más según el rendimiento de los datos de prueba.
Bidireccional RNN
Por ejemplo, hay una serie de televisión, los personajes que aparecieron en el tercer episodio, ahora vamos a predecir los nombres de los personajes que aparecen en el tercer episodio, no puede predecir el contenido de los dos episodios anteriores, por lo que debe usar el cuarto, El contenido del quinto episodio para predecir el contenido del tercer episodio, esta es la idea de RNN bidireccional
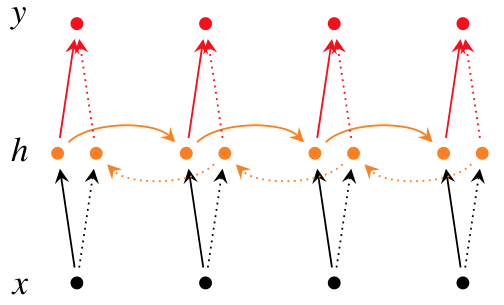
Si desea que la red neuronal recurrente utilice la información del futuro, debe establecer una conexión directa entre el estado actual y el estado en un momento posterior.
La red recurrente bidireccional incluye dos enlaces de cálculo directo y cálculo inverso
- En el cálculo de avance, oculta estado de capa en el tiempo t \ (h_t \) y pasado \ (h_ {t-1} \) asociado
- En el cálculo inverso, el estado de la capa oculta \ (h_t \) y la futura red recurrente bidireccional relacionada \ (h_ {t + 1} \)
en el momento t necesita calcular los resultados hacia adelante y hacia atrás por separado, y usar ambos como oculto Los parámetros finales de la capa.
RNN profundo
La estructura profunda se puede obtener al introducir la estructura profunda en la red neuronal recurrente.
Por ejemplo, cuando aprende inglés, recordará todas las palabras que desea evaluar si lee las palabras en inglés una vez, generalmente con las palabras que ha memorizado algunas veces antes, y luego elige las que están memorizadas pero no familiares o no. Palabras memorizadas
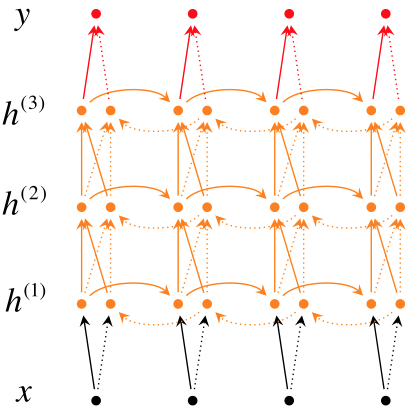
En comparación con RNN bidireccional, el RNN bidireccional profundo tiene varias capas ocultas más, porque su idea es que no se puede recordar mucha información al mismo tiempo.
El RNN bidireccional profundo se basa en tal idea, el estado de cada capa oculta \ (h_t ^ i \) No solo depende del estado de la capa oculta anterior al mismo tiempo \ (h_t ^ {i-1} \) , sino que también depende del estado de la misma capa oculta h_ {t-1} ^ {i} $
El papel de la estructura de profundidad es establecer una imagen más clara De representación. Con "Gestalt", debe elegir las palabras correctas según el contexto. Algunos agujeros de relleno se pueden inferir solo de la oración en la que se encuentran, lo que corresponde a la dependencia de una sola capa oculta en la dimensión del tiempo; algunos agujeros de relleno pueden necesitar leerse a través de todo el párrafo o el texto completo para determinar, lo que corresponde a la dimensión del tiempo y la dimensión del espacio. Dependencia
RNN recursivo
Las redes neuronales recurrentes pueden procesar datos con una estructura jerárquica, que puede considerarse como la promoción de redes recurrentes.

La característica de la red neuronal recurrente es compartir parámetros en la dimensión de tiempo para expandir la secuencia de procesamiento.Si se expande en una estructura de estado de árbol, se utiliza la red neuronal recurrente. La red neuronal recurrente primero convierte los datos de entrada en una determinada estructura topológica, y luego utiliza recursivamente el mismo coeficiente de peso en la misma estructura para obtener una predicción estructurada a través del recorrido.
Por ejemplo, "maestro en dos universidades" tiene ambigüedad. Si simplemente se divide en secuencias de palabras, la ambigüedad no se puede resolver.
La red neuronal recurrente divide una oración completa en una combinación de varios componentes a través de una estructura de árbol, y el vector generado no es el nodo raíz de la estructura de árbol.
5. Red de memoria a largo y corto plazo (LSTM)

La memoria larga a corto plazo (LSTM, Long Short-Term Memory) es un tipo de red neuronal recurrente en el tiempo. Está especialmente diseñada para resolver el problema de dependencia a largo plazo del RNN general (red neuronal recurrente). El artículo se publicó por primera vez en 1997. Debido a su estructura de diseño única, LSTM es adecuado para procesar y predecir eventos importantes con intervalos muy largos y retrasos en las series de tiempo.
RNN introduce la función de memoria al compartir parámetros a tiempo, de modo que la información previa se pueda aplicar a la tarea actual, pero este tipo de memoria generalmente solo tiene una profundidad limitada.
Por ejemplo, Dragon Ball Super o Naruto actualizan un episodio todas las semanas. Incluso después de una brecha de una semana, podemos conectar sin problemas el contenido del episodio anterior con la trama del nuevo episodio. Sin embargo, la memoria de RNN no tiene una continuidad tan fuerte, y mucho menos una semana, se estima que la comida se ha sacado en 5 minutos.
LSTM puede memorizar selectivamente cierta información con un intervalo de tiempo más largo, como la memoria humana, y juzgará si se olvida o se recuerda información diferente según las características de los elementos constitutivos.
LSTM se utiliza para lograr memoria a largo plazo, para lograr cualquier longitud de memoria. Se requiere que el modelo tenga la capacidad de juzgar el valor de la información, combinarse con sí mismo para determinar qué información debe conservarse y qué información debe descartarse, y la unidad también debe poder decidir qué parte de la memoria debe usarse de inmediato.
4 tipos de composición
LSTM generalmente consta de los siguientes 4 módulos

- Las celdas de memoria (celdas de memoria)
se utilizan para almacenar valores o estados, y el período de almacenamiento puede ser a largo o corto plazo. - La puerta de entrada
determina qué información se almacena en la celda de memoria - La puerta de olvido
determina qué información se descarta de la celda de memoria - La puerta de salida
determina qué información se emite desde la celda de memoria